![[ 딥러닝 논문 리뷰 - PRMI Lab ] - TRPO & PPO 의 설명과 코드 구현](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fru7L3%2FdJMcadAQJju%2FAAAAAAAAAAAAAAAAAAAAAJGr6OBF2wleV8J5uB0osJFXmy2tCVJUATNiCHnK8D6b%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3D0PM%252FM%252BXoOg1W4uDvN74yQmHQQ7o%253D)
생성모델 논문에서 강화학습을 접목한 논문이 최근에 많이 보였습니다. 그래서 이번 방학에 강화학습 예를들어 PPO, TRPO, GRPO등이 뭔지 알아보고 코드까지 세세하게 분석해보려 했습니다. ETRI 인턴을 갔다오면 지쳐서 매번 쓰려져 미뤄왔던 포스팅을 지금에야 하게되었습니다. 이번에는 고려대 오승상 교수님의 강화학습 강의를 차근차근 보고, 가장 관심이 많았던 TRPO와 PPO가 TRPO에서 어떻게 발전된 형태이고 그 중 PPO의 코드는 어떻게 구현되고 결과는 어떤지 알아보겠습니다.
오승상 교수님 강화학습: https://www.youtube.com/watch?v=c15b9AjHxBA&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC&index=27
Trust Region Policy Optimization (TRPO)
TRPO (UC Berkely 2015): https://arxiv.org/abs/1502.05477
Trust Region Policy Optimization
We describe an iterative procedure for optimizing policies, with guaranteed monotonic improvement. By making several approximations to the theoretically-justified procedure, we develop a practical algorithm, called Trust Region Policy Optimization (TRPO).
arxiv.org
DDPG는 model update stepsize가 너무 크면, 모델 수렴이 잘 되지 않는다는 단점이 있었습니다. 이를 위해 TRPO는 trust region ( \(\delta\))라는 개념을 도입하여 DDPG의 문제를 해결합니다.

우리는 \(\eta(\pi)\)를 advantage인 \( A_{\pi_{old}} \)와 \(\eta(\pi_{old})\)를 이용해 업데이트를 하게됩니다. 결국에 $$\eta(\pi) = \eta(\pi_{old}) + \sum_{s}\rho_{\pi}(s)\sum_{a}\pi(a|s)A_{\pi_{old}}(s,a)$$ 와 같이, state visitation frequency ($\rho$)를 이용해 업데이트 식을 구성할 수 있게 됩니다. 여기에서 모덴 state s에 대해서 $\sum_{a}\pi(a|s)A_{\pi_{old}}(s,a) \geq 0$이라면, $\eta$는 monotonic하게 증가하겠죠. 하지만 우리가 nerual network로 근사하고 계산하다보면, 해당 부분이 negative가 되어 이러한 설정이 깨져버리게 됩니다. 그래서 아직까지는, monotonic improvement를 만족하는지는 애매한 상황입니다. 그리고 애초에 $\rho_{\pi}(s)$를 구하려면, 새로운 policy에 대해 sample을 많이 구해야하는데 이 또한, 우리는 새로운 policy를 찾고있는 상황이기 때문에, 지금 상황에서는 구하는 것은 불가능합니다.

그래서, 우리는 $\rho_{\pi}$대신에 $\rho_{\pi_{old}}$로 local approximation을 하게 됩니다. 이러한 approximation된 꼴과 이전 꼴에는 중요한 관계가 있는데, 바로 $\pi_{\theta_0}$이라는 값에서 동일한 값을 가지고, 1차 미분 계수의 값이 같다는 것입니다. 이를 증명하기 위해서는, $\sum_{s}\rho_{\pi_{old}}(s)\sum_{a}\pi(a|s)A_{\pi_{old}}(s,a)$에서 $A_{\pi_{old}}(s,a)$이라는 값이 a에 대해 Expectation을 취해주면, 0이 된다는 사실로 두개의 사실을 증명할 수 있습니다. 이를 통해서 아주 작은 step일떄 $\pi_{old} \rightarrow \pi$로 갈때 $L_{\pi_{old}}$가 improve된다면, $\eta$도 improve한다는걸 알 수 있습니다. 여전히 근대 어느정도 step까지 허용이 될 지는 모릅니다.
그래서 다음으로 conservative policy iteration update의 개념을 소개합니다. 이러한 issue를 위해 새로운 policy를 사용하는 것이 아닌 mixture policy를 도입하고, $\pi^{'}$를 $L_{\pi_{old}}(\pi)$를 최대화하는 $\pi$로 설정합니다. 이를 통해 우리는 $$\eta(\pi) = L_{\pi_{old}}(\pi) - \frac{2\epsilon\gamma}{(1-\gamma)^2}\alpha^2, \epsilon = \max_{s}|\mathbb{E}_{a\sim\pi^{'}(a|s)}[A_{\pi_{old}}(s,a)]|$$ 라는 lower bound를 얻을 수 있습니다. 하지만, 실제로는 mixture policy를 사용하고 이를 practical하게 사용하기 매우 쉽지 않습니다. 그 이유는 $\epsilon$에서 모든 state에서의 $\pi^{'}$에서의 최댓값을 구하는데, state space가 크면 이를 구하기가 매우 쉽지 않기 때문입니다. 그래서 이를 근사할 또다른 방법을 찾게 됩니다.

우리는 $\alpha = \max_{s}D_{TV}(\pi_{old}(\cdot|s)||\pi(\cdot|s))$처럼 Total Variation distance를 사용하여, $$\eta(\pi) = L_{\pi_{old}}(\pi) - \frac{4\epsilon\gamma}{(1-\gamma)^2}\alpha^2, \epsilon = \max_{s,a}|A_{\pi_{old}}(s,a)|$$ 와 같이 lower bound를 재정의하고, 이를 KL Divergence로 다음과 같이 바꿉니다 $$\eta(\pi) = L_{\pi_{old}}(\pi) - CD_{\text{KL}}^{\text{max}}(\pi_{old},\pi), C = \frac{4\epsilon\gamma}{(1-\gamma)^2}$$. 이는 $D_{TV}(p||q)^2 \leq D_{KL}(p||q)$라는 사실로 간단히 증명이 됩니다.
그 다음 Miniorization-Maximization algorithm으로, lower bound를 surrogate objective로 두어, policy를 monotonically하게 improvement하게끔 보장하게 합니다. MM algorithm은 자세히 설명하지 않겠습니다.
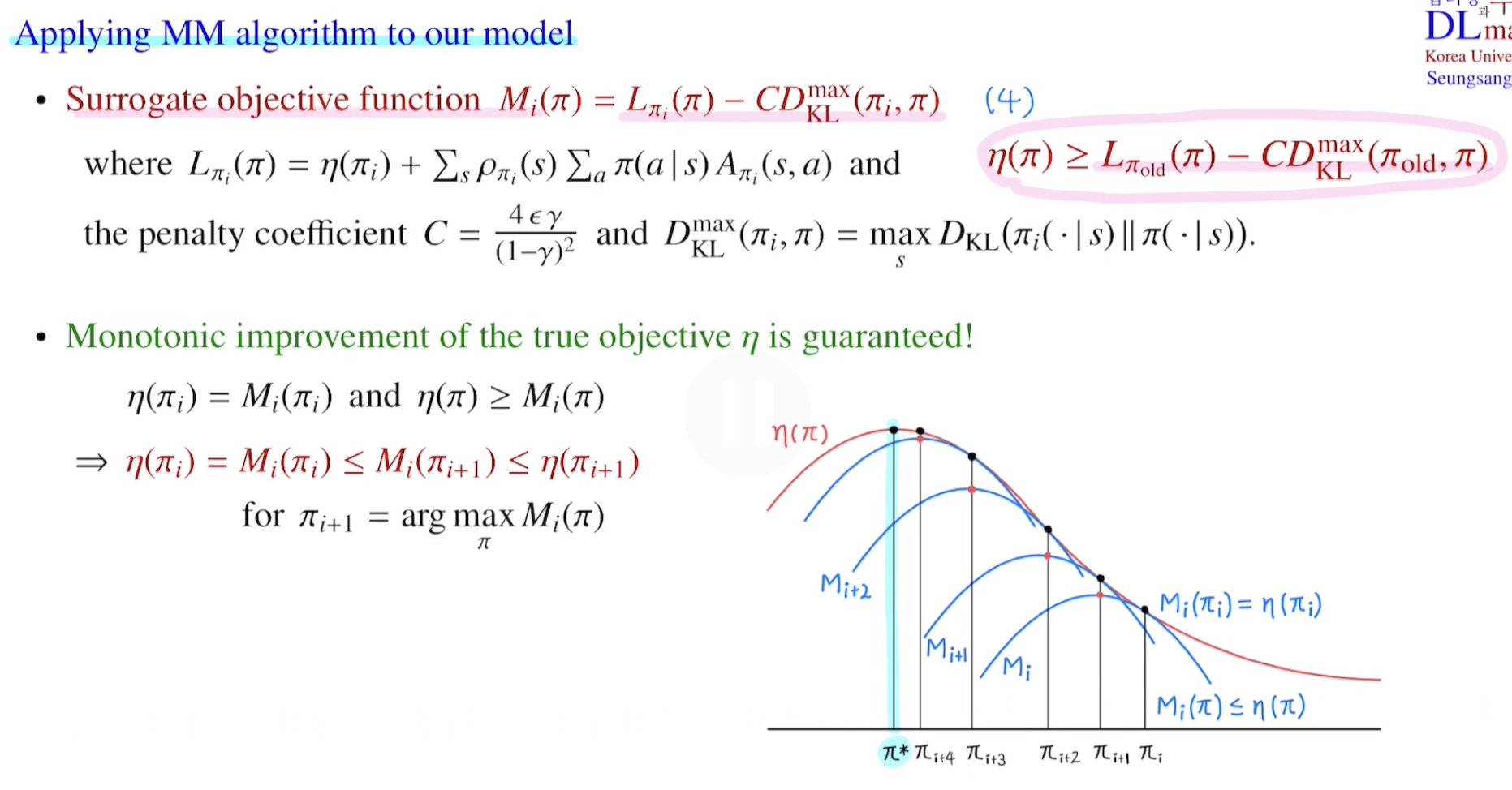
구체적으로, 위에서 구한 lower bound $L_{\pi_{old}}(\pi) - CD_{\text{KL}}^{\text{max}}(\pi_{old},\pi)$를 surrogate objective function인 $M_{i}(\pi)$로 두고 MM algorithm을 위 슬라이드처럼 진행하게 된다면, monotonic하게 improvement할 수 있게 됩니다. 하지만 실제로, 수많은 iteration을 통해 optimal policy를 찾을 수 있기 때문에, TRPO는 많은 계산이 뒤따릅니다. 추가적으로 만약 discount factor $\gamma \rightarrow 1$이라면, $C$값이 커지게 될 것이고, 그러면 $D_{\text{KL}}^{\text{max}}(\theta_{old}, \theta)$값이 작아져야 합니다, 이 말은, new policy, old policy사이의 간격이 작아야 하기 때문에 gradient stepsize가 작아져야해서, 많은 계산량이 또 소모되게 됩니다.

우리는 surrogate objective를 Largrangian duality로 KL constrained objective로 아래와같이 표현할 수 있습니다. $$\max_{\theta}L_{\theta_{old}}(\theta)\ \ \ \text{subject to }\ \ D_{\text{KL}}^{\text{max}}(\theta_{old},\theta)\leq \delta$$. 이는 계산량이 무한하다면, 정확히 같은 form이 됩니다. 그리고 우리는 $\delta$를 $C$보다 hyperparameter로 조절하기 쉽기 때문에, 이를 조절하면서 학습하게 되고 이를 trust region이라고 하는 것입니다. 하지만 $D_{\text{KL}}^{\text{max}}(\theta_{old},\theta)$는 모든 state에 대해 계산되어야 하기 때문에, constraint의 계산이 부정확할 수 있습니다. 따라서 우리는 Heuristic approximation을 하게 되는데, 기존의 max로 표현되었던 부분을 $\mathbb{E}_{s\sim\rho_{\theta_{old}}}$로 감싸주어 approximation을 합니다. 강화학습에서는 Montecarlo simulation을 하기 때문에, 이를 sampling으로 대체할 수 있습니다.

Montecarlo simulation을 통해 single path method를 채택한 sample-based estimation을 합니다. 위 식에서 일단 $\eta(\theta_{old})$값은 maximum $\theta$를 찾는데 필요없기 때문에 빼주었습니다. 그리고 state visitation frequenct를 확률 값으로 바꾸기 위해 $\frac{1}{1-\gamma}$를 곱해주어 표현해주고, 우리는 $a \sim \pi_{\theta}$를 통해 Advantage값을 계산해야 하는데, new policy $\pi$는 우리는 모르기에 Montecarlo simulation이 불가능합니다. 따라서, Importance sampling을 통해 old policy로 해당 값을 가능하게끔 꼴을 바꾸어 줍니다. 또한, 실제 논문에서는 $A_{\theta_{old}}$를 Q-value인 $Q_{\theta_{old}}$로 바꾸어 구현하기도 한다고 합니다. 그래서 최종 최적화 형태는 아래와 같습니다. $$\max_{\theta}\mathbb{E}_{s\sim\rho_{\theta_{old}}, a\sim\pi_{\theta_{old}}}\big[ \frac{\pi_{\theta}(a|s)}{\pi_{\theta_{old}}(a|s)}Q_{\theta_{old}}(s,a)\big]\ \ \ \text{subject to}\ \ \ \mathbb{E}_{s\sim\rho_{\theta_{old}}}[D_{\text{KL}}(\pi_{\theta_{old}}(\cdot|s)||\pi_{\theta}(\cdot|s))]\leq\delta$$

우리는 TRPO에서 Natural Gradient를 사용하여 policy를 update하게 되는데, 이러한 NPG가 어떻게 이루어지는지 보겠습니다. 결론만 말해서, $L_{\theta_{old}}$ term은 1차 derivate만 사용하고, $D_{\text{KL}}$ term은 2차 derivate만 사용합니다. 2차 derivate에서는 Hessian인 $H$ matrix가 사용됩니다. $$H = \nabla_{\theta}^2\bar{D}_{\text{KL}}(\theta_{old}||\theta) = \Big( \frac{\partial^2\bar{D}_{\text{KL}}(\theta_{old}||\theta)}{\partial\theta_i\partial\theta_j} \Big) \Big|_{\theta=\theta_{old}}$$를 우리는 Fisher Information Matrix로 명명합니다. 실제로는 $N$개의 sample을 통해 평균을 구해 $H$를 구하게 됩니다. 위 슬라이드에서, 실제로 $L_{\theta_{old}}, D_{\text{KL}}$를 2차 미분까지 근사를 하지만, 각각 $\theta$를 업데이트 하는데 관여하지 않는 term들을 날리고, 0인 값을 날리면 실재로 각각 1, 2차항만 남게 됩니다.
그리고 $H$를 통해서 Natural gradient인 $H^{-1}\nabla_{\theta}L_{\theta_{old}}(\theta)\big|_{\theta=\theta_{old}}$가 가장 steepest 하게 gradient를 업데이트 direction이 됩니다. $H$는 실제로 curvature를 반영하기 때문에, $\theta$를 더 올바른 방향으로 update할 수 있게 합니다. 이를 통해 업데이트 식은 다음과 같습니다 $\theta = \theta_{old} + \beta\cdot H^{-1}\cdot g$. 그리고 이를 통해 constraint를 다시 표현하게 되면, $\frac{1}{2}(\beta\cdot H^{-1}\cdot g)^T H \beta\cdot H^{-1}\cdot g \leq \delta$가 됩니다. 즉, 이 constraint를 만족하는 최대의 learning rate $\beta$는 $frac{1}{2}(\beta\cdot H^{-1}\cdot g)^T H \beta\cdot H^{-1}\cdot g = \delta$ 를 만족할 때 라는것을 알 수 있습니다.

즉 learning rate $\beta$를 $\sqrt{\frac{2\delta}{g^TH^{-1}g}}$로 업데이트 하면, trust region을 만족한다고 할 수 있는 것입니다. 여기서 우리는 NPG를 사용해서 update하면 빨리 converge를 하지만, $H$를 계산해야 하기 때문에 계산량이 너무 많게됩니다. 여기에서 우리는 $\min_{x}f(x) = \frac{1}{2}x^T H x - gx$라는 시스템을 풀면 됩니다. 이는 $H$가 positive-definite matrix이기 때문에 (convex한 형태임), Conjugate gradient를 통해 quadratic equation $f(x)$의 해를 기존의 gradient descent보다 빠르게 풀 수 있습니다.
마지막으로, 우리의 update 식은 수많은 approximation을 거쳤기 떄문에, $\beta$값으로 policy를 update하면 constraint를 만족하지 않을 수 있습니다. 그래서 line search를 진행하게 되는데, $\beta$를 $\alpha (0 < \alpha < 1)$로 점진적으로 곱해가며 shrinking을 하면서, KL constraint를 만족하는지 확인하고, 만족하는 $\beta$값을 사용합니다.
Proximal Policy Optimization (PPO)
PPO (OpenAI 2017) paper: https://arxiv.org/abs/1707.06347

기존의 TRPO에서 KL constraint는 $\pi_{\theta_{old}}$와 $\pi_{\theta}$가 너무 멀어지는걸 방지하기 위한 term입니다. 하지만 이러한 constraint가 없어지면 policy ratio $\frac{\pi_{\theta}(a|s)}{\pi_{\theta_{old}}(a|s)}$가 급격하게 커지거나 작아지면서 매우 불안정해지게 policy가 update됩니다. 그래서 PPO는 Clipped surrogate objective function을 도입합니다.
$$\max_{\theta}L^{\text{CLIP}}(\theta) = \mathbb{E}[\min(r(\theta)A_{\theta_{old}}(s,a), \text{clip}(r(\theta), 1-\epsilon, 1+\epsilon)A_{\theta_{old}}(s,a)]$$와 같이 KL constraint를 clipping으로 대체함으로서 policy가 너무 급격하게 바뀌는걸 방지합니다. 그리고 $L^{\text{CLIP}}(\theta)$는 $L^{\text{TRPO}}(\theta)$에 대한 lower bound이여야 하기 때문에, min을 기존의 surrogate 값에 적용해줍니다.

PPO는 추가적으로 $L^{\text{VF}}(\theta), S[\pi_{\theta}](s)$항을 추가합니다. $L^{\text{VF}}$는 value estimation (critic)을 학습하기 위한 term이며, 만약 policy와 value함수를 같은 네트워크로 최적화를 한다고 하면, 더 안정적이게 수렴할 수 있게 도와주는 역할을 합니다. 또한, $S[\pi_{\theta}](s)$값은, entropy bonus로서, 무질서도를 높임으로서(noise 증가) exploration을 조금 더 키워주게 하는 역할을 합니다.
PPO 코드 구현
TRPO의 코드는 사실 너무 복잡하기 떄문에, 진행하지 않겠다. 아주 간단한 PPO의 코드 구현체를 HDBG 님의 블로그를 참고하여 구현하고 돌려보았다. 전체 코드는 아래와 같다.
import random
from tqdm import tqdm
from collections import deque
import numpy as np
import pandas as pd
import gymnasium as gym
import matplotlib.pyplot as plt
import torch
import torch.nn as nn딛
import torch.nn.functional as F
from torch.distributions import Normal
from torch.utils.data import TensorDataset, DataLoader
import torch.nn as nn
"""
연속적인 행동 공간을 다루기 위해서 출력값을 mu(행동의 평균값), log_std(행동의 표준편차에 로그를 취한 값)
"""
class MLPGaussianPolicy(nn.Module):
def __init__(self, dim_state, dim_action, dim_hiddens=(512, ), activation_fn=F.relu):
super(MLPGaussianPolicy, self).__init__()
self.input_layer = nn.Linear(dim_state, dim_hiddens[0])
self.hidden_layers = nn.ModuleList()
for i in range(len(dim_hiddens) - 1):
hidden_layer = nn.Linear(dim_hiddens[i], dim_hiddens[i+1])
self.hidden_layers.append(hidden_layer)
self.mu_layer = nn.Linear(dim_hiddens[-1], dim_action)
self.log_std_layer = nn.Linear(dim_hiddens[-1], dim_action)
self.activation_fn = activation_fn
def forward(self, s):
s = self.activation_fn(self.input_layer(s))
for hidden_layer in self.hidden_layers:
s = self.activation_fn(hidden_layer(s))
mu = self.mu_layer(s)
log_std = torch.tanh(self.log_std_layer(s))
return mu, log_std.exp()
"""
Crtic
"""
class MLPStateValue(nn.Module):
def __init__(self, state_dim, hidden_dims=(512, ), activation_fn=F.relu):
super(MLPStateValue, self).__init__()
self.input_layer = nn.Linear(state_dim, hidden_dims[0])
self.hidden_layers = nn.ModuleList()
for i in range(len(hidden_dims) - 1):
hidden_layer = nn.Linear(hidden_dims[i], hidden_dims[i + 1])
self.hidden_layers.append(hidden_layer)
self.output_layer = nn.Linear(hidden_dims[-1], 1)
self.activation_fn = activation_fn
def forward(self, x):
x = self.activation_fn(self.input_layer(x))
for hidden_layer in self.hidden_layers:
x = self.activation_fn(hidden_layer(x))
x = self.output_layer(x)
return x
"""
PPO는 On-policy알고리즘임. 그래서 자신이 방금 겪은 경험으로 학습하고 나면 그 경험은 바로 버림
따라서, (st, at, rt, st+1, at+1, 종료여부)를 잠시 저장해두는 바구니
"""
class RolloutBuffer:
def __init__(self):
self.buffer = list()
def store(self, transition):
self.buffer.append(transition)
"""
저장된 경험들을 꺼내고 리스트를 비운다.
"""
def sample(self):
s, a, r, s_prime, done = map(np.array, zip(*self.buffer))
self.buffer.clear()
return (
torch.FloatTensor(s),
torch.FloatTensor(a),
torch.FloatTensor(r).unsqueeze(1),
torch.FloatTensor(s_prime),
torch.FloatTensor(done).unsqueeze(1)
)
@property
def size(self):
return len(self.buffer)
class PPO:
def __init__(
self,
state_dim,
action_dim,
hidden_dims=(64, 64 ),
activation_fn=torch.tanh,
n_steps=2048,
n_epochs=10,
batch_size=64,
policy_lr=0.0003,
value_lr=0.0003,
gamma=0.99,
lmda=0.95,
clip_ratio=0.2,
vf_coef=1.0,
ent_coef=0.01,
):
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.policy = MLPGaussianPolicy(state_dim, action_dim, hidden_dims, activation_fn).to(self.device)
self.value = MLPStateValue(state_dim, hidden_dims, activation_fn).to(self.device)
self.n_steps = n_steps
self.n_epochs = n_epochs
self.batch_size = batch_size
self.lmda = lmda
self.gamma = gamma
self.clip_ratio = clip_ratio
self.vf_coef = vf_coef
self.ent_coef = ent_coef
self.policy_optimizer = torch.optim.Adam(self.policy.parameters(), lr=policy_lr)
self.value_optimizer = torch.optim.Adam(self.value.parameters(), lr=value_lr)
self.buffer = RolloutBuffer()
"""
[-1, 1]사이의 행동을 샘플링
"""
@torch.no_grad()
def act(self, s, training=True):
self.policy.train(training)
s = torch.as_tensor(s, dtype=torch.float, device=self.device)
mu, std = self.policy(s)
z = torch.normal(mu, std) if training else mu
action = torch.tanh(z)
return action.cpu().numpy()
"""
핵심 학습 로직
"""
def learn(self):
self.policy.train()
self.value.train()
# buffer에서 데이터를 통째로 꺼내옴
s, a, r, s_prime, done = self.buffer.sample()
s, a, r, s_prime, done = map(lambda x: x.to(self.device), [s, a, r, s_prime, done])
# GAE 및 log_prob_old 계산
with torch.no_grad():
delta = r + (1 - done) * self.gamma * self.value(s_prime) - self.value(s) # \delta_t 담은 배열
adv = torch.clone(delta) # gae를 담을 배열
ret = torch.clone(r) # return을 담을 배열
for t in reversed(range(len(r) - 1)):
adv[t] += (1 - done[t]) * self.gamma * self.lmda * adv[t + 1]
ret[t] += (1 - done[t]) * self.gamma * ret[t + 1]
# \pi_{old}(a|s) 로그 확률 값 계산하기
mu, std = self.policy(s)
m = Normal(mu, std)
z = torch.atanh(torch.clamp(a, -1.0 + 1e-7, 1.0 - 1e-7)) # act단계에서 tanh를 씌웠으므로, 원래의 정규분포 확률을 계산하기 위해 atanh를 취해 값을 되돌림
log_prob_old = m.log_prob(z).sum(dim=-1, keepdims=True) # 업데이트 전의 전책이 이 행동을 할 확률을 미리 계산해둠
# Training the policy and value network ``n_epochs`` time
dts = TensorDataset(s, a, ret, adv, log_prob_old)
loader = DataLoader(dts, batch_size=self.batch_size, shuffle=True)
# 수집한 데이터로 n_epochs만큼 반복해서 학습함
for e in range(self.n_epochs):
value_losses, policy_losses, entropy_bonuses = [], [], []
for batch in loader:
s_, a_, ret_, adv_, log_prob_old_ = batch
# 가치 네트워크의 손실함수 계산
value = self.value(s_)
value_loss = F.mse_loss(value, ret_) # value loss는 예측한 가치 V(s)와 실제 보상 합계 ret의 차이를 줄임
# 정책 네트워크의 손실함수 계산
mu, std = self.policy(s_)
m = Normal(mu, std)
z = torch.atanh(torch.clamp(a_, -1.0 + 1e-7, 1.0 - 1e-7))
log_prob = m.log_prob(z).sum(dim=-1, keepdims=True)
ratio = (log_prob - log_prob_old_).exp() # 새로운 정책과 옜날 정책의 확률 비율
surr1 = adv_ * ratio
surr2 = adv_ * torch.clamp(ratio, 1.0 - self.clip_ratio, 1.0 + self.clip_ratio) # clipping objective (ppo)
policy_loss = -torch.min(surr1, surr2).mean()
entropy_bonus = -m.entropy().mean()
loss = policy_loss + self.vf_coef * value_loss + self.ent_coef * entropy_bonus
self.value_optimizer.zero_grad()
self.policy_optimizer.zero_grad()
loss.backward()
self.value_optimizer.step()
self.policy_optimizer.step()
value_losses.append(value_loss.item())
policy_losses.append(policy_loss.item())
entropy_bonuses.append(-entropy_bonus.item())
result = {'policy_loss': np.mean(policy_losses),
'value_loss': np.mean(value_losses),
'entropy_bonus': np.mean(entropy_bonuses)}
return result
def step(self, transition):
result = None
self.buffer.store(transition)
# 설정된 스탭만큼 데이터가 모이면, learn을 호출해 학습을 시작함.
if self.buffer.size >= self.n_steps:
result = self.learn()
return result
def evaluate(env_name, agent, seed, eval_iterations):
env = gym.make(env_name)
scores = []
for i in range(eval_iterations):
(s, _), terminated, truncated, score = env.reset(seed=seed + 100 + i), False, False, 0
while not (terminated or truncated):
a = agent.act(s, training=False)
s_prime, r, terminated, truncated, _ = env.step(a)
score += r
s = s_prime
scores.append(score)
env.close()
return round(np.mean(scores), 4)
def seed_all(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
env_name = 'Hopper-v5'
seed = 0
seed_all(seed)
max_iterations = 1000000
eval_intervals = 10000
eval_iterations = 10
# activation_fn = F.relu
activation_fn = F.tanh
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
agent = PPO(
state_dim,
action_dim,
activation_fn=activation_fn,
)
logger = []
(s, _), terminated, truncated = env.reset(seed=seed), False, False
for t in tqdm(range(1, max_iterations + 1)):
a = agent.act(s)
s_prime, r, terminated, truncated, _ = env.step(a)
result = agent.step((s, a, r, s_prime, terminated))
s = s_prime
if result is not None:
logger.append([t, 'policy_loss', result['policy_loss']])
logger.append([t, 'value_loss', result['value_loss']])
logger.append([t, 'entropy_bonus', result['entropy_bonus']])
if terminated or truncated:
(s, _), terminated, truncated = env.reset(), False, False
if t % eval_intervals == 0:
score = evaluate(env_name, agent, seed, eval_iterations)
logger.append([t, 'Avg return', score])
logger = pd.DataFrame(logger)
logger.columns = ['step', 'key', 'value']
fig = plt.figure(figsize=(12, 4))
ax = fig.add_subplot(1, 4, 1)
key = 'Avg return'
ax.plot(logger.loc[logger['key'] == key, 'step'], logger.loc[logger['key'] == key, 'value'], 'b-')
ax.grid(axis='y')
ax.set_title("Average return over 10 episodes")
ax.set_xlabel("Step")
ax.set_ylabel("Avg return")
ax = fig.add_subplot(1, 4, 2)
key = 'policy_loss'
ax.plot(logger.loc[logger['key'] == key, 'step'], logger.loc[logger['key'] == key, 'value'], 'b-')
ax.grid(axis='y')
ax.set_title("Policy loss")
ax.set_xlabel("Step")
ax.set_ylabel("Policy loss")
ax = fig.add_subplot(1, 4, 3)
key = 'value_loss'
ax.plot(logger.loc[logger['key'] == key, 'step'], logger.loc[logger['key'] == key, 'value'], 'b-')
ax.grid(axis='y')
ax.set_title("Value loss")
ax.set_xlabel("Step")
ax.set_ylabel("Value loss")
ax = fig.add_subplot(1, 4, 4)
key = 'entropy_bonus'
ax.plot(logger.loc[logger['key'] == key, 'step'], logger.loc[logger['key'] == key, 'value'], 'b-')
ax.grid(axis='y')
ax.set_title("Entropy bonus")
ax.set_xlabel("Step")
ax.set_ylabel("Entropy bonus")
fig.tight_layout()
# plt.show()
plt.savefig('./output/output.png')
- PPO는 2,000번 이상 환경과 상호작용하며 데이터를 수집하고 네트워크 파라미터를 여러번 업데이트 시킵니다.
- PPO class에 vf_coef, ent_coef, clip_ratio등은 ppo objective function을 구성하기 위한 재료이다.
- learn 메서드에서, GAE actor-critic과 같이 동작하며, 구한 Value, Advantage, importance sampling coeffient 값을 통해, 수집한 데이터로 여러번 정책을 업데이트 한다.
- n_epoch번 네트워크가 업데이트 되는 동안 $\pi_{\theta_{old}}$는 고정되어 있다.
- RolloutBuffer를 통해 on-policy (PPO는 on-policy이다) 데이터 수집 및 폐기를 구현한다.
- 사실 importance sampling과정에서 off-policy처럼 보일 수 있지만, on-policy이다. (미세한 off-policy)
- MLPGaussianPolicy, MLPStateValue 클래스로 정책 네트워크 및 상태 가치 네트워크를 각각 구현한다 (같은 네트워크 X)
- PPO 알고리즘으로 Gymnasium MuJoCo 환경 중 하나인 Hopper-v4를 제어한다.
- PPO activation을 ReLU, tanh로 바꿔가며 실험한다.
- 실제로 PPO는 $N$개의 policy가 각각 병렬적으로 환경과 $T$번 상호작용하며 $NT$개의 경험 데이터를 획득하고, 이 경험 데이터들을 사용하여 목적 함수를 최적화 한다.
- 이 코드는 $N=1$ 인 경우인데, PPO는 $N=1$경우에서 잘 동작하지 않는다. 그 이유는 1개의 환경에서 상호작용하여 얻은 $T$개의 데이터가 서로 너무 correlated되어서 과적합 확률이 높아지기 때문이다.
- 병렬 에이전트는 PPO등 on-policy알고리즘 성능 향상에 거의 필수적이다.
- 이 코드는 $N=1$ 인 경우인데, PPO는 $N=1$경우에서 잘 동작하지 않는다. 그 이유는 1개의 환경에서 상호작용하여 얻은 $T$개의 데이터가 서로 너무 correlated되어서 과적합 확률이 높아지기 때문이다.
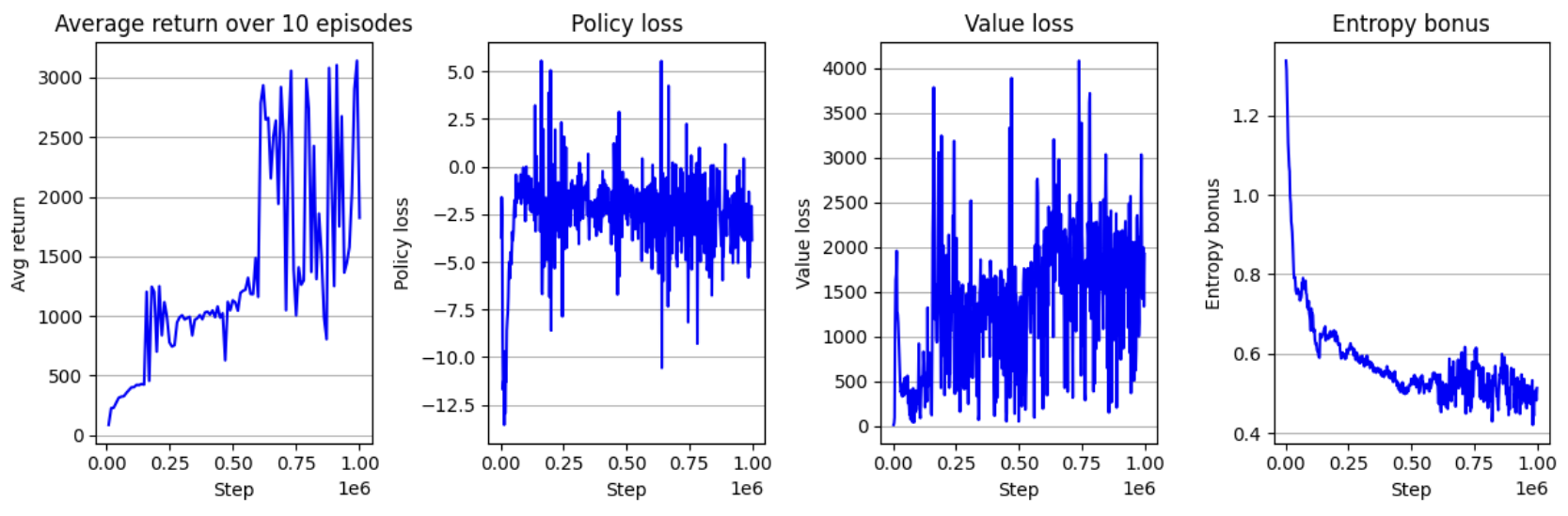

실제로 activation으로 tanh를 쓰면, Avg return이 1.5배 높아졌다. 이러한 현상은 on-policy에서 상당히 흔한? 현상이라고 한다. 이는 구현이 매우 복잡한 TRPO와 비슷한 성능이다.