![[ 딥러닝 논문 리뷰 - PRMl Lab ] - Asyrp: DIFFUSION MODELS ALREADY HAVE A SEMANTIC LATENT SPACE (ICLR 2023)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbPN7pi%2FbtsMSCS7ji0%2F5nt8KfxKbFbyqzeOuegitk%2Fimg.png)
교수님께서 style transfer논문을 찾아보라고 하셔서, diffusion + style transfer논문을 찾아보는 중에 DiffStyle을 보게되었고 해당 논문의 fundamental엔 Asyrp(Asymmetric reverse process)라는 논문이 있었습니다. 이제 본격적으로 졸업을 위해 SCI에 논문을 써야하기에, 이러한 좋은 논문을 읽으며 논문을 쓰는법을 많이 배운거 같습니다.
git: https://github.com/kwonminki/Asyrp_official
GitHub - kwonminki/Asyrp_official: official repo for Asyrp : Diffusion Models already have a Semantic Latent Space (ICLR2023)
official repo for Asyrp : Diffusion Models already have a Semantic Latent Space (ICLR2023) - kwonminki/Asyrp_official
github.com
paper: https://arxiv.org/pdf/2210.10960
Abstract
diffusion model은 많은 domain에서 좋은 성능을 내며 성공했습니다. 하지만, diffusion model은 generative process을 control할 semantic latent space에 대한 연구가 부족했습니다. 이에 대해 저자들은 pretrained된 diffusion model을 freeze시킨 상태에서의asymmetric reverse process (Asyrp)을 제안했습니다. 저자들이 제안한 h-space라는 latent space는 semantic image manipulation을 수행하기 쉬웠습니다. 또한 저자들은 versatile한 editing 방법론과 editing strength를 이용한 interval과 quality deficiency를 고려한 interval을 설정하여 quality-boosting할 수 있는 구조에 대해 소개합니다. 저자들의 방법론은 (DDPM+, iDDPM, ADM,, etc) 많은 구조에 대해 적용가능하며, (CelebA-HQ, AFHQ-dog, LSUN-church, LSUN-bedroom, METFACES,, etc) 많은 데이터셋에 적용가능합니다. https://kwonminki.github.io/Asyrp/ 프로젝트 페이지는 이와 같습니다.
Background
DDIM

해당 논문에서는 DDIM을 주로 설명합니다. DDIM은 위와같은 확률분포에서 reverse process를 sampling합니다. 또한, \(\eta\)값이 1이면 DDPM, 0이면 DDIM이 됩니다.
CLIP

CLIP은 블로그에서도 소개한적이 있는데, image Encoder \(E_I\)와 text encoder \(E_T\) output의 similarity를 기반으로 multi-modal embedding을 학습합니다. 이는 mode collapse없이 cosine-distance를 이용한 loss를 통해 homogeneous editing이 가능합니다.
Introduction

Image guidance는 guiding image의 latent variable과 unconditional latent variables와 섞는 방법입니다. 이는 어느정도 control을 제공하긴 하나, guide된 이미지의 어떤 condition을 반영해야하는지에 대한 부분이 모호하며, 직관적으로 condition을 magnitude하는것이 힘듭니다.
Classifier guidance는 LDM할때도 다루었지만, 이는 새로 학습한 classifier의 gradient을 reverse process에 활용해 target class를 만드는 방법입니다. 이는 추가적인 classifier를 학습시켜야 한다는 점이 비효율적입니다. 또한, sampling과정에서 classifier의 gradient를 구하는 것이 비용이 든다고 합니다.
DiffusionCLIP같은 경우에는 이미지를 latent로 보낸 다음에 CLIP loss를 통해 새로운 모델을 fine tuning하는 방식입니다. 이는 이전 방식과는 다르게 target attribute를 source에 잘 섞을 수 있지만 여전히 많은 모델이 필요해 비효율적이라고 합니다.
GAN (Goodfellow et al., 2020)은 latent space에서 image editing에 대한 쉬운 직관을 내놓았었습니다. 원본 이미지에 해당하는 잠재 벡터(latent vector)가 주어지면, 이 벡터를 어떤 방향으로 조정하면 생성된 이미지가 CLIP의 임베딩 공간에서 원하는 텍스트 설명과 가장 비슷해질지를 찾을 수 있습니다. 이러한 latent direction은 다른 이미지에도 똑같이 적용될 수 있습니다. 하지만 real image가 들어왔을때 이에대한 latent vector를 찾는것은 매우 어렵습니다. 이에 대한 diffusion의 연구도 많았으나, 대부분이 추가적인 classifier를 만들어야 했습니다.
해당 논문에서는 Asyrp을 발견했으며, 이는 frozen diffusion model에서도 original image의 latent space에서의 edit이 가능합니다. 저자들의 latent space이름은 h-space이며 이는 추후에 설명할 좋은 attribute들을 다 가지고 있습니다. Figure1에서 (d)가 이에 해당합니다.
Discovering semantic latent space in diffusion models
해당 부분에서는 naive approach가 작동하지 않는지와 새로운 controllable reverse process를 제안합니다. 그리고 앞으로 해당 논문에서는 야래오 같은 간략한 표현을 씁니다.

간략함을 위해 \(sigma_{t}z_t\)는 생략하지만, \(\eta \neq 0\)일때는 생략하지 않습니다.
Problem
pretrained and frozen diffusion model에서 \(x_T\)를 통한 semantic latent manipulation이 목표입니다. 초기의 아이디어는, \(x_T\)를 CLIP loss방향으로 이동시키는 방법이었습니다. 하지만 이는 잘못된 manipulation이 발생할 수 있고, 이미지가 distort될 수 있다는 문제가 있습니다.
위의 방법에 대한 대안은 network가 predict한 \(\epsilon_{t}^{\theta}\)를 shift시키는 것입니다. 하지만 이는 \(x_0\)을 적절히 manipulate할 수 없는데, \(\mathsf{P}_t, \mathsf{D}_t\)가 이를 \(p_{\theta}(x_{0:T})\)로 계속 가게 하여, 일종의 상쇄가 일어납니다. 저자들은 이에 대한 Theorem 1을 정의합니다.


이에 대한 증명은 Appendix C에 있으며 위 그림 (a-b)에서 \(x_0, \tilde{x}_0\)이 거의 같음을 확인할 수 있습니다.
Asymmetric reverse process
저자들은 새로운 asymmetric한 reverse process를 아래와 같이 새로이 정의합니다.

단지 \(mathsf{P}_t\)를 \(\epsilon_t^\theta \rightarrow \tilde{\epsilon}_t^\theta\)로 변경한 것 뿐입니다. 이는 \(x_t\)로 향하는 방향은 그대로 두고, \(\mathsf{D]_t\)는 original flow를 따라가게 합니다. 아래 그림은 직관적인 Asyrp의 프로세스를 보여줍니다.
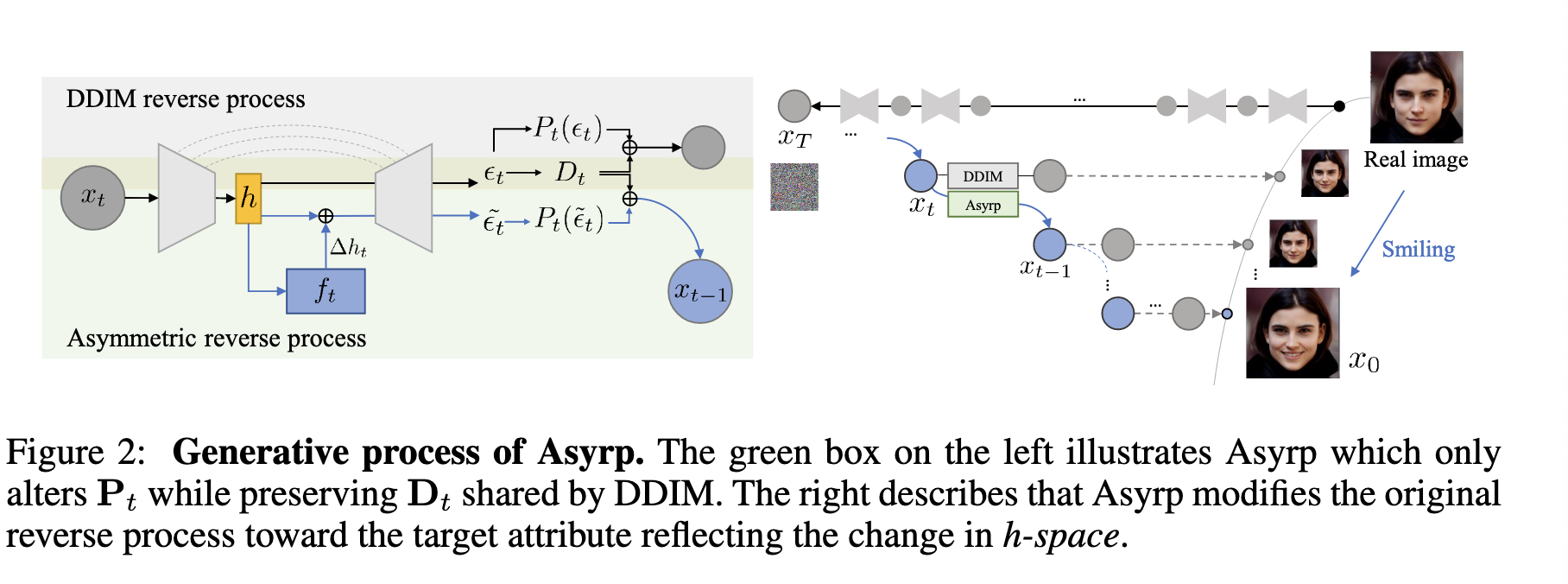
저자들은 \(\mathsf{P}_{t}^{edit}\)과 \(\mathsf{P}_{t}^{source}\)를 위에서 소개한 directional CLIP loss의 input으로 사용하고, 이 둘간의 차이를 정규화합니다. 그 후 \(\vartriangle\epsilon=argmin_{\vartriangle\epsilon}\mathbb{E}_{t}\mathcal{L}^{(t)}\)인 \(\vartriangle\epsilon\)값을 구하는데, \(\mathcal{L}^{(t)}\)는 아래와 같이 정의됩니다.

뒤에서 다루겠지만 이러한 \(\vartriangle\epsilon\)은 \(x_0^{edit}\)의 특성을 렌더링하지만, \(\epsilon-space\)는 diffusion model에서 semantic latent space의 특성이 부족합니다.
h-space

현재 SOTA의 diffusion모델들의 \(\epsilon_t^{\theta}\)는 U-Net에서 나옵니다. 이러한 이유로 저자들은 이를 bottle-neck으로 생각했고, U-net의 가장 깊은 부분의 feature map인 \(h_t\)를 \(\epsilon_t^{\theta}\)를 control하기 위해 선택했습니다. \(h_t\)는 \(\epsilon_t^{\theta}\)보다 더 작은 spatial resolution과 high-level semantic을 가지고 있기도 하기 때문이죠. 이러한 이유로 sampling equation은 아래와 같이 변경합니다.

\(\epsilon_t^{\theta}(x_t|\vartriangle h_t)\)는 original feature maps \(h_t\)에 \(\vartriangle h_t\)를 추가한 것입니다. \(\vartriangle h_t\)는 위의 식 Eq(7)를 최소화함으로써, 기존의 \(\mathsf{P}_t(\tilde{\epsilon}_t^{\theta}(x_t))\)대신 \(\mathsf{P}_t(\epsilon_t^{\theta}(x_t|\vartriangle h_t))\)를 사용하여 attrribute를 조절합니다.
저자들은 h-space에서 기존과 다른 특성을 발견했다고 합는데, 이는 아래와 같습니다.
- 같은 \(\vartriangle h\)는 다른 sample에서도 같은 효과를 적용한다.
- \(\vartriangle h\)를 Linear scaling하면 attribute change의 mangitude를 조절할 수 있고, 이는 심지어 negative scale까지 적용됩니다.
- 2개 이상의 \(\vartriangle h\)를 동시에 합쳐 attribute를 조정하는 것도 가능합니다.
- \(\vartriangle h\)는 quality degradation없이도 결과를 뽑아낼 수 있습니다.
- \(\vartriangle h\)이 주는 attribute의 변화가 timestep t가 달라도 일관되게 변합니다.
Implicit neural directions

\(\vartriangle h\)을 수많은 timestep에 적용하기에는 너무 많은 iteration이 필요하고, learning rate나 scheduling을 하기에도 많이 힘듭니다. 대신에, \(h_t\) -> \(\vartriangle h\)인 implicit function인 \(f_t(h_t)\)를 정의합니다. \(f_t(h_t)\)는 2개의 1x1 convolution으로 이루어진 작은 network이며, U-net의 timestep과 concatenate됩니다 (Figure 14와 차원은 아무래도 다른거 같습니다). 이 또한 \(\mathsf{P}_t^{edit}=\mathsf{P}_t(\epsilon_t^{\theta}(x_t|f_t))\)를 사용하여 Eq (7)를 최적화 합니다.
\(f_t\)를 사용하여 learning하면 learning rate에 보다 robust하며, 모든 timestep에 대해 \(\vartriangle h_t\)를 학습하는 것보다 더 빨리 수렴한다고 합니다. 또한, \(f_t\)를 통해 implicit function을 학습하면 unseen timestep과 bottleneck feature에 대해 일반화를 할 수 있습니다. 이러한 일반화는 DDIM에서 정의한것과 같은 subsequence \({x_{\tau i}}_{\forall} \in [1, S]\), \(S < T\)에서 training accelerate를 할 수 있습니다. 이를 통, custom subsequcne \({\tilde{\tau}_i}\), \(\tilde{S} < T\)를 정의할 수 있는데, \(\vartriangle \tilde{h}_{\tilde{\tau}} = f_{\tilde{\tau}}(h_{\tilde{\tau}})S/\tilde{S}\)를 통해 normalize를 함으로써 구현할 수 있게됩니다. 이는 \(\sum \vartriangle h_t\)의 크기를 보존할 수 있습니다 (\( \vartriangle \tilde{h}_{\tilde{\tau}}=\vartriangle h_t S \)). 이를 통해 \(f_t\)를 어떤 subsequence, timestep length에도 상관없이 훈련시킬 수 있습니다. 뒤에 볼 Figure 6을 제외하고 모든 experiment에서 \(\vartriangle h_t\)를 얻기위해 \(f_t\)를 사용합니다.
Generative process design
이제까지는 asyrp의 h-space에 대해 다루었다면, 여기서는 전체적인 editing process 3단계에 대해 다루겠습니다. 이는 editing with Asyrp -> traditional denoising -> quality boosting형태로 이루어져있으며, 우리는 각각의 phase를 결정하기위한 quantifiable 요소에 대해 알아보겠습니다.
Editing process with asyrp

Diffusion model은 초반 stage에서 고차원적인 context정보를 학습하고, 더 높은 차원에서는 imperceptible fine details를 학습합니다 (Choi et al., 2022). 비슷하게 저자들은 generative process의 초기단계는 semantic changes를 잘 학습할 수 있도록 변경한다고 합니다. 저자들이 정한 해당 stage를 \([T, t_{edit}]\)으로 명명합니다.
LPIPS는 2개의 이미지의 유사도를 평가하기 위해 사용되는 지표중에 하나입니다.
비교할 2개의 이미지를, 각각 VGG에 넣고 중간 layer의 feature값들간의 similarity를 측정하여 평가지표로 활용합니다.
LPIPS(\(x\), \(\mathsf{P}_T\))와 LPIPS(\(x\), \(\mathsf{P}_t\))는 original image와 predicted image간의 perceptual distance를 각각 timestep \(T\), \(t\)에서 측정한 값입니다. 해당 지표의 의미는 reverse process에서 더 예측해야할 component의 크기를 의미합니다. 그리고 editing strength \([T, t]\)을 아래와같이 정의합니다.

Figure 3에서 LPIPS(\(x\), \(\cdot\))을 \(\mathsf{P}_t\), \(x_t\)에 대해 나타냈는데, 이들간의 inset이 editing strength를 의미합니다. 저자들은 일반적으로 가장 적은 editing interval을 통해 충분한 distinguishable한 change를 가져다줄 수 있는 editing inverval을 찾습니다. 경험적으로 \(t_{edit}\), LPIPS(\(x\), \(\mathsf{P}_{t_{edit}}\))\(=0.33\)이 가장 합당한 interval이라고 결정할 수 있다고 합니다.

하지만 몇개의 attribute는 일반적으로 더 많은 visual change를 필요로 합니다 (e.g., pixar > smile). 이러한 attribute에 대해서는 editing strength \(\xi\)를 \(\delta = 0.33d(E_T(y_{source}), E_T(y_{target}))\)로 하는데, 여기서 \(E_T(\cdot)\)은 \(y_{(\cdot)}\)에 대한 CLIP text embedding이며, \(d(\cdot , \cdot)\)은 인자간의 cosine distance를 의미합니다. 저자들은 \(t_{edit}\) attribute를 LPIPS(\(x\), \(\mathsf{P}_{t_{edit}}\))\(=0.33 - \delta\)로 확장해서 표현하기로 합니다.
Quality boosting with stochastic noise injection
DDIM이 stochasticity (\(\eta = 0\))으로 perfect inversion을 가능하게 했습니다. 다만, Karras et al.(2022)는 stochasticity가 image quality를 증가시킨다고 말합니다. 비슷하게, 저자들은 \([t_{boost}, 0]\)에 stochastic noise를 inject하고 이를 boosting interval이라고 명명합니다.
더 긴 boosting inverval은 higher quality로 이어지지만, 너무 과도하게 긴 interval은 content를 변형시킵니다. 그리하여, 저자들은 editing inverval과 비슷하게 quality boosting와 minimal content change를 보장하는 최소한의 구간을 결정하고자 합니다. image의 noise를 quality boosting의 용량이라고 생각하고 이를 quality deficiency라 하기로 합니다. (\(\gamma_t=LPIPS(x, x_t)\))와 같이 표현하는데, 이는 original image와 \(x_t\)간의 noise의 amount입니다. 여기서 \(\mathsf{P}_t\)대신 \(x_t\)를 사용했는데, 지금 상황에서는 semantic 보다 actual image에 대해 다루기 때문입니다. 저자들은 경험적으로 \(t_{boost}\) 를 \(\gamma t_{boost}=1.2\)가 가장 많은 일반적인 quality boosting과 가장 적은 content change를 제공했다 합니다. 그리고 이는, \([t_{boost}, 0]\)이 editing strength를 0.25보다 적음을 보장한다 합니다. Figure 3을 보면, \(t_{boost}\)이후에 \(LPIPS(x, x_t)\)가 날카롭게 drop한 반면, \(LPIPS(x, \mathsf{P}_t)\)는 적게 바뀌었음을 볼 수 있습니다. 저자들은 실험의 대부분의 quality degrade는 DDIM때문이지 Asyrp때문이 아니라고 합니다.

Experiments
첫번째 장 에서는 다양한 attribute, dataset, architecture에 대해서 h-space와 Asyrp의 효율성을 보여줍니다. 두번째 장에서는 quantitative 결과를 보여주고, 세번째 장에서는 h-space와 \(epsilon\)-space에서의 semantic latent space의 속성에 대해 분석합니다.

detail은 위에 설명한 내용입니다.
Versatility of h-space with Asyrp

기존의 U-Net 기반의 아키텍쳐와 다양한 dataset에 대해 Asyrp의 효율성을 보여줍니다. Asyrp은 training에서 보지 못했던 attribute도 synthesize할 수 있습니다 (church -> {department, factory, and temple}). 심지어 dogs에서 Poodle과 Yorkshire에 smiling을 synthesize했는데, 해당 종의 dataset에서는 찾아보기 힘든 그림입니다.

Figure 5를보면, 사람 이미지를 다양한 identities로 변경한 것을 보여줍니다. 이는 Asyrp의 Versatility는 놀라운데, 그 이유는 model을 바꾸지도 않고 inference단계에서 그저 h-space의 bottleneck feature map을 shift했는데, 이런 결과가 나오기 때문입니다.
Quantitative comparison
저자들의 방법은 별도의 finetuning없이 various diffusion model과 결합할 수 있습니다. 그럼에도 불구하고 Asyrp은 모든 모델을 finetuning시키는 DiffusionCLIP와 비교합니다.

해당 실험결과는 80명의 참가자들에게 40개의 original image set에 대해, 어떤게 더 quality 좋고 자연스럽게 synthesize했냐고 물어봤을때의 결과입니다. Table 1은 Asyrp이 DiffusionCLIP을 다방면에서 월등히 뛰어남을 보여줍니다. Appendix K에 더 많은 평가지표로 비교한 결과가 있습니다.
Analysis on h-space
저자들은 semantic latent space의 다양한 속성에 대해 분석합니다 (homogeneity, linearity, robustness, consistency across timesteps).
Homogenity

FIgure 6에서 h-space와 \(\epsilon\)-space에서의 homogenity를 비교한 결과입니다. 하나의 image에 대해 최적화된 \(\vartriangle h_t\)가 다른 input image에 적용된 결과를 보여줍니다. 또한, 하나의 이미지에 대해 최적화된 \(\vartriangle \epsilon_t\)가 다른 input image에 적용되면 이는 image distort를 발생시킵니다.

Figure 10을 보면, \(\vartriangle h_t^{mean}=\frac{1}{N}\sum \vartriangle_t^i\)가 random sample \(N=20\)에 대한 결과와 거의 비슷했음을 보여줍니다.
Linearity

Figure 7을 보면, \(\vartriangle h\)를 linearly scaling하면 이에 해당하는 크기만큼 visual attribute도 변함을 볼 수 있습니다. 놀랍게도 이는 negative scaling까지 적용됩니다.

더 나아가서 Figure 8을 보면, 서로 다른 \(\vartriangle h\)를 합치면 이는 두개의 semantic change를 한번에 표현할 수 있다는 결과를 볼 수 있습니다.
Robustness

Figure 9는 h-space와 \(\epsilon\)-space에 대해 random noise를 추가한 것에 대한 결과입니다. random noise는 h-space와 \(\epsilon\)-space에 대해 각각 random direction, random magnitude로 골라졌습니다. h-space에 Perturbation된 결과는 semantic change가 거의 없는 realistic image로 이어졌습니다. 반면에 \(\epsilon\)-space에 Perturbation된 결과이미지는 distort되는 결과를 볼 수 있습니다.
Consistency across timesteps

이전에 모든 샘플에 대한 \(\vartriangle h_t\)에 대해 \(\vartriangle h_t^{mean}\)을 사용해도 기존과 비슷한 결과를 나타냈다고 했습니다. 이번에는 저자들은 time-invariant한 \(\vartriangle h_{global}=\frac{1}{T_e}\sum_{t}\vartriangle h_t^{mean}\)를 \(\vartriangle h_t\)를 추가하게되면, 이 또한 비슷한 결과가 나옴을 볼 수 있었다 합니다 (\(T_e\)는 editing interval \([T, t_{edit}]\)). 즉 저자들은 best quality를 뽑을려면 \(\vartriangle h_t\)를 사용하는것이 좋고, \(\vartriangle h_t^{mean}\) or \(\vartriangle h^{global}\)을 일종의 타협점으로서 간단하게 뽑고싶을때 사용해도 괜찮다고 합니다.
'AIML > 딥러닝 최신 트렌드 알고리즘' 카테고리의 다른 글
| [ 딥러닝 코드 리뷰 - PRMI Lab ] - DDPM 코드 리뷰 및 실행 (0) | 2025.03.17 |
|---|---|
| [ 딥러닝 논문 리뷰 - PRMI Lab ] - COLMAP about SfM (Structure from Motion) (0) | 2025.03.13 |
| [ 딥러닝 코드 리뷰 - PRMI Lab] - NeRF Code 코드 분석하기 (0) | 2025.03.11 |
| [딥러닝 논문 리뷰 - PRML Lab] - 3D Gaussian Splatting (3D-GS) (0) | 2025.02.22 |
| [ 딥러닝 논문 리뷰 - PRMI Lab ] - DiT (Scalable Diffusion Models with Transformers) (0) | 2025.01.12 |