![[ 딥러닝 논문 리뷰 - PRMI Lab ] - DreamFusion: Text-to-3D using 2D Diffusion (ICLR 2023)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FldZE5%2FbtsNLm8Wt4X%2FAAAAAAAAAAAAAAAAAAAAAEK44OxLHqmx9j6A1gnT4hPxMqwGXkG1YHgRhvTLkIc-%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DZeLS7OjV5xwqLzz2PawOfLh8pY8%253D)
CS492(D)강의를 들으면서 인상깊었던 논문을 개인적으로 찾아보던중, SDS loss라는 개념이 인상깊어서 해당 논문을 간단하게나마 리뷰하고 정리하겠습니다. DreamFusion의 핵심인 SDS Loss에 대해 알아보고, DreamFusion에서 사용되는 shading기법에 대해 간단히 알아보겠습니다.
논문 링크: https://arxiv.org/pdf/2209.14988
참고: https://xoft.tistory.com/39
[논문 리뷰] DreamFusion (ICLR 2023) : Text to 3D 연구
DREAMFUSION: TEXT-TO-3D USING 2D DIFFUSION, Ben Poole, arXiv2022, Google Resarch Dream Fusion에서는 NeRF와 Diffusion Model기반의 Text-to-2D 모델을 사용해서 Text-to-3D 방법을 제시합니다. 유사한 이전 연구인 Dream Fields(2022)는
xoft.tistory.com
성민혁 교수님 강의: CS492(D)
SDS Loss

기존의 DDPM Loss는 위와같은 형태입니다. U-net을 통해 \(x_t, t\)를 주면 noise를 예측하는 식입니다. DDIM도 비슷합니다. DreamFusion에서 사용되는 SDS Loss에 대해 간단히 알아보겠습니다.
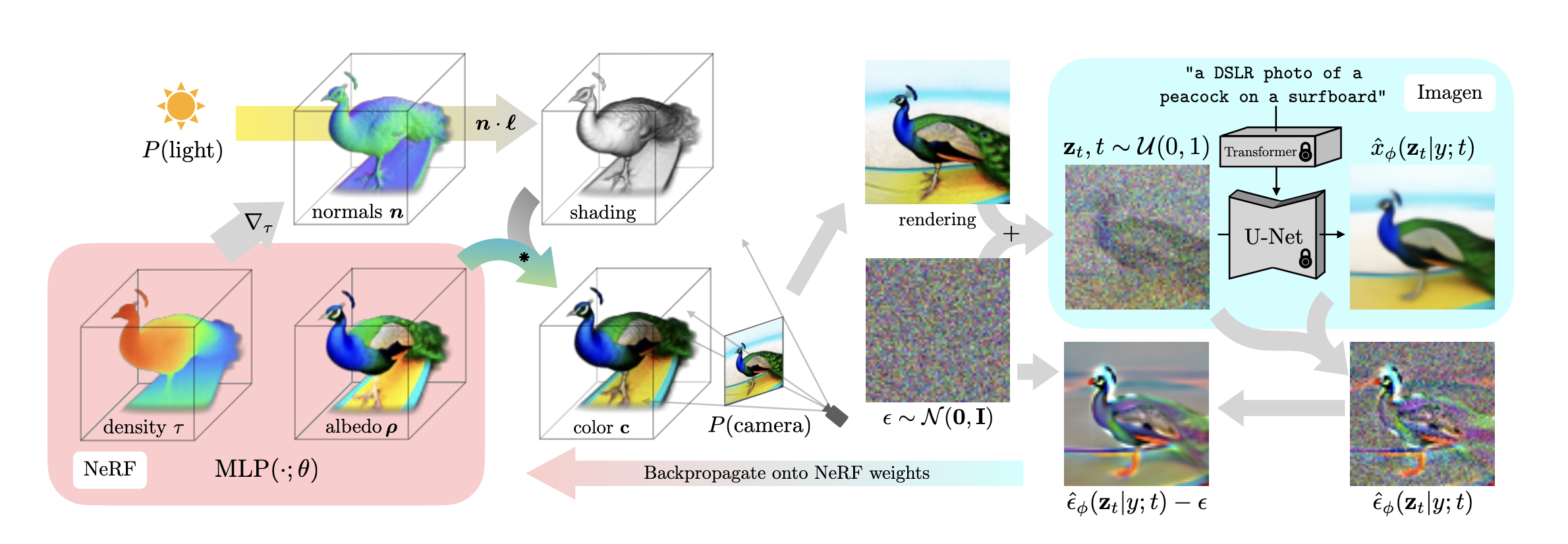

DreamFusion의 오른쪽 부분이 SDS부분입니다. DreamFusion에서 입력은 NeRF로 생성된 이미지입니다. 위 수식에서와 같이 \(g(\theta ; c)\) 특정 angle에서 샘플링된 이미지라고 할 수 있습니다. 이는 DDPM에서의 \(x_0\)이라고 할 수 있습니다.

\(x_t\)를 noise를 추가해서 만들 수 있습니다. 여기서 \(y\)는 text를 임베딩 한 값입니다. 이를 \(\hat{\epsilon}_{\theta}\)에 넣는데, 이는 noise predictor입니다. 이의 결과를 실제 noise와의 차이를 구성해 loss식을 만들 수 있습니다.
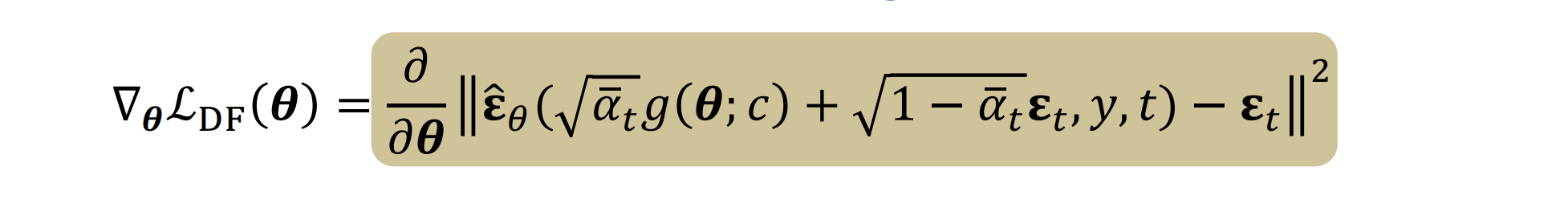
그리고 이에 대한 Gradient를 취하면 위와같은 최종 Gradient식이 완성됩니다. 이제 여기서 DreamFusion저자들은 training speed를 향상시키기 위해 일종의 trick을 사용합니다.

\(\nabla_{\theta}\mathcal{L}_{DF}(\theta)\)을 chain rule을 이용해 분해하면 Noise Predictor Jacobian이 중간에 있게됩니다. \(\hat{\epsilon}_{\theta}\)는 parameter가 많은 모델이기 때문에, 이를 계산하기 위해서는 memory가 매우 많이 필요합니다. 저자들은 간단히 해당 term을 0으로 만들어도 SDS가 잘 동작한다는 것을 발견해서 실제로 omit했다고 합니다. 위 그림에서 U-net이 lock되어있는 이유도 이에 해당합니다.
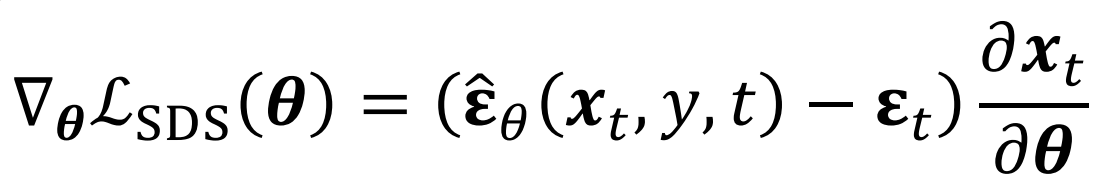
그럼 위와같이 SDS loss를 구성할 수 있습니다. DreamFusion의 Appendix에는 해당 수식이 왜 동작하는지에 대한 증명도 있습니다.
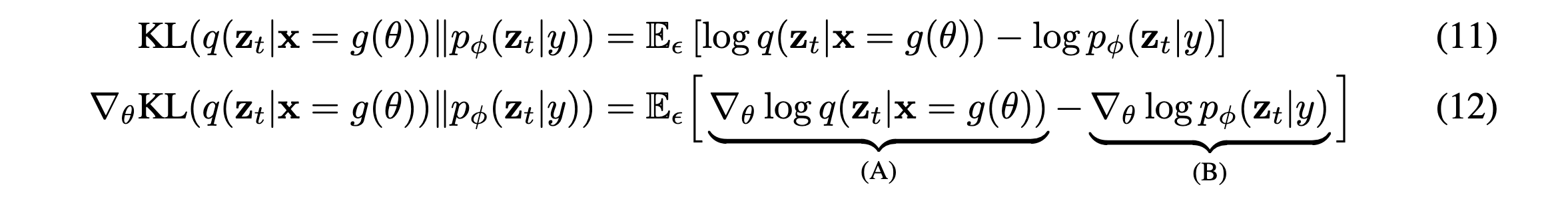
NeRF로 rendering한 이미지 \(x\)가 있고, latent variable \(z_t\)를 만드는 확률분포 \(q\)와 텍스트로 임베딩된 \(y\)가 주어질때 U-net의 파라미터에 따라 다른 확률분포를 만드는 \(p_{\phi}\)간의 KL-Divergence를 최소화하기 위해 위 식을 구성합니다[weighted density distillation(2018)]. 그리고 \(\epsilon\)으로 샘플링한 기댓값으로 나타내고, Gradient를 취하면 (A), (B)와 같은 항으로 구성되게 됩니다. 먼저 (A)의 \(z_t\)는 \(\theta\)에 대해 고정된 값이 만들어지기 때문에 미분값이 0입니다.
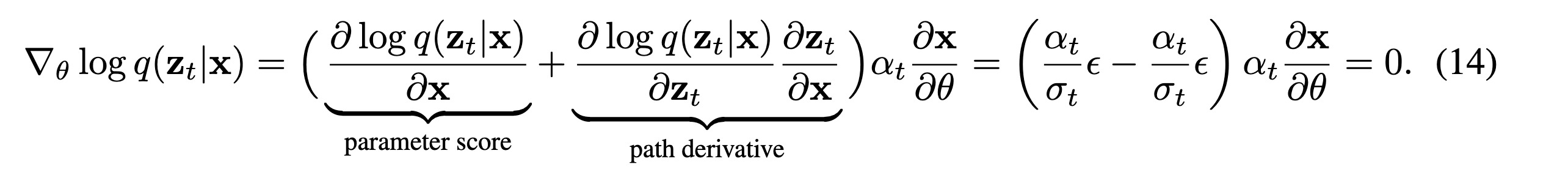
위와같이 우리는 (A)을 parameter score + path derivate로 분해하여 표현할 수 있는데, Stikcking-the-Landing이라는 논문에서 path derivate만 남기고 parameter score를 제외시키면 path derivate가 다른 Loss term과 correlate되어 variance가 줄어들게 된었다고 해서, 해당 Term을 사용하겠다 합니다.
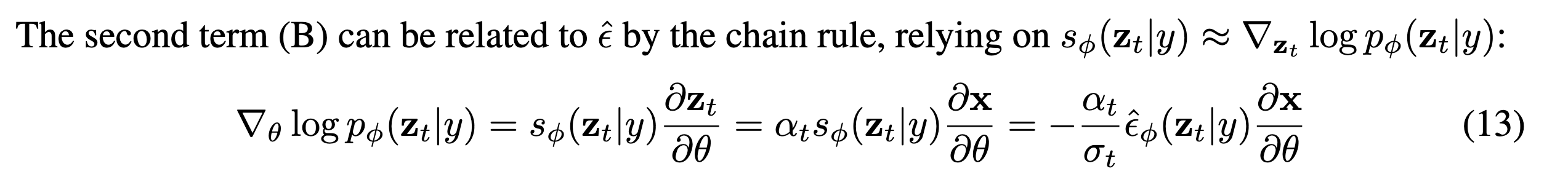
(B) term은 score function을 chain rule로 분해하여 위와같이 나타냅니다. NeRF parameter \(\theta\)에 대해 결정되니까 score function의 정의에서 chain rule로 분해해 주어야 합니다.
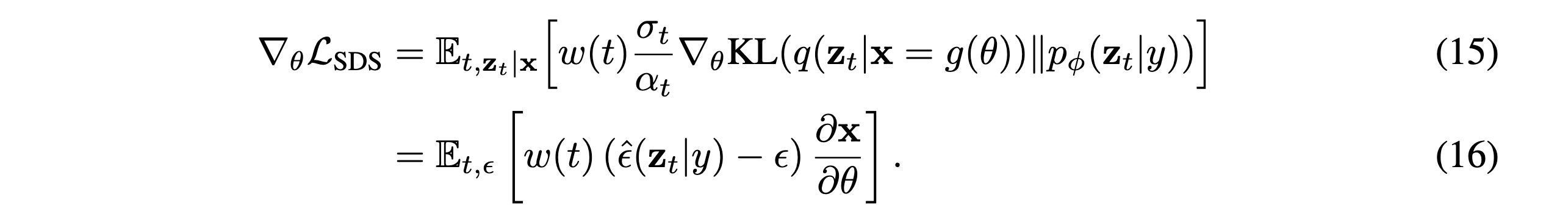
최종적으로 위와같은 식을 만들 수 있는데, 이를 통해 lower-variance gradient를 가지면서 안정적이고 빠르게 수렴하게 만들 수 있다고 합니다.
Rendering
위 그림을 보면, SDS Loss를 사용하는 부분을 제외한 왼족 부분은 NeRF를 이용해서 이미지를 sampling하는 과정입니다. sampling을 하는 과정을 간단히 설명하겠습니다.
random camera pose, light position을 사용해서 64x64의 shade된, NeRF로 sampling한 이미지를 생성합니다. 기존의 NeRF와 다른점은, 3가지의 서로 다른 rendering 방법을 랜덤으로 사용했다는 점입니다.
- shading없이 albedo \(\rho\)로 렌더링 (NeRF는 view-dependent)
- shading하여 렌더링
- albedo \(\rho\)를 white로 바꿔서 shading하여 렌더링
그럼 DreamFusion에서 shading을 어떻게 구현했는지 보겠습니다.
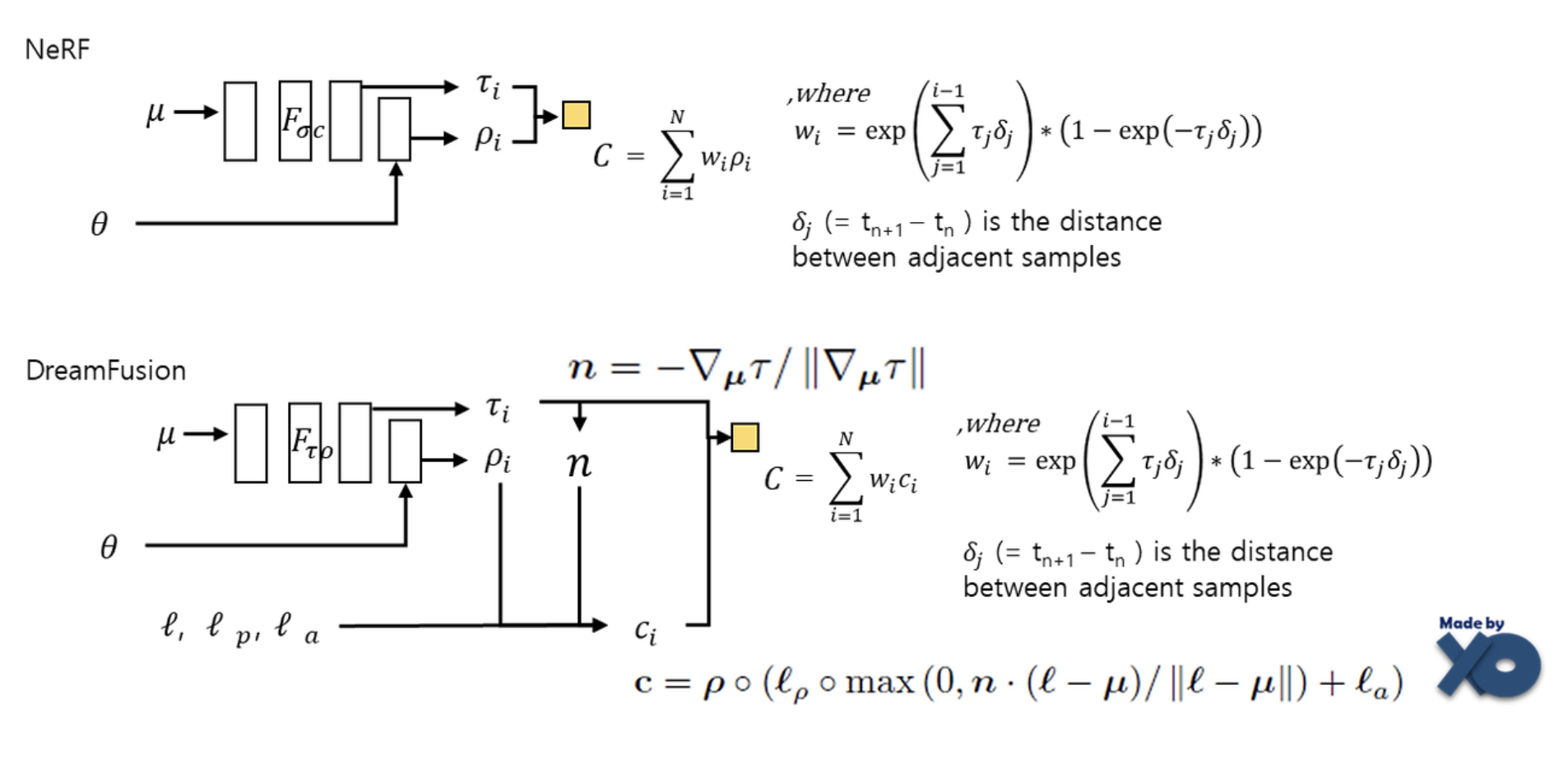
NeRF는 Ray의 방향에의해 결정되는 radiance color \(\rho\)을 volume rendering하여 color pixel값을 결정했습니다. DreamFusion은 위 방식에 추가조명을 활용하여 조명에 따라 달리 보이는 surface color c을 활용하여 volume rendering합니다.
DreamFusion에서는 volume density \(\tau\)에 대해 미분하여 normal vector n을 계산합니다. 여기서 n은 geometry의 local 방향성을 알려주는 vector입니다. 그리고 light 3D point \(l\)에서 발산되는 조명 색상 \(l_p\)와 ambient 조명 색상 \(l_{\alpha}\)를 가정하여, diffuse reflectance가 위 수식의 \(c\)와 같이 계산되어 최종적인 volume rendering을 통해 color 가 계산됩니다.
추가로 albedo \(\rho\)를 white color (1, 1, 1)로 바꿔주면, texture가 없는 shaded output을 만들 수 있습니다. 이렇게 shaded x albedo를 통해 color를 결정하면 물체의 외형 정보와 조명 효과가 분리되어 모델링됩니다. 즉 이를 통해 성능을 높일 수 있었다고 합니다.
추가적인 최적화기법은 나중에 시간이 되면 추가하겠습니다.
Experiments

위와같이 하나의 scene에 대해 text prompt로 refine 3D scene을 구성할 수 있습니다.
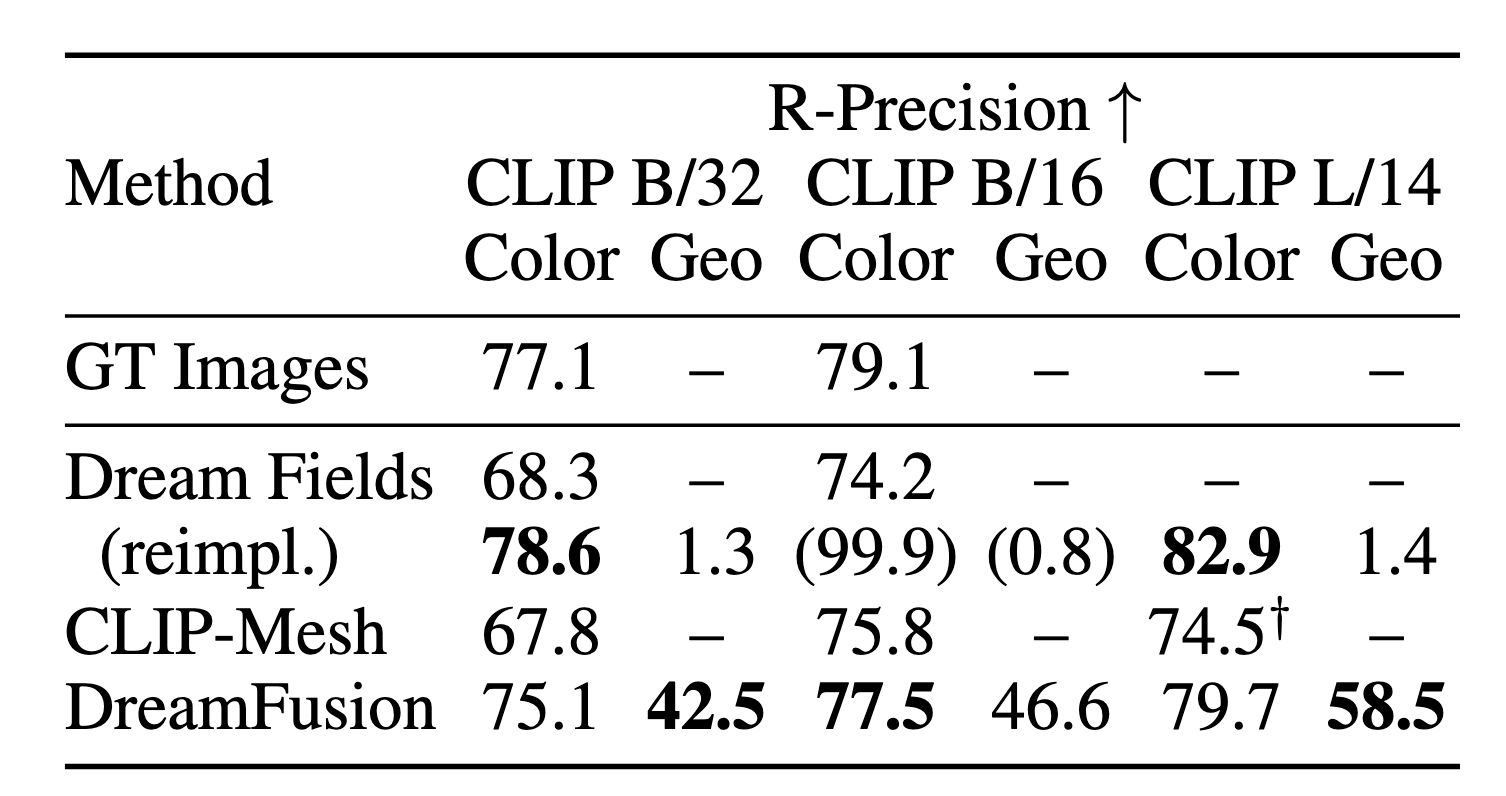
3D reconstruction task는 일반적으로 recovered geometry와 GT간의 Chamfer Distance를 계산하여 평가하고, view-synthesis는 rendered된 veiw와 GT를 비교하는데 PSNR를 씁니다. 하지만 이에 대한 zero-shot에 대해서는 GT가 없기 떄문에, 입력 문장에 대한 렌더링된 이미지의 일관성을 측정하는 CLIP R-Precision으로 평가합니다. R-Precision은 렌더링된 이미지가 주어질때 CLIP이 오답 텍스트중에 정답을 적절히 찾는 정확도로 계산됩니다. 이에 대한 다양한 zero-shot text-to-3D모델과의 비교 결과입니다.
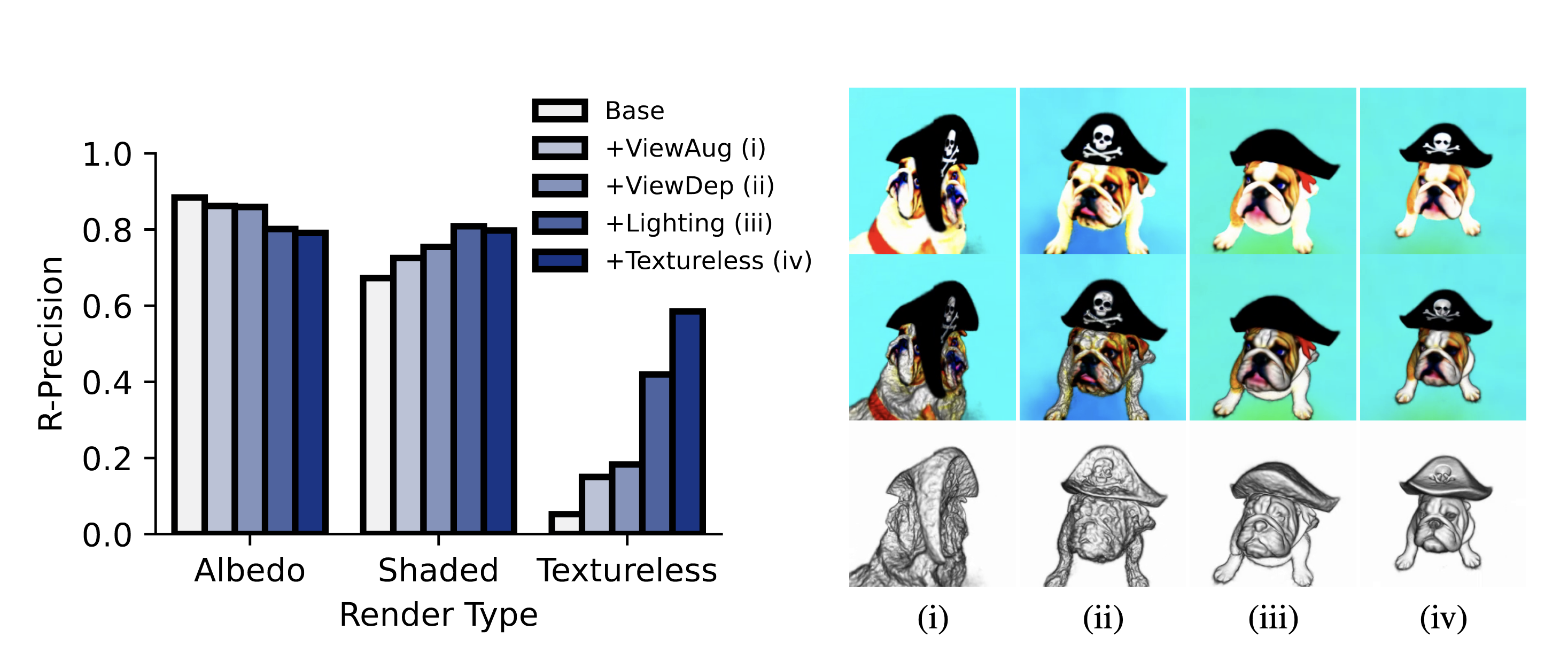
Ablation결과입니다. 위 4개의 최적화 방법을 점진적으로 늘려 실험했습니다.
- viewpoints의 범위 늘리기 (i)
- (ii)가 없다면 얼굴이 2개가 나올 수 있음
- view-dependent한 prompt engineering (ii)
- geometry를 향상시켰지만 surface가 non-smooth함.
- 추가 조명 사용 (iii)
- geometry를 향상시켰지만 어두운 부분은 여전히 non-smooth함.
- albedo를 white으로 만들어 shading (iV)
- geometry를 smooth하게 함.