![[딥러닝 논문 리뷰 - PRML Lab] - 3D Gaussian Splatting (3D-GS) & code (tile rasterize)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FJk7h9%2FbtsMtsWuX89%2FCF7k5LO7qKU8i3SoXbS0kK%2Fimg.png)
이번에 볼 논문은 2023 SIGRAPH에서 소개된 3D Gaussian Splatting입니다. 복학 준비를 하면서 3D Vision관련 프로젝트나 연구분야를 설정하는 중에 NeRF보다 발전된(효율적인) 형태인 해당 논문을 발견했습니다. 그리고 이후 CVPR이나 top tier논문에서도 다양하게 발전하는 양상을 보고 리뷰하기로 했습니다. 이후에는 InstantNGP과 같은 관련 논문을 리뷰해볼 생각입니다.
논문 링크: https://arxiv.org/pdf/2308.04079
참고 블로그 링크: https://xoft.tistory.com/51
[논문 리뷰] 3D Gaussian Splatting (SIGGRAPH 2023) : 랜더링 속도/퀄리티 개선
3D Gaussian Splatting for Real-Time Radiance Field Rendering, Bernhard Kerbl, SIGGRAPH 2023 NeRF분야에서 뜨거운 이슈가 된 논문입니다. NeRF에서 해결하고자 하는 Task와 동일하게, 여러 이미지와 촬영 pose 값이 주어지
xoft.tistory.com
xoft님의 3D-GS가 가장 도움이 되었으며 생소한 3D Gaussian개념부터 구체적인 알고리즘을 상세히 분석할 수 있었습니다.

radiance field 방법론들은 여러개의 사진이나 비디오로부터, 새로운 view를 만들어 내는 방향으로 발전해왔습니다. 하지만 여전히 high-quality의 결과물을 만들기 위한 네트워크를 train, rendering하는데 많은 비용이 발생합니다. 해당 논문은 이러한 문제점을 일부 해결하고자 1080p, real-time (>= 30fps)에서 train, rendering하는 시간을 획기적으로 줄이기 위한, 3가지 key element를 소개합니다.
첫번째로 NeRF와 동일하게 SfM(Structure-from Motion)으로 Calibration된 카메라로부터 시작합니다. 그 후, SfM 프로세스로부터 생성된 sparse point cloud를 3D Gassian으로 초기화 합니다. 이전의 포인트 기반 솔루션들은 Multi-View Stero(MVS) 데이터가 필요했지만, 3D-GS는 SfM으로부터 생성된 point로만 고품질의 결과를 얻을 수 있습니다. 3D Gaussian을 통해 모든 volumetric 공간에 대해서 미분 가능하고 αα-blending을 통해 효율적으로 rasterization할 수 있습니다.
두번째로 3D 위치, α (불투명도), anistropic covariance (이방성 공분산), 뒤에서 볼 SH 계수(구면 조화 계수)와 같은 3D Gaussian의 속성을 interleaved optimization하는 것입니다. SH (Spherical Harmonic)는 Graphics에서 color값을 계산할 때 view-dependent한 특성을 고려하고자 할 때 사용되는 개념입니다.
세번째로 빠른 GPU 정렬 알고리즘을 통해 수행되는 tile-based rasterization입니다. 이를 통해 visibility order를 반영하는 anistropic splatting을 수행할 수 있으며 필요한 공유 메모리에 backward 계수들을 저장하여 빠른 backward pass가 가능해집니다.
이러한 3D-GS은 기존의 SOTA급 qualit를 뽑아낼 수 있고 real-time이 가능한 방법론이라고 할 수 있겠습니다. 더 자세한 방법은 아래에서 살펴보겠습니다.
Differentiable 3D Gaussian Splatting
sparse한 SfM의 기본요소부터 시작하려면 미분 가능한 체적표현이 가능하다는 속성을 상속하는 동시에 빠른 렌더링이 가능하도록 구조화되지 않고 명시적인 기본 요소가 필요하다고 합니다. 이를 위해 2D로 쉽게 splat할 수 있는 3D Gaussian을 사용하여 빠른 α-blending을 가능토록 했습니다.
점평균 μ를 중심으로 하고, Gaussian에 대한 covariance matrix인 3D Gaussian은 아래와 같이 정의됩니다.
이후에 w2c (word2cam)과 같은 행렬이 주어지면 camera space에서의 공분산 행렬 Σ′은 아래와 같이 정의됩니다.
위에서 J는 c2i (camera2image) 변환의 affine근사의 Jacobian입니다(Taylor Expansion으로 유도). 자세한 설명은 포스트 위에 첨부한 xoft님의 블로그를 참고하시면 됩니다. 여기서 재미있는 특성이 Σ′의 3번쨰 행,열을 없애버리면 2D상에 법선(normal)이 있는 점에서 시작하는 것과 같은 2x2 covariance matrix를 얻을 수 있다는 점입니다.
Equation(5)의 quadratic form에 대해서 잠깐 첨언하자면 J는 Jacobian (affine approximation) perspective projection이라고 했습니다. 이는 1st Talor approximation이기 때문에, Gaussian의 점평균에서 멀어질수록 approximation error가 생기는 것이 자명합니다. 최근에는 이러한 perspective error를 3D-GS의 한계로 제시하고 해결하려는 연구도 지속되고 있습니다. pixel space에서 쓰는 covariance matrix (2x2)에서는 z-axis를 쓰지 않기 떄문에, 아래와 같이 실제 cuda코드에 구현되어 있습니다.
이를 최적화 하기위한 명시적인 접근은 ∑을 direct로 최적화하는 것입니다. 하지만 covariance matrix의 특징중에 하나가 positive-definite일 때만 공간상에서 의미있는 특징을 가지는 것입니다. 이러한 상황에서 gradient descent를 사용하면 빈번하게 유효하지 않은 covariance matrix를 생성하게 되어 최적화가 힘들어 지게 될것입니다.
저자들은 이를 해결하고자 보다 표현력이 뛰어난 표현을 선택했습니다. Σ은 타원체의 구성을 설명하는 것과 유사한데, 따라서 scaling matrix인 S, rotation matrix인 R을 통해 Σ을 찾아낼 수 있습니다.
실제 구현에서는 rotation을 위한 행렬을 quaternion q로 별도로 지정합니다. 이들은 독립적으로 최적화되며, 이러한 최적화에 적합한 anistropic covariance matrix를 통해 3D Gaussian을 만들어내면 scene의 다양한 기하학적 구조에 적용할 수 있어 아래와 같이 매우 compact한 표현이 가능해집니다.
covariance matrix를 아래와 같이 약간 바꿔서 쓸 수 있습니다.
∑=RSSTRT=R[s21000s22000s23]RT
covariance matrix의 형태가 3D ellipsoid (anistropic) matrix와 같습니다. 즉 3D-GS는 3D상의 불투명한 타원체를 primitive kernel로 사용함을 알 수 있습니다.
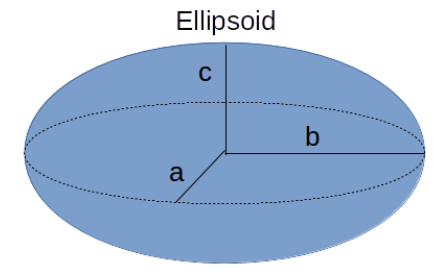
Quadratic form A−1MA를 다룰 때, M: transformation in A: coordinate system이라고 해석하면 좋습니다.
정방향 행렬에서, eigendecomposition을 해석할때와 비슷한데, 선형변환에도 방향이 보존되는 axis(eigenvectors)로 이루어진 coordinate system에서, 각 axis가 어느정도 가중치를 가지고 있는지 (eigenvalues)를 분석하는것기 eigendecomposition이기 때문입니다. 이는 또한, PCA와 관련됩니다.
3D Gaussian Splatting 완벽 분석 (feat. CUDA Rasterizer)
3D Gaussian Splatting 을 완벽하게 이해해보자!
velog.io
Density of the Projected Gaussian
3D Gaussian splatting은 실제 rendering시에 Gaussian density(강도)와 opacity를 곱해서 사용합니다. 실제 cuda 코드에서 사용되는 3D 공간 위의 점 p에 대한 ith Gaussian의 density fi(p)를 아래와 같이 정의합니다.
fi(p)=σ(αi)exp(−12(μi−p)TΣ−1i(μi−p))
exponential 안의 값은 Mahalanobis Distance(=power)인데, 이는 어떤 분포를 고려한 ellipsoid내에서의 실질 거리라고 볼 수 있습니다. 이는, 어떤 3D point를 2D로 projection했을때 해당 point가 pixel과 가까울수록, power값이 1에 가까워져 non-opaque해지는 직관적인 해석과 들어맞습니다.
또한, 실제 코드에서는 위의 Σ−1i이 positive semidefinite이기 때문에, small λ를 더해주어 아래와 같이 covariance matrix가 positive definite가 되도록 바꿔줍니다.
xTATAx+λxTx>0
그리고 실제 코드에서는 Σ−1를 conic이라고 명명합니다.
마지막으로 2D splat의 radius를 99.7%이상 cover 가능한
r=3×maxistandard deviationi
위와같이 정의해서, Gaussian culling용도로 사용합니다. 3D Gaussian의 standard deviation은 eigenvalue와 같으므로, Characteristic equation으로 구합니다. 실제 코드에서도 Characteristic equation는 closed form equation이여서 근의공식으로 풉니다.
Optimization
우선 3D to 2D의 변환은 투영이 모호하기 때문에 3D Gaussian이 잘못 배치될 수 있습니다. 그래서 최적화 단계에서 Gaussian을 잘못 배치한 경우 없애고 다시 생성할 수 있어야 합니다. 저자들은 α에 sigmoid를 사용했으며, covariance의 scale에는 exponential function을 사용했습니다.
저자들은 초기 Gaussian을 3D point상에 가장 가까운 세 점까지의 거리의 평균과 동일한 normal(법선)을 갖는 isotropic Gaussian으로 설정합니다. 또한, Plenoxels [Fridovich-Keil and Yu et al. 2022]과 비슷하게 exponential decay scheduling을 사용했지만 position만 제외했다고 합니다. Loss function은 L1과 구조적 동일성을 위한 D-SSIM을 결합한 식으로 구성됩니다. (초기 λ=0.2)
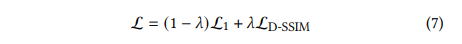
Adaptive Control of Gaussians
초기 sparse SfM부터 시작하여 adaptive하게 저자들의 방법대로 Gaussian의 수와 volume에 대한 밀도를 조절하여 더 장면을 잘 나타낼 수 있는 dense한 집합으로 이동할 수 있습니다. 저자들은 초기 warm-up 후 매 100 iteration마다 densify하고 α가 threshold인 ϵα보다 작은 것을 제거합니다.
3D Gaussian에 대한 adaptive control에서는 빈공간을 채워줘야 합니다. 이에 대해 2가지 상황이 있는데 첫번째로 기하학적 feature가 누락된 영역 (under-reconstruction)에 집중해야하고, 두번째로 기하학적 feature가 넓은 영역을 덥는 (over-reconstruction)에도 집중해야합니다. 이들은 large view-space gradient을 띄고 있는데 그 이유는 optimization과정에서 gaussian을 움직이려고 하기 때문입니다.
이러한 2가지 경우는 densification하기 좋은 후보군이기 때문에 평균 크기의 position gradient 가 τpos=0.0002이상이라면 densify합니다.
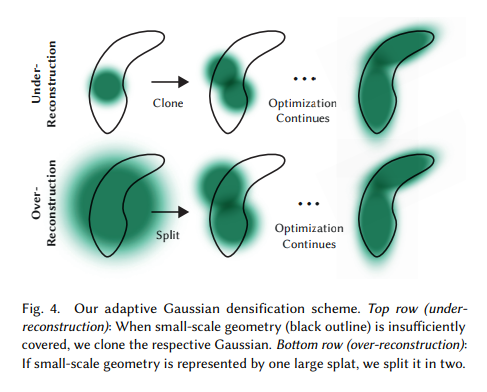
Under-Reconstruction의 경우에는 빈 공간에 새로운 Gaussian을 추가해주어야 한다. 이를 위해 동일한 크기의 복사본을 position gradient만큼 이동하여 배치합니다.
Over-Reconstruction의 경우는 큰 Gaussian을 작은 Gaussian으로 분할해야 합니다. 저자들은 실험적으로 설정한 scale parameter인 ϕ=1.6으로 새로운 Gaussian을 만듭니다. 또한, 큰 Gaussian을 sampling PDF로 사용해서 작은 Gaussian을 배치합니다.

pseudo code에 대한 부연설명. M, S, C, A등의 파라미터들은 매 iteration마다 update되지만, 초록색 부분은 100 iter마다 업데이트.
초록색 부분의 clone의 경우 Gaussian의 개수와 volume은 증가, split은 volume은 유지하면서 Gaussian은 증가하게 됨. 이 때문에 카메라의 가까운 영역에 floater들이 생기고 Gaussian들이 무작위로 증가하는 형태로 나타남.
이러한 과정은 입력 카메라의 floater를 만들어 정체될 수 있습니다. 저자들은 이를 해결하기 위해 N=3000 iter마다 α값을 0에 가까운 값으로 설정합니다 (M, S, C, A는 100iter동안 0이 아닌 값으로 변경될 것이고, 100iter 후에는 densify단계에서 RemoveGaussian으로 필요없는 Gaussian 삭제). 이를 통해 threshold보다 작은 값을 가지는 α를 제거하여 Gaussian에 대한 전체적인 α를 상승시킵니다. 또한, world space에서 큰 자리를 차지하는 gaussian을 주기적으로 제거하여 총 Gaussian의 수를 효과적으로 제어할 수 있다고 합니다 (큰 크기의 Gaussian이 중첩되는 경우도 방지). 유클리드 공간상에서 모든 3D Gaussian들은 기본 요소로서 존재하며 다른 방법론과 같이 공간 압축, 워핑, 투영등이 필요하지 않습니다.
이는 논문의 Appendix에 있는 Pseudo code입니다. 빨간색 부분은 변수 초기화, 파란색 부분은 inference후 loss계산 후 최적화 하는 부분, 초록색 부분은 위에서 언급한 Gaussian을 다루는 부분입니다. 파란색 부분에서 Rasterize부분이 보이는데 이제 이 부분에 대해 저자들이 어떻게 구현했는지 설펴보겠습니다.
Fast Differentiable Rasterizer for Gaussians

저자들은 이전 솔루션의 문제였던 α-blending에서의 픽셀당 정렬 비용의 문제를 피하기 위해 Gaussian splatting용 tile-based rasterizer를 소개합니다. 해당 rasterizer는 임의의 혼합된 gaussian에 대해 효율적인 역전파가 가능하고, 적은 추가적인 메모리 비용과 픽셀당 오버헤드가 일정하게 유지됩니다.
먼저 화면을 16x16의 tile로 나누고 (CreateTiles), view frustrum을 고려하여 각 tile에 대해 유효한 3D Gaussian을 선별하는 것으로 시작합니다. 이는 view frustrum과 99% 신뢰 구간의 Gaussian만 취하며 view frustrum에서 멀리 떨어진 extreme한 position을 개별적으로 제거하는 guard band를 사용합니다. (Cull Gaussian, pseucode상에서는 creat tiles가 후행됩니다)
겹치는 tile 수만큼 projection된 2D Gaussian을 instance화 합니다. 이렇게 생성된 instance들은 view space depth와 tile ID 쌍으로 조합하여 Key를 만듭니다. 그 후, Key로 Single GPU Radix Sort를 병렬적으로 수행하여, tile마다 2D splat에 대해 depth ordering을 수행합니다. 이를 통해 pseudo code상의 BlendInOrder에서 key를 기반으로 가까운 gaussian을 먼저 반영해 그릴 수 있습니다. 이로서 tile안에서 작은 pixel크기를 차지하는 gaussian들이 무시될 수 있었지만, 이로서 artifact가 적어지고 수렴이 잘 될 수 있었다고 합니다. 기존 방법들은 pixel마다의 정렬이 필요했지만, tile-based의 GPU Radix sort를 사용함으로서 병렬성이 늘어나고 amoritized(분할 상환)이 가능해져 장면을 표현하는데 사용하는 3D Gaussian의 수를 늘릴 수 있었습니다.
그 다음으로는 각 tile에 대한 list를 초기화합니다. 그 후 반복을 통해서 각 tile에 대해 list를 순회하면서 thread block을 만들어 Rasterization을 수행합니다. 각 thread block은 공동 메모리에 Gaussian의 패킷을 싹다 저장합니다. 그 후, 각 tile안의 pixel들에 대해 앞에서 만든 list를 순회하면서 color와 α를 누적하여 병렬처리를 진행합니다. 여기서 pixel의 α값이 target(saturation)에 도달하거나, 장기적으로 tile의 thread가 모두 쿼리되면, 해당 thread가 중지됩니다. 참고로 위에서 density of the projected gausian부분에서 설명한 방법대로 alpha-blending을 합니다.
해당 방법에서 α는 rasterization의 유일한 정지조건입니다. 또한, 이전 연구와 다르게 Rasterization동안의 gradient update하는 Gaussian(기본 요소)의 수를 제한하지 않았습니다. 이는 Depth Complexity를 다양화하고 scene에 따른 hyperparameter를 튜닝하지 않고도 임의의 scene을 커버할 수 있게되었습니다. 이를 빠르게 하려고 저자들은 공유 메모리에 픽셀당 accumulate된 임의의 list를 따로 저장하는 방법을 선택할 수 있었지만, 이에 대한 동적 메모리 관리 overhead를 피하기 위해 tile별 list를 다시 순회하도록 했습니다. 이는, Forward pass에서 정렬된 Gaussian의 list와 tile range를 재사용할 수 있기 때문입니다. backward pass(Gradient Update)에서는 기울기 계산의 용이성을 위해 뒤에서 앞으로 순회하게 됩니다.
순회는 tile안의 pixel에 영향을 준 가장 마지막 point(Gaussian)부터 시작하여 이를 공유 메모리에 로드하는 것이 공동으로 수행됩니다. 그리고 forward pass중에 해당 색상에 기여한 마지막 포인트보다 깊이가 낮거나 같은 경우에 overlap(expensive) 테스트와 포인트 처리를 진행합니다. backward pass에서는 original blending 프로세스에서 사용된 누적 opacity 값이 필요합니다. 저자들은 backward pass에서 점점 줄어드는 opacity list를 순회하는 대신 forward pass가 끝날때 누적된 total opacity를 저장하여 중간의 opacity를 복구할 수 있게됩니다. 또한, 각 point는 프로세스에서 끝난 total opacity를 저장하여 뒤에서 앞으로 순회할 때 각 포인트의 α로 나누어 gradient계산에 필요한 계수를 얻을 수 있습니다.
Fast Differentiable Rasterizer for Gaussians With Code
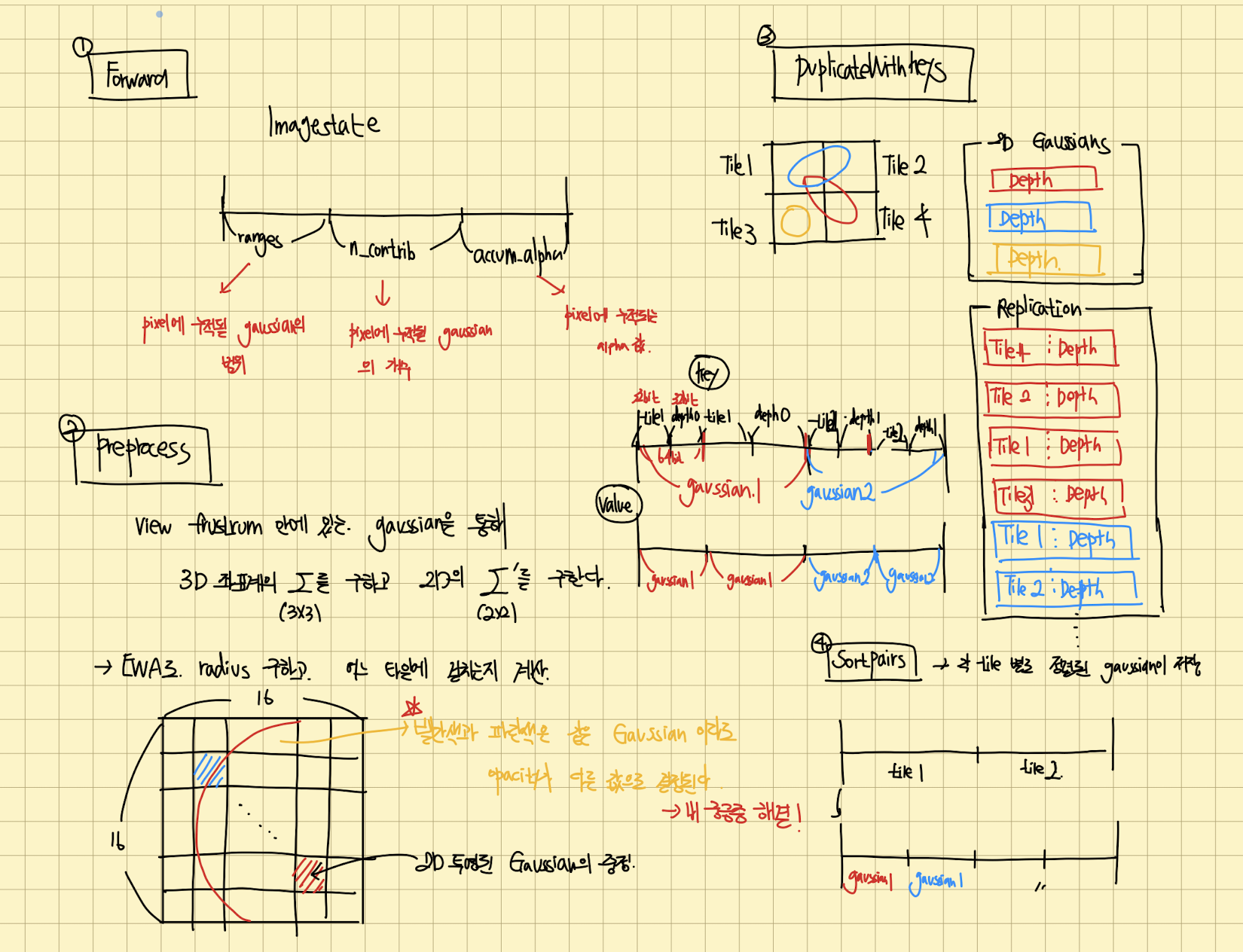
위에 설명한 fast rasterization을 그림과 코드로 간단하게나마 설명해보겠습니다.
참고: https://clean-dragon.tistory.com/16
Forward
Forward는 PreProcess -> duplicateWithkeys -> SortPairs -> identifyTileRanges -> Render순으로 이루어져 있습니다.
먼저 PreProcess전에 각 픽셀마다 render에 쓰일 정보가 저장될 메모리 공간을 할당합니다.
struct ImageState { uint2* ranges; uint32_t* n_contrib; float* accum_alpha; static ImageState fromChunk(char*& chunk, size_t N); };
- ranges: pixel에 누적될 gaussian의 범위
- n_contrib: pixel에 누적될 gaussian의 개수
- accum_alpha: pixel에 누적되는 alpha값
위에 설명에서, gaussian의 범위, 개수, 누적 alpha값을 개별 pixel처리에서 사용한다 했는데, 위와 같이 pixel 마다 저장한 것을 볼 수 있습니다.
PreProcess
const float* cov3D; if (cov3D_precomp != nullptr) { cov3D = cov3D_precomp + idx * 6; } else { computeCov3D(scales[idx], scale_modifier, rotations[idx], cov3Ds + idx * 6); cov3D = cov3Ds + idx * 6; } // Compute 2D screen-space covariance matrix float3 cov = computeCov2D(p_orig, focal_x, focal_y, tan_fovx, tan_fovy, cov3D, viewmatrix);
3D, 2D의 gaussian의 covariance matrix의 계산, 좌표의 계산, tile에 어느 gaussian이 겹쳐있는지 계산, gaussian의 opacity가 픽셀마다 얼마나 계산되어야 하는지 정합니다. 이는 view frustrum안에 있는 gaussian만을 골라내어 계산합니다.
그리고 EWA를 통해 gaussian의 radius를 구하고, 이 radius를 기준으로 gaussian이 어느 타일과 겹치는지 계산하며 gaussian의 평균과 픽셀의 거리마다 opacity가 다르게 적용할 수 있는 conic이라는 matrix를 계산합니다.
DuplicateWithKeys
duplicateWithKeys << <(P + 255) / 256, 256 >> > ( P, geomState.means2D, geomState.depths, geomState.point_offsets, binningState.point_list_keys_unsorted, binningState.point_list_unsorted, radii, tile_grid) CHECK_CUDA(, debug)
PreProcess에서 계산된 radius를 통해, gaussian과 겹친 tile의 id(32 bit), depth(32 bit)를 key에 저장합니다. 그리고 gaussian의 값을 value에 저장합니다 (겹친 tile만큼)
SortPairs
위에서 구한 key, value를 통해 radix sort를 이용해 정렬합니다. 이를 통해 tile별로 depth마다 정렬되어있는 gaussian들이 저장됩니다.
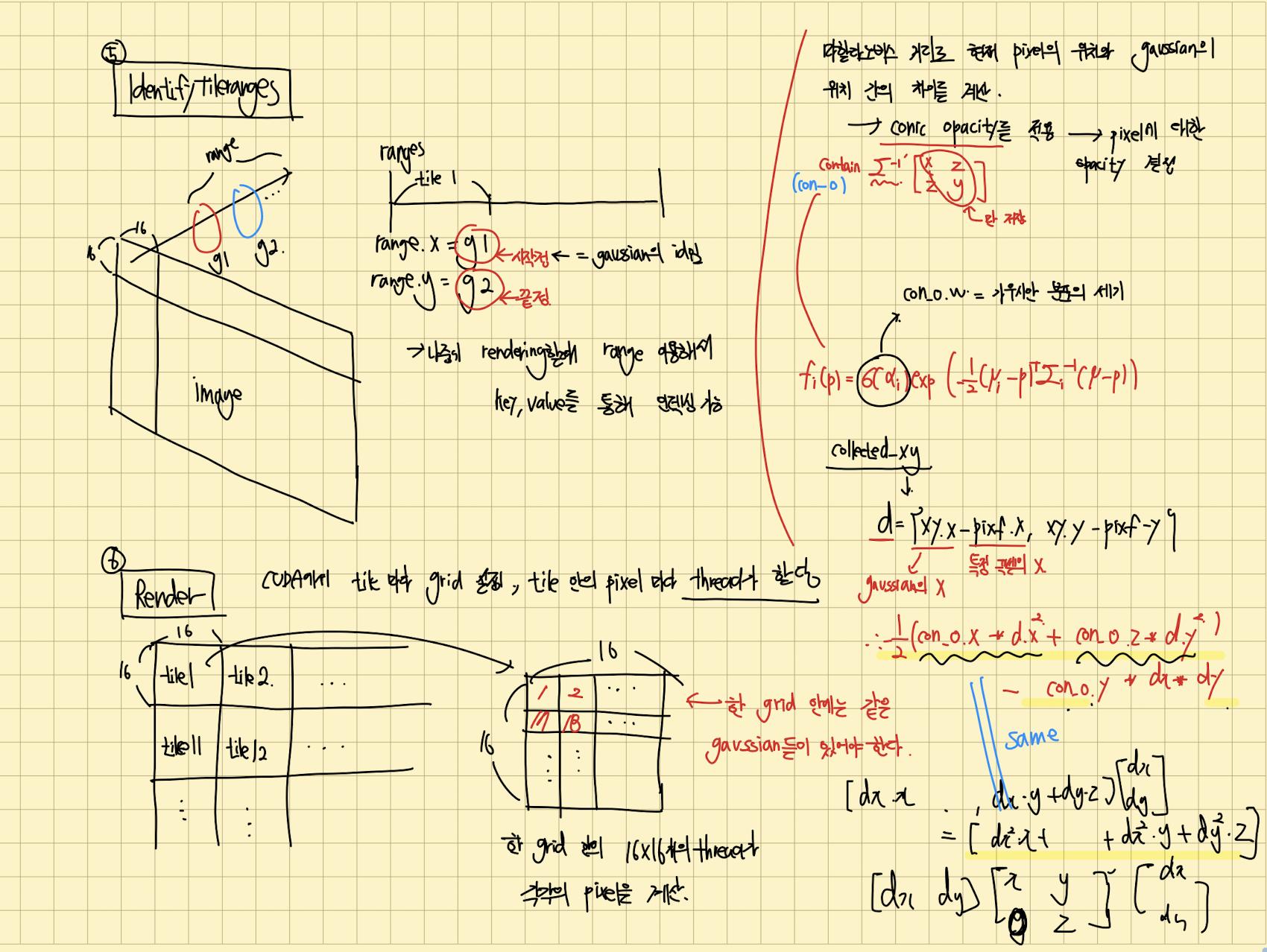
identifyTileranges
위에 정렬한 key, value를 가지고 tile마다 gaussian의 ID의 시작과 끝을 저장합니다. 여기서 저장한 range를 통해 나중에 rendering할때 range를 이용해 key, value를 통해 gaussian을 인덱싱할 수 있습니다.
Render
위에서 말했듯 Gaussian을 이용해서 이미지를 rendering할 때, CUDA에서 tile마다 thread block을 설정하고, tile 안에 pixel마다 thread가 할당됩니다.
renderCUDA<NUM_CHANNELS> << <grid, block >> > ( ranges, point_list, W, H, means2D, colors, conic_opacity, final_T, n_contrib, bg_color, out_color);
먼저 위와같은 renderCUDA()를 호출하는 부분을 보겠습니다. 인자로 앞서 계산한 정보와 gaussian parameter정보를 받습니다.
auto block = cg::this_thread_block(); uint32_t horizontal_blocks = (W + BLOCK_X - 1) / BLOCK_X; uint2 pix_min = { block.group_index().x * BLOCK_X, block.group_index().y * BLOCK_Y }; uint2 pix_max = { min(pix_min.x + BLOCK_X, W), min(pix_min.y + BLOCK_Y , H) }; uint2 pix = { pix_min.x + block.thread_index().x, pix_min.y + block.thread_index().y }; uint32_t pix_id = W * pix.y + pix.x; float2 pixf = { (float)pix.x, (float)pix.y }; // Check if this thread is associated with a valid pixel or outside. bool inside = pix.x < W&& pix.y < H; // Done threads can help with fetching, but don't rasterize bool done = !inside; // Load start/end range of IDs to process in bit sorted list. uint2 range = ranges[block.group_index().y * horizontal_blocks + block.group_index().x]; const int rounds = ((range.y - range.x + BLOCK_SIZE - 1) / BLOCK_SIZE); int toDo = range.y - range.x;
Block ID와 thread ID를 계산하고, 각 pixel마다 thread별로 계산하도록 위치를 정합니다. 그리고 identifyTileranges에서 계산한 ranges를 이용해 tile내의 gaussian의 범위를 가져옵니다. 이 행위는 thread를 이용해서 gaussian을 병렬적으로 인덱싱합니다.
여기서는 16x16개의 thread를 사용하는데, thread로 한번에 가져올 수 있는 gaussian의 개수는 최대가 256개입니다. 그래서 rounds를 계산하여, 256개 이상의 gaussian이 tile안에 있다면 계속 인덱싱 하여 가져올 수 있게 합니다. 위의 상황에서 toDo=300인데, BLOCK_SIZE=256이면 for문을 2번 돌면 그만인 것입니다.
__shared__ int collected_id[BLOCK_SIZE]; __shared__ float2 collected_xy[BLOCK_SIZE]; __shared__ float4 collected_conic_opacity[BLOCK_SIZE];
위 shared는 grid내의 각 thread끼리 공유하는 공유 메모리를 할당하는 부분입니다.
for (int i = 0; i < rounds; i++, toDo -= BLOCK_SIZE) { // End if entire block votes that it is done rasterizing int num_done = __syncthreads_count(done); if (num_done == BLOCK_SIZE) break; // Collectively fetch per-Gaussian data from global to shared int progress = i * BLOCK_SIZE + block.thread_rank(); if (range.x + progress < range.y) { int coll_id = point_list[range.x + progress]; collected_id[block.thread_rank()] = coll_id; collected_xy[block.thread_rank()] = points_xy_image[coll_id]; collected_conic_opacity[block.thread_rank()] = conic_opacity[coll_id]; } block.sync(); // Iterate over current batch for (int j = 0; !done && j < min(BLOCK_SIZE, toDo); j++) { // Keep track of current position in range contributor++; // Resample using conic matrix (cf. "Surface // Splatting" by Zwicker et al., 2001) float2 xy = collected_xy[j]; float2 d = { xy.x - pixf.x, xy.y - pixf.y }; float4 con_o = collected_conic_opacity[j]; float power = -0.5f * (con_o.x * d.x * d.x + con_o.z * d.y * d.y) - con_o.y * d.x * d.y; if (power > 0.0f) continue; // Eq. (2) from 3D Gaussian splatting paper. // Obtain alpha by multiplying with Gaussian opacity // and its exponential falloff from mean. // Avoid numerical instabilities (see paper appendix). float alpha = min(0.99f, con_o.w * exp(power)); if (alpha < 1.0f / 255.0f) continue; float test_T = T * (1 - alpha); if (test_T < 0.0001f) { done = true; continue; } // Eq. (3) from 3D Gaussian splatting paper. for (int ch = 0; ch < CHANNELS; ch++) C[ch] += features[collected_id[j] * CHANNELS + ch] * alpha * T; T = test_T; // Keep track of last range entry to update this // pixel. last_contributor = contributor; } }
해당 부분은 병렬처리를 하는 부분입니다. 현재 pixel의 위치와 gaussian의 위치 간의 차이를 계산하고, 그 계산한 결과에 conic_opacity를 적용하여, 최종적으로 pixel에 대한 opacity를 계산합니다. 그 후, density(gaussian intensity)를 opacity와 곱하여 alpha를 만들어내며, alpha blending식을 통해 pixel에 대한 color를 계산합니다.
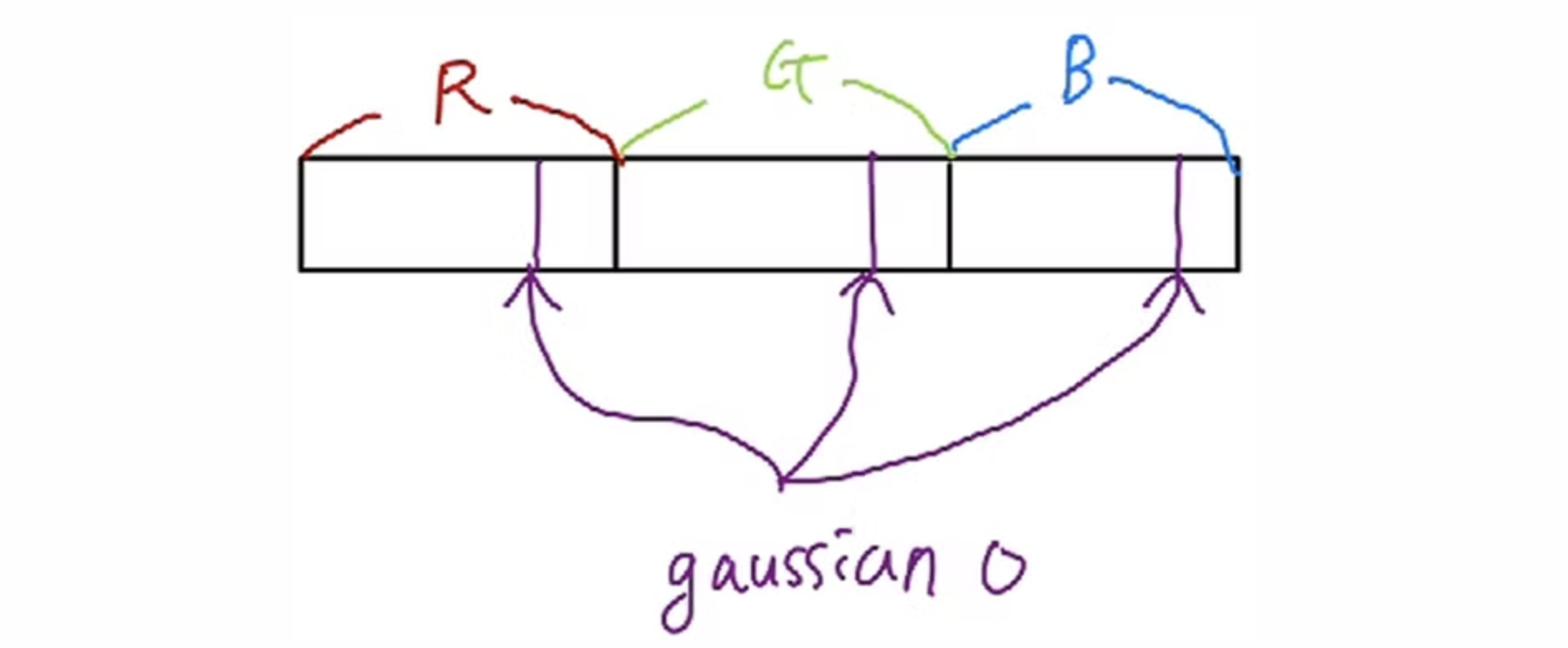
그리고 gaussian의 color가 저장된 메모리로부터 gaussian의 ID를 이용해 color값을 위와같은 형태로 저장합니다. 위 과정을 tile안에 있는 gaussian마다 반복합니다.
cuda코딩도 시간날때 짬짬히 봐둬야겠습니다..
Experiment
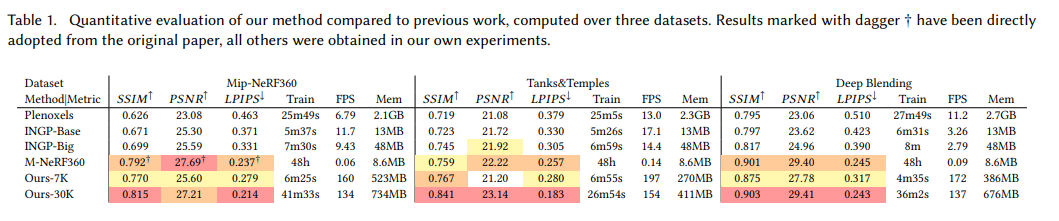
이전 연구와 정량적 연구 결과입니다.

다른 연구와의 비교 그림입니다.
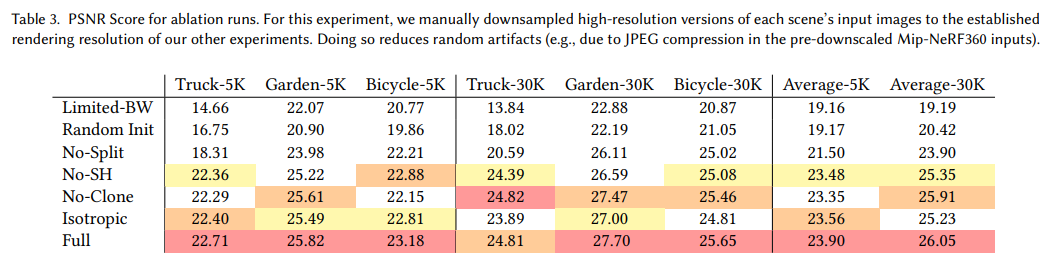
이는 SfM 초기화 설정에 대한 ablation study입니다.
하지만 3D-GS방법은 장면이 잘 보이지 않는 구역에서 artifact가 관찰된다던지, 학습 중에 본 뷰와 겹치지 않는 뷰에서 artifact가 관찰된다는 한계점이 존재합니다.