![[ 딥러닝 코드 리뷰 - PRMI Lab] - NeRF Code 코드 분석하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FezSZDa%2FbtsMIM0KVDk%2FAAAAAAAAAAAAAAAAAAAAAIaoDq47WcHOvtZlKwdoMejM5jdnuPV4QG36kKcNjizv%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3Dg8oA%252Bq0xTR%252BILO%252FXY0F6dzkrV4M%253D)
https://github.com/yenchenlin/nerf-pytorch
GitHub - yenchenlin/nerf-pytorch: A PyTorch implementation of NeRF (Neural Radiance Fields) that reproduces the results.
A PyTorch implementation of NeRF (Neural Radiance Fields) that reproduces the results. - yenchenlin/nerf-pytorch
github.com
https://arxiv.org/abs/2003.08934
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
We present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views. Our algorithm represents a scene using a fully-con
arxiv.org
[ 3D Vision - Study ] - Nerual Fields and 3D Representations — 현서의 개발 일지📚
[ 3D Vision - Study ] - Nerual Fields and 3D Representations
3D Vision Study의 목표는 NeRF를 한번 접해보기 위함이였습니다. NeRF는 ECCV 2020(oral)로서 best paper상을 받은 주인공이며, 그만큼 파급력이 높은 기술임을 알 수 있습니다. 당시에 최고의 complex view synthes
hyunseo-fullstackdiary.tistory.com
NeRF에서 사용하는 Dataset에는 llff, deepvoxel, blender("Realistic Synthetic 360") 등이 있는데 여기서는 llff기준으로 분석하겠습니다. 각 데이터셋은 Lambertian reflect등의 특성 등과 다양한 camera view등과 같은 차이가 있습니다.
DataLoader
def train():
parser = config_parser()
args = parser.parse_args()
# Load data
K = None
if args.dataset_type == 'llff':
images, poses, bds, render_poses, i_test = load_llff_data(args.datadir, args.factor,
recenter=True, bd_factor=.75,
spherify=args.spherify)
hwf = poses[0,:3,-1]
poses = poses[:,:3,:4]
# poses [20, 3, 4] -> extrinsic matrix
print("poses: llff", poses.shape)
# images [20, 378, 504, 3], render_poses [120, 3, 5], hwf, 1dim vector [378. 504. 407.5658], ./data/nerf_llff_data/fern
print('Loaded llff', images.shape, render_poses.shape, hwf, args.datadir)
# render_poses는 c2w matrix
if not isinstance(i_test, list):
i_test = [i_test]
if args.llffhold > 0:
# llff에서 자동으로 test데이터셋 분리
print('Auto LLFF holdout,', args.llffhold)
i_test = np.arange(images.shape[0])[::args.llffhold]
i_val = i_test
i_train = np.array([i for i in np.arange(int(images.shape[0])) if
(i not in i_test and i not in i_val)])
print('DEFINING BOUNDS')
if args.no_ndc:
near = np.ndarray.min(bds) * .9
far = np.ndarray.max(bds) * 1.
else:
near = 0.
far = 1.
print('NEAR FAR', near, far)
llff 데이터셋에 대해서 load_llff_data를 통해 images, poses, bds, render_poses, i_test를 가져옵니다.
- images: 이미지 데이터입니다.
- images는 [20, 378, 504, 3] 크기로, 378x504x3크기의 이미지이고, 20장의 이미지가 있습니다.
- poses
- poses를 각각 hwf, poses로 다시 분해하여 hwf(height, width, focal_length)와 poses(extrinsic matrix)로 분해합니다. poses는 3x4 extrinsic matrix입니다. (c2w matrix)
- render_poses: rendering할때 사용할 camera pose정보입니다.
- render_poses는 [120, 3, 5]로 120개의 3x5 matrix인데, 앞부분의 3x4 matrix는 render에 필요한 extrinsic matrix정보입니다.
- near, far
- bds(경곗값)을 이용하여 0.9, 0.1로 near, far값을 정하여 ray에서 point 샘플링할 최소 최대 깊이를 정합니다.
- ndc를 적용한다면 1, 0으로 설정하여 진행합니다.
- i_train, i_val, i_test
- train, validation, test에 해당하는 index list입니다.
Ray
# Ray helpers
def get_rays(H, W, K, c2w):
print('c2w.shape ', c2w.shape)
print('c2w: ', c2w)
i, j = torch.meshgrid(torch.linspace(0, W-1, W), torch.linspace(0, H-1, H)) # pytorch's meshgrid has indexing='ij'
i = i.t()
j = j.t()
# i [378, 504], j [378, 504]
print('chekc i, j', i.shape, j.shape)
print(i, '\n', j)
# dirs [378, 504, 3]
# pixel좌표계에 있는 pixel들을 normalized plane으로 옮긴 결과 --> (z-plane = 1) 3d vector
# [X, Y, Z] -> [X, -Y, -Z]: OpenCV -> COLMAP이 사용하는 coordinate system이 다르기 떄문
dirs = torch.stack([(i-K[0][2])/K[0][0], -(j-K[1][2])/K[1][1], -torch.ones_like(i)], -1)
print('dirs.shape', dirs.shape)
print(dirs)
# Rotate ray directions from camera frame to the world frame
# dir들을 c2w행렬과 dot-product하여 world-coordinate로 변환해준다
rays_d = torch.sum(dirs[..., np.newaxis, :] * c2w[:3,:3], -1)
rays_o = c2w[:3,-1].expand(rays_d.shape)
print('check ray', rays_d.shape, rays_o.shape)
print(rays_d, '\n', rays_o)
return rays_o, rays_dget_rays함수를 통해 normalized plane(z-plane=1)에 있는 vector를 world좌표계에 대해서 표현한 ray를 만들어 줍니다.
- dirs [378, 504, 3]
- COLMAP type의 normalized plane을 meshgrid와 K(intrinsic matrix)를 통해서 구해줍니다.
- rays_d
- dirs [378, 504, 3]와 c2w[:3. :3] (3x3 rotation matrix R)을 dot-product하여 [378, 504, 3]의 direction matrix를 구합니다.
- rays_o
- c2w[:3, -1] (3x1 translation matrix t)을 추출합니다.
그 외에도 get_rays_np는 numpy에 대해서 다시 쓴 함수입니다. 추후에 rays_d + rays_o를 하면, 카메라를 기준으로한 normalized plane이 world 좌표계 상에서 좌표값이게 됩니다. 그리고 rays_d * depth + rays_o 처럼 depth값을 주게되면 NeRF논문상에서의 Stratified Sampling도 구현할 수 있습니다.
# render안에서 batchify_rays를 하고 그 안에서 배치마다 render_rays를 한다.
def render(H, W, K, chunk=1024*32, rays=None, c2w=None, ndc=True,
near=0., far=1.,
use_viewdirs=False, c2w_staticcam=None,
**kwargs):
"""Render rays
Args:
H: int. Height of image in pixels.
W: int. Width of image in pixels.
focal: float. Focal length of pinhole camera.
chunk: int. Maximum number of rays to process simultaneously. Used to
control maximum memory usage. Does not affect final results.
rays: array of shape [2, batch_size, 3]. Ray origin and direction for
each example in batch.
c2w: array of shape [3, 4]. Camera-to-world transformation matrix.
ndc: bool. If True, represent ray origin, direction in NDC coordinates.
near: float or array of shape [batch_size]. Nearest distance for a ray.
far: float or array of shape [batch_size]. Farthest distance for a ray.
use_viewdirs: bool. If True, use viewing direction of a point in space in model.
c2w_staticcam: array of shape [3, 4]. If not None, use this transformation matrix for
camera while using other c2w argument for viewing directions.
Returns:
rgb_map: [batch_size, 3]. Predicted RGB values for rays.
disp_map: [batch_size]. Disparity map. Inverse of depth.
acc_map: [batch_size]. Accumulated opacity (alpha) along a ray.
extras: dict with everything returned by render_rays().
"""
if c2w is not None:
# special case to render full image
rays_o, rays_d = get_rays(H, W, K, c2w)
else:
# use provided ray batch
rays_o, rays_d = rays
# viewdirs는 카메라의 pose를 나타낸다. MLP의 입력으로 들어가는 view direction
# 원래라면 (phi, theta)값을 넣어주어야 하지만, rays_d값을 normalize해주어 3개의 변수로 구성되어있음
if use_viewdirs:
# provide ray directions as input
viewdirs = rays_d
if c2w_staticcam is not None:
# special case to visualize effect of viewdirs
rays_o, rays_d = get_rays(H, W, K, c2w_staticcam)
viewdirs = viewdirs / torch.norm(viewdirs, dim=-1, keepdim=True)
viewdirs = torch.reshape(viewdirs, [-1,3]).float()
print('viewdirs: ', viewdirs)
sh = rays_d.shape # [..., 3]
if ndc:
# for forward facing scenes
rays_o, rays_d = ndc_rays(H, W, K[0][0], 1., rays_o, rays_d)
# Create ray batch
rays_o = torch.reshape(rays_o, [-1,3]).float() # [378, 504, 3] -> [190512, 3]
rays_d = torch.reshape(rays_d, [-1,3]).float()
# 1로 채워놓음
near, far = near * torch.ones_like(rays_d[...,:1]), far * torch.ones_like(rays_d[...,:1])
# [190512, 8] -> 3(rays_o) + 3(rays_d) + 2(near + far)
rays = torch.cat([rays_o, rays_d, near, far], -1)
# use_viewdirs=True -> view direction을 입력으로 사용함.
if use_viewdirs:
rays = torch.cat([rays, viewdirs], -1)
# rays: [190512, 11]
print('rays shape: ', rays.shape)
# Render and reshape -> for OOM
# all_ret: rendering 결괏값을 가지고 있는 배열
all_ret = batchify_rays(rays, chunk, **kwargs)
for k in all_ret:
k_sh = list(sh[:-1]) + list(all_ret[k].shape[1:])
all_ret[k] = torch.reshape(all_ret[k], k_sh)
k_extract = ['rgb_map', 'disp_map', 'acc_map']
ret_list = [all_ret[k] for k in k_extract]
ret_dict = {k : all_ret[k] for k in all_ret if k not in k_extract}
return ret_list + [ret_dict]이제 ray를 render해야합니다. 이를 위해 batchify_rays()를 render함수 안에서 호출합니다. batchify_rays의 출력값은 rendering 결괏값을 가지고 있는 배열입니다.
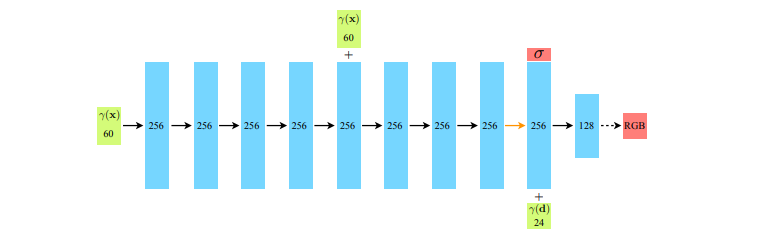
- use_viewdirs
- 학습할때 view direction을 사용하겠다는 의미입니다.
- view_dirs
- view direction은 카메라의 pose를 의미합니다. 원래 paper에는 spherical coordinate로 \((\theta, \phi)\)로 표현하였으나, normalized된 rays_d를 사용하여 3개의 변수로 진행됩니다.
- chunk
- chunk는 batchify_rays에서 minibatch를 구성할때 쓰는 단위입니다.
def batchify_rays(rays_flat, chunk=1024*32, **kwargs):
"""Render rays in smaller minibatches to avoid OOM.
"""
all_ret = {}
for i in range(0, rays_flat.shape[0], chunk):
# ray_flat을 입력으로, ray위에 있는 voxel들의 color와 volume density를 출력으로 갖는 함수.
ret = render_rays(rays_flat[i:i+chunk], **kwargs)
# chunk 크기만큼 batch로 구성하여, render_rays함수를 수행한 후, 결과값을 all_ret이라는 자료구조에 저장하는 코드드
for k in ret:
if k not in all_ret:
all_ret[k] = []
all_ret[k].append(ret[k])
all_ret = {k : torch.cat(all_ret[k], 0) for k in all_ret}
return all_retbatchify_rays는 ray를 rendering할때 OOM을 방지하기 위해 minibatch를 구성하고 결괏값을 저자가 정의한 자료구조에 저장하는 함수입니다
Coarse Sampling
def render_rays(ray_batch,
network_fn,
network_query_fn,
N_samples,
retraw=False,
lindisp=False,
perturb=0.,
N_importance=0,
network_fine=None,
white_bkgd=False,
raw_noise_std=0.,
verbose=False,
pytest=False):
"""Volumetric rendering.
Args:
ray_batch: array of shape [batch_size, ...]. All information necessary
for sampling along a ray, including: ray origin, ray direction, min
dist, max dist, and unit-magnitude viewing direction.
network_fn: function. Model for predicting RGB and density at each point
in space.
network_query_fn: function used for passing queries to network_fn.
N_samples: int. Number of different times to sample along each ray.
retraw: bool. If True, include model's raw, unprocessed predictions.
lindisp: bool. If True, sample linearly in inverse depth rather than in depth.
perturb: float, 0 or 1. If non-zero, each ray is sampled at stratified
random points in time.
N_importance: int. Number of additional times to sample along each ray.
These samples are only passed to network_fine.
network_fine: "fine" network with same spec as network_fn.
white_bkgd: bool. If True, assume a white background.
raw_noise_std: ...
verbose: bool. If True, print more debugging info.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray. Comes from fine model.
disp_map: [num_rays]. Disparity map. 1 / depth.
acc_map: [num_rays]. Accumulated opacity along each ray. Comes from fine model.
raw: [num_rays, num_samples, 4]. Raw predictions from model.
rgb0: See rgb_map. Output for coarse model.
disp0: See disp_map. Output for coarse model.
acc0: See acc_map. Output for coarse model.
z_std: [num_rays]. Standard deviation of distances along ray for each
sample.
"""
N_rays = ray_batch.shape[0] # ray의 개수
rays_o, rays_d = ray_batch[:,0:3], ray_batch[:,3:6] # [N_rays, 3] each
viewdirs = ray_batch[:,-3:] if ray_batch.shape[-1] > 8 else None
bounds = torch.reshape(ray_batch[...,6:8], [-1,1,2])
near, far = bounds[...,0], bounds[...,1] # [-1,1]
# N_samples: 64
# 0~1사이에 N_samples 갯수만큼 균일하게 나누어진 실수값을 가짐
t_vals = torch.linspace(0., 1., steps=N_samples)
if not lindisp: # lindisp -> inverse depth
z_vals = near * (1.-t_vals) + far * (t_vals)
else:
# 카메라에서 point가 떨어진 깊이를 저장하는 변수 -> lindisp=False: z_vals는 거리
# [near, far] 균일한 값을 저장하게 됨 -> 내분을 이용한듯
z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))
z_vals = z_vals.expand([N_rays, N_samples])
# perturb은 stratified sampling에 해당됨.
# i번째 point위치와 i+1번째 point위치 사이의 랜덤한 위치를 선택하는 sampling 알고리즘
if perturb > 0.:
# get intervals between samples
mids = .5 * (z_vals[...,1:] + z_vals[...,:-1])
upper = torch.cat([mids, z_vals[...,-1:]], -1)
lower = torch.cat([z_vals[...,:1], mids], -1)
# stratified samples in those intervals
t_rand = torch.rand(z_vals.shape)
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
t_rand = np.random.rand(*list(z_vals.shape))
t_rand = torch.Tensor(t_rand)
z_vals = lower + (upper - lower) * t_randrenders_ray의 앞부분입니다. 이는 실제로 Volumetric rendering을 하는 함수입니다. 이전에 rays에 [.., 11]로 묶었던 배열을 다시 푸는 것으로 시작합니다.
- N_rays
- Ray의 개수입니다. 보통 1024
- N_samples
- 하나의 ray에서 sampling (Coarse Sampling)할 sample의 개수로 config/fern.txt에는 64로 설정되어 있습니다.
- t_vals
- [0, 1]을 N_samples만큼 균일하게 나누어진 배열입니다.
- z_vals
- 카메라에서 실제로 point(sampled)가 떨어진 거리를 의미합니다. 만약 lndsip(=inverse-depth)=True이면 inverse depth를 저장하고 False이면 해당 값이 실제로의 depth를 의미합니다. 여기서 [near, far]에서 균일하게 자른 값을 저장합니다.
마지막에 perturb > 0.인 경우에 실행하는 분기는 NeRF의 stratified sampling을 수행하는 과정입니다. mids, upper, lower를 이용하여 t_rand([0. 1] 난수)를 통해 lower + (upper - lower) * t_rand를 통해 stratified sampling을 수행해줍니다.
# 주어진 image plane에서 주어진 Camera pose로 ray를 그렸을 때, world 좌표계에서 Voxel point좌표를 알 수 있음
# 논문에서도 o(rays_o) + t(z_vals)d(rays_d)
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples, 3]위에서 구한 z_vals로 부터 rays_o + rays_d * (depth = z_vals)를 수행해서 sampling할 point의 좌표를 pts에 저장합니다. [N_rays, N_samples, 3]
Fine Sampling
raw = network_query_fn(pts, viewdirs, network_fn)
# raw: prediction from model
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
# finesampling할 개수
if N_importance > 0:
rgb_map_0, disp_map_0, acc_map_0 = rgb_map, disp_map, acc_map
# coarse_sampling에서 만든 z_val에서 깊이 중간값을 가져옴
z_vals_mid = .5 * (z_vals[...,1:] + z_vals[...,:-1])
# sample_pdf함수를 통해 앞선 weight를 이용해서, inverse translation sampling을 진행한다.
z_samples = sample_pdf(z_vals_mid, weights[...,1:-1], N_importance, det=(perturb==0.), pytest=pytest)
z_samples = z_samples.detach()
z_vals, _ = torch.sort(torch.cat([z_vals, z_samples], -1), -1)
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples + N_importance, 3]
run_fn = network_fn if network_fine is None else network_fine
# raw = run_network(pts, fn=run_fn)
# network_query_fn은 pts와 view direction을 입력으로 하여, raw라는 출력값을 갖는 MLP함수
# Network의 결괏값을 post process없이 그대로 출력해서 raw라는 변수명을 붙임임
# 두번째 network_query_fn: fine network
raw = network_query_fn(pts, viewdirs, run_fn)
# raw2outputs은 raw를 입력으로 하여, rgb_map, disp_map, acc_map, weights, depth_map형태로 변환하는 후처리 함수.
# NeRF논문에서 volume rendering수식이 들어가는 부분분
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
ret = {'rgb_map' : rgb_map, 'disp_map' : disp_map, 'acc_map' : acc_map}
if retraw:
ret['raw'] = raw
if N_importance > 0:
ret['rgb0'] = rgb_map_0
ret['disp0'] = disp_map_0
ret['acc0'] = acc_map_0
ret['z_std'] = torch.std(z_samples, dim=-1, unbiased=False) # [N_rays]
for k in ret:
if (torch.isnan(ret[k]).any() or torch.isinf(ret[k]).any()) and DEBUG:
print(f"! [Numerical Error] {k} contains nan or inf.")
return retcoarse sampling에서 만든 point들을 NeRF 모델에 넣고 weight를 구한뒤, inverse transform sampling을 통해 실제로 유의미한 weight의 sample을 추출합니다.
network_query_fn으로 raw한 결괏값을 뽑아내고, raw2outputs으로 유의미한 결괏값들을 만듭니다.
- N_importance
- N_sample과 비슷하게 1개의 ray상에서 fine sampling할 sample의 개수를 의미합니다. (llff에서는 n_sample과 동일하게 64로 지정합니다.)
- z_vals_mid
- corase_sampling에서 만든 z_val에서 중간값을 가져옵니다.
- sample_pdf (inverse transform sampling)
- corase sampling을 통해 구해진 weight(volume density)를 가지고 cumulate pdf를 통해 inverse transform sampling을 해 fine sampling을 수행합니다.
- network_query_fn
- pts와 view direction을 입력으로 raw(rgb, alpha)값을 뽑아내는 MLP입니다.
- raw2outputs
- raw를 postprocess하여 rgb_map, disp_map, acc_map, weights, depth_map으로 변환해주는 함수입니다. 실제로 volume rendering수식이 들어가는 부분입니다.
fine sampling한 z_samples에 corase sampling한 z_vals를 합친 후 정렬해 z_vals를 만듭니다. 그리고 이를 통해 실제 rays_o + rays_d * z_vals를 통해 sampling할 point정보를 구합니다.
또 다시 network_query_fn, raw2outputs를 통해 rgb값과 동시에 유의미한 정보를 뽑아냅니다. 그 후, ret에 각각의 유의미한 정보를 dictionary 형태로 저장합니다.

Render Path (inference)
# inference에 사용되는 rendering 코드드
def render_path(render_poses, hwf, K, chunk, render_kwargs, gt_imgs=None, savedir=None, render_factor=0):
H, W, focal = hwf
if render_factor!=0:
# Render downsampled for speed
H = H//render_factor
W = W//render_factor
focal = focal/render_factor
rgbs = []
disps = []
t = time.time()
for i, c2w in enumerate(tqdm(render_poses)):
print(i, time.time() - t)
t = time.time()
# render()를 통해 rgb, disp, acc를 갖는다.
# rgb: 최종 결과 image map
# disp: disparity map으로써 inverse of depth
# acc: accumulated opacity(alpha)
rgb, disp, acc, _ = render(H, W, K, chunk=chunk, c2w=c2w[:3,:4], **render_kwargs)
rgbs.append(rgb.cpu().numpy())
disps.append(disp.cpu().numpy())
if i==0:
print(rgb.shape, disp.shape)
"""
if gt_imgs is not None and render_factor==0:
p = -10. * np.log10(np.mean(np.square(rgb.cpu().numpy() - gt_imgs[i])))
print(p)
"""
if savedir is not None:
rgb8 = to8b(rgbs[-1])
filename = os.path.join(savedir, '{:03d}.png'.format(i))
imageio.imwrite(filename, rgb8)
rgbs = np.stack(rgbs, 0)
disps = np.stack(disps, 0)
return rgbs, dispsrender_path는 --render_only를 실행할때 주면 실행되는 inference code입니다. 위에서 설명한 render()함수를 통해 rgb, disp 정보를 구합니다. 자세히 보진 않았지만, pre-trained된 모델이 지정된 폴더안에 있으면 바로 그 가중치를 통해 실행하는것 같습니다.
MLP
def create_nerf(args):
"""Instantiate NeRF's MLP model.
"""
embed_fn, input_ch = get_embedder(args.multires, args.i_embed)
input_ch_views = 0
embeddirs_fn = None
if args.use_viewdirs:
embeddirs_fn, input_ch_views = get_embedder(args.multires_views, args.i_embed)
output_ch = 5 if args.N_importance > 0 else 4
skips = [4]
model = NeRF(D=args.netdepth, W=args.netwidth,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars = list(model.parameters())
model_fine = None
if args.N_importance > 0:
model_fine = NeRF(D=args.netdepth_fine, W=args.netwidth_fine,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars += list(model_fine.parameters())
network_query_fn = lambda inputs, viewdirs, network_fn : run_network(inputs, viewdirs, network_fn,
embed_fn=embed_fn,
embeddirs_fn=embeddirs_fn,
netchunk=args.netchunk)
# Create optimizer
optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999))
start = 0
basedir = args.basedir
expname = args.expname
##########################
# Load checkpoints
if args.ft_path is not None and args.ft_path!='None':
ckpts = [args.ft_path]
else:
ckpts = [os.path.join(basedir, expname, f) for f in sorted(os.listdir(os.path.join(basedir, expname))) if 'tar' in f]
print('Found ckpts', ckpts)
if len(ckpts) > 0 and not args.no_reload:
ckpt_path = ckpts[-1]
print('Reloading from', ckpt_path)
ckpt = torch.load(ckpt_path)
start = ckpt['global_step']
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
# Load model
model.load_state_dict(ckpt['network_fn_state_dict'])
if model_fine is not None:
model_fine.load_state_dict(ckpt['network_fine_state_dict'])
##########################
render_kwargs_train = {
'network_query_fn' : network_query_fn,
'perturb' : args.perturb,
'N_importance' : args.N_importance,
'network_fine' : model_fine,
'N_samples' : args.N_samples,
'network_fn' : model,
'use_viewdirs' : args.use_viewdirs,
'white_bkgd' : args.white_bkgd,
'raw_noise_std' : args.raw_noise_std,
}
# NDC only good for LLFF-style forward facing data
if args.dataset_type != 'llff' or args.no_ndc:
print('Not ndc!')
render_kwargs_train['ndc'] = False
render_kwargs_train['lindisp'] = args.lindisp
render_kwargs_test = {k : render_kwargs_train[k] for k in render_kwargs_train}
render_kwargs_test['perturb'] = False
render_kwargs_test['raw_noise_std'] = 0.
return render_kwargs_train, render_kwargs_test, start, grad_vars, optimizercreate_nerf는 보기에는 복잡해보이지만, NeRF를 정의하는 부분입니다. 모델 정의와 함께 다양한 최적화 방식도 정의하고 render에 넘겨줄 매개변수도 정의합니다.
- model
- coarse network
- model_fine
- fine network
# 인자인 fn이 network의 forward함수에 해당.
def batchify(fn, chunk):
"""Constructs a version of 'fn' that applies to smaller batches.
"""
if chunk is None:
return fn
def ret(inputs):
return torch.cat([fn(inputs[i:i+chunk]) for i in range(0, inputs.shape[0], chunk)], 0)
return ret
# embeddirs_fn은 positional encoding 부분
def run_network(inputs, viewdirs, fn, embed_fn, embeddirs_fn, netchunk=1024*64):
"""Prepares inputs and applies network 'fn'.
"""
inputs_flat = torch.reshape(inputs, [-1, inputs.shape[-1]])
embedded = embed_fn(inputs_flat)
if viewdirs is not None:
input_dirs = viewdirs[:,None].expand(inputs.shape)
input_dirs_flat = torch.reshape(input_dirs, [-1, input_dirs.shape[-1]])
embedded_dirs = embeddirs_fn(input_dirs_flat)
embedded = torch.cat([embedded, embedded_dirs], -1)
outputs_flat = batchify(fn, netchunk)(embedded)
outputs = torch.reshape(outputs_flat, list(inputs.shape[:-1]) + [outputs_flat.shape[-1]])
return outputs위의 create_network에서 run_network를 사용하는데, run_network는 network_query_fn를 구성합니다. run_network안에는 batchify가 있는데, batchify의 인자 fn에 NeRF의 forward함수를 넘겨주고 chunk단위로 반복하여 결괏값을 출력합니다. 구성이 많이 복잡하다고 생각합니다...
def raw2outputs(raw, z_vals, rays_d, raw_noise_std=0, white_bkgd=False, pytest=False):
"""Transforms model's predictions to semantically meaningful values.
Args:
raw: [num_rays, num_samples along ray, 4]. Prediction from model.
z_vals: [num_rays, num_samples along ray]. Integration time.
rays_d: [num_rays, 3]. Direction of each ray.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray.
disp_map: [num_rays]. Disparity map. Inverse of depth map.
acc_map: [num_rays]. Sum of weights along each ray.
weights: [num_rays, num_samples]. Weights assigned to each sampled color.
depth_map: [num_rays]. Estimated distance to object.
"""
raw2alpha = lambda raw, dists, act_fn=F.relu: 1.-torch.exp(-act_fn(raw)*dists)
# dists는 ray간의 거리를 나타냄
dists = z_vals[...,1:] - z_vals[...,:-1]
dists = torch.cat([dists, torch.Tensor([1e10]).expand(dists[...,:1].shape)], -1) # [N_rays, N_samples]
# 카메라 좌표계에 있는 point들을 World좌표계로 이동
# z축 기준 거리를 실제 3D 거리로 보정
dists = dists * torch.norm(rays_d[...,None,:], dim=-1)
# rgb는 MLP의 출력인 raw에서 앞쪽 3개에 해당하는 값
rgb = torch.sigmoid(raw[...,:3]) # [N_rays, N_samples, 3]
# Gaussian Noise로 생성되어짐짐
# 실제로 Gaussian Noise를 적용해서 퀄리티 향상을 줄 수 있다고 Appendix에 나와있음음
noise = 0.
if raw_noise_std > 0.:
noise = torch.randn(raw[...,3].shape) * raw_noise_std
# Overwrite randomly sampled data if pytest
if pytest:
np.random.seed(0)
noise = np.random.rand(*list(raw[...,3].shape)) * raw_noise_std
noise = torch.Tensor(noise)
# alpha는 (1-exp(-sigma_i * delta_i))에 해당하는 값
# MLP출력값인 raw의 volume density(sigma)값과 dists(delta)값의 곱으로 계산됨
# Target Point의 불투명도를 나타낸다.
alpha = raw2alpha(raw[...,3] + noise, dists) # [N_rays, N_samples]
# weights = alpha * tf.math.cumprod(1.-alpha + 1e-10, -1, exclusive=True)
# weights는 T_i(1-exp(-sigma_i * delta_i))에 해당하는 값
weights = alpha * torch.cumprod(torch.cat([torch.ones((alpha.shape[0], 1)), 1.-alpha + 1e-10], -1), -1)[:, :-1]
# rgb_map은 C(r)에 해당하는 값 -> ray위의 N개의 모든 점에 대해 summation하여 계산됨.
# sum(weights * rgb)으로 표현가능능
rgb_map = torch.sum(weights[...,None] * rgb, -2) # [N_rays, 3]
# weights와 z_vals을 곱하고, 전체를 summation함으로써, Volume Density값으로 Depth Map을 형성
# C(r)식에서 c_i대신에 z_vals가 들어갔다고 생각하면 됨. 카메라로부터 멀어지면 값이 커지고, weights가 커져도 값이 커짐짐
depth_map = torch.sum(weights * z_vals, -1)
# disparity map이며, 이는 depth map을 inverse한 map으로 표현되어 있음
disp_map = 1./torch.max(1e-10 * torch.ones_like(depth_map), depth_map / torch.sum(weights, -1))
# acc_map은 weights들을 summation하여 나타냄. fine network의 입력값들을 sampling할때 사용됨.
acc_map = torch.sum(weights, -1)
if white_bkgd:
rgb_map = rgb_map + (1.-acc_map[...,None])
return rgb_map, disp_map, acc_map, weights, depth_mapraw2outputs에서는 앞서말했다 싶이 유의미한 결과를 MLP의 결과로부터 추출합니다. 설명은 주석으로 달았습니다.
- dists = dists * torch.norm(rays_d[..., None,:], dim=-1)
- 해당 코드는 단순 깊이 정보인 dists(z_vals로 부터 계산)을 rays_d 벡터에 맞게 길이를 조정해준 것입니다.
- 깊이 간격 (dists): tensor([[1., 1.], [1., 1.]])
- 광선 방향 벡터 크기 (ray_norms): tensor([[1.], [1.4142]])
- 3D 거리 (dists_3D): tensor([[1., 1.], [1.4142, 1.4142]])
- 위와같이 예시에서 실제 vector의 거리는 1.4142배 커졌습니다.
- 해당 코드는 단순 깊이 정보인 dists(z_vals로 부터 계산)을 rays_d 벡터에 맞게 길이를 조정해준 것입니다.
- weights = alpha * torch.cumprod(torch.cat([torch.ones((alpha.shape[0], 1)), 1.-alpha + 1e-10], -1), -1)[:, :-1]
- torch.ones으로 cumprod이 가능하게 함.
- 1e-10은 연산이 0에 수렴하는걸 방지하기 위함.
- cumprod([1, ...(구조분해)[1-alpha]])의 [:, :-1]의 크기는 [num_rays, 1(weight)] 로 나올 것입니다.
# Model
class NeRF(nn.Module):
def __init__(self, D=8, W=256, input_ch=3, input_ch_views=3, output_ch=4, skips=[4], use_viewdirs=False):
"""
"""
super(NeRF, self).__init__()
# D: 네트워크의 깊이(길이)
self.D = D
# W: 네트워크의 너비
self.W = W
# input_ch: 인풋채널 크기
self.input_ch = input_ch
# input_ch_views: 방향채널 크기
self.input_ch_views = input_ch_views
# skips: skip-connection적용 여부
self.skips = skips
# use_viewdirs: 방향정보 적용 여부
self.use_viewdirs = use_viewdirs
self.pts_linears = nn.ModuleList(
[nn.Linear(input_ch, W)] + [nn.Linear(W, W) if i not in self.skips else nn.Linear(W + input_ch, W) for i in range(D-1)])
### Implementation according to the official code release (https://github.com/bmild/nerf/blob/master/run_nerf_helpers.py#L104-L105)
self.views_linears = nn.ModuleList([nn.Linear(input_ch_views + W, W//2)])
### Implementation according to the paper
# self.views_linears = nn.ModuleList(
# [nn.Linear(input_ch_views + W, W//2)] + [nn.Linear(W//2, W//2) for i in range(D//2)])
if use_viewdirs:
# 중간에 feature를 변환하는 layer -> positional encoding 적용
self.feature_linear = nn.Linear(W, W)
# 밀도(alpha) 예측
self.alpha_linear = nn.Linear(W, 1)
# rgb 예측하는거,
self.rgb_linear = nn.Linear(W//2, 3)
else:
self.output_linear = nn.Linear(W, output_ch)
def forward(self, x):
input_pts, input_views = torch.split(x, [self.input_ch, self.input_ch_views], dim=-1)
h = input_pts
# MLP foward pass
for i, l in enumerate(self.pts_linears):
h = self.pts_linears[i](h)
h = F.relu(h)
if i in self.skips:
# skip connection을 해준다.
h = torch.cat([input_pts, h], -1)
if self.use_viewdirs:
# 바로 alpha(density)값 예측
alpha = self.alpha_linear(h)
# feature 추출
feature = self.feature_linear(h)
h = torch.cat([feature, input_views], -1)
for i, l in enumerate(self.views_linears):
h = self.views_linears[i](h)
h = F.relu(h)
rgb = self.rgb_linear(h)
outputs = torch.cat([rgb, alpha], -1)
else:
outputs = self.output_linear(h)
# 결과로 rgb, alpha값이 둘다 나옴
return outputs
NeRF를 정의한 부분입니다. 대부분의 정보는 주석을 참고하시면 됩니다. NeRF모델에서 skip-connection이라든지 viewdirection을 추가하는 모듈, density(alpha)값을 반환하는 부분, 중간중간 ReLU이 적용됨을 볼 수 있습니다.
참고로 density를 뽑아낼때 feature_linear(h)를 통해 해당 feature를 input_views와 concatenate하여 views_linear에 입력으로 사용해 density를 뽑아냅니다. 최종적으로 forward했을때 결괏값 outputs을 rgb, alpha로 묶어서 반환합니다. 그외에도 load_weights_from_keras등도 있는데 생략하겠습니다.
Loss Function
# Misc
img2mse = lambda x, y : torch.mean((x - y) ** 2)
mse2psnr = lambda x : -10. * torch.log(x) / torch.log(torch.Tensor([10.]))
to8b = lambda x : (255*np.clip(x,0,1)).astype(np.uint8)
img_loss = img2mse(rgb, target_s)
trans = extras['raw'][...,-1]
loss = img_loss
psnr = mse2psnr(img_loss)
if 'rgb0' in extras:
img_loss0 = img2mse(extras['rgb0'], target_s)
loss = loss + img_loss0
psnr0 = mse2psnr(img_loss0)
loss.backward()
optimizer.step()
# NOTE: IMPORTANT!
### update learning rate ###
decay_rate = 0.1
decay_steps = args.lrate_decay * 1000
new_lrate = args.lrate * (decay_rate ** (global_step / decay_steps))
for param_group in optimizer.param_groups:
param_group['lr'] = new_lrate다시 train() 함수로 돌아와서 이제야 render() 결과를 통해 rgb, disp, acc, extras를 구했습니다. 그 후, 최적화를 하려면 loss function이 있어야 합니다.

rgb는 fine network의 결괏값이고, extras['rgb0']은 coarse network의 결괏값입니다. 위 수식처럼 coarse network, fine network 각각에 대해 loss를 구하고 더한 후에, back propagation합니다.
Positional Encoding
# Positional encoding (section 5.1)
class Embedder:
def __init__(self, **kwargs):
self.kwargs = kwargs
self.create_embedding_fn()
def create_embedding_fn(self):
embed_fns = [] # 변환할 함수 리스트
d = self.kwargs['input_dims'] # 입력 차원 (보통 3)
out_dim = 0 # 출력차원 (몇개의 encoding을 만들 것인지)
# 원본 입력을 포함할 것인지에 대한 여부
if self.kwargs['include_input']:
embed_fns.append(lambda x : x)
out_dim += d
max_freq = self.kwargs['max_freq_log2']
N_freqs = self.kwargs['num_freqs']
# freq_bands는 N_freqs개의 주파수 값이 됨
if self.kwargs['log_sampling']: # 로그스케일 or 선형 스케일
freq_bands = 2.**torch.linspace(0., max_freq, steps=N_freqs)
else:
freq_bands = torch.linspace(2.**0., 2.**max_freq, steps=N_freqs)
# 각 주파수 freq에 대해 sin, cos을 적용
# freq -> [2^0, 2^1, ... ,2^(L - 1)]
for freq in freq_bands:
# p_fn -> [sin, cos]
for p_fn in self.kwargs['periodic_fns']:
# phi가 큰 영향을 끼치지는 않음
embed_fns.append(lambda x, p_fn=p_fn, freq=freq : p_fn(x * freq))
out_dim += d
self.embed_fns = embed_fns
self.out_dim = out_dim
def embed(self, inputs):
return torch.cat([fn(inputs) for fn in self.embed_fns], -1)
def get_embedder(multires, i=0):
if i == -1:
return nn.Identity(), 3
embed_kwargs = {
'include_input' : True,
'input_dims' : 3,
'max_freq_log2' : multires-1,
'num_freqs' : multires,
'log_sampling' : True,
'periodic_fns' : [torch.sin, torch.cos],
}
embedder_obj = Embedder(**embed_kwargs)
embed = lambda x, eo=embedder_obj : eo.embed(x)
return embed, embedder_obj.out_dimEmbedder는 positional encoding을 통해 고주파 피쳐를 만드는 과정입니다. 2중 for문에서 freq_band(log scale), p_fn(sin, cos)을 통해 아래와같은 수식으로 임베딩을 합니다. 그리고 N_freq를 통해 임베딩할 차원을 결정합니다. paper 참고.
