![[ 딥러닝 논문 리뷰 - PRMI Lab ] - DiT (Scalable Diffusion Models with Transformers)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FefRazq%2FbtsLJtXo0x8%2FAAAAAAAAAAAAAAAAAAAAAKZkLfXSMJmIswFZFe56FrTC3QvFGrHD4lh35kvA_adc%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DLZAL58VV4vDimFIxuJM5bmegJMs%253D)
오늘은 OpenAI에서 만든 SORA의 근간이 되는 기술을 공부해보고 싶어서 찾다가 DiT(Diffusion Transformer)라는 논문이 있어서 정리해 보려고 합니다. 새로운 기술에 대한 논문이기 보다는, 모델의 구조와 관련된 논문이라고 생각됩니다. 그리고 최근에 4090데탑을 맞춰서, NerF, Diffusion 모델들을 코드를 분석하며 돌려보도록 하겠습니다.
Diffusion Transformers (Preliminaries)
DDPM (Denoising Diffusion Probablitistic Model)
DDPM 리뷰: https://hyunseo-fullstackdiary.tistory.com/426
[ 딥러닝 논문 리뷰 - PRMI Lab ] - Denoising Diffusion Probabilistic Model (DDPM)
Generative model에 있어서 이전에 GAN, VAE, Normalizing Flow모델등을 알아봤었습니다. 요즘에는 DDPM이 GAN보다 성능이 좋다고 들었습니다. 원래는 StyleGan을 통해 발전된 GAN에 대해 알아보려고 했으나, DDPM
hyunseo-fullstackdiary.tistory.com
Classifier guidance (Diffusion Models Beat GANs on Image Synthesis)
논문 링크: https://arxiv.org/abs/2105.05233
Diffusion Models Beat GANs on Image Synthesis
We show that diffusion models can achieve image sample quality superior to the current state-of-the-art generative models. We achieve this on unconditional image synthesis by finding a better architecture through a series of ablations. For conditional imag
arxiv.org

위 그림에서 기존의 \(p_{\theta}(x_t|x_{t+1})\)을 \(y\)에 대해 condition한 수식을 \(\mathbf{Z}p_{\theta}(x_t|x_{t+1})p_{\phi}(y|t)\)로 표현할 수 있음을 보여줍니다. \(p_{\theta}(x_t|x_{t+1})\)을 Gaussian Distribution으로 표현하고 있습니다.

\(p_{\phi}(y|x_t)\)또한 Diffusion procedure의 성질을 이용해 Taylor expansion을 통해 정리합니다. 그럼 최종적으로 구하고자 했던 식은 \(\sum g\)로 mean shifted된 형태로 표현되게 됩니다.
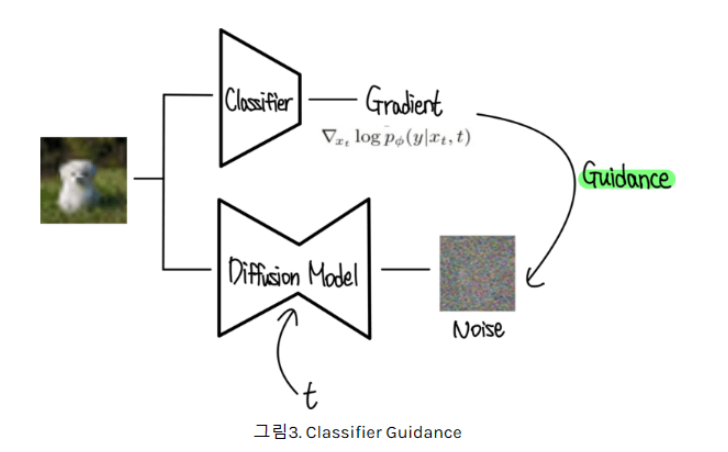
해당 논문을 정리하면 위와 같은 그림으로 표현할 수 있겠습니다. label y로 conditional하게 image를 sampling하기 위해서는 \(x_t, y\)로 훈련해서 얻은 별도의 classifier의 gradient \(\nabla g\)를 DDPM sampling 과정의 mean에 더해주면 됩니다. 논문에서는 classifier guidance의 strength를 조정하는 \(s\)를 classifier의 gradient에 곱해줘서 강도를 조절해줍니다.
Classifier-free guidance (Classifier-Free Guidance)
논문 링크: https://arxiv.org/pdf/2207.12598

해당 논문은 제목 그대로 classifier를 만들지 않고 conditioning하는 방법에 대해 다룹니다. 간단히 위 pseudo code에서 \(p_{uncound}\)를 통해서 라벨 \(c\)를 뽑아내고, forward pass의 \(z_t,\ t,\ c\)를 함께 활용하여 모델을 훈련시킵니다.
해당 논문에서는 unconditional model, conditional model 2개를 동시에 훈련시키는 방향으로 훈련합니다. unconditional model은 \(c = \emptyset\)로 설정합니다. 기본 \(p_{uncond} = 0.5\)로 설정합니다.

기본적으로 위 pseudo code에서 \(w\)가 0이면 non-guided model이라고 정의합니다. 또한 \(c\)는 text_embedding으로서, CLIP, T5와 같은 모델을 주로 사용합니다.
LDM (Latent Diffusion Model), VQ-VAE (Vector Quantinize-VAE)
논문 링크: https://arxiv.org/pdf/2112.10752

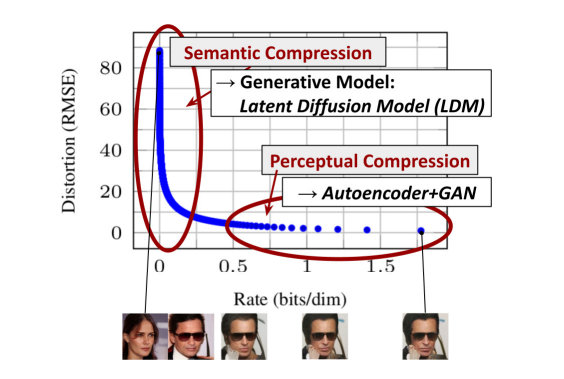
LDM은 DM에서의 모든 pixel space에서의 계산 비효율성을 개선하기 위해 Encoder, Decoder구조를 도입한 것입니다. VQ-VAE구조를 사용하여 의미없는 고주파 특성을 보존하는 대신 저주파의 특성(=의미)을 학습하는 Semantic Compression을 합니다. LDM을 살펴보기 전에 VQ-VAE에 대해 간단히 보겠습니다.

VQ-VAE는 VQ(Vector Quantinize)를 활용하여 latent space인 \(z_{e}(x)\)를 Embedding space(codebook, 일종의 사전)을 이용하여 vector mapping을 합니다. 따라서 제한된 개수의 codebook vector를 사용하여 discrete sampling을 하는 것입니다.

codebook과의 mapping은 위 수식과 같이 L2가 가장 작은 vector와 매핑해 one-hot 확률분포 \(q(z|x)\)를 만듭니다. 그 후, 순서에 맞는 vector를 추출해 \(z_{q}(x)\)를 생성합니다.
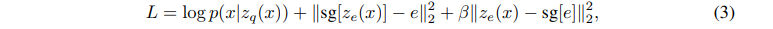
VQ-VAE의 loss식에는 sg(stop gradient)가 포함되어 있습니다. 그 이유는 VQ operation이 비선형적이고 미분 불가능하기 떄문입니다. 그래서 gradient를 복사하여 decoder -> encoder로 그대로 복사 해줍니다. loss는 앞에서부터 각각 Reconstruction, codebook, commitment loss라고 합니다.
- Reconstruction Loss
- Decoder와 encoder를 최적화하는 부분입니다.
- decoder의 최종 output이 최적화 됩니다.
- Codebook loss
- encoder의 출력물에 sg를 걸고 code book을 업데이트 하는 과정입니다.
-
- 이러한 과정 때문에 reconstruction loss인 \(log p(z|z_{q}(x))\)가 \(e_i\)의 update에 관여를 하지 않는 이유입니다.
-
- codebook이 encoder의 결과와 비슷하게 최적화 됩니다.
- encoder의 출력물에 sg를 걸고 code book을 업데이트 하는 과정입니다.
- Commitment loss
- encoder의 출력이 codebook의 결과와 비슷하게 최적화 됩니다.

다시 LDM으로 돌아와서 high-variance latent space를 피하기 위해 저자들이 적용한 regularization을 소개합니다. KL-reg, VQ-reg로 나눌 수 있습니다.
- KL-reg
- VAE처럼 KL-divergence를 통해 \(z\)를 특정 분포로 정규화 하여, 잠재 공간을 효율적으로 압축되게 합니다.
- VQ-reg
- VQ-VAE에서 봤던것 처럼, 잠재 공간을 discrete하게 만들어, Semantic Compression을 가능하게 합니다.
- VQ-reg는 decoder에 넣어서 layer를 따로 구성했다고 합니다.

LDM의 Loss식은 위와 같습니다. \(e_{\theta}(z_t,t)\)는 time conditional U-net입니다. 하지만 \(z_t\)는 \(\epsilon\): Encoder를 통해서 \(z\)를 만들고 DM을 통해 노이즈를 추가해 \(z_t\)를 만들어, 이로부터 학습을 진행합니다.


LDM에서 domain specific encoder \(\tau_{\theta}\)를 활용하여 \(y\)를 intermediate representaiton으로 바꿉니다. 그 후, 해당 representation(=embedding)을 cross-attention을 통해 U-net에 정보를 전달합니다.
representation을 통해 K.Q.V(learnable matrix)를 만들어준다음에, 수식에 나와있는 shape에 맞추어 cross-attention을 진행해줍니다. 참고로 \(d_{\epsilon}^i\)와 같이 \(i\)로 notation되어 있는건 U-net의 layer 번호, N은 batch size등을 의미합니다.
DiT (Scalable Diffusion Models with Transformers)
논문 링크: https://arxiv.org/pdf/2212.09748
참고 블로그: https://kyujinpy.tistory.com/132
[Diffusion Transformer 논문 리뷰3] - Scalable Diffusion Models with Transformers
*DiT를 한번에 이해할 수 있는(?) A~Z 논문리뷰입니다! *총 3편으로 구성되었고, 마지막 3편은 제 온 힘을 다하여서.. 논문리뷰를 했습니다..ㅎㅎ *궁금하신 점은 댓글로 남겨주세요! DiT paper: https://ar
kyujinpy.tistory.com
DiT의 저자들은 transformer architecture를 diffusion model에 scaling properties를 가질 수 있도록 설계했다고 합니다. 그리하여 DiT는 Vision Transformer(ViT)를 사용하여, patch sequence를 통해 image task를 해결합니다.
DiT-1. Patchfy
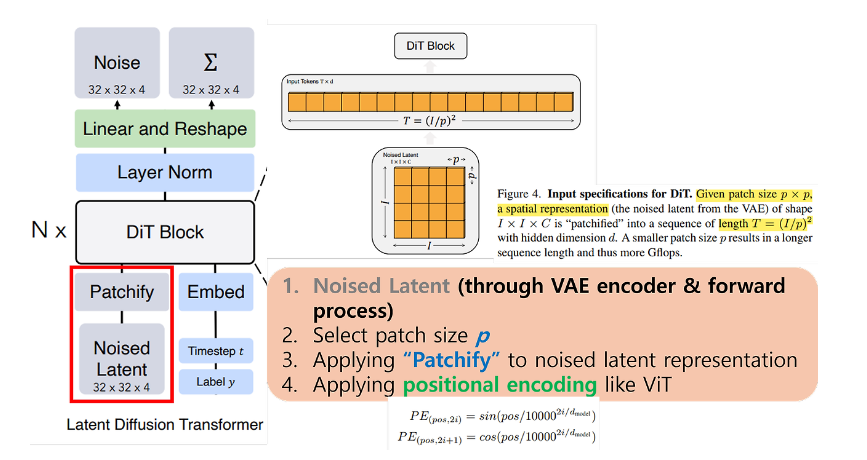
먼저 빨간색 박스에 해당되는 Noised Latent, Patchify에 대해 알아보겠습니다.
Noised Latent는 VAE Encoder ---> forward Process입니다. 위의 LDM에서 설명한 그림(윗부분) 그대로 입니다. 그 다음 블록인 Patchify는 \(I \times I \times C\)인 Noised Latent를 \(p \times p\)의 patch로 쪼개어 length가 \(T = (I/p)^2\)이고 hidden dimension이 \(d\)인 sequence로 만드는 부분입니다. \(T \times d\)의 patch가 생성되는데, 더 작은 값의 \(p\)는 longer sequence = higher Gflops를 의미한다고 합니다. 추가적으로 만들어진 sequence에 ViT에도 적용된 sin-cos positional encoding도 적용해 줍니다.
DiT-2. Embed

Embed layer의 detail은 Appendix쪽에 있습니다. 우선, input timestep를 embed하기 위해 2개의 MLP를 활용하여 256d의 embedding을 만드는데, MLP output의 결과를 SiLU activation function에 넣어서 최종적으로 256d를 만듭니다.
과정을 간단히 보면 time step t이 sinusoidal PE(Positional Encoding)를 통해 [B, 256(=frequency dimension)]로 변환됩니다. MLP를 통해 [B, \(d_{hidden}\)]이 됩니다. \(d_{hidden}\)은 DiT에 활용되는 hyperparameter인 Transformer hidden size입니다. 그 후, SiLU가 적용되는 일련의 과정이 2번 반복됩니다. 즉 결과는 [B, \(d_{hidden}\)]가 되어, 이는 time step정보 \(t\)를 Transformer가 잘 처리할 수 있도록 변환된 vector가 됩니다.
또한, Timestep과 label 정보에 대하여 embedding정보로 들어오게 되면, 이는 각각 256d의 vector일 것인데, 두개의 vector를 더한 상태(+) 로 MLP에 넣어주게 됩니다.
DiT-3. DiT Block
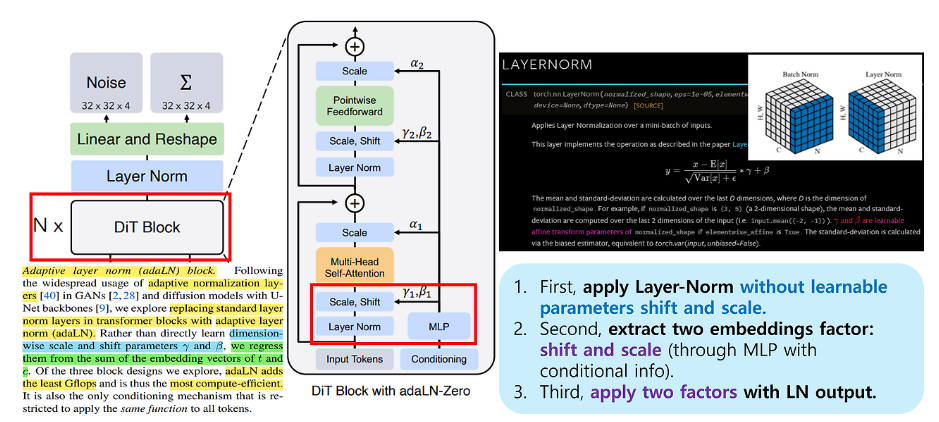
DiT Block을 들어가기 전에 adaLN에 대해 살펴보겠습니다. 기존의 Layer Normalization(LN)은 마지막에 learnable parameter를 통해 shift, scale을 합니다. 하지만, DiT에서는 Embed layer의 timestep, label의 embedding을 통해 shift, scale을 진행합니다. 이러한 adaLN은 styleGAN과 같은 GAN의 style trasfer에서 자주 사용됩니다.

adaLN은 2개(timestep, label)의 shift, scale 인자가 필요하다고 했습니다. 총 4개의 embeding vector가 MLP의 출력으로 나오는 것입니다. adaLN-Zero는 추가로 scale factor \(\alpha\)를 추가하여 총 6개의 output이 나오도록한 모델 구조를 말합니다. 그리고 이러한 scale factor \(\alpha\)는 0으로 두고 시작하기 때문에 adaLN-Zero로 명명하는 것입니다.
뿐만 아니라 \(\alpha = 0\)인 상황에서는 input token(patch sequence)만이 살아남습니다 (위 그림 참고). 그래서 초기의 DiT block은 identity function이 됩니다.

추가로 adaLN-Zero인 경우 transformer hidden size의 6배에 해당하는 vector를 출력하게 된다고 합니다. 또한, Core transformer(FFNN, SA)에는 GELU가 사용된다고 합니다.
DiT-4. Transformer Decoder
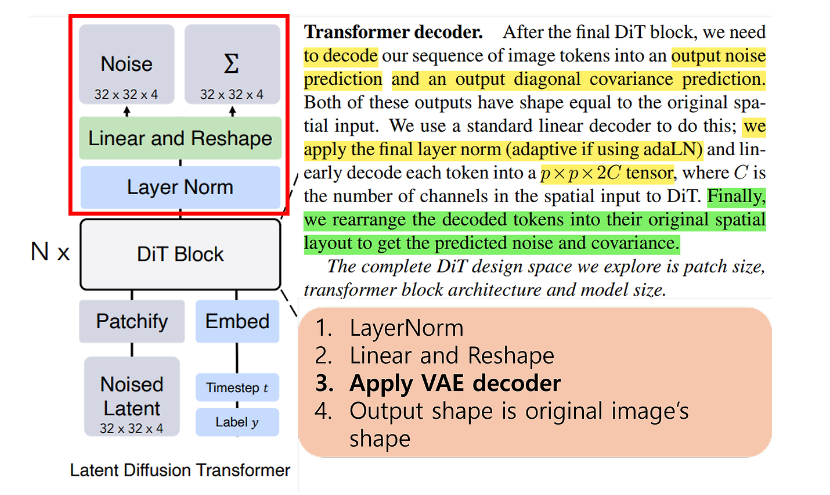
Transformer Decoder에는 Layer Normalization을 적용하고, linear and Reshape을 적용하여 각 patch마다 기존 channel size의 2배가 되는 output을 출력하게 합니다. 이에 output은 위 처럼 예측된 noise값과 covariance값이 되고, 이후 VAE decoder에 noise값을 넣어서 실제 image를 synthesis를 하게 됩니다.
Diffusion 과정의 역전파 과정에서 \[x_{t-1} \sim \mathcal{N}(\mu_{\theta}(x_t, t), {\scriptstyle \sum}_{\theta}(x_t, t))\]를 통해 \(x_{t-1}\)로 샘플링하여 이전 단계로 이동합니다. 원래 DDPM에서는 해당 분산을 고정했지만, 공분산을 학습하게 함으로써 Diffusion 과정이 시간 단계 \(t\)에서의 노이즈 수준을 더 잘 반영할 수 있도록 합니다. 또한, 고해상도 이미지를 생성할 때 공분산을 작게 설정하면 품질이 높아지고 큰 공분산은 더 창의적인 결과를 생성할 수 있도록 조절할 수 있습니다.
Result
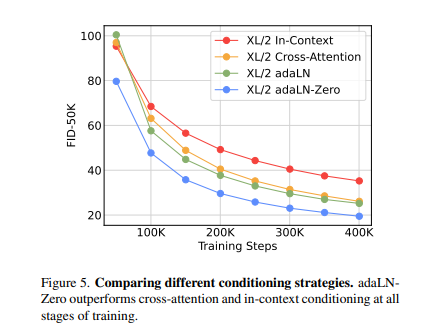
그 외에도 DiT Block에 위의 adaLN, adaLN-Zero와 더불어 Cross-attention, In-Context conditioning을 했을때의 성능 비교를 한 표입니다. In-context는 \(t, c\) embedding을 additional tokens로서 input sequence에 포함시켜서 ViT의 cls token과 비슷하게 처리하는 방법입니다. Cross-attention block은 \(t, c\)를 length-two sequence로 Self-Attention 뒤에 Cross-Attention레이어를 추가하여 Query로 이미지 토큰, Key/Value로 \(t, c\)를 두어 학습하는 방법입니다. 결과적으로는 XL/2 adaLN-Zero가 가장 뛰어난 것을 볼 수 있습니다.

위표에서와 같이 FID, IS가 이전의 모델과 비교하였을 때 우수함을 확인할 수 있습니다.