![[ 딥러닝 논문 리뷰 ] - GLASS Flows: Transition Sampling For Alignment (ICLR 2026)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FeckAcv%2FdJMcaaYVfjN%2FAAAAAAAAAAAAAAAAAAAAAHIb_9T38afZf-I1-9OsSh9vgqSbwvqSjnP1uzFUxwLA%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DllDanD%252FnQL8Y7UYO2lDQBMYQGC4%253D)
안녕하세요, 벌써 막학기 학부 생활이 시작되었고 학부 연구생 생활도 열심히 해 나가고 있습니다. 최근에는 Diffusion, Flow model에서의 Inference-time scaling에 관심이 많아져서 관련 논문을 보고 있었습니다. 그러던 중 ICLR 2026에 GLASS Flows라고 하는 논문을 찾게 되었고, Flow Matching의 저자인 Lipman형님과, Ricky Chen형님의 논문이라는걸 알았고 재밌어 보여서 읽었다가, 너무 많은 수식에 혼절 직전까지 왔었습니다. 이에 2일정도를 논문 읽는데에 쏟아부었고 재밌는 논문인거 같아서 리뷰를 해보려고 합니다. 이제 곧 대학원 입시이기도 한데, 파이팅 해야겠습니다!
paper: https://arxiv.org/pdf/2509.25170
github: https://github.com/PeterHolderrieth/glass_flows_tutorial
GitHub - PeterHolderrieth/glass_flows_tutorial
Contribute to PeterHolderrieth/glass_flows_tutorial development by creating an account on GitHub.
github.com
1 Introduction
최근에 많은 연구들이, inference-time에 model을 발전시키는 방향으로 연구가 진행되었습니다. 추가적인 reward를 최적화하면서 finetuning하는 것과 같은 방법들이 있습니다. 이러한 reward alignment 방법은, text-to-image alignment, inverse problem, molecular design과 같은 분야에 적용되었습니다. 하지만 이러한 알고리즘은, 좋은 성능을 내는데에 아주 많은 컴퓨팅 시간을 필요로 했습니다. 그래서 이러한 효율성이 이 분야에서 가장 큰 문제입니다.
diffusion, flow 모델에서의 inference는 보통 다음 2개의 방법으로 이루어집니다.
- ODE sampling: flow matching에서 사용되며, diffusion모델에서의 probability flow ODE를 풀때 사용됩니다.
- SDE sampling: 기본적인 diffusion모델
경험론적으로, ODE sampling이 보다 효율적으로 결과물을 샘플링할 수 있습니다. 하지만, SDE샘플링을 사용하면, randomness가 reverse time에 적용이 되면서, $$ p_{t' \mid t} (x_{t'} \mid x_t) = \mathbb{P} [X_{t'} = x_{t'} \mid X_t = x_t] $$ 같은 transition probability로 특성화되게 됩니다. 여기에서 $p_{t'|t}(x_{t'}|x_{t})$를 transition kernel이라고 하며, 많은 reward alignment algorithm이 transition kernel에 의존합니다. 이 randomness가 SDE sampling의 가장 큰 장점이자 특징인 것이죠. 하지만 ODE에서 SDE 샘플링으로 넘어가면, ODE 샘플링의 효율성을 잃게됩니다.
그래서 저자들은 $p_{t'|t}$를 ODE로부터 샘플링을 할 수 있는 Gaussian Latent Sufficiernt Statistic (GLASS) Flows를 제안합니다. GLASS Flows는 다음과 같은 특징이 있습니다.
- ODE의 높은 효율성을 통합
- SDEs의 controllable stochastic evolution을 통합
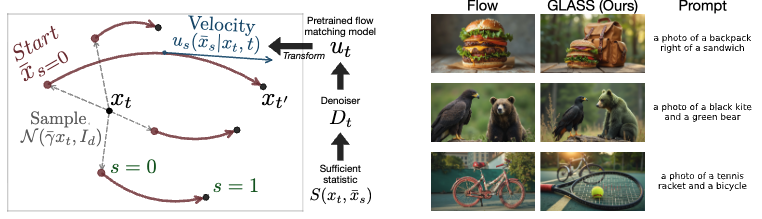
이를 위해 저자들은 inner flow matchin model을 통해 $p_{t'|t}$를 샘플링하게 하였는데요, 이 inner model은 pre-trained flow matching모델로부터 쉽게 얻을 수 있게 설계했습니다. 이러한 추가 학습이 필요없는 inner model은 sufficient statistics라는 이론 통계학 개념에 강하게 의존합니다. 그리고 GLASS Flows는 어느 SDE sampling 알고리즘에 plug-in으로 간단히 적용 가능합니다. 저자들은 실험에서 GLASS Flow로 reward alignment로 text-to-image generation에서 SOTA를 낼 수 있었다고 합니다.
2 Background and Motivation
이 섹션에서는 flow matching (FM) framework위주로 background설명을 합니다, 비슷하게 diffusion에서도 적용 가능합니다. 본 논문에서는 $z \in \mathbb{R}^d$로 실제 data distribution $p_{data}$를 나타냅니다. 그리고 flow matching표기와 동일하게 data point는 timestep $t=1$을 뜻하고 noise는 $t=0$을 말합니다. noise data를 표시하기 위해, Gaussian conditional probability path $p_t(x_t|z)$를 다음과 같이 표현합니다.
$$x_t = \alpha_t z + \sigma_t \epsilon,\ \ \ \ \epsilon \sim \mathcal{N}(0,I_d)\ \ \Leftrightarrow\ \ p_t(x_t|z)=\mathcal{N}(x_t;\alpha_t z, \sigma_t^2I_d)$$
$z\sim p_{data}$는 marginal probability path인 $p_t(x_t) = \mathbb{E}_{z\sim p_{data}}[p_t(x_t|z)]$를 만들 수 있습니다. 이는 Gaussian noise인 $p_0 = \mathcal{N}(0, I_d)$와 $p_1 = p_{data}$를 interpolate하는 probability path라고 할 수 있고, GMM이라고도 볼 수 있겠습니다. 결과적으로 FM모델은 marginal vector field를 아래와 같이 학습하게 됩니다.
$$u_t(x_t) = \int u_t(x_t|z)p_{1|t}(z|x_t)dz,\ \ \ p_{1|t}(z|x_t) = \frac{p_t(x_t|z)p_{data}(z)}{p_t(x_t)}$$
$u_t(x_t|z)$는 conditional vector field를 나타냅니다. 이 marginal vector field를 초기 Gaussian noise로부터 ODE를 simulation하게 되면 trajectory는 $p_t$라는 marginal이 됩니다.
$$X_0 \sim p_0,\ \ \ \frac{d}{dt} X_t = u_t(X_t)\ \ \ \Rightarrow \ \ \ X_t \sim p_t$$
diffusion에서는 이러한 ODE sampling 방식을 probability flow ODE라고 합니다. 추가적으로 DDIM논문에 있었던 time-reversal SDE를 통해 데이터를 샘플링 할 수도 있습니다.
$$X_0 \sim \mathcal{N}(0, I_d),\ \ \ dX_t = [u_t(X_t)+\frac{v_t^2}{2}\bigtriangledown\log p_t(X_t)]dt + v_tdW_t,\ \ \ v_t^2=2\frac{\dot{\alpha}_t}{\alpha_t}\sigma_t^2-2\sigma_t\dot{\sigma}_t$$
여기에서, $\bigtriangledown\log p_t(x_t)$는 score function을 뜻하며, 위에 점이 붙은건, scheduler의 time-derivations를 뜻합니다. 이를 우리는 DDPM sampling이라고 하고, 여기서 말하는 score function은 위에서 말한 $u_t$로 reparameterization할 수 있습니다. $u_t$를 훈련한 동일 neural network를 통해서 SDE simulation을 할 수 있다는 것입니다.
3 Motivation: Efficient Transitions for Reward Alignment
Inference-time reward alignment에서 원하는건 $p_{data}$가 아닙니다. post-training을 함으로써, $p_{data}$를 prior distribution으로 함으로써, user-specified objective로 분포를 steer하는 것을 목표로 합니다. 여기에서 reward objective function $r: \mathbb{R}^d \rightarrow \mathbb{R}$을 reward function이라고 합니다. 목표는 아래와 같은 reward-tilted distribution을 만드는 것을 목표로 합니다.
$$p^r(z) = \frac{1}{Z_r}p_{data}(z)exp(r(z))\ \ \ (Z_r > 0)$$
여기에서 likelihood인 $p^r(z)$은 $p_{data}(z)$보다 높으며, $r(z)$가 높다. 다음으로는 대표적인 3가지 reward alignment algorithm을 소개하고, 어떻게 이러한 방법들이 $p_{t'|t}$에 의존하는지 보겠습니다.
3.1 Sequential Monte Carlo (SMC) methods
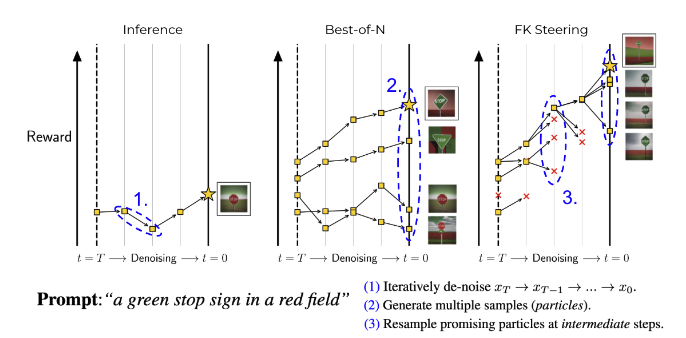
$p_{t'|t}$를 proposal distribution으로 활용하는 방법입니다. particle filter를 생각하면 쉬운데, $K$개의 particle $x_t^k$를 다음과 같이 뽑습니다.
$$x_{t'}^k \sim p_{t'|t}(\cdot|x_t^k)\ \ \ (0 \leq < t' \leq 1, k=1,\cdots,K)$$
이 particle은 potential 함수인 $G(x_t, x_{t'})$를 통해서 우리가 원하는 tilted distribution으로 guiding됩니다. FK-steering이 논문에서 제안하는 3가지 potential함수등이 예시가 되겠습니다. particle은 다음과 같이 multinomial분포로 샘플링됩니다.
$$\underbrace{a_{t'}^k \sim \text{Multinomial}(G(x_t^1,x_{t'}^1),...,G(x_t^K,x_{6'}^K))}_{\text{sample indices}},\ \ \ \ \underbrace{x_{t'}^k=x_{t'}^{a_{t'}^k}}_{\text{reassign particles}}\ \ \ (k=1,\cdots,K)$$
이는 결국에 SMC를 순차적으로 unpromising particle을 promising한 것으로 대체하는 것을 말합니다.
3.2 Search methods
DDPM sampling을 search tree branch의 $p_{t'|t}$로부터의 rollout이라고 생각하는 것입니다. 이러한 search based 방법들은, value function을 고려하는데 아래와 같이 정의됩니다.
$$V_t(x_t)=\log \mathbb{E}_{z\sim p_{1|t}(\cdot|x_t)}[\text{exp}(r(z))],\ \ \ \ \text{where}\ p_{1|t}(z|x_t)=p_t(x_t|z_{p_{data}}(z)/p_t(x_t))$$
tree의 각 노드를 평가하기 위해, $V_t$를 사용하며, 이는 flow matching posterior인 $p_{1|t}$에 의존합니다. $p_{1|t}(z|x_t)$와 같은 posterior분포로부터 샘플링하는 것은 오직 SDE를 푸는 것 밖에 답이 없기때문에, 이 연산은 매우 비효율적입니다. 그래서 대부분의 논문에서는 이 $V_t(x_t)$를 근사해서 사용하고, 위의 SMC에서 potentials로도 사용할 수 있습니다.
3.3 Guidance methods
guidance method는 marginal vector field인 $u_t$를 intermediate reward function $r_t$를 사용해서 수정하는 방식입니다.
$$u_t^r(x)=u_t(x)+c_t\bigtriangledown r_t(x)\ \ \ (c_t \geq 0)$$
이상적인 상황에서의 $r_t(x)$는 $V_t(x)$입니다, 이는 말했다 싶이 계산적으로 매우 비효율적이기에 근사합니다 또한, SMC과정을 correcting하는데에 사용되거나, SDE 샘플링에 사용합니다. 구체적으로 SMC에서 proposal에 $\bigtriangledown r_t(x)$항을 추가해서 dirft를 더 상세하게 refine하는 역할을 하게 됩니다. 이는 guided proposal + SMC correction 같은 이름으로 자주 등장하는 개념중에 하나입니다.
3.4 GLASS Flows motivation
본 논문의 핵심 motivation은 위와같은 novel한 reward alignment algorithm을 제안하는 것이 아닙니다. 저자들은, 위에 사용되는 transition을 최적화하는것에 해당합니다. 저자들의 목표는 아래와 같습니다.

이제 천천히 이게 무슨 내용인지 알아보겠습니다.
4. GLASS Flows
우리의 목표는 transition kernel로부터 $X_{t'}\sim p_{t'|t}(x_{t'}|x_t)$입니다. 저자들은 transition kernel을 디자인 하기 위해 inner flow matching model인 $u_s(\bar{x}_s|x_t,t)$를 새로운 time variable인 $s (0 \leq s,t \leq 1, \bar{x}_s, x_t \in \mathbb{R}^d)$를 정의합니다. 우리의 목표를 수식적으로 표현하면 아래와 같습니다.
$$\bar{X}_0 \sim p_{init},\ \ \ \ \frac{d}{ds}\bar{X}_s = u_s(\bar{X}_s|x_t,t)\ \ \ \ \Rightarrow \bar{X}_1 \sim p_{t'|t}(\cdot|X_t=x_t)$$
우리는 정확히 $p_{init}$에서 시작하여 $s=1$에서 transition kernel에서 샘플링할 수 있는 결과를 얻어야 합니다. 또한, 저자들은 stochasticity를 initial condition인 $\bar{X}_0$을 샘플링함으로써 가능하게 합니다. 그 이후의 transition은 ODE를 따르므로 deterministic하게 됩니다. 이에 대한 의사 코드는 아래와 같습니다.

이제 이 의사 코드가 뭐를 의미하는지 자세히 알아보겠습니다.
4.1 GLASS Transitions
먼저 우리는 trnasition family를 정의해야합니다. $X_t, X_{t'}$를 아래와같은 probability path에서 정의한 marginal을 가질 수 있도록 정의합니다.
$$X_t \sim \mathcal{N}(\alpha_tz,\sigma_t^2I_d),\ \ \ X_{t'}\sim\mathcal{N}(\alpha_{t'}z,\sigma_{t'}^2I_d)\ \ \ (z\sim p_{data})$$
또한, data point $z \in \mathbb{R}^d$가 있을때, 각각 차원의 mean, variance는 고정됩니다. 하지만 우리는 이러한 transition family에서 자유도 하나를 가질 수 있게 설정하는데 $X_t, X_{t'}$간의 correlation인 $-1 \leq \rho \leq 1$입니다. 구체적으로 아래와같이 mean scale $\mu$와 covariance인 $\Sigma$를 정의합니다.
$$\mu= \begin{pmatrix} \mu_1\\ \mu_2 \end{pmatrix} = \begin{pmatrix} \alpha_t\\ \alpha_{t'} \end{pmatrix}, \qquad \Sigma= \begin{pmatrix} \Sigma_{11} & \Sigma_{12}\\ \Sigma_{21} & \Sigma_{22} \end{pmatrix} = \begin{pmatrix} \sigma_t^2 & \rho \sigma_t\sigma_{t'}\\ \rho \sigma_t\sigma_{t'} & \sigma_{t'}^2 \end{pmatrix}$$
그리고 우리는 joint distribution인 $X = (X_t, X_{t'})^T$를 다음과 같이 정의합니다.
$$\begin{equation} X \sim p_{t,t'}(X\mid z) = \prod_{j=1}^d \mathcal{N}\!\left( (X_t^{j}, X_{t'}^{j});\, z^{j}\mu,\, \Sigma \right), \qquad z=(z^1,\ldots,z^d)^\top \sim p_{\text{data}}. \tag{12} \end{equation}$$
각각의 좌표는 똑같이 독립적으로 noised됩니다. 또한, correlation을 좌표차원에 대해서 정의할 수 없고, 오직 time에 대해서만 정의합니다. 이를 통해 transition family $p_{t',t}(X_t,X_{t'})$은 baye's theroem에 따라 conditional distribution을 아래와 같이 정의할 수 있게됩니다.
$$\begin{equation} p_{t'\mid t}(X_{t'}\mid X_t) = \frac{p_{t,t'}(X_t, X_{t'})}{p_t(X_t)}. \tag{13} \end{equation}$$
이를 이 논문에서는 GLASS transition이라고 정의합니다. 중요한점은, $\rho = \frac{\alpha_t \sigma_{t'}}{\sigma_t \alpha_{t'}}$로 두면, $p_{t'|t}^{\text{DDPM}}(X_{t'}|X_t)=p_{t'|t}(X_{t'}|X_t)$와 같이 정의할 수 있는데, 이 말은 DDPM transition은 GLASS transntion의 special case라는 점입니다. 여기에서 $\rho$는 $X_t, X_{t'}$간의 similarity를 조절하는 역할을 하게 됩니다.
4.2 Constructing the Velocity Field
$D_t$인 Denoiser를 다음과 같이 expected of posterior로 reparameterize할 수 있습니다.$$\begin{equation} D_t(x) = \int z\, p_{1\mid t}(z\mid x)\,dz = \frac{1}{\dot{\alpha}_t \sigma_t - \alpha_t \dot{\sigma}_t}\Big(\sigma_t\,u_t(x) - \dot{\sigma}_t\,x\Big). \tag{14} \end{equation}$$
이 수식의 두번째 항을 보면 denoiser는 velocity field인 $u_t$를 reparameterizing함으로써 구할 수 있다는것을 볼 수 있습니다. 즉 이걸로 Denoiser의 output을 통해 $u_t$를 구할 수 있는 것입니다. 이제부터는 $D_t$를 이용해서 우리가 원하는 velocity field인 $u(\bar{x}_s|x_t,t)$를 구할 수 있는 방법에 대해 다루겠습니다.
4.2.1 GLASS Denoiser
우리는 GLASS denoiser를 $x_t, x_{t'}$가 주어졌을때 expected posterior로 정의할 수 있습니다.
$$\begin{equation} D_{\mu,\Sigma}(x) = \int z \, p(Z=z \mid X=x)\, dz, \qquad x=(x_t,x_{t'}),\;\; x_t,x_{t'}\in\mathbb{R}^d . \tag{15} \end{equation}$$
noisy $x_t$는 $z$에 대한 measurement입니다. DDPM에서와 같이 정석적인 denoiser $D_t$는 하나의 Gaussian measurement인 $x_t$가 주어졌을때의 평균 $z$였습니다. 하지만, GLASS Denoiser에서는 inner model때문에, 2개의 Gaussian measurements $(x_t, x_{t'})$로부터 평균 $z$를 Denoiser $D_{\mu, \Sigma}$로 부터 구해야합니다. 이를 우리는 GLASS Denoiser라고 합니다. 우리는 또한, single denoiser step만으로 수행하고 싶기 때문에, 이 2개의 measurements $(x_t, x_{t'})$를 효율적이고 합리적으로 요약해야합니다. 이때 사용되는 것이 sufficient statistic이고 아래와 같이, 구할 수 있습니다.
$$S(x)= \frac{\mu^\top \Sigma^{-1} x}{\mu^\top \Sigma^{-1} \mu}, \qquad x=(x_t,x_{t'})^\top \in \mathbb{R}^{2\times d}$$
이론 통계학에서는, $S(x)$를 sufficient static이라고 합니다. 이는 매우 직관적인데, $S(x)$는 계산해보면 $x_t, x_{t'}$의 가중합꼴이 됩니다. 이 가중합의 의미는, measurement가 더 $z$같을 수록(lower variance, higher scale) 더 높은 가중치를 주는 원리입니다. 이제, 어떻게 GLASS Denoiser를 적용할까에 대한 생각을 해봐야 합니다. 먼저, 우리가 정의한 $S(X) | Z$의 확률분포는 다음과 같이 정의되게 됩니다. $$S(X)\mid Z=z \sim \mathcal{N}\!\left(z,\ \frac{1}{\mu^\top\Sigma^{-1}\mu}\right)$$ 그리고 FM denoiser는 measurement가 $X_t = \alpha_t Z + \sigma_t \epsilon$형태일 때를 처리합니다. 그래서 FM denoiser가 익숙한 입력 분포와 똑같이 만들기 위해 먼저 스케일을 $Y := \alpha_{t}S(X)$ 이렇게 맞춰줍니다. 그러면 $Y\mid Z=z \sim \mathcal{N}\!\left(\alpha_{t}z,\ \alpha_{t}^2(\mu^\top\Sigma^{-1}\mu)^{-1}\right)$ 와 같이 정의되는데, 이제 $Y | Z$의 분산이 $\sigma_t^2$가 되게 $t^*$를 고르면 $$\alpha_{t^*}^2(\mu^\top\Sigma^{-1}\mu)^{-1}=\sigma_{t^*}^2 \quad\Longleftrightarrow\quad \frac{\sigma_{t^*}^2}{\alpha_{t^*}^2}=(\mu^\top\Sigma^{-1}\mu)^{-1}$$
이와 같다. 그래서 invertible function $g(t) = \sigma_t^2 / \alpha_t^2$로 두고, $t^*=g^{-1}\!\left((\mu^\top\Sigma^{-1}\mu)^{-1}\right)$ 이렇게 설정하면 기존의 DDPM sampling처럼 GLASS Denoiser를 동작시킬 수 있는 것입니다.
4.2.2 GLASS Velocity Field
이제 GLASS velocity field인 $u_s(\bar{x}_s|x_t,t)$가 GLASS Denoiser의 reparameterization이라는 것을 유도할 것입니다. 먼저 우리는 $p_{t,t'}(x_t,x_{t'}|z)$가 Gaussian이라고 했고, 이의 conditional distribution이 다음과 같이 Gaussian이라고 하였습니다.
$$\begin{equation}
p_{t'\mid t}(x_{t'} \mid x_t, z)
=
\mathcal{N}\!\left(x_{t'};\, \bar{\alpha} z + \bar{\gamma} x_t,\ \bar{\sigma}^2 I_d\right).
\tag{16}
\end{equation}$$
$$\begin{equation}
\bar{\gamma} = \rho \frac{\sigma_{t'}}{\sigma_t},
\qquad
\bar{\alpha} = \alpha_{t'} - \bar{\gamma}\alpha_t,
\qquad
\bar{\sigma}^2 = \sigma_{t'}^2(1-\rho^2).
\tag{17}
\end{equation}$$
이를 바탕으로 marginalizing을 하면 다음과 같은 marginal Gaussian probability path를 얻을 수 있게 됩니다.
$$\begin{equation}
p_s(\bar{x}_s \mid x_t, z)
=
\mathcal{N}\!\left(\bar{x}_s;\, \bar{\alpha}_s z + \bar{\gamma} x_t,\ \bar{\sigma}_s^2 I_d\right),
\qquad
p_s(\bar{x}_s \mid x_t)
=
\int p_s(\bar{x}_s \mid x_t, z)\, p_{1\mid t}(z\mid x_t)\, dz.
\tag{18}
\end{equation}$$
여기에 있는 스케줄러인 $\bar{\alpha}_s, \bar{\sigma_s}$는 $\bar{\alpha}_0 = 0, \bar{\alpha}_1 = \bar{\alpha}, \bar{\sigma}_1 = \bar{\sigma}, \bar{\sigma}_0^2 > 0$. 이 스케줄러 조건이면 marginal probability path가 noise와 GLASS transition을 interpolation하는 경로가 된다고 보면 됩니다. 저자들은, 스케줄러가 $p_s(\bar{x}_s|x_t,z)$가 optimal transport path (CondOT scheduler)가 되도록 다음과 같이 자연스럽게 잡을 수 있다고 합니다, i.e. $\bar{\alpha}_s=s\bar{\alpha}, \bar{\sigma}_s = (1-s)\bar{\sigma}_0 + s\bar{\sigma}$.

이제 논문의 Teorem1 부분을 볼텐데요, 여기에서는 구체적으로 inner flow matching model $u_s(\bar{x}_s|x_t,t)$ 을 포함하는 어느 flow matching, diffusion도 GLASS transition으로 샘플링이 가능하다는 것을 보여주는데요, 보겠습니다. 먼저 equation 18에서, intermediate probability path를 다음과 같이 $p_s(\bar{x}_s|x_t,z) = \mathcal{N}(\bar{x}_s; \bar{\alpha}_s z + \bar{\gamma}x_t, \bar{\sigma}_s^2 I)$로 정의할 수 있었는데, 다음처럼 샘플링 reparameterization하여 $\bar{X}_s = \bar{\alpha}_s Z + \bar{\gamma}x_t + \bar{\sigma}_s\epsilon,\ \ \ \epsilon \sim \mathcal{N}(0, I)$와같이 표현할 수 있습니다. 이제 위 식을 $s$에 대해 미분하면 다음과 같습니다.
$$\partial_s \bar{X}_s
=
(\partial_s \bar{\alpha}_s)\, Z
+
(\partial_s \bar{\sigma}_s)\, \epsilon$$
그런데 ODE의 이렇게 implicit한 noise $\epsilon$로 표현하는게 아니라, $\bar{X}_s$ 자체의 함수로 표현되어야 하므로, $\epsilon$를 $\bar{X}_s$로 다시 씁니다.
$$\epsilon = \frac{\bar X_s - \bar\alpha_s Z - \bar\gamma x_t}{\bar\sigma_s}$$
이를 미분식에 다시 대입하면
$$\partial_s \bar X_s
= (\partial_s \bar\alpha_s)\, Z
+ (\partial_s \bar\sigma_s)\,
\frac{\bar X_s - \bar\alpha_s Z - \bar\gamma x_t}{\bar\sigma_s}$$
정리하면 최종적으로 다음과 같습니다.
$$\partial_s \bar X_s
=
\left(\frac{\partial_s \bar\sigma_s}{\bar\sigma_s}\right)\bar X_s
+
\left(\partial_s \bar\alpha_s
- \bar\alpha_s \frac{\partial_s \bar\sigma_s}{\bar\sigma_s}\right) Z
+
\left(-\bar\gamma \frac{\partial_s \bar\sigma_s}{\bar\sigma_s}\right) x_t$$
즉,
$$\partial_s \bar X_s
= w_1(s)\bar X_s + w_2(s) Z + w_3(s) x_t$$
와같이, 논문에 equation 21.과 동일한 형태가 됩니다. 하지만, 실제 샘플링에서는 latent $Z$를 직접 알 수 없으므로, 현재 상태에서의 평균적인 velocity를 쓰기 위해 조건부기대값을 취해줍니다.
$$u_s(\bar x_s \mid x_t, t)
:= \mathbb E\left[
\partial_s \bar X_s \mid \bar X_s = \bar x_s, X_t = x_t
\right]$$
위 식에 선형성 공식을 대입하면
$$u_s(\bar x_s \mid x_t, t)
= w_1(s)\bar x_s+w_2(s) \mathbb E[Z \mid X_t = x_t, \bar X_s = \bar x_s]+w_3(s) x_t$$
여기서
$$D_{\mu(s),\Sigma(s)}(x_t,\bar x_s)
:= \mathbb E[Z \mid X_t = x_t, \bar X_s = \bar x_s]$$
로 정의한 것이 위에서 계속 설명한 GLASS denoiser입니다. 따라서 최종적으로
$$u_s(\bar x_s \mid x_t, t)
= w_1(s)\bar x_s+w_2(s) D_{\mu(s),\Sigma(s)}(x_t,\bar x_s)+w_3(s) x_t$$
가 나오게 되는데, 이게 바로 Theorem 1.의 equation 19.입니다. 이전에 정의한 conditional probability path를 통해 scale, variance를 구하면 equation 20.을 얻을 수 있고, equation 21은 바로 위에서 각 항의 계수를 나타냅니다. 따라서, 스케줄러 $\bar{\alpha}_s, \bar{\sigma}_s, \bar{\gamma}$가 잘 정의되어 있다면, 최종 확률분포인 $\bar{X}_1$와 이의 inner probability path인 $\bar{X}_s$은 다음과 같이 ODE로 구해질 수 있는 것이죠.
$$\bar{X}_0 \sim \mathcal{N}(\bar{\gamma}x_t, \bar{\sigma}_0^2 I_d),\ \ \ \frac{d}{ds}\bar{X}_s = u_s(\bar{X}_s|x_t,t)$$
이 velocity를 통해 ODE를 풀면 $0 \leq s \leq 1$상에서 $\bar{X}_s \sim p_s(\cdot|x_t)$와 같이 inner flow matching probability trajectory를 구할 수 있는 것입니다. 이처럼 추가적인 모델 학습이 필요없고, 결과가 Gaussian measurements의 sufficient statistic에 의존하는 방법론을 Gaussian Latent Sufficient Statistic (GLASS) Flows 라고 명명하는 것입니다.
Sampling with GLASS Flows
저자들은 전체 생성과정을 한번에 ODE integration으로 하는 대신 시간 구간을 $K$개로 쪼개고 각 구간마다 확률적인 Markov transition을 샘플링해 이어 붙히는 새로운 샘플러를 제안합니다. Theorem 1.의 요지는 GLASS가 만든 inner ODE를 정확히 풀면 그 결과 $\bar{X}_1$이 원하는 transition $p_{t'|t}(\cdot|x_t)$에서 나온 샘플이 되는 것입니다. 그래서 만약 어떤 단계에서 이미 $X_{t_k}\sim p_{t_k}$라면, 그 다음 단계도 $X_{t_{k+1}}\sim p_{t_{k+1}}$를 만족합니다.
또한, $\rho$를 자유롭게 골라도 marginal이 유지되는 것도 핵심 특징입니다. GLASS transition은 $(X_t, X_{t'})$의 joint Gaussian을 만들 때 $X_t$의 분산은 $\sigma_t^2$, $X_{t'}$의 분산은 $\sigma_{t'}^2$, 둘 사이 상관만 $\rho$로 조절하는 식으로 정의됩니다. 즉 $\rho$는 두 시점이 얼마나 같이 움직이느냐를 바꾸지만, 각 시점의 marginal $p_t, p_{t'}$자체는 스케줄러 $\alpha_t, \sigma_t$로 고정되어있고, GLASS는 그 고정된 marginal을 가지는 joint Gaussian family안에서 $\rho$만 바꾸는 구조라, 어떤 $\rho$를 써도 각 단계의 marginal 경로 $p_{t_k}$위에 계속 남게 됩니다.
기존 ODE 샘플링은 한 번 시작하면 무조건 결정론적입니다, 하지만 GLASS는 매 구간마다 transition을 샘플링하므로 전체가 Markov chain이 됩니다. 이 Markov chain은 각 시점에서 미리 학습된 모델이 이미 학습한 marginal probability인 $p_t$를 유지합니다. 따라서, 확률적 탐색 / SMC / 검색 과 같은 reward-guiding method에 필요한 stochasticity를 얻으면서도, 모델이 원래 학습한 분포 경로를 망가뜨리지 않느다고 저자들을 주장합니다.
계산량은 $K \cdot M$입니다. 맨 위에 있던 Algorithm1을 보면 이해하기 쉬운데, 먼저 한 transition을 샘플링하려면 inner time $s \in [0,1]$ ODE를 $M$ step으로 적분하며, 각 스텝마다 사실상 pre-trained 네트워크를 평가하므로, transition이 총 $K$개면 총 NFE가 대략 $K \cdot M$이 됩니다. 참고로 Appendix에 $M = 1$로 각 transition을 inner ODE 한 스텝으로 정의하면, 한 번의 업데이트가 DDIM형태의 가우시안 업데이트로 정의된다는 점도 큰 특징입니다. 또한, 이 모든건 당연히 discretization error가 없고 모델이 정확한 $u_t$를 안다는 이상적인 가정이 있어야 이와같은 marginal 보존이 정확히 성립합니다!
Implementation
이 섹션에서는 GLASS Flows를 실제 구현할때, 수치적으로 불안정해질 수 있고, CFG/파라미터화/이산시간 모델까지 어떻게 정리해서 적용하냐에 대해 다룹니다. GLASS Flows에서 $s=0$에서 $\bar{X}_0 = \bar{\gamma}x_t + \bar{\sigma}_0\epsilon$꼴입니다. 여기에서 GLASS Denoiser를 그대로 계산하려고 하면, $\bar{X}_0$이 $z$와 독립인 구조 때문에, posterior가 사실상 $p(z|x_t,\bar{x}_0) = p(z|x_t)$로 붕괴합니다. 이를 sufficient static $S(x)$으로 억지로 계산하려고 하면 분모/역행렬/스케줄러 비율에서 불안정이 커질 수 있습니다. 그래서 실제 구현에서는 $s=0$이면 GLASS denoiser를 계산하지 말고 그냥 $D_t(x_t)$를 반환하는 $D_{\mu(0), \Sigma(0)}(x_t,\bar{x}_0) = D_t(x_t)$와 같은 분기처리가 필요합니다.
$2 \times 2$공분산 $\Sigma(s)$ 역행렬 계산 안정성
$Sigma(s)$는 구조상 $\text{det}\Sigma (s) = \sigma_t^2\bar{\sigma}_s^2$이고, $\sigma_t > 0, \bar{\sigma}_s > 0$이면, 이론적으로 항상 invertible입니다. 다만 실제로는 $t \rightarrow 1$이면 $\sigma_t \rightarrow 0$이 되고, $s \rightarrow 1$이면서 $t' = 1 \text\ \ {or}\ \ \rho \rightarrow \pm 1$이면 $\bar{\sigma}_s \rightarrow 0$이므로 실제 float32에서 계산이 불안정해질 수 있습니다.
실제로 그래서, 네트워크 forward를 제외한 나머지계산은 float64로 처리하는 방법을 추천한다고 합니다. 뿐만 아니라 $\Sigma (s) \leftarrow \Sigma (s) + \epsilon I$같은 작은 diagonal jitter를 추가하거나, ODE 적분에서 $s=1$까지 정확히 계산하기보다, 보통은 $s \leq 1 - \frac{1}{M}$까지만 평가해서 $\bar{\sigma}_s = 0$ 특이점을 회피하는 방법을 채택합니다 (Algorith 1.에 반영)
기존 대규모 t2i FM/diffusion은 대부분 CFG를 쓰므로, GLASS에서도 이를 그대로 쓰되, 중요한 구현 원칙이 있습니다. $$u_t^w (x|c) = (1+w)u_t(x|c) - w u_t(x)$$
이 수식을, 그냥 새로운 ground-truth vector field라고 간주하고, GLASS의 모든 계산을 전부 $u_t^w$기준으로 일관되게 수행하게합니다. 이렇게 하는 이유는, GLASS는 위에서도 봤지만 $u_t \leftrightarrow D_t$ reparameterization을 계속 쓰는데, CFG를 마지막에만 섞으면 $D_t$와 $u_t$의 관계가 깨져 inner model도 틀어질 수 있습니다. 다음과 같이 모든 계산을 합니다.
$$D_t^{(w)}(x\mid c)
=
\frac{1}{\dot{\alpha}_t\sigma_t-\alpha_t\dot{\sigma}_t}\big(\sigma_t u_t^{(w)}(x\mid c)-\dot{\sigma}_t x\big)$$
또한, 다른 파라미터화(denoiser/score/$\epsilon$-pred)의 경우와 discrete diffusion은 어떻게 처리하느냐에 대한 답은 다음과 같습니다. GLASS 알고리즘은 $u_t(x)$형태의 velocity field라고 가정합니다. 하지만 실제 diffusion구현은 score $\bigtriangledown \log p_t(x)$, denoiser $D_t(x)$, noise predictor $\epsilon_{\theta}$등 다양한 형태가 있습니다. 저자들은 그냥 어떤 형태든 먼저 $D_t(x)$ 형태로 reparameterize한 뒤, GLASS denoiser/velocity를 구성하면 된다고 말합니다 (일반적인 특징임). discrete인 상황에서는 GLASS 내부에서 계산되는 네트워크에 질의할 시간인 $t^* = g^{-1}((\mu^T\Sigma^{-1}\mu)^{-1})$가 연속값으로 나오므로, 네트워크가 학습된 discrete grid 밖의 $t$를 넣으면 out-of-domain이 될 수 있다는 문제가 있습니다. 이를 위해 $t^*$가 grid에 떨어지도록 내부 $s$스텝을 제한/선택하는 방법을 채택한다고 합니다.
4.3 Inference-time Reward Alignment With GLASS
Sequential Montel Carlo (SMC)
$$x_{t'}^{(k)} \sim p_{t'|t}(\cdot|x_t^{(k)})$$
기존 SMC 기반 방법들은 particle을 뽑을때, SDE 샘플링을 써서 느려졌는데, GLASS Flows를 쓰면, 각 particle 전이를 ODE로 샘플링할 수 있어 같은 compute budget에서 더 많은/더 정확한 샘플 전이 샘플을 얻을 수 있게 도비니다. 또한, discretization error가 줄어들며, 결과적으로 SMC의 resampling/reweighting이 더 제대로 작동하게 도와줍니다.
Value function estimation
$$V_t(x_t) = \log \mathbb{E}_{z \sim p_{1|t}(\cdot | x_t)}[\text{exp}(r(z))]$$
검색류 방법은 노드 평가를 위해 value function을 쓴다고 했었습니다. 여기서 핵십은 $p_{1|t}(z|x_t)$ posterior에서 샘플을 뽑아야 추정이 잘 되는데, 기존엔 이 posterior 샘플링이 SDE기반이라 매우 비효율적이였습니다. 다음과 같이 근사치로 Monte Carlo로 추정해버립니다.
$$p_{1|t}(z\mid x_t)=p^{\mathrm{DDPM}}_{t'=1\mid t}(X_1=z\mid X_t=x_t)$$
하지만, GLASS Flows는 이런 posterior/전이 샘플링을 ODE 방식으로 빠르게 만들고, Monte Carlo로 $V_t$를 더 정확히 추정 가능하고, 검색에서 노드 선택/가지치기가 개선될 여지가 많아지게 된다고 합니다.
Reward guidance
$$u_t^r (x) = u_t (x) + c_t \bigtriangledown r_t (x)$$
GLASS 내부 velocity field $u_s (\bar{x}_s|x_t,t)$에 유사하게 reward항에 더해 guidnace를 할 수 있다고 설명합니다.
5 Related Work
전통적인 discrete-time diffusion(i.e., DDPM)은 보통 continuous ODE/SDE의 1차 근사 관점으로 이해할 수 있고, GLASS는 이러한 작은 스텝 근사가 아니라, 멀리 떨어진 $t < t'$사이의 전이 $p_{t'|t}$를 직접 타깃으로 삼아 샘플링한다는 점이 다릅니다.
논문이 말하듯 Transition Matching의 어떤 supervision은 GLASS trnasition의 특수한경우 $\rho = 1$로 해석될 수 있다고 합니다. 하지만 TM은 pre-training/architecture 변경 중심인거고, GLASS는 pretrained 모델을 inference-time에 변환 중심이라서 문제 설정 자체가 다르다고 주장합니다.
TADA와의 관계도 언급합니다. 둘 다 핵심 수학 아이디어가 Gaussian conjugacy / sufficient statistic로 사전학습 모델에서 재훈련 없이 새로운 동력학/샘플러를 복원한다는 점에서 닮았고, TADA는 주로 샘플링 가속을 위해 state augmentation을 쓰고, GLASS는 reward alignment에 필요한 stochastic translation을 ODE 효율로 제공하는 데 초점을 둔다고 합니다.
또한, reward finetuning (GRPO, SOC, 일부 RL)도 언급하는데, 이러한 방법에선, 학습 중에 다양한 샘플을 뽑아 reward를 평가하고 그 신호로 업데이트를 합니다. 이때 흔히 쓰는데 DDPM/SDE sampling인데, GLASS Flows를 활용해서 학습 중 exploration을 위해 어쩔 수 없이 SDE를 쓰던 부분을 효율적으로 최적화할 수 있다고 언급합니다.
6 Experiments
6.1 Efficient Posterior Sampling and Value Function Estimation
이 절은, reward alignment에 중요한 다음 두 작업을 GLASS Flows가 실제로 더 효율적으로 만드는지 실험으로 보여줍니다.
- posterior sampling: $p_{1|t}(z|x_t)$에서 $z$를 샘플링
- value function estimation: $V_t(x)$를 잘 추정
비교 대상은 아래와 같습니다.
- DDPM sampling (SDE 기반): 전이를 샘플링할 때 매 스텝에 랜덤 노이즈가 들어감
- GLASS Flows (ODE 기반 전이 샘플링): 시작에서만 랜덤 초기값을 뽑고, 이후는 ODE로 결정론적으로 진행하지만 결과는 목표 전이분포를 따르도록 설계
벤치마크는 노이즈 낀 이미지 $x_t$를 주고 원본 $z$를 다시 샘플링하는 문제를 벤치마크로 썼습니다.

먼저 ImageNet모델에서 $z \sim p_{data}$로 이미지를 샘플링하고, $x \sim p_t(\cdot|z)$로 노이즈를 입히고, $z' \sim p_{1|t}(\cdot|x)$와 같이 posterior를 여러 샘플로 추정한 task입니다. 왼쪽 posterior sampling exampling에서는 $M=6$으로 GLASS Flow의 inner step을 설정하였고, 논문에 나와있진 않지만 $K = 1$로 설정하였고, 200개의 Monte Carlo sample을 활용하였습니다. $M$이 작으면 ODE 이산화 오차가 생기지만, 실험적으로 같은 $M$에서 SDE(DDPM)보다 오차가 훨씬 작아서, 왼쪽 그림처럼 posterior를 GLASS Flows가 더 잘 복원한 것을 볼 수 있습니다.
이론적으로는 두 방법 다 충분히 많은 스텝이면 posterior를 맞출 수 있습니다 ($M=30$). 하지만 작은 $M = 10$에서 $t=0.2$를 봤을때, posterior recovery, value function estimation 부분에서 DDPM보다 GLASS Flows가 훨씬 적은 FID, (Pearson) Correlation이 높은 것을 볼 수 있습니다.
6.2 Novel Sampling Method
이 절에 posterior sampling을 넘어서 T2I 모델에 적용하여 비교하고 싶은 것입니다.
- ODE sampling: 한 번 초기 노이즈를 뽑으면 이후 경로는 결정론적
- DDPM samplingL 매 스텝에 노이즈가 들어가는 확률적 샘플링. 전이를 자연스럽게 제공하지만, NFE가 같을 때 ODE보다 품질이 떨어지거나 더 많은 스텝이 필요하다는 emperical한 문제가 있음.
- GLASS Flows: 겉으로 ODE처럼 적분을 하되, 각 전이 샘플링에서 내부 초기 랜덤성으로 확률성을 만들어 SDE전이처럼 branching가능한 전이 샘플을 제공하는 방식
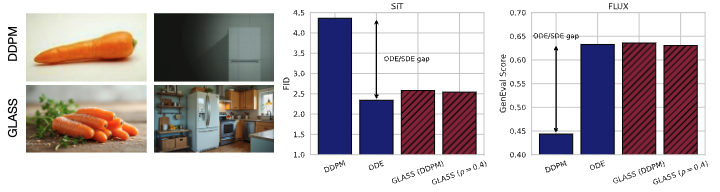
FLUX 기본 파라미터에서 ODE vs DDPM의 성능 격차가 큽니다. 즉 같은 NFE (i.e. 50)에서 DDPM이 더 흐리거나 품질이 낮게 나오는 경향을 보여주는것을 말합니다. GLASS Flows($\rho=0.4)$가 그 격차를 줄입니다, DDPM의 전이 확률성은 유지/대체 하면서 품질은 ODE수준으로 회복시킵니다. 실제로 확률적 전이인데도 ODE sampling과 동급 성능을 나타냅니다. 즉 GLASS Flows는 efficiency <-> stochasticity라는 tradeoff를 제거해버립니다!
6.3 Sequential Montel Carlo Experiments
이전 6.2절에서 $\rho = 0.4$, FLUX 모델에 대해 가장 잘 맞는 설정으로 골랐고, 이어서 6.3에서는 그 설정을 사용해 SMC기반 정렬, 특시 Feynman-Kac Steering에 GLASS Flows를 plugin으로 넣어 성능/효율을 평가하겠다는 흐름입니다. 그리고 잠깐 $\rho$가 SMC/FKS에서 갖는 의미/직관에 대해 잠깐 살펴보겠습니다.
- $\rho$가 크면: 한 particle의 다음 상태가 현재 상태와 더 비슷하게 움직여서 branch가 덜 퍼질 수 있고(탐색 다양성 적음), 대신 국소적으로 안정적일 수 있음.
- $\rho$가 작으면: particle들이 더 넓게 퍼지며 (탐색 다양성 높음), 너무 작으면 품질/안정성에 손해가 날 수도 있음.
저자들은 $\rho = 0.4$가 품질(GenEval 등)과 탐색성(정렬 성능)사이 밸런스가 좋았다는 관찰을 바탕으로, 이후 SMC 실험에서도 그 설정을 베이스로 씁니다. 다만 SMC/FKS 성능은 단지 sampler의 정확도 뿐만 아니라 다음과 같은 요인에도 영향을 받게 되는데.
- 기본 생성 모델의 probability path/오차 특성.
- reward model의 형태
- particle의 수/resampling 빈도
- 한 transition의 시간 간격($t' - t$)
그래서 저자들은 FLUX에서는 $\rho = 0.4$가 가장 좋았지만, 다른 backbone/스케줄러/해상도/도메인에서는 다른 $\rho$가 최적일 수 있음을 알립니다. 6.3에서는 본격적으로 같은 FKS 알고리즘이라도 transition을 SDE(DDPM) vs GLASS Flows로 샘플링할 때 reward 점수와 GenEval같은 외부 품질 지표에서 효율-성능 tradeoff가 어떻게 바뀌는지 보려는 세팅입니다.
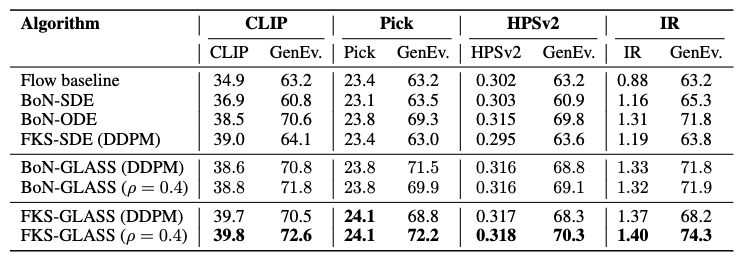
당연히 BoN보다 FKS가 정량 지표가 좋습니다. 우리가 자세히 볼 것은 DDPM vs ODE vs GLASS로 비교한 SMC 실험입니다. 여기에서 중요한 시사점들을 정리해서 설명하겠습니다. 먼저 SDE로 FKS를 해도 BoN-ODE를 못이긴다는 점입니다. FKS라는 더 좋은 정렬 알고리즘을 쓰더라도, 전이를 SDE(DDPM)으로 샘플링하면 GenEval이 크게 깎이거나, 전체 효율-품질이 망가질 수 있습니다. 또한, FKS-GLASS (CLIP 39.8, GenEv 72.6)와 BoN-ODE (GenEv 70.6), FKS-SDE (GenEv 64.1)을 보면, GLASS를 쓰면, FKS에 필요한 확률적 전이 샘플링은 유지하면서, 샘플링 품질은 ODE급으로 올려 결과적으로 reward도 올리고 GenEval도 올리는 조합이 가능해 진다는 중요한 실험 결과를 볼 수 있습니다. 또한, GLAS는 단지 DDPM을 ODE로 바꿈 수준이 아니라, SMC(FKS)의 장점을 실제 성능으로 연결시키는 기반을 제공한다는 아주 중요한 시사점을 제공해줍니다.

추가로 FKS + GLASS + $\bigtriangledown$이들어있는 실험결과도 있는데, 이는 $\bigtriangledown$ guidance로 FKS의 각 스텝에서 보상증가 방향으로 미세하게 끌어주는 항을 추가한 FKS-GLASS입니다. 참고로 이는 reward가 미분가능해야만 할 수 있습니다.
7 Concolusion
GLASS Flows는 flow/diffusion 모델에서 Markov tarnsition $p_{t'|t}(x_{t'}|x_t)$을 SDE없이 ODE로 샘플링할 수 있게 해주는 방법입니다. 이를 위해 inner flow matching model $u_s(\bar{x}_s|x_t,t)$을 구성해, 초기값만 랜덤으로 뽑고 이후는 결정론적 ODE으로 빠르게 전개합니다.
앞으로 이 논문에서 언급한 Transition Matching, TADA같은 논문도 읽어보고, learning based reward-alignment 논문도 많이 읽어봐야겠습니다.