![[ 딥러닝 논문 리뷰 - PRMI Lab ] - CLIP: Learning Trasferable Visual Models From Natural Language Supervision](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcIn9IK%2FbtsGYM8sK2X%2FAAAAAAAAAAAAAAAAAAAAANnARzpfPVhW111XOlzFqtcj4u-Vp9jSg1wMGX3eJAFX%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DhbHe15f7hvEWS1P8%252ByNtZWIpUa0%253D)
Stable Diffusion Model을 읽기 위해, 저번까지 Diffusion과 관련된 내용을 다루었습니다. 이번에는, OpenAI에서 ICML 2021에 Accept되었던 CLIP에 대해서 다루어보려고 합니다. 현재 OpenAI의 DALLE-2나 StableDiffusion, SORA,.. 다양한 멀티모달 생성형 AI에 CLIP의 개념이 들어가있다고 합니다. CLIP이 무엇이고 어떤점이 Contribution이었는지에 대해 보겠습니다.
Abstract
기존의 SOTA 모델은 특정 카테고리 내에서 label을 학습해서 예측하게끔 하는 형태였습니다. 이러한 방법은, 이미지의 일반화 성능과 다른 task에서의 사용 가능성을 제한합니다. 따라서 이에 대한 대안으로 CLIP은 이미지를 설명하는 raw-text를 라벨로 사용한다면, down-stream task에서의 일반화 문제를 해결할 수 있을 것이라고 제안합니다.
이러한 방법론을, 저자들은 서로 다른 30개의 benchmark dataset을 이용해 평가했다고 합니다. 저자들이 제안한 모델은 다양한 down-stream task에서 더욱 좋은 성능을 내었다고 합니다. 이는 추가적인 데이터셋을 활용하지 않고도 특정 태스크를 위해 Linear Probe한 모델들과 견줄만한 성능을 도출했다는 것입니다. 실제로 저자들은 ImageNet Zero-Shot을 ResNet-50을 활용해서 학습한 모델과 비교합니다.
1. Introduction and Motivation Work

NLP분야에서는 raw-text를 이용해서 pre-training을 시키는 방안은 계속 발전해왔습니다. autoregressive하고 maksed language modeling을 통한 task-agnostic학습은 모델의 대규모의 데이터셋을 이용해 학습 가능하도록 했습니다. 또한, text-to-text 인터페이스의 학습을 통해서 기존에 output heads를 따로두어 특정 task에 맞게 토큰을 사용하게끔 하는등의 노력을 할 필요가 없어졌습니다. 이러한 시스템의 Flag-ship system은 GPT-3을 예시로 들수있는데, 이를 통해 라벨링된 데이터셋없이도 다양한 task에서도 좋은 성능을 내는 모델이 될 수 있었다고 합니다. 위와같은 결과는, NLP에서 web-scale에서의 text가 high-quality의 crowd-labed NLP dataset을 압도하는 결과를 낳게 되었습니다.

하지만 Computer Vision분야에서는 여전히 ImageNet과 같은 crowd-labeled dataset이 업계 표준입니다. 그러면 어떻게 Computer Vision분야에서 이러한 방안을 적용시킬 수 있을까 선행 연구들을 보겠습니다. 간단히 몇개만 보면, image retrieval를 통해 image-text documents pair를 학습시킨 경우, mani-fold learning을 통해 image와 연관된 image caption을 예측하도록 학습시킨 경우, DBM을 통해 image-text pair를 학습시킨 경우, CNN을 통해 image의 captions를 예측하도록 학습시킨 경우,.. etc. 최근의 방식은 transformer-based의 language modeling, maksed language modeling및 contrastive objectives를 이용하는 것입니다(VirTex, ICMLM, ConVirt,..). 하지만 자명한 선행연구들이 있음에도 불구하고, 이러한 연구분야의 논문은 많이 부족합니다. 그 이유에 대해 알아보겠습니다.
그 이유는 common benchmark에서의 다른 방법들보다 낮은 지표가 그 이유입니다. (Learninhttps://arxiv.org/pdf/1612.09161g Visual N-Grams from Web Data. Li et al., 2017)에서 ImageNet zero-shot learning에서 11.5% 정확도를 달성했습니다. 이는 해당 년도의 SOTA (Self-training with Noisy Student improves ImageNet classification, Xie et al., 2020) 88.4%보다 월등히 낮은 정확도입니다. 대신 weak supervision에서의 사용은 성능 향상을 보였습니다.
(Exploring the Limits of Weakly Supervised Pretraining Mahajan 2018 et al.)에서는 Instagram에서의 ImageNet-related hashtags를 예측하도록 학습되었습니다. 그 외에도 noisly labeled JFT-300M dataset에 대해서 transfer benchmark가 좋아졌다는 결과도 있었습니다. 이러한 노력들은 gold-labels를 통해 제한적으로 학습하는 것과 제한없는 raw-text로의 학습간의 과도기에 있다고 볼 수 있습니다. 이러한 weakly supervised learning이 발전하여 1000 -> 18291개의 클래스를 supervision할 수 있게 되었고 이를 통해 더욱 text를 통해 visual concept를 학습할 수 있었지만 여전히 사용되는 static softmax classifier와 dynamic outputs 메커니즘의 부족이 zero-shot성능을 여전히 제한해 많은 부족한 점이 있습니다.
weak supervised모델과 최근 연구되는 자연어 처리를 이용한 image representation모델과의 차이점은 scale이라고 볼 수 있습니다. 최근 모델들은 수백만개에서 수십업 개의 이미지를 이용해 학습하지만, VirTex, ICMLM, ConVIRT와 같은 이전의 weak supervised모델들은 20만개의 이미지만을 사용했습니다. 최근에는 더 많은 데이터셋에 대해서 학습할 수 있게 하고자, 4억개의 image-text pair(raw)를 만들었으며, 이를 ConVIRT의 간단한 버전을 통해 학습했는데, 이를 저자들이 제안한 CLIP이라고 부르기로 했습니다.
저자들은 그래서 8개의 CLIP모델을 컴퓨팅 자원을 2자리수 차이로 변화시켜가며, 이 모델들의 transfer performance가 컴퓨팅 자원의 양과 예측 가능한 함수 관계를 가지는지 분석합니다. 저자들은 GPT모델들과 같이 CLIP도 다양한 분야의 task에 적용할 수 있으며, 특정 task만을 위해 만들어진 모델과 비교도 할 수 있음을 알게 되었습니다. 그리고 Linear-Probe방식을 이용한 fine-tuning에서 CLIP이 다른 모델들보다 성능이 좋을뿐 아니라 효율적이라고 말합니다. 뿐만 아니라 zero-shot CLIP 모델이 같은 정확도를 가지는 다른 모델보다 robust하다고 언급합니다.
이제 CLIP의 구현 방법과 Detail들에 대해서 알아보겠습니다.
2. Approach
2.1 Natural Language Supervision
본 연구에서의 핵심 아이디어는 자연어를 이용한 supervised learning입니다. 이와 관련된 연구는 unsupervised, self-supervised, weakly supervised, supervised,..등 다양히 적용되어 왔습니다. CLIP은 이들과 다를바 없지만 natural language supervision이라는 점에서는 다 동일합니다. 이전의 연구들은 natural language의 복잡도와 이의 수많은 source에서 씨름했었습니다. 이러한 자연어를 이용한 방법에는 이점이 있기 때문인데, 그 이유는 scale을 키우기가 쉽기 때문입니다. 기존에는 1-of-N 다수 voting방식으로 흔히 말하는 gold label을 만듭니다. 하지만 natural language는 internet에서 다양한 source에서 수집해 scaling할 수 있기 때문입니다. 이러한 자연어는 단순히 이미지를 텍스트로 표현하도록 학습하는 것이 아니라 모델이 이미지에게 조금 더 깊은 이해를 가질 수 있게 해 zero-shot transfer를 가능하게 해준다는 장점이 가장 큽니다.
2.2 Creating a Sufficiently Large Dataset
기존의 작업들은 MS-COCO, Visual Genome, YFCC100M등의 dataset으로 주로 이루어졌습니다. MS-COO, Visual Genome은 high-quality의 crowd-labeled datasets이며, 규모가 작다. 이에 반해 위에서 잠깐본, (Exploring the Limits of Weakly Supervised Pretraining Mahajan 2018 et al.)여기에서는 3.5B Instagram photos를 이용해 훈련하기도 한다. 100M개에 달하는 YFCC100M dataset은 적절한 대안이 될 수 있지만, 이의 metadata는 매우 sparse하고 low-quality라는 단점이 있다.
기존의, natural language supervision의 주요 동기는, internet에 public하게 공개되어있는 대량의 데이터셋에 있습니다. 하지만 현재의 존재하는 dataset들은 이러한 정보를 적절히 반영하지 못했기 때문에, 이러한 결과만 반영한다면 연구의 잠재력을 과소평가하는 것이라고 합니다. 그래서 저자들은 400M개의 image-text pair로 이루어진 dataset을 internet에서 구해서 만들었다고 합니다. 그리고 데이터를 구성하는데에 있어서 다양성을 위해, 500K개의 query를 날려서 수집했으며, 하나의 query에 대해서 20K개 넘지 않도록 구성했다고 합니다. 그리고 이는 GPT-2를 훈련시킬때 사용했던 dataset인 WebText의 개수와 비슷하며 저자들이 만든 dataset의 이름을 WIT(WebImage Text)라고 하겠답니다.
2.3 Selecting an Efficient Pre-Training Method
SOTA의 CV 모델은 매우 많은 양의 연산량을 필요로합니다. (Exploring the Limits of Weakly Supervised Pretraining Mahajan 2018 et al.)에서는 저자들의 ResNeXT101-32x48d모델을 훈련시키는데 19 GPU years를 필요로 했다고합니다.
(Self-training with Noisy Student improves ImageNet classification Xie 2020 et al.)은 저자들의 Noisy Student EfficientNet-L2를 훈련시키는데 33 TPUv3 cores-year를 필요로 했다 합니다. 두개의 system모두 1000개의 class를 가진 ImageNet을 학습시키는데 이렇게 많은 연산량을 필요로 합니다. 그럼 수십, 수백 Billon개의 natural language에서 Visual Concepts를 뽑아내는건 엄청 어려울 것입니다. 그래서 저자들은 training efficiency가 natural language supervision의 성공에 key역할이라고 합니다.


저자들은 초기에 (VirTex: Learning Visual Representations from Textual Annotations Desai 2021 et al.)와 비슷하게 image CNN과 text transformer를 결합해서 scratch부터 훈련시켰다고 합니다.하지만 이는 scaling하기 어렵다는 단점이 있었다고 합니다. Figure2를 보면, 63M짜리 transformer language model의 image encoder에서 ResNet-50모델을 2번 inferencing하는데의 시간이 기본 baseline 모델을 통해 같은 image를 BoW prediction하는데의 시간이 3배 차이가 날 만큼 느렸다고 합니다.


위 2개의 접근 방법은 같은 문제점을 공유하는데 각각의 image에서 exact words를 predict하려고 하기 때문입니다. 이는 매우 어려운 task인데 하나의 image에 대해 description, comments, related text은 매우 다양할 수 있기 때문입니다. 최근 연구인 contrastive representation learning을 통해 더 좋은 image representation을 학습할 수 있다고 밝혀냈다고 합니다. 또한, (Generative Pretraining from Pixels 2020 Chen et al.,)에서 generative models이 iamge에 대한 high-quality representation을 학습할 수 있지만, contrastive models는 더 적은 cost로 같은 performance를 낼 수 있다고 합니다. 이러한 연구들을 토대로 저자들은, text에 어떤 image의 pair가 맞는지를 찾아내는 proxy task를 정의할 수 있었다고 합니다. 우리는 순서를 고려하지 않는 BoW prediction에서 training objective를 contrastive objective로 바꾸니 Figure 2처럼 4x efficiency improvement를 달성할 수 있었다 합니다. 그럼 이제 해당 방법이 어떻게 구현되었는지 보겠습니다.

학습 원리는 생각보다 간단합니다. batch $N$ (image, text) pairs가 있다고 할때 CLIP은 $N x N$ 쌍에 대해서 훈련을 하게 됩니다. 이를 위해 CLIP은 image encoder, text encoder로부터 multi-modal embedding space를 구성하여 cosine similarity를 $N$ real pair에 대해서는 최대화, $N^2 - N$ incorrect pairs에 대해서는 최소화 하게끔 목적함수를 구성합니다.


실제로 위와같이 InfoNCE loss를 통해서 구성됩니다. i~N번째 이미지에 대한 loss를 행에 대해서 각각 계산해주고, 비슷하게 열에 대해서 텍스트에 대한 cross-entropy loss를 구성합니다. 또한, pseudo code를 보면, 계산한 loss_i, loss_t에 대해서 평균을 내어 loss를 구성함을 알 수 있습니다. 뿐만 아니라 내적을 하는 과정에서 temperature를 통한 모델의 smoothing도 tuning 해줄 수 있음을 볼 수 있습니다.
clip은 pre-training dataset이 large size이기 때문에, over-fitting은 저자들의 주된 관심사가 아니였다고 합니다. 또한, 저자들은 CLIP의 image encoder를 ImageNet과같은 dataset으로 초기화하지 않고 scratch부터 훈련을 하였다 하고, text encoder는 pre-trained weights를 사용하였다고 합니다.
그리고 text-space와 image-space를 구성하는 과정에서 non-linear projection을 사용하지 않고 linear projection(dot production)을 사용하였습니다. 그 이유는 저자들은 두개를 사용해본 결과 non-linear projection을 사용했을때의 별다른 큰 효과를 못봤다고 하며 오히려 non-linear projection을 사용하면 image의 detail한 부분에 co-adapt하여 뒤에서 알아볼 일반화 성능에 영향을 끼쳤다고 합니다. 그리고 CLIP의 훈련에 있어서 random square crop 데이터 증강법만을 사용했다고 합니다.
2.4 Choosing and Scaling a Model




우선 image encoder에서는 ResNet-50모델을 베이스로 사용했습니다. 그리고 이에 대한 변형인 ResNet-D와 여기에 antialiased rect-2 blur pooling을 사용했다고 합니다. 또한, global average pooling layer과 더불어 attention pooling mechanism을 사용했다고 합니다. 여기서 attention pooling은 transformer-style의 single layer에서 multi-head QKV attention을 global average-pooled(image representation)을 conditioned query로 주어서 구현했다고 합니다.
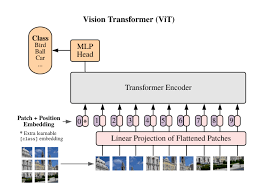
image encoder의 2번째 아키텍처로는 최근에 연구된 Vision Transformer(ViT)를 채택했습니다. 여기에 minor modification을 주었는데, layer normalization층을 combined patch, position embedding층 전에 추가했다 합니다. 그리고 조금 다른 initialize scheme을 사용하였는데, 이는 실제 code를 봐야 알것 같습니다.


text-encoder로는 modified Transformer를 사용했다고 합니다. 63M-parameter, 12-layer 512 wide model, 8 attention head모델을 사용했다고 합니다. 그리고 byte pair encoding(BPE)를 사용했습니다. 또한, 계산효율성을 위해 max sequence length를 76으로 설정했습니다. 당연히 [SOS], [EOS] token을 문장 첫, 끝에 달아주었습니다. 그리고 [EOS] token은 highest layer of transformer에서 feature representation으로도 사용된다 합니다. 해당 feature representation이 결국 layer normalization -> linearly projected되어 multi-modal embedding space로 가는 원리입니다. 추가적으로 Masked self-attention이 text encoder에 사용되었는데, pre-trained language model의 ability를 preserve하기 위함이거나, language model에 auxiliary objective를 추가해주기 위함이라고 합니다. 이에 대해서는 추가 연구가 필요하다고 언급하고 있습니다.
이전의 computer vision research에서는 (Exploring the Limits of Weakly Supervised Pretraining Mahajan 2018 et al.)와 같이 model의 width나 depth중에 하나만 골라서 증가시켰습니다. (EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 2019 Tan & Le et al.,)에서는 이전 접근과는 다르게 width, depth, reslution간의 관계를 수식적으로 정의해서 최적의 조합을 찾아 model을 꾸렸는데 이는 우리가 너무잘 아는 EfficientNet입니다. 하지만 text-encoder에서 저자들은 width는 ResNet의 width와 맞춰주긴 했으나, 추가적으로 depth를 증가시키지는 않았는데 CLIP의 성능이 text-encoder의 크기에 덜 민감하다는 것을 알 수 있었기 때문이라고 합니다.
2.5. Training
저자들은 5종류의 ResNets와 3종류의 Vision Transformer(ViT)를 통해 학습했습니다. ResNet으로는 ResNet-50, ResNet-101 나머지 3개는 EfficientNet-style모델로 대략적으로 ResNet-50대비 4x 16x 64x 계산량의 모델을 사용했습니다. 논문에서는 이들을 RN50x4, RN50x16, RN50x64로 표기합니다. ViT로는 ViT-B/32, ViT-B/16, ViT-L/14를 사용합니다.
모든 모델은 32epochs동안 훈련시키며, Adam optimizer를 decoupled weight decay regularization(AdamW)과 함께 사용했습니다. 또한, cosine schedule로 learning rate를 scheduling했습니다. initial hyperparameter는 baseline ResNet-50에서 1epoch동안 훈련시키며 grid searches, random searches, manual tuning의 조합으로 정했습니다. 그리고 더 큰 모델에 대해서는 heuristically하게 적용해주었다고 합니다. 그리고 learnable temerature parameter $\tau$는 0.07로 설정하고, logits의 scale이 100이 넘지 않아 모델이 안정적으로 수렴하게 하기 위해 clipping도 합니다.

저자들은 32,768이라는 큰 minibatch size를 사용하며, training을 가속화하고 memory를 절약하기 위해 Mixed-Precision을 사용합니다. 추가적인 memory를 절약하기 위해 gradient checkpointing과 half-precition Adam statistics, half-precision stochastically rounded text encoder weights를 사용합니다. 그리고 공유되는 embedding similarities도 GPU간 공유할 수 있게 했답니다. ( 모르는 방법론들이 많습니다.. 이는 추후에 알아보겠습니다 )

가장 큰 ResNet모델인 RN50x64는 훈련시키는데 592 V100 GPU로 18days가 소모된다고 합니다. 추가적으로 가장 큰 ViT모델은 256 V100 GPU로 12days가 소모된다고 합니다. 그리고 ViT-L/14는 performance를 boosting하기 위해 336 pixel resolution으로 추가적인 epoch를 수행해주었는데, 이는 FixRes에서 제안한 방법입니다(FixRes는 train과 test간의 이미지 해상도 차이로 인한 문제점을 해결) resolution Experiment에서 이를 ViT-L/14@336px로 표기합니다. 그리고 기본적으로 아무 언급없이 CLIP이라고 말하는 모델은 best performance를 나타내는 ViT-L/14@336px를 말합니다.
3. Experiments
사실 방법론에서는 ConVIRT를 간단화한 것 밖에는 없었습니다. CLIP 논문의 상당한 부분을 차지하는 것이 CLIP입니다. 저는 그래서 Experiment의 내용이 저자들이 우리에게 하고자하는 말이 많을 것으로 판단했습니다. Experiment의 핵심 내용과 그 원리를 파악해보겠습니다.
3.1. Zero-shot Learning
3.1.2. Using CLIP for zero-shot transfer
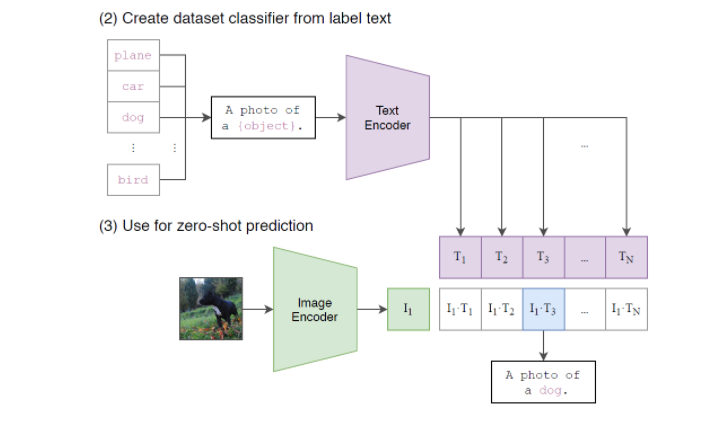
저자들이 소개한 CLIP의 zero-shot trasfer방법은 간단합니다. 이미지에 대한 Classifier를 학습하고자 한다면, 위와같이 구성을 한다음에, multimodal-embedding space를 구성합니다. 그리고 이에 대한 temerature paramter $\tau$를 설정하고, softmax를 취해주어 multi-nomial logistic regression을 진행합니다. 이런식으로 해석해봤을때 image encoder가 zero-shot을 위한 visual backbone의 핵심이 됩니다.
3.1.3. Initial comparison to visual n-grams

(Learning Visual N-Grams from Web Data. Li et al., 2017) 에서 보았던 visual n-grams는 성능이 별로 좋지 않았었습니다. ImageNet에 대해서 11.5%의 분류성능을 가졌었습니다. 이를 CLIP과 비교합니다.
3.1.3. Prompt engineering and ensembling

가장 흔한 문제는 다의성(polysemy)라고 합니다. CLIP의 text-encoder에 제공할 수 있는게 class name 하나뿐 이라면 모델은 context를 구별할 수 있는 능력이 없어집니다. 이는 같은 단어인데 다른 의미를 지칭하는 두 사물을 구별할 수 없는 상황이 예시가 될 수 있습니다. 또한 가장 중요한 문제점은 CLIP을 pre-train하는데 필요한 WIT dataset에는 이미지와 one-to-one matching되는 sentence가 드물다는 것입니다. 흔히 web상에서는 text는 full sentence를 이루게됩니다. 그래서 저자들은 이러한 간극을 매우기 위해 "A photo of a {label}."과 같은 template을 사용해서 text-encoder의 input으로 구성했습니다. 저자들이 실험을 한 결과 이는 아주 좋은 기본 template이었다고 합니다. 또한, 이를 통해서 single word를 통해 CLIP을 구성한 baselie model보다 performance도 증가했다 합니다.
그리고 GPT-3과 비슷하게 prompt-engineering을 했더니 zero-shot performance도 확연하게 증가했답니다. 각각의 task에 맞춤형 prompt template을 제공하는 것이죠. 예를 들면 Oxford-IIIT Pets에는 "A photo of a {label}, a type of pet."이런식으로 제공합니다. 그리고 서로 다른 context prompts를 이용해서 multiple zero-shot classifier를 ensembling한 실험도 있습니다. "A photo of a big {label}"과 "A photo of a small {label}"을 ensembling할 수 있습니다. 이러한 ensembling은 probability space가 아닌 embedding space에서 진행된다 합니다. Figure 4를 보면 ImageNet에 대해서는 5%에 가까운 성능향상을 이끌어 낸 것을 볼 수 있습니다.
3.1.5. Analysis of zero-shot CLIP performance
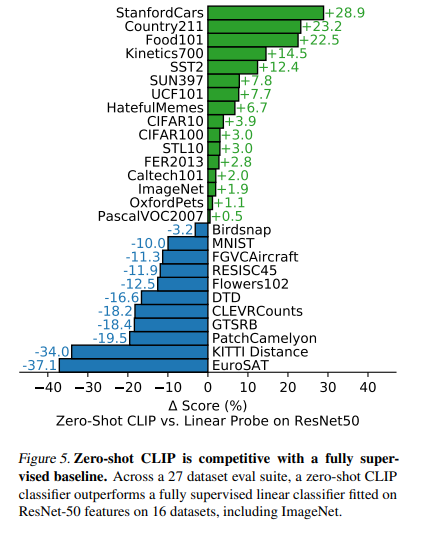

저자들은 CLIP이 어떻게(how) zero-shot classifier에서 잘 작동하는지 확인하고 싶었다 합니다. 그래서 저자들은 fully supervised, regularized, logistic regression classifier on ResNet-50을 Linear Probe에서 적용되도록 만들었고, Figure 5와 같이 27개의 dataset에 대해서 비교했습니다.
16/27개의 dataset에서 zero-shot transfer가 성능이 Linear Probe on ResNet50을 이겼습니다. 이를 통해 StanfordCars, Food101과 같은 fine-grained classification tasks에서는 CLIP의 zero-shot이 성능이 더 좋았습니다. 하지만 Flowers102, FGVCAircraft와 같은 dataset에서는 zero-shot의 성능이 더 좋지 않았습니다. 저자들은 이러한 원인이 WIT와 ImageNet사이의 per-task간의 supervision 양 차이에 있을것이라고 합니다. STL10에서는 99.3%의 정확도로 SOTA를 달성하였습니다.
zero-shot CLIP은 몇몇의 specialized되어있고, 복잡하며, 추상적인 task에 대해서는 성능이 떨어집니다. 대표적으로 satellite image classification (EuroSAT, RESISC45), lymph node tumor detection (PatchCamelyon), counting objects in synthetic scenes (CLEVRCounts),, etc는 CLIP의 복잡한 task에 대해서의 한계를 보여줍니다. 이러한 task들은 non-expert의 사람이 robustly하게 수행할 수는 있습니다. 저자들은 이러한 task들은 zero-shot trasfer와 비교할게 아니라 few-shot trasfer와 비교하는게 맞을것 같다고 합니다. Figure 6을 보면 zero-shot CLIP은 4-shot linear classifier와 비슷하고, ImageNet으로 pre-trained된 16-shot BiT-M, SimCLRv2와 비슷합니다. Figure 6에서는 20개의 datasets, 16 examples per task를 사용했다고 합니다. 나중에 Section 3.2에서 보겠지만 Zero-shot CLIP을 fully-supervised했을 때 현 SOTA인 Noisy Student EfficientNet-L2보다 5%성능이 높았다고 합니다.


Figure 7에서는 zero-shot CLIP과 같은 성능을 내는 logistic regression classifier를 만들기 위해 class마다 몇개의 labeled example이 필요한지를 보여주고 있습니다. 이는 zero-shot CLIP의 data-efficiency를 보여줍니다.
Figure 8에서는 zero-shot performance와 linear probe performance간의 correlation을 보여주는데, zero-shot performance가 거의 sub-optimal한 관계를 가짐을 그래프로 보여주고 있습니다.

Figure 9에서는 Zero-shot CLIP이 model scale에 따라 smooth하게 scale하는 것을 볼 수 있습니다.
3.2. Representation Learning
이전 Section 3.1에서는 CLIP의 zero-shot trasfer성능을 봤습니다. 하지만, model의 representation learning capabilities를 연구하는 것이 더 일반적입니다. 일반적으로 linear classifier를 extracted feature에 fitting시키는 방법이 일반적입니다. 또 다른 방안으로는 end-to-end fine-tuning방법이 있습니다. 이는 더 유연성있게 모델을 tuning시킬 수 있으며, 일반적으로 후자가 전자보다 성능이 더 좋습니다. 하지만 저자들은 linear-classifier를 Section 3.2에서 사용합니다. 그 이유는 CLIP은 data-agnostic pre-training을 high-performance로 수행되는 것에 집중합니다. 하지만, Fine-tuning을 하게되면, 특정 down-stream task로 feature space가 변할 수 있기 때문에, 모델의 일반화 성능을 어느정도 masking하는 역할을 하게 되어 실험을 할 수 없기 때문입니다. 이러한 이유에서 저자들은 제한된 유연성에도 모델의 failure인 부분을 찾아내고 feedback을 받기 위해 Lienar classifiers을 하고자 합니다.

Figure 10에서는 Linear probe average score를 12, 27개의 dataset에 대해 측정합니다. 크기가 낮은 ResNet모델 몇개에서는 SOTA보다 낮은 성능을 보이지만, 큰 모델인 RNx64, ViT기반 모델들에 대해서는 SOTA를 모두 앞섭니다.

Appendix에서 이에 실험한 qualitative example들을 볼 수 있습니다.

Figure 11은 EfficientNet과 비교한 그래프입니다.
3.3. Robustness to Natural Distribution Shift
기본적으로 기계학습에서 딥러닝 모델들은 training dataset에 in-distribution에 대한 correlations를 과도하게 맞추려고 합니다. 이로 인해 model의 overfitting위험의 가능성이 있게 되는 것인데, 이는 training set과 test set의 distribution이 동일할 것이라는 가정에 기초해 있기 때문입니다. 이런 개념을 distribution shift이라고 합니다. 해당 링크로 들어가면 Batch Normalization때문에 유명한 covariance shift부터 실무에서 중요시 여기는 distribution shift개념에 대해 잘 설명합니다. 실제로 이러한 문제를 방지하기 위해, distribution에 invariant한 어떤 것을 뽑는 것이고 이를 Domain Generalization이라고 합니다. 그리고 해당 Section 3.3에서는 CLIP이 Distribution Shift에 얼마나 robust한지 Experiment결과로 보여줍니다.

Figure 12는 CLIP의 feature가 ImageNet에 pre-trained된 models보다 task shift에 robust함을 보여주고 있습니다. 같은 ImageNet Score에 대해 CLIP의 average transfer score가 훨씬 높습니다.

Figure 13은 zero-shot CLIP에 대해 ImageNet model의 natural distibution shifts된 것(ImageNetV2, ImageNet-R, ObjectNet, ImageNet Sketch, ImageNet-A)들과의 비교를 합니다. 거의 대부분의 zero-shot CLIP의 성능은 ImageNet의 76.2%에서 크게 벗어나지 않는 정확도를 보여주었고, ImageNet ResNet101과의 gap을 75%까지 올렸습니다.
이러한 결과는 무조건 ImageNet으로 supervised learning하는게 robustness gap을 일으키는 것이 아니라는 것을 시사합니다. CLIP은 large diverse pre-training dataset인 WIT으로 pre-trained되었기 때문에, fine-tuning되어도 robustness한 모델을 만들 수 있다고 합니다. 이를 증명하기 위해, CLIP 모델을 ImageNet distribution으로 L2 regularized logistic regression classifier를 fitting시키며 알아보겠습니다.

Figure 14에서 ImageNet으로 Adap한 것이 정확도 9.2%를 상승시켰습니다. 이는 근 3년간의 성능향상과 맞먹는 엄청난 결과이지만, 이는 항상 distribution shift된 상황에서도의 성능 향상을 뜻하는 것은 아닙니다. 우측 상단 그래프를 보면, ImageNet과 distribution이 비슷한 ImageNetV2, Youtube-BB에 대해서만 성능향상이 일어난 것을 볼 수 있고 나머지는 성능이 떨어진 것을 볼 수 있습니다. 이러한 결과의 원인을 저자들은 "exploting supurious correlations"이라고 합니다. 즉 불필요한 상관관계를 활용했다는 것이죠.
그리고 우측 하단의 그래프는 서로 다른 dataset에 대해서 ImageNet을 bais로 trasfer시킨 결과입니다. 좌측 그래프에서 이는 5%의 robustness improvement를 달성했지만, 이는 소수의 dataset에 대한 large improvement의 결과였습니다. ObjectNet을 유심히 볼 필요가 있는데, 좌측 상단에서는 상승하지 않았는데, 왜 여기서는 상승했나 궁금할 수 있습니다. 이는 ObejctNet의 창작자가 ImageNet의 class와 긴밀하게 overlap되게 만들었기 때문입니다. 그리고 해당 실험은 각각의 dataset의 class크기를 맞춰주기 위해 pooling prediction을 사용했기 때문에 이러한 결과가 나타난 것입니다.
즉 Figure 14가 하고싶은 말은 Zero-shot CLIP은 기존 standard ImageNet model보다 distribution shift에 훨씬 robust하다는 것입니다. 그리고 결국 CLIP을 fully-supervised로 갈 수록 이러한 robustness의 장점은 사라진다는 것이죠. 이를 Figure 15에서 zero-shot에서 n-shot(fully-supervised)로 가면서 실험합니다.

이처럼 CLIP을 few-shot학습을 시키면 해당 task는 더 잘 풀게 되지만, zero-shot CLIP에 비해서 robustness가 떨어진다는 사실을 위 그래프를 통해 알 수 있습니다.
4. Comparison to Human Performance
본 Section에서는 CLIP을 사람의 performance와 learning하는 정도에 대해 비교합니다. 저자들은 사람의 zero-shot성능과 더불어 예시를 더 보여주었을때의 few-shot성능의 zero-shot과 비교했을때의 상승 정도를 측정합니다. 이를 통해 저자들은 human과 CLIP에 있어서 task difficulty를 측정하고 이 둘간의 차이와 상관관계를 측정하고자 하는 것을 목표로 합니다. 실험 절차는 아래와 같습니다.
- 데이터셋은 Oxford IIT Pets dataset을 사용합니다.
- 5명의 다른 사람에게 test split의 3669개의 이미지를 주고 37종류의 개/고양이 중 어느 것인지(혹은 I don't know를 고를 수 있음)을 선택하게 합니다.
- 5명의 사람은 인터넷 검색 없이, 아무런 예시도 보지 못한채 이미지를 labeling합니다.
- one-shot, two-shot의 경우 각각 1, 2개의 예시를 본 다음 labeling합니다.
- 기본적인 class에 대한 설명은 주어줍니다.

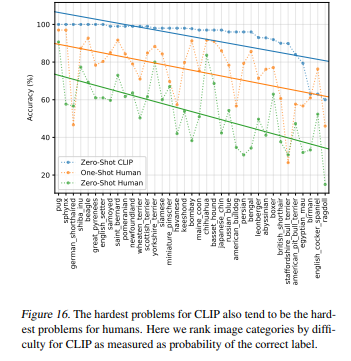
Table 2를 보면, CLIP의 성능이 사람과 비교했을때 모든 측면에서 뛰어난것을 볼 수 있습니다. 심지어 3번째 column의 데이터는 사람이 labeling할 때 I don't know한건 뺀 것인데, 그래도 CLIP이 우세했다. 뿐만 아니라 4번째 column은 피험자들이 가장 많이 고른 것으로 labeling을 한 것인데, 그래도 CLIP보다 정확도가 낮은것은 변하지 않았다.
FIgure 16을 보면, CLIP이 어려워했던 문제(labeling)은 human도 똑같이 어려워했음을 볼 수 있습니다.
5. Data Overlap Analysis
대규모 데이터셋을 통해 pre-training할때에 걱정거리중 한가지는 down-stream eval task과 data가 overlap되는 것입니다. 이는 매우 중요한데, 최악의 시나리오에서 pre-training dataset이 eval dataset에 통째로 leak되어서 evaluation결과가 부정확하고 일종의 cheating이 될 수도 있습니다. 그래서 원칙적으로는 겹치는 데이터가 없어야 down-stream task에 대해 정확한 성능을 측정할 수 있습니다.
이를 방지하기 위한 방법은, dataset에서 모든 중복된 data를 제거하는 것입니다. 하지만 이는 model이 evaluate할 모든 가능한 data를 알고있어야 하고, benchmarking과 이후 분석 범위에서 제한이 돌 수 있게됩니다. 대신 저자들은 CLIP은 데이터가 얼마나 겹치는지, 그리고 이러한 overlap된 데이터가 얼마나 CLIP의 성능에 영향을 주는지 평가를 합니다. 만약 별 영향이 없다면, 조금 겹쳐도 모델의 성능이 충분히 좋다고 얘기할 수 있기때문입니다.
- 각 평가 데이터셋마다 얼마나 겹치는지 duplicate detector를 만들어 사용합니다. 그리고 가장 가까운 이웃을 찾고 데이터셋마다 recall을 최대화하면서 높은 precision을 유지하도록 threshold를 겁니다. 이 제한을 사용해서 2개의 두 부분집합을 만든다.
- Overlap: 위 threshold 하에서 training example과 일정 이상 유사한 모델 example을 포함한다.
- Clean: threshold 이하의 모든 example을 포함한다.
- All: 아무 수정도 가하지 않은 전체 데이터셋.
- All 대비 Overlap 비율을 측정하여 오염도(the degree of data contamination)를 기록한다.
- 위 3개의 split에 대해 zero-shot CLIP 성능을 측정하고 All - Clean을 주요 측정 지표로 사용한다. 이 측정 결과는 데이터 오염도에 따라 차이가 있을 것이다. 만약 양의 값을 가지면 측정된 정확도 중 얼마만큼이나 오염된 데이터에 의해 부풀려졌는지 확인할 수 있을 것이다.
- overlap된 정도가 낮을 경우 binomial significance test도 수행하고(null hypothesis로 Clean에서의 정확도 사용), Overlap 부분집합에 대해 one-trailed(greater) p-value 값을 계산한다. Dirty에서 99.5% Clopper-Pearson confidence interval 또한 계산한다.

Figure 17은 이에 대한 결과인데, 일부의 경우에서 data overlap으로 인한 정확도가 부풀려진 것을 볼 수 있습니다. 왼쪽 그래프를 보면 5/35 dataset에서만 99.5% 신뢰구간을 벗어납니다. 2개의 dataset(ImageNet Sketch, Kinetics-700)에서는 overlap이 발생했는데, 오히려 더 성능이 낮은점을 볼 수 있습니다. 오른쪽 그래프를 보면 detector로 탐지한 overlapping example의 비율이 한 자리수라서 test 정확도 향상이 전체에 비해 크지 않습니다.
6. Limitations
CLIP의 한계점에 대해 몇개 짚어보겠습니다.
- zero-shot CLIP이 simple supervised baseline(ResNet-50, 101)에 비해 좋긴 한데, 현재 SOTA에 비하면 현저히 낮은 성능을 가지는 모델입니다. 저자들은 zero-shot CLIP이 SOTA와 동등한 성능을 가지게 되려면 계산량이 1000배는 증가해야할 것이라고 합니다. 현재 기술력으로는 불가능하므로 이는 추후 연구방향이라고 합니다.
- zero-shot CLIP의 성능이 강한 부분도 있지만 그렇지 못한 부분도 많다고 합니다. CLIP은 세분화된 분류문제에서 특히 약합니다. 또한, 사진에서 가장 가까운 자동차까지의 거리를 분류하는 task와 같은, CLIP이 pre-train시에 학습했을리 없는 새로운 task에 대해서는 정답률이 처참하다는 단점이있습니다.
- CLIP은 high-quality의 OCR representation을 학습하지만, MNIST에서는 88%정확도밖에 도달하지 못합니다. 그 이유는 pre-train dataset에 MNIST의 손글씨와 유사한 example이 거의 없기 때문일 것이라고 하며, 이러한 결과는 CLIP이 일반적인 딥러닝 모델이 가지고 있는 일반화(generalization)이라는 문제를 해결하지 못했음을 의미합니다.
- 4억 개의 이미지를 1초에 하나씩 32 epoch을 수행하면 405년이 걸리는데, 이럿듯 데이터 활용률이 낮습니다.
- CLIP은 인터넷에서 수집한 데이터로 학습했기 때문에, 사회적 편견등이 똑같이 학습되어 윤리적인 문제점이 발생할 수 있습니다.
7. Broader Impacts
CLIP의 확장 가넝성은 당연히 뛰어난 zero-shot과 image representation을 학습한다는데에 있어서, 다양한 분야에 활용될 수 있습니다. OCR을 수행할수도, action recognition, sentimantal recognition뿐만 아니라 감시분야에도 사용될 수 있습니다.
7.1. Bias
Section 6마지막에서 언급한 CLIP의 윤리적인 문제점에 대해 다룰려 합니다. 사회적 편견은 데이터셋에 그대로 녹아들어가 있고, 이를 통해 학습하는 모델 역시 이를 그대로 학습합니다. 논문에서는 FairFace benchmark dataset으로 실험을 진행하였습니다.
FairFace에 있는 class에 새로운 class name들을 추가했습니다('동물', '고릴라', '침팬치', '오랑우탄', '도둑', '범죄자', '수상한 사람'). 이것의 목표는 CLIP이 비하표현의 피해가 특정 인구통계학적 하위 그룹에 영향을 끼치는지 확인하고자 하는 것입니다. 이때, 전체 이미지의 4.9%는 분명 사람의 이미지임에도 위에서 추가한 class로 잘못 분류되었습니다. '흑인'이 14%정도로 가장 높은 오분류 비율을 보였습니다. 0~20세 이하의 사람이 그 이상의 사람보다 오분류율이 높았습니다. 또한, 남성은 16.5%가 범죄와 관련된 class('도둑', '수상한 사람', '범죄자')로 분류된 반면 여성은 9.8%만이 범죄자 관련 class로 분류되었습니다.

Figure 18을 보면 이러한 편향의 결과를 볼 수 있습니다.
이처럼 CLIP에 대해 알아보았는데, 정말 실험결과가 많고 배울 것이 많은 논문이였습니다. 하지만 OpenAI가 코드를 올리지 않는 바람에 어떻게 구현되어있는지 확인하기 힘들다는 점이..좀 그렇습니다. 다음에는 Latent Diffusion Model에 대해 알아보겠습니다.