![[ 딥러닝 최신 알고리즘 - PRMI Lab ] - Emerging Properties In Self-Supervised Vision Transformers (DINO)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcDEnza%2FbtsD1ncknmo%2FEzSSMXTbFuyNxh0xMyadE0%2Fimg.png)
이전에는 Swin Transformer에 대해 알아봤습니다. 이번에는 새로운 Transformer Architecture를 제안하는 논문보다는, 방법론적인 측면에 보다 집중한 논문을 읽어보고 싶었습니다. DINO(Distillation with No label)을 살펴볼 것인데, 해당 논문에서는 Self-Supervised learning 과 관련된 사전 지식이 필요로 했습니다. Self-Supervised learning에서의 evaluation protocol나 이전에 제안되었던 SimCLR, MoCo, BYOL,.. 등을 말이죠. 몰라도 괜찮습니다, 해당 포스팅에서 제가 간단히 짚으면서 넘어가겠습니다.
해당 논문에서, DINO의 구조, DINO를 훈련시키는 방법, DINO의 성능 평가 방법과 훈련시에 디테일한 부분까지 다룹니다.
논문과 코드의 링크, 공부할때에 도움이 되었던 고려대학교 DSBA연구실의 세미나 자료도 첨부하겠습니다.
Abstract

해당 논문은 self-supervised learning(SSL)이 ViT에 새로운 특성을 추가해줄 수 있지 않을까? 로부터 시작되었습니다. 실제로, ViT와 SSL을 통해 image의 semantic segmentation정보를 잘 뽑아낼 수 있었다고 하고, SSL로부터 뽑아낸 image의 feature는 아무런 사후 작업없이 k-NN classifiers와 끝내주는 궁합을 나타냈다고 합니다.
MoCo에서 제안되었던 momentum encoder와 multi-crop training, ViT에서의 작은 patch크기를 통해 DINO를 간단한 구조로 구현했습니다. 이는 ViT-Base + DINO를 linear-evaluation을 했더니 80.1% top-1 accuracy를 찍었다고 합니다. 이제부터 이와 관련된 이야기를 시작해보겠습니다.
1. Introduction
ViT와 convnet의 성능은 비슷하지만, 아직까지 ViT가 convnet과 비교했을때 갖는 확실한 이점이 없었습니다. ViT는 일반적으로 convnet보다 계산 비용이 더 많이들고, 훈련셋도 더 많이 필요하고, feature가 unique한 특성을 나타내지도 않습니다. 그래서 ViT의 숨겨진 성공요소를 SSL을 통해 찾기로 합니다.
NLP task에서 Transformer의 성공을 위한 주요 요소가 SSL입니다. BERT, GPT만 봐도 알 수 있습니다. 이러한 SSL의 목적은 pretext task를 통해 supervised 방법보다 더 부유한 학습 신호를 제공하는 것에 있습니다. 마찬가지로 vision task에서도 복잡한 이미지 정보가 사전에 정의된 카테고리의 단일 개념으로 축소됩니다.
DINO이전의 SSL논문에서 다양한 SSL방법들은 이미지에서 큰 효과가 있음을 밝혔습니다. 이러한 방법들에서는, NLP task와 유사하나, 일반적으로 자명해(collapse)를 피하거나 성능을 증가시키기 위한 다른 구조를 사용합니다. 그래서 저자들은 ViT feature들에서 SSL의 영향력을 연구했고 supervised ViT나 convnet에는 나타나지 않은 흥미로운 요소들을 발견할 수 있었다고 합니다.
- (1) SSL ViT feature들은 위의 Abstract에 있던 그림과 같이 object boundaries를 명시적으로 표현합니다.
- (2) SSL ViT feature들은 finetuning, linear classifier, data augmentation없이 k-NN classifier에서 특히 잘 수행됩니다.
(1) 특성은 SSL이면 일반적으로 가지는 특성이고, (2)는 DINO에서 momentum encoder와 multi-crop augmentation가 함께 적용되어야지만 유효한 특성입니다. 위에서도 말했지만 VIT에서 작은 patch크기를 갖는 것은 좋은 feature vector를 뽑아내기 위한 중요한 특성입니다.
이렇게 제안된 DINO는 뒤에서 자세히 다루겠지만 teacher network를 momentum encoder로 구축하고 표준 cross-entropy loss를 사용하여 student network의 출력과 비교해서 student network에 gradient를 흘려주어 업데이트 합니다 (teacher network는 ema로 업데이트 됩니다). DINO는 또한, collapse를 피하기 위해 기존의 SSL에 사용되었던 advanced normalization, contrastive loss를 사용할 필요가 없습니다. 오직 centering과 sharpening을 통해서 모델의 구조에 변화나 추가적인 내부 정규화를 적용할 필요 없이 convnet, ViT에서 유연하게 사용할 수 있습니다.
실험 부분에서는, 이전의 SSL feature들과 DINO의 feature를 linear evaluation을 통한 결과를 비교하며 DINO와 ViT의 시너지를 검증합니다. 추가로 SOTA ResNet-50구조와 DINO가 함께 같이 잘 적용됨을 보여줍니다. ViT로 DINO를 훈련시키는데 2개의 8-GPU만 있으면 3일이면 ImageNet linear classification 벤치마크 76.1%를 달성할 수 있다고 합니다.
2. Related work
Self-supervised learning과 관련된 연구들을 나열하고 있습니다. 초기에는 각각의 unlabeled image내 하나의 이미지에 대해 K개의 transformation을 시킨다음에, 해당 이미지 간에는 같은 클래스라고 예측하게 한 Exemplar가 있었습니다. 이렇게 하면 동일한 class내에 존재하는 patch가 갖는 공통된 특징을 최대화하고, 서로 다른 class내에 존재하는 patch들의 different feature를 잘 구별할 수 있게됩니다. 이 외에도 하나의 이미지 외에는 다 다른 클래스라고 둔다음에, contrastive learning(InfoNCE loss)을 하는 SimCLR이 있습니다. (이 외에도 MoCo, SimCLR2, MoCo2,.. etc) 이러한 방법에서는 명시적으로 정해진 클래스의 분류기를 학습하는 것이므로 확장성에 있어서 문제가 있고 대규모의 데이터셋에서는 잘 작동하지 않는다는 문제점이 있습니다.
그래서 분류하는 것이 아닌 노이즈를 통해 비교하는 NCE기반의 모델이 나왔지만 이 또한 대규모의 이미지를 동시에 처리해야하므로 memory bank나 추가적인 기술과 메모리가 많이 필요합니다.

최근 연구는 위와같이 계산량, negative sample에 대한 의존성, 큰 batch size가 필요하다는 단점을 해결하기 위해 unsupervised feature를 학습할때 image를 discriminating하는 매커니즘을 없애버립니다. 그래서 나타난게 BYOL 입니다. 여기에는 momentum encoder를 사용해 특징을 뽑아닙니다. 추가적으로 BYOL에서 uniform distribution을 뽑아내는법, whitening을 사용하는 법같이 더 정교한 representation을 뽑아내는 방법이 연구되었는데, 이는 DINO에게 많은 영감을 준 부분입니다. 결과적으로 DINO는 BYOL과 동일한 student-teacher architecture를 사용하지만, 조금 다른 similarity matching loss를 사용합니다 (BYOL은 negative cosine sim, DINO는 cross entropy).
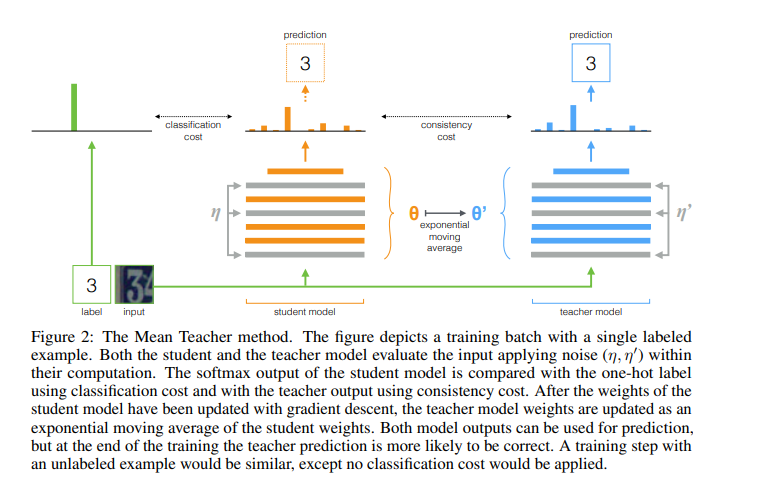
DINO는 이름부터 self-distillation with No labels이기 때문에, SSL방식으로 knowledge distillation의 원리를 활용합니다. 이 접근방식에서 지식 전달은 레이블이 없는 상황에서도 효과적인 학습을 가능하게 합니다. teacher가 SSL방식으로 목표를 생성하고 이를 student가 따라오도록 유도합니다. 이를 통해 teacher는 많은 모델을 앙상블 하는 효과를 지니게 됩니다(Polyak-Ruppert averaging). 즉 DINO는 BYOL로 부터 초기화된 구조로 mean teacher self-distillation + no-label 상황에서의 self-supervised learning을 수행하는 것이라고 정리할 수가 있겠습니다.
3. Approach
3.1 SSL with Knowledge Distillation
DINO구조는 위 Section2에서 말한 그대로입니다.
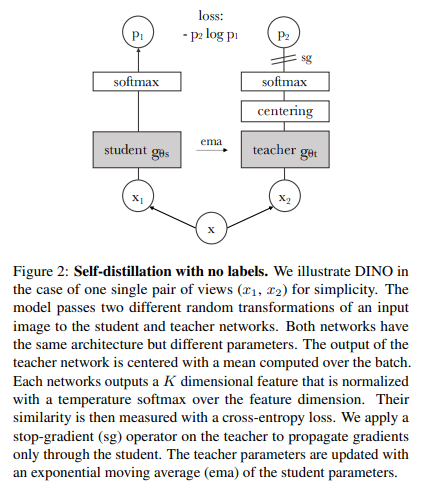
그리고 DINO의 pseudo code는 아래와 같습니다. 이제부터 설명할 내용들과 매칭해서 보시길 바랍니다.

Knowledge distillation은 student network gθs를 학습시킬때 teacher network gθt와 출력을 맞춰주는 학습 패러다임입니다. DINO에서 이미지 x가 주어졌을때 두개의 network는 K차원의 Ps와 Pt를 출력하게 됩니다. 이는 확률분포이며 softmax를 통해서 얻을 수 있습니다.
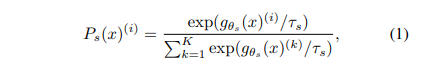
식은 위와같습니다. 여기서 τs>0는 temperature 파라미터로서 output distribution의 뾰족한 정도를 결정합니다. 최대한 0에 가깝게 설정해줘야 collapse가 일어나지 않습니다. 그리고 student와 teacher의 temperature는 다를 수 있습니다. 이제 Ps(x)(i)와 Pt(x)(i)의 cross entropy loss를 최소화 시켜서 두 신경망의 출력 분포를 일치시킵니다.
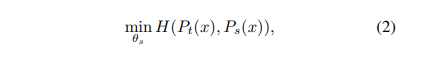
이제 이러한 과정을 저자들이 Eq2에 어떻게 self-supervised learning을 적용하였는 디테일한 부분에 대해 설명하겠습니다. 먼저 저자들은 하나의 이미지에 대해 multi-crop strategy로 이미지의 distorted view나 crop를 구성합니다. 아래와 같이 말이죠.

이를 좀 더 수식적으로 설명하자면, view set V를 생성합니다. 이 set은 xg1와 xg2와 같은 global view와 작은 해상도에서의 local view를 포함합니다. 모든 view set V는 student network를 통과할 수 있지만 teacher는 global view만을 통과할 수 있습니다. 이를 통해 local-to-global 대응을 촉진시킵니다.
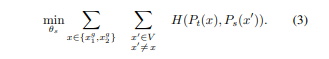
최종적으로 위와같은 loss식을 최소화하게 됩니다. 이러한 loss는 2개의 view뿐만 아니라 여러 개의 view에 대하여 사용할 수 있습니다. 하지만 저자들은 여기에서는 global views로는 원본 이미지의 넓은 영역을 포함하는 2242해상도의 이미지를, local view로는 원본 이미지의 좁은 영역을 포함하는 962해상도의 이미지를 기본 DINO설정값으로 합니다.
Teacher network
우리는 knowledge distillation과는 다르게 priori(사전 지식)으로 teacher network gθt를 가지지 않습니다. Section 5.2에서 이러한 teacher network의 업데이트 방식을 다르게 하면서 DINO의 성능을 평가합니다. 결과론적으로 student network의 이전 iteration결괏값으로 teacher network를 업데이트 하는 것이 성능이 가장 좋습니다(epoch마다는 teacher network freeze). 그 외에는 대부분이 수렴하지 않습니다. 이 중에서도 student network의 iteration 결괏값을 exponentiaon moving average (EMA)방식으로 업데이트하는 momentum encoder가 DINO와 잘 맞았다고 합니다.
이에 대한 업데이트 규칙은 아래 수식과 같습니다.
여기서 λ는 0.996 -> 1로 cosine schedule을 통해서 증가시킨다고 합니다. 여기서 momentum encoder의 역할은 기존의 MoCo에서는 contrastive learning의 큐에서 사용했지만, DINO에서는 큐가 없기에 다른 역할을 합니다. 바로 위에서 언급했던 SSL에서의 Mean teacher의 역할을 합니다. 그리고 이는 실험결과 Polyak-Ruppert averaging역할을 하며, 여러 모델을 앙상블 + robust한 효과를 낼 수 있었다고 합니다. 이는 결국 teacher가 고품질의 target feature를 생성해내 student의 학습을 가이드하게 되어 teacher가 student보다 더 성능이 좋게되는 결과가 나옵니다.
Network architecture
DINO 신경망 g는 ResNet backbone f와 projection head h로 이루어져 있습니다. 그리고 downstream task에서 사용되는 feature는 backbone f의 출력값입니다. 또한, projection head는 3-layer MLP로 이루어져있고, hidden_dim=2048, l2 normalization, weight normalized fully-connected layer with K dimensions로 구성되어 있습니다.
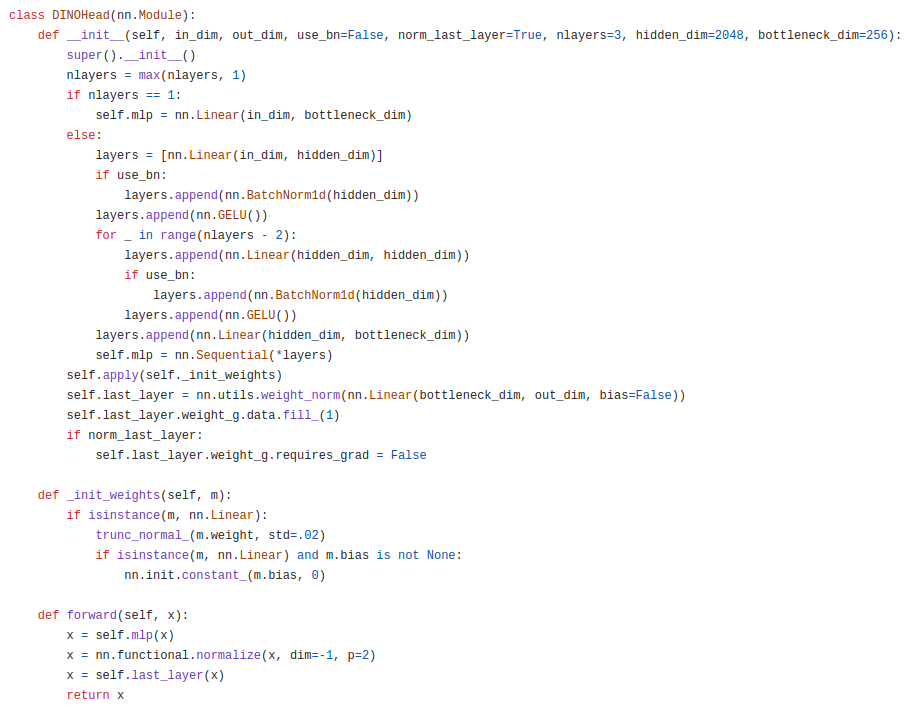
위는 공식 코드를 참고한 것이며, 실제로 3-layer MLP로 이루어져있고, l2 normalize, weight_norm이 다 적용되어있는 것을 볼 수 있습니다. 그 외에도 옵션으로 BN을 줄 수 있는데, ViT기반 아키텍처에서는 BN을 대부분 사용하지 않습니다. 이렇게 옵션으로 준 이유도 ablation study를 위한 것으로 판단됩니다. 참고로 BYOL은 collapse를 피하기 위해 student network에서 predictor를 사용하기도 했는데, DINO에서는 해당 predictor가 성능을 더 떨어트리기 때문에 사용하지는 않습니다.
Avoiding collapse
여러 SSL방법이 contrastive loss, clustering constraints, predictor, batch normalization을 collapse를 피하기 위해 사용됩니다. DINO는 여러 정규화방법으로 안정화될 수는 있지만, collapse를 피하기 위해 오직 centering, sharpening을 사용했습니다.
Section 5.3에서 자세히 설명하겠지만, centering은 특징 벡터가 한쪽으로 dominate하게 쏠리는 것을 방지하지만 uniform distribution하게 만들어 버립니다. shaprening은 이와는 반대의 특성을 가집니다. 해당 기법 2개가 상호보완적으로 특징 벡터를 밸런스있게 만들어낸다는게 저자들의 주장입니다. 하지만 이러한 방법은 batch에 대한 의존도를 낮추기 위해 안정성이 낮아집니다. 그 이유는 centering이 1차 batch 통계에만 의존하여 teacher에 bias항을 추가하는 것으로 해석될 수 있기 때문입니다. -> 결국 batch size가 있어야 한다는 의미임. 그래서 batch size가 다르더라도 잘 적용되게 하기 위해서 gt(x)←gt(x)+c로 업데이트 될때, c는 ema로 업데이트되게 합니다. 식은 아래와 같습니다.
여기서 m>0은 rate parameter이고 B는 batch size입니다. sharpening은 τt값을 낮게 두는 것으로 간단히 구현될 수 있습니다.
3.2 Implementation and evaluation protocols
Vision Transformer
저자들은 DeiT의 구조를 따랐습니다. 이에 대한 자세한 내용은 아래 Table 1을 참고하기 바랍니다.
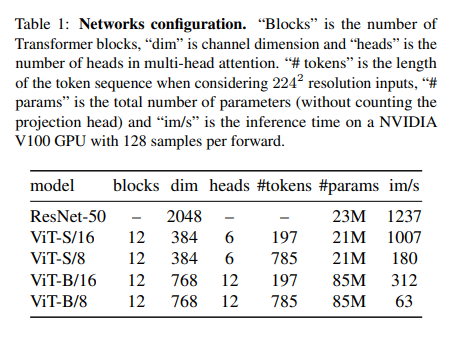
ViT아키텍처에서는 NxN이미지 패치의 시퀀스를 입력으로 받습니다. 본 논문에서는 일반적으로 N=16("/16)이나 N=8("/8)을 사용하였습니다. 이 패치들은 최종적으로 liear embedding을 거치게 됩니다.
저자들은 추가 학습 가능한 토큰을 넣어 전체 시퀀스의 정보를 집계하도록 CLS token을 집어넣어 주었습니다. 그리고 이의 출력에 projection head h를 붙혔습니다. 사실 DINO는 supervised learning이 아닌데 기존 연구와의 일관성을 위해 CLS token이라고 명명한 것입니다.
Implementation details
- dataset: ImageNet에 대해서 레이블 없이 Pre-train
- batch size: 1024, AdamW, 16 GPUs -> when using ViT-S/16
- learning rate: 처음 10epoch만 0.005 x batchsize/256까지 warmup 후 cosines annealing
- weight decay: cosine schedule로 0.04 -> 0.4
- τs=0.1, τt는 0.04 -> 0.07로 초반 30 epochs 동안 linear-warmup
- BYOL의 data-augmentation사용 (color jittering, Gaussian blur and solarization) + multi-crop
Evaluation protocols
SSL을 평가하는 표준 프로토콜은 고정된 feature들은 linear classifier로 학습시키거나 feature들을 downstream task에 대하여 finetune시키는 것입니다.
Linear evaluation을 위해서는 random resize crop과 horizontal flips augmentation을 학습에 사용하고 central crop에 대한 accuracy를 측정했습니다. Finetuning evaluation을 위해서는 사전 학습된 가중치로 신경망을 초기화하고 학습 단계에서 adapt시켰다고 합니다.
하지만 두 evaluation방법 모두 hyperparameter에 sensitive하므로 learning rate를 바꾸면서 실행했는데, 정확도가 크게 바뀌는 것을 발견했다고 합니다. 따라서 저자들은 feature들의 품질을 평가하기 위해서 weighted k-NN classifier로 측정하였습니다. Pre-train된 모델은 고정시키고 feature를 계산한뒤 저장합니다. 그런다음 k-NN classifier는 이미지의 feature을 가장 가까운 k개의 저장된 feature와 매칭시킨다음에 voting을 진행합니다.
그리고 저자들은 k=20일때가 정확도가 가장 높았다고 합니다. 이 evaluation방법은 추가 hyperparameter tuning이나 data augmentation없이도 downstream task에 대해서 1번만 실행하면 되기 때문에 feature evaluation을 매우 간단하게 만든다고 합니다.
4. Main Results
먼저 SSL on ImageNet에 대해 DINO의 벤치마크를 검증해볼 것입니다. 그 후에는, DINO의 결과 feature를 image retrieval, object discovery, transfer-learning에 대하여 실험한 결과를 보겠습니다.
4.1 Comparing with SSL frameworks on ImageNet
같은 architecture를 사용했을때와 다른 architecture를 사용했을때의 결과를 보겠습니다.
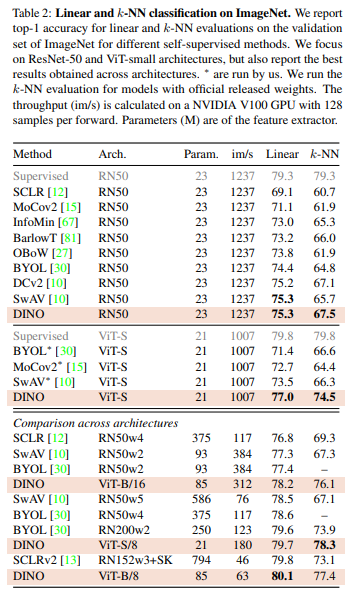
Comparing with the same architecture
Table 2를 보면 DINO를 다른 SSL method와 비교한 것을 볼 수 있습니다. 이전에 언급했던 SimCLR, MoCo, BYOL, SwAV등을 볼 수 있죠. 그리고 이에 대한 architecture는 ResNet-50 or ViT-S으로 고정했습니다. 이 두 모델은 Param, throughput, supervised accuracy가 비슷하기에 대조군으로 두었습니다.
DINO는 RN50와 함께 사용했을때에 SOTA와 동등한 정확도를 보여줍니다. 그리고 architecture를 ViT-S로 바꾸었을때 DINO가 BYOL, MoCov2, SwAV보다 Linear classification에 대해서는 +3.5%, k-NN evaluation에 대해서는 +7.9%를 달성했습니다. 더 놀라운 점은 simple k-NN classifier가 linear classifier가 비슷한 성능(74.5% versus 77.0%)을 찍었다는 겁니다. knn classifier는 추가적인 학습을 필요로 하지 않는다는 점에서 주목할 만한 feature입니다. 이는 DINO가 ViT와 결합되었을때에만 나타나는 현상이라는 점이 주목할 만합니다.
Comparing across architectures
Table 2아래를 보면 아키텍처마다 best accuracy를 지닌 것들을 나열해놓았습니다. large ViT와 DINO가 결합되었을 때 성능이 향상되었고, patch 크기("/8" variants)일 때 성능이 더 큰 폭으로 증가했습니다. 이러한 patch의 variants는 추가적인 파라미터를 필요로 하지 않지만 running time의 증가와 memory usage를 증가시킨다는 한계점이 존재합니다. 그래도 ViT with 8x8 patch가 DINO와 결합되었을때에 10x 적은 파라미터와, 1.4x 빠른 run time과 함께 80.1% top-1 accuracy를 달성했으며 k-NN classifier에서 77.4% 를 달성했다고 합니다.
4.2 Properties of ViT trained with SSL
여기에서는 DINO의 feature를 nearest neighbor serach의 관점에서 downstream task에서 object location과 transferability를 가지고 있는지에 대해서 실험합니다.
4.2.1 Nearest neighbor retrieval with DINO ViT
DINO의 feature를 nearest neighbor retrieval에 대해 적용해봅니다. 그리고 이를 landmark retrieval과 copy detection task에 대해 확장합니다.
Image Retrieval
* Nearest neighbor retrieval이란 주어진 데이터 포인트에 가장 유사한 데이터 포인트를 데이터셋에서 찾아내는 과정을 말합니다. 이는 아래와 같은 과정으로 진행됩니다.
- 유사도 측정: 주어진 데이터 포인트(query)와 데이터셋 내 다른 모든 데이터 포인트 사이의 similarity를 측정합니다. 여기서 similarity는 유클리디안 거리, 코사인 유사도 등이 될 수 있습니다.
- 가장 가까운 이웃 찾기: query와 가장 유사성이 높은 데이터 포인트를 데이터셋에서 찾습니다.,
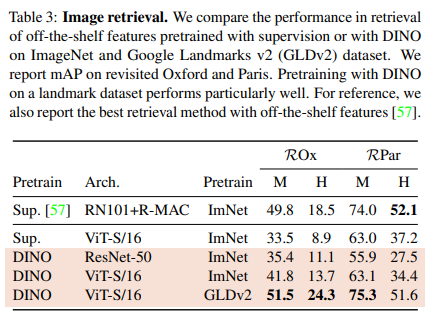
Oxford and Paris image retrieval datasets에 대해 실험했습니다. 이는 query/database pair에 대해 구분 난이도에 대해 Medium(M), Hard(H) split으로 나누어져있습니다. Table 3를 보면 ImageNet이나 GLDv2에서 supervision이나 DINO로 pretrained된 모델에서 뽑아낸 off-the-shelf features에 대해 성능을 비교했다고 합니다. 그리고 revisited Oxford and Paris에 대해 mAP를 측정했습니다.
해당 결과를보면, DINO feature가 ImageNet에서 supervised로 학습된 것보다 성능이 좋았다고 합니다. 그리고 DINO를 GLDv2(1.2M)에 대해 pretrain시킨 것이 것이 이전에 만들어진 방법론들보다 더 성능이 좋은것을 볼 수 있습니다.
Copy detection
* Copy detection이란 주로 이미지나 비디오와 같은 디지털 미디어에서 원본 콘텐츠의 복사본 또는 변형된 버전을 식별하는 과정을 말합니다.
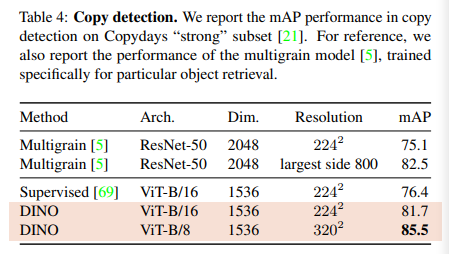
여기서는 INRIA Copydays dataset의 "strong" subset에 대해 mAP을 측정한 결과입니다. 해당 task에서 YFCC 100M dataset에 대해 10k distractor image를 기존의 셋에 추가해줍니다. 그리고 pretrained network에서 cosine similarity를 통해 copy detection을 수행합니다. 여기서 [CLS] token을 output에 연결하고 GeM pooled를 통해 1536d feature를 만듭니다. 그리고 이 feature는 whitening을 통해 정규화됩니다. 이때 whitening 변환은 distractor image를 제외한 YFCC100M 데이터셋의 추가적인 20k개의 무작위 이미지에서 학습됩니다. 이렇게 DINO로 훈련된 ViT는 Copy detection task에서 매우 경쟁력 있는 성능을 보여줍니다.
4.2.2 Discovering the semantic layout of scenes
해당 포스팅의 맨 위에있는 Figure1에서 self-attention map이 image에 대한 많은 segmentation정보를 가지고 있는 것을 볼 수 있었습니다. 여기서는 attention map에서 추출된 masks의 quality를 standard benchmark를 통해 측정해보겠습니다.
Video instance segmentation
여기서는 DAVIS-2017 video instance segmentation benchmark에 대해 output patch tokens를 통해 평가했습니다.

비디오나 이미지 시퀀스에서, 한 프레임과 바로 다음 프레임 간의 유사성을 평가합니다. 이는 각 프레임을 대표하는 feature를 비교함으로써 수행됩니다. 이를 통해 인접한 프레임 중에서 가장 유사한 프레임을 찾습니다. 여기서 중요한 점은 이 과정에서 추가적인 모델 학습이나 기존 가중치의 finetuning을 수행하지 않는다는 점입니다. 이 방법을 통해 각 프레임이 속하는 장면(scene)을 판단하고, 연속되는 프레임들을 같은 장면으로 그룹화하거나 다른 장면으로 구분할 수 있습니다.
Table 5를 보면 해당 모델이 이러한 dense task를 위해 설계된 것이 아님에도 매우 좋은 성능을 내는 것을 볼 수 있습니다.
Probing the self-attention map

Figure 3에서 우리는 ViT의 각기 다른 multi head가 각기 다른 semantic region을 가질 수 있음을 보여주고 있습니다. 이미지가 풀숲에 가려지거나 작더라도 잘 캐치해 내는 것을 볼 수 있습니다.

Figure 4에서 Supervised ViT는 뭉쳐있는 객체에 대해 질적으로나 양적으로 엉성하게 캐치하는 것을 볼 수 있습니다. 해당 실험에서는 self-attention map의 60%만을 살릴 수 있게 threshold을 걸고 ground truth와의 segmentation mask의 Jaccard similarity를 쟀습니다. 사실 self-attention map은 segmentation mask를 위한 작업이 아님에도 supervised와 DINO model간의 확연한 차이를 볼 수 있습니다. -> convnet도 가능하지만 이렇게 mask를 뽑아내는 과정이 고됨
4.2.3 Transfer learning on downstream task
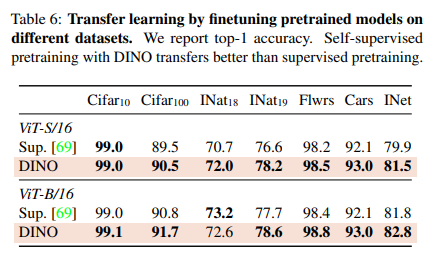
여기서 DINO에 대해 pretrained된 feature를 각기 다른 downstream task에 적용시켜본 결과입니다. 같은 architecture에서 supervision on ImageNet의 경우와 비교했습니다. 결과는 뭐 ViT의 SSL을 통해 finetuning한 것이 supervision보다 보다 좋은 성능을 내더라는 것입니다. 이 경우는 ViT나 convnet나 비슷비슷한 결과를 냈다고 합니다. 최종적으로 SSL은 ImageNet에 대해 (+1-2%)의 성능향상을 이끌어냈습니다.
5. Ablation Sutdy on DINO
이 부분은 제가 가장 재미있게 보았던 부분입니다. 여기서는 DINO에 있어서 ViT의 Ablation study를 진행하고 자세한 부분은 Appendix를 참고하면 됩니다.
5.1 Importance of the Different Components
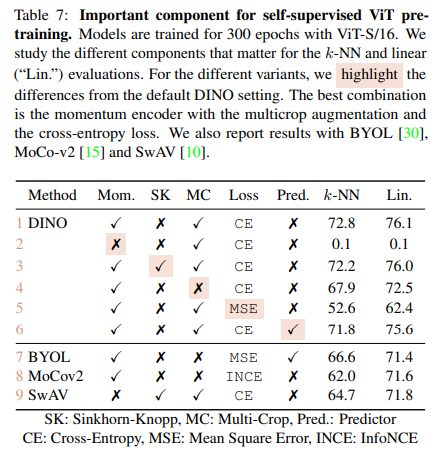
Table 7에서 DINO에 있어서 거의 모든 경우의 ablation study를 진행한 결과입니다. momentum encoder를 없애니까 수렴을 안하는 것을 볼 수 있습니다. 그리고 SK(Sinkhorn-Knopp)도 collapse를 피하기 위한 기법인데, 이는 DINO에서는 오히려 성능을 약간 떨어트렸다고 합니다. 이 외에도 multi-crop, cross-entropy loss가 DINO에서 중요한 역할을 한다는 것을 볼 수 있습니다. 추가로 predictor는 DINO에서 성능을 약간 떨어트리지만 BYOL에서는 collapse를 피하기 위해서는 필요한 component라는 것을 표를 보면 파악할 수 있습니다.
Importance of the patch size
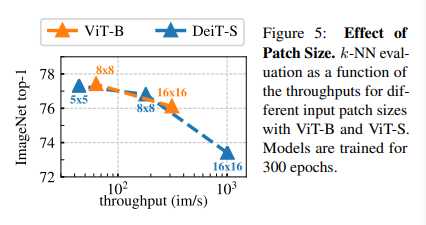
Figure 5를 보면 k-NN의 top-1 accuracy를 ViT와 DeiT의 patch size에 대해 그려놓은 것을 볼 수 있습니다. 많이 언급했지만, patch size를 줄이면 performance는 증가했지만 throughput의 비용이 그만큼 증가한다는걸 볼 수 있습니다.
5.2 Impact of the choice of Teacher Network
여기서 DINO안에서 teacher network의 역할을 알기 위해 ablation해봅니다. 그리고 k-NN protocol을 이용해 비교합니다.
Building different teachers from the student
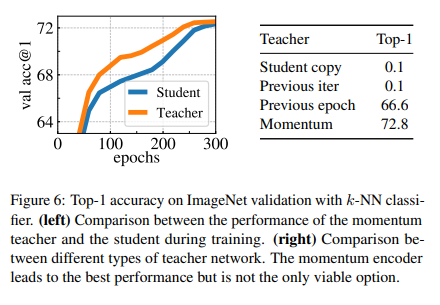
(1) teacher network의 previous epoch결과를 통해 student를 update하는 방법, (2) student network의 previous iteration결과를 통해 teacher를 update이 있는데, 이 두개는 둘다 수렴이 되지 않음을 볼 수 있습니다. 신기하게도 (3) teacher network를 이전 epoch의 결과로 취하면 collapse하지 않고 MoCo-v2, BYOL과 비슷한 성능을 냈다고 합니다.
당연히 *(4) momentum encoder를 사용해서 teacher network를 update하는 방법이 이전 방법들의 성능을 압도했다고 합니다. 이러한 방법이 시사하는 점은, teacher를 update하는 다른 방법이 있을 수 있다는 것을 시사합니다.
Analyzing the training dynamic
왜 momentum encoder방식이 더 좋은 성능을 내는지에 대해 살펴보겠습니다. Figure 6의 왼쪽 그림을 보면 Teacher가 Student의 성능보다 항상 좋은 것을 볼 수 있습니다. 이러한 현상은 이전의 momentum encoder방식과 위의 (3) 방식에서는 관측할 수 없는 현상이였다고 합니다.
저자들은 DINO의 momentum teacher의 이런 현상을 Polyak-Ruppert averaging의 현상중 하나라고 주장했습니다. 이는 모델의 파라미터르 학습 중에 평균시키는 방법인데, model의 앙상블을 시뮬레이션할때 종종 사용되곤 합니다. DINO도 Polyak-Ruppert averaging의 일종으로서 training시에 항상 여러 모델을 앙상블하여 좋은 성능을 내는 모델을 만드는 것이라고 이해해도 좋습니다. 이제 앙상블된 teacher model은 student를 가이드하고 성능을 쫙쫙 올려나가는 것이죠.
5.3 Avoiding collapse
collapse에는 2가지 형태가 있는데, model의 output이 모든 차원에 대해 uniform한 경우와 하나의 차원에 dominant되는 경우가 존재할 수 있습니다. 아래 그림과 같이 말이죠.
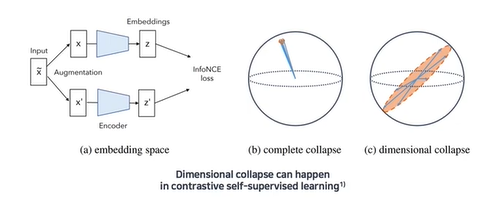
centering은 한 차원으로 dominant되는 것을 막지만 uniform output을 만들게 하고, sharpening은 그 반대의 효과를 장려해서 서로 상호 보완적인 효과를 낸다고 했었습니다. 진짜 맞는지 알아보기 위해서 우리는 loss식인 cross-entropy식을 entropy오 Kullback-Leibler divergence(KL)로 쪼개볼 수 있습니다. -> 수식적으로 이항해서 증명할 수 있음
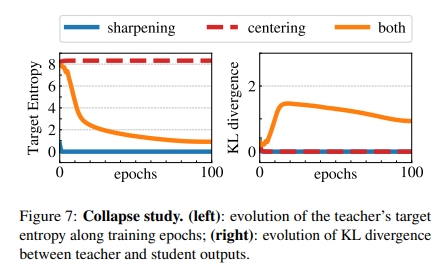
KL이 0로 간다는건, constant output으로서 collapse를 의미하는 것이라고 볼 수 있습니다. Figure 7에서 entropy와 KL의 수치를 training시에 sharpening, centering둘 중 하나를 적용하거나 둘다 사용하는 경우를 가시화했습니다. 만약 한개가 빠진 경우 KL은 0으로 수렴하는데, 이는 서로 상호보완 관계며 collapse를 방지해 준다는 것을 자연스레 알 수 있습니다. 그리고 entropy h는 no sharpening상황에서는 −log(1/K)로 수렴하고 no centering상황에서는 0으로 수렴합니다. 이는 위에서 말한대로 centering과 sharpening이 서로 다른 종류의 collapse를 방지하게 하는 효과를 갖는다는 것을 증명합니다.
6. Concolusion
해당 연구에서 주목할만한 점은 (1) k-NN에 적용할 수 있는 feature의 퀄리티 (2) attention mask의 scene layout를 들 수 있습니다. (1)은 image retrieval분야에서 유망하며, (2)는 weakly supervised image segmentation분야에 잠재력이 충분합니다.
그리고 뭐니뭐니해도 (3) Self-Supervised learning이 ViT기반의 모델의 발전의 핵심요소가 될 수 있다. 라는 점입니다. BERT, GPT가 그랬듯이 image task에서도 DINO가 그 start를 끊은 것이라고 볼 수 있겠습니다. 우리는 DINO로 pre-trained된 모델을 통해 image의 feature의 효율을 극한으로 뽑아먹을 수 있을 것을 기대합니다.
그 다음 포스팅으로는 DDPM에 대해 살펴볼 생각이며, 그 후에는 cycle gan, style gan등 gan의 주요 variant를 살펴볼 것입니다. 그리고 DALLE-2와 같은 멀티 모달 모델을 NLP task를 공부하면서 차근차근 정복해 나가보겠습니다.
'AIML > 딥러닝 최신 트렌드 알고리즘' 카테고리의 다른 글
- Abstract
- 1. Introduction
- 2. Related work
- 3. Approach
- 3.1 SSL with Knowledge Distillation
- 3.2 Implementation and evaluation protocols
- 4. Main Results
- 4.1 Comparing with SSL frameworks on ImageNet
- 4.2 Properties of ViT trained with SSL
- 4.2.1 Nearest neighbor retrieval with DINO ViT
- 4.2.2 Discovering the semantic layout of scenes
- 4.2.3 Transfer learning on downstream task
- 5. Ablation Sutdy on DINO
- 5.1 Importance of the Different Components
- 5.2 Impact of the choice of Teacher Network
- 5.3 Avoiding collapse
- 6. Concolusion