![[ 딥러닝 최신 알고리즘 - PRMI Lab] - Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdM58gZ%2FbtsDrk7m9Ft%2FbQGy60jKAV7f8atRGva0DK%2Fimg.png)
ViT, DeiT순으로 Vision Transformer와 관련된 내용을 쭉 살펴보았었습니다. 이들의 고질적인 한계점은, (1) high resolution image가 들어오게 되면, sequence의 길이가 quadratic하게 증가해서, 이에 계산 복잡도가 기하급수적으로 늘어난다는 것이었습니다. (2) Hierarachical Representation(=계층적인 표현)을 학습하지 못합니다. 기존의 CNN기반 모델이 가지는 이점이기도 합니다. (3) Translation Invariant(=이동 불변성)이 부족합니다. General Purpose모델에 중요한 요소중에 하나입니다.
그래서 이러한 문제점에 대해 해결책을 제시해서 General Purpose의 Backbone Model로서의 가능성을 제시한 Ze Liu et.al의 Swin Transformer에 대해 리뷰해보는 시간을 가져보도록 하겠습니다. 이는 ICLR 2021 best paper상을 받았으며, Vision분야의 SOTA를 찍었던 모델이기에 리뷰할 충분한 가치가 있습니다.
그리고 모델을 이해하는데 많은 도움이 된 고려대 DSBA연구실의 세미나 링크를 첨부합니다.
Abstract
논문에서는 Swin Transformer를 제시합니다. Swin Transformer는 NLP보다는 Image분야에 적합하게 설계됩니다. 모델에서 소개하는 가장 핵심적인 내용은 아래와 같습니다.
- Shifted Windows
- self-attention과정에서의 계산 효율성을 보장합니다.
- cross-window connection을 제공합니다.
- hierarchical architecture로서, 모델에 scale flexibility를 제공합니다.
이를 통해 기존의 SOTA모델의 성능을 압도했으며, vision backbones으로서의 가능성을 제시합니다. Swin-Transformer를 다 읽어보니, 전체적인 구조는 간단한데 그 안의 구현 방법이 전체적으로 추상적입니다. 코드를 통해 논문을 보며 이해 안가는 부분을 이해했습니다. 그리고 코드를 잘 분석한 블로그가 있어 링크 남깁니다.
1. Introduction

해당 그림의 (a)는 Swin Transformer에서 계층적인 feature map을 뽑아내기 위한 Patch Merging층의 과정을 가시화한 것입니다. 빨간 테두리가 Local window이며, 각각의 회색 테두리는 Patch를 의미합니다. Multi head Self-Attention층에서 Local window개별적으로, Self Attention이 진행되는데 이는 Linear Complexity로 계산 가능합니다. (이는 CNN의 FPN, U-Net에서 사용하는 구조와 같습니다)
(b)는 ViT/DeiT에서 사용되던 하나의 single low resolution의 feature map을 뽑아내는 방법을 가시화한 것입니다. 이는 큰 Patch마다 Globaly하게 Self Attention이 적용되고, Quadratic Complexity로 계산 됩니다.
Difference between NLP with Vision
NLP와 Vision의 차이점은 (1) scale에 있습니다. Vision은 pixel하나하나에 대해 NLP에서의 token처럼 처리해주어야 하는데, 이러한 고해상도의 Image를 Transformer block에 투입하면 계산이 Intractable한 경우가 나올 수 있습니다. 이를 극복하기 위해, 위와같은 계층적 구조를 활용한 general-purpose Transformer Backbone을 제시하겠다 합니다.
Shifted window
Swin Transformer에서의 핵심은 window partiton간의 shift를 하는 consecutive self-attention 계층입니다.
위와같이 연속된 레이어에서 shifted window는 이전 레이어에서 인접한 윈도우간의 bridge를 놓아줍니다(방법은 뒤에서 자세히 설명합니다). 이는 Table4에서 볼 수 있다싶이, w/o shifting (기존의 sliding window), shifted windows방식을 비교했을때에, 'Classification, Instance Segmentation, Semantic Segmentation'방식 모두에서 높은 metric수치가 나왔음을 알 수 있습니다.
또한, shifted window방식은, 모든 query patch가 key set을 공유하기 때문에, window마다 다른 key set을 가지는 sliding window방식보다 latency가 더 적다고 합니다. 아래 Table5를 참고하시기 바랍니다.
Section2는 읽어보니, 기존의 CNN모델의 그 변형들인 EfficientNet, HRNet에 대해 소개하고 있습니다. 뿐만 아니라, CNN모델의 성능을 높이기 위해 depth-wise conv, deformable conv,,..등이 연구되었음을 언급하고 있습니다.
기존의, Self-attention기반의 아키텍처의 비효율성을 언급하고 해당 기술이 CNN을 보완하기 위해 어떻게 사용되고 발전되어왔는지에 대해 말하고 있습니다. 또한, ViT, DeiT에 대해 언급하고 이들에 대한 단점에 대해 서술하고 있습니다. 바로 Swin Transformer의 방법에 대해 구체적으로 봅시다.
3. Method
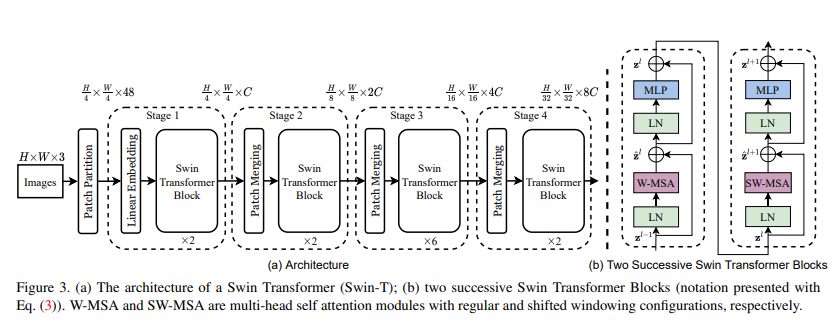
구조가 그렇게 복잡하지는 않아보입니다. 눈짐작으로 보면, ()의 image가 들어오고, Patch Partition층을 통해 패치로 나누어서 ()이 됩나봅니다. 그리고 Linear embedding층을 ViT에서 했던것처럼 통과시키고, Swin Transformer block을 통과시킵니다. 이와같은 Stage를 Linear Embedding이 Patch Merging으로만 바뀐것을 반복하면 끝입니다.
하지만 자세히보면, 여기에 기존의 Vision Transformer방식과 다르게 Position Embedding이 없는 것을 볼 수 있습니다. 이는 나중에 Relative Position bias방법에 대해 다룰때 자세히 보겠습니다. 이제 구체적인 방법에 대해 알아보겠습니다.
3.1 Overall Architecture
Figure3에서는 이미지를 나누는 Patch의 크기를 4x4로 설정했습니다. 그래서 feature dimension의 크기가 4x4x3=48이 되는 것입니다. 그리고 Linear Embedding층에서 Swin Transformer Block의 input으로 넣기 위해 임의의 차원으로 사영시킵니다. 그 다음의 Swin Transformer Block은 input의 크기를 유지하기 때문에, 크기에 영향을 주지 않습니다. Stage1이 끝났습니다.
Stage2의 시작부분에는 hierarchical representation을 만들어내기 위해, token의 크기를 () -> ()로 인접한 2x2개의 패치를 Merge시켜버립니다. 이로인해, 네트워크가 깊어지면 token의 크기는 줄어들고, feature dimension은 커지게 되는겁니다. Stage3, Stage4,.. 를 이처럼 반복합니다.
실제 코드를 통해 맞는지 간단히 검증해보겠습니다. 디테일한 부분은 생략하겠습니다.
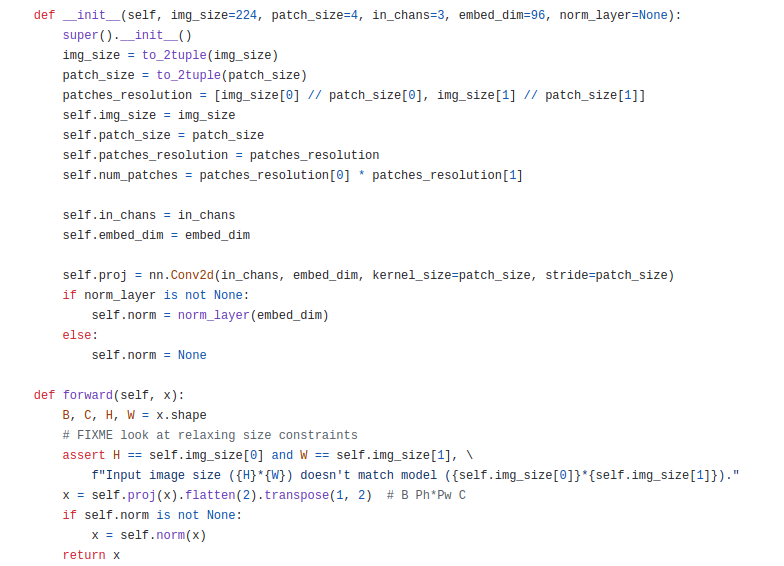
input image의 기본은 (B, 3, 224, 224)입니다. conv2d로 구현된 proj(=Linear Embedding)층을 통과시키고 flatten(2)를 해주게 되면 (B, 96, 56x56)이 됩니다. 또 transpose(1, 2)를 통해 (B, 56x56, 96)으로 만들어줍니다.
Swin Transformer block
Figure3의 (b)부분입니다. Swin Transformer block은 기존의 MSA를 shifted windows기반의 block으로 대체합니다. 이는 Section 3.2에서 더 자세히 설명합니다. 다른 부분은 ViT와 동일합니다. 2-layer MLP(with GELU)와 LayerNorm(LN), residual connection이 따라옵니다.
3.2 Shifted Window based Self-Attention
해당 부분은 연속된 Transformer Block으로 구성되는데 각각의 Block에는 W-MSA, SW-MSA로 구성됩니다. 이들은 linear complexity로 local window간의 self-attention연산을 수행할 수 있습니다. 또한, 이들때문에 high-resolution 이미지에 대해서도 처리할 수 있게됩니다. 이제 W-MSA, SW-MSA가 뭔지, 어떻게 배치와 함께 계산되는지 등을 살펴보겠습니다.
Self-attention in non-overlapped windows
각각의 local window안에서 self-attention이 진행됩니다. 그리고 각각의 window는 개의 Patch를 가지고 있습니다. 이 상황에서 개의 patch에 대한 기존의 MSA와 W-MSA에 대한 시간복잡도는 아래와 같습니다(Appendix에 설명 포함).
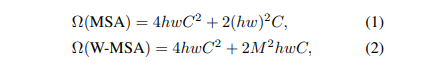
MSA는 에 대해 qudratic하게 변합니다. W-MSA는 모델에서 고정된 상수인 에 대해 qudratic하지만, 에 대해서는 linear한 시간 복잡도를 가집니다. 이러한 이유에서, Swin Transformer가 scalable한다는 것이고, 엄청난 장점입니다.
Shifted window partitioning
local window로 잘 나누었습니다. 그런데, window가 다른데 인접한 patch간의 관계는 학습할 수 없는걸까요?? 이를 위해 shifted window partitioning approach를 제안합니다. 이는 Swin Transformer block에서 consecutive한 window간에 shift를 해주는 것을 말합니다.
2x2 window, 4x4()인 상황을 가정합니다. 그럼 block에서 () pixel만큼 shift해서 기존에 쪼개진 window를 대체합니다. 이를 실제로 효율적으로 배치와 계산되는지는 바로 다음에 알아봅니다. 이러한 접근방식은, vision의 다양한 분야에서 좋은 성능을 냅니다(위의 Table4 참고)
Efficient batch computation
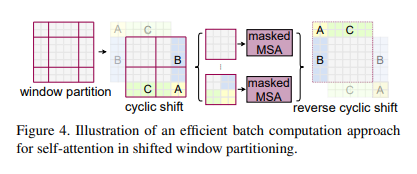
위와같은 partitioning방법을 사용하면 window의 개수가 증가합니다. 이에 대한 navie solution은, 보다 작은 window에 padding을 해주는 것입니다. 하지만 이렇게하면 Figure4만 봐도 2x2 -> 3x3이 되어 계산이 2.25배 많아집니다.
그래서 저자들은 보다 효율적인 cyclic-shifting방법을 방법을 제안합니다. DSBA세미나의 그림을 추가로 첨부합니다.
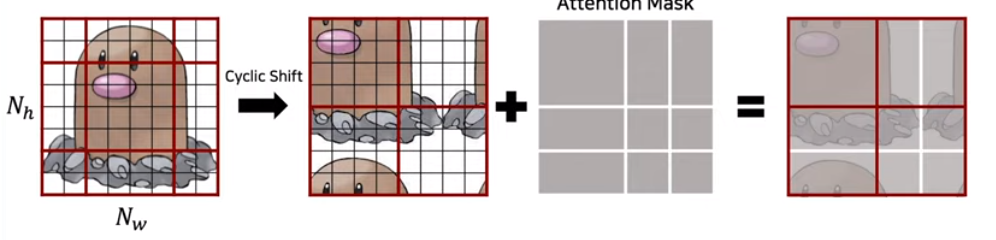
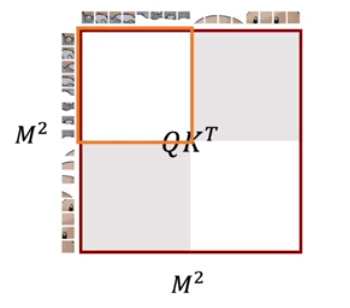
위 그림처럼 잘려나간 3개의 부분을 아래에 이어 붙힙니다. 그리고 이 4개의 local window간에 self-attention이 수행될 것인데 왼쪽 아래 디그다 그림을 보겠습니다. 여기서 가로로 사진을 나눠보면, 이 둘은 인접해 있는 patch들이 아닐겁니다. 그래서 이들간의 self-attention을 수행할때에도, 위쪽은 위쪽끼리만, 아래는 아래쪽끼리만 계산되기 위해 오른쪽과같은 크기의 Attention mask를 실제로 추가해줍니다. 최종적으로 계산된 결과를 reverse cyclic shift를 통해 원상복구 시킴으로써 SW-MSA가효율적으로 수행되는 것입니다.
Relative position bias
Swin Transformer는 ViT/DeiT와 다르게 Absolute Position Embedding을 사용하지 않고, Relative Position Embedding을 사용합니다.

의 window에서 relative position을 표현하기 위해서는 가 필요합니다. 그리고 저자들은 B를 뽑아내기 위해 을 정의합니다. 그럼 를 어떻게 만드는지 보겠습니다.
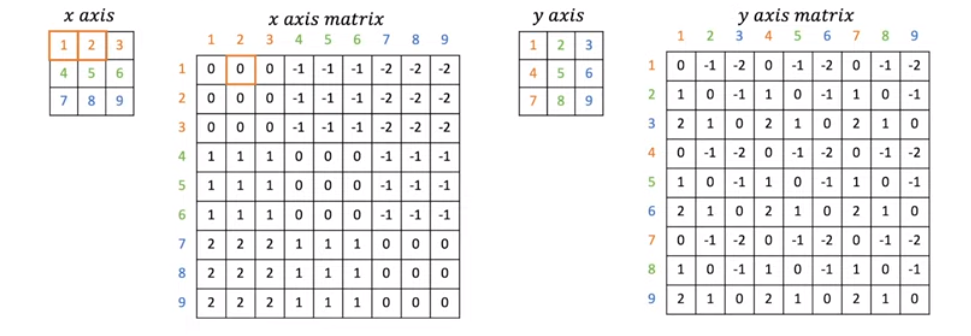
각 x, y축에 대한 relative한 정도를 x axis matrix, y axis matrix에 저장합니다. 이제 두개의 matrix를 index처럼 나타내주기 위해 합처주어야 하는데, 이에 대한 식은 아래와같습니다.
# Step 1 x_axis_matrix += window_size - 1 y_axis_matrix += window_size - 1 # Step 2 ''' Relative Posiion Bias를 x축 기준으로 한 것에 대한 이유는 사진이 좌우(=y)대칭인 경우가 많기 때문 -> 그래서 x축을 기준으로 주는 것이 더 효과적이라 판단 ''' x_axis_matrix *= 2 * window_size - 1 relative_position_M = x_axis_matrix + y_axis_matrix
그럼 아래와같은 0~24까지 25개의 값을가진 Relative Position Index Matrix가 만들어집니다. 이제 에서 각 0~25의 위치가 어디인지 파악해서 인덱싱해서 로 가져오면 끝입니다.
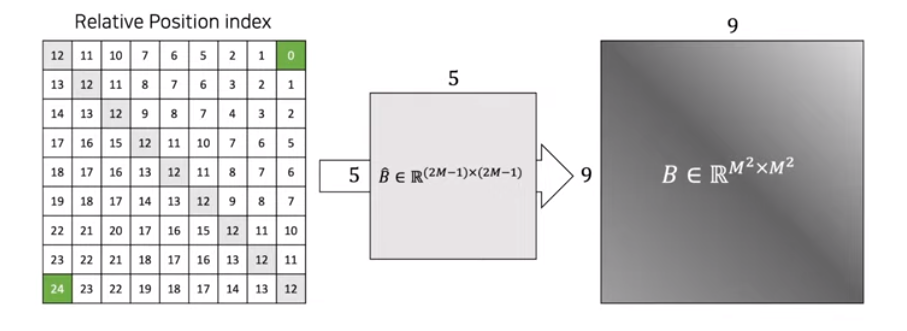
실제로 코드를 봐도, 를 학습가능한 파라미터로 크기의 행렬을 만들어 사용하는 것을 볼 수 있습니다.

이에대한 실험 결과도 Table4에 absolute, relative에 대한 ablation study로 진행되어 있으니 위 그림을 다시한번 보시기 바랍니다. 간단히 코드로 BasicLayer, SwinTransformerBlock를 보겠습니다.

BasicLayer는 depth개의 SwinTransformerBlock, downsample(=PatchMerge)으로 이루어져있습니다. SwinTransformerBlock의 shift_size는 홀수면 (window_size // 2) -> floor연산을 진행합니다.

forward의 input x는 (B, 56x56, 96)의 size입니다. .view를 통해 (B, 56, 56, 96)으로 변환됩니다. 해당 x는 SW-MSA(=shift_size != 0)이라면, window_partition이 적용됩니다.
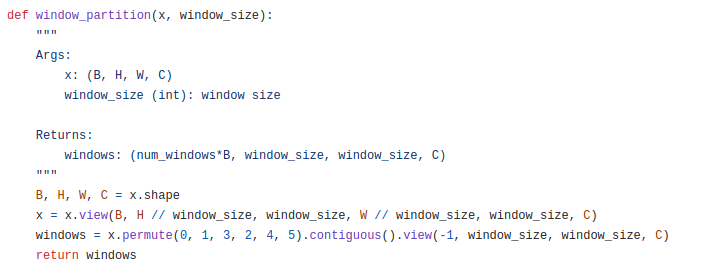
x를 (B, H // window_size, window_size, W // window_size, window_size, C)부분을 통해 x를 window로 나누어 새로운 차원을 추가해주게 됩니다. 이를 통해 생성된 x의 크기는 (B, 56//7, 7, 56//7, 7, 96)입니다. 그 후, permute -> view(-1, window_size, window_size, C)를 통해 (B x (56//7) x (56//7), 7, 7, 96) = (64B, 7, 7, 96)형태가 됩니다. 그림으로 그려보면 아래와 같은 겁니다.
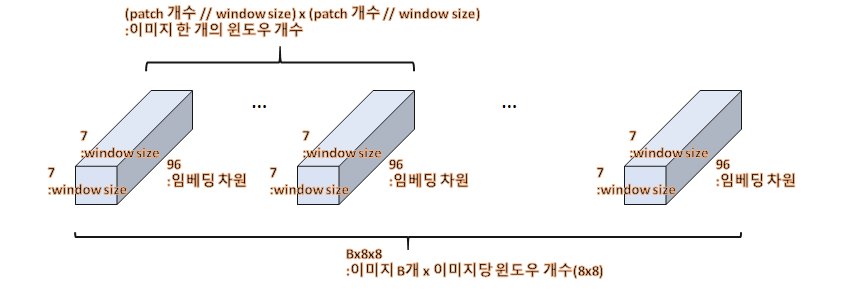
이렇게, 배치와 window를 하나의 차원으로 묶는건 논문에 나와있지 않았기 때문에 이러한 부분은 코드를 참고해야합니다. 사뭇 논문에서는 모든걸 다 알려주지는 않고 세부적인 구현이나 증명은 코드나 Appendix에 있다는걸 느꼈습니다.
partition 다음에는, view를 통해 (64B, 7x7, 96)으로바꾸고 이제 window 64에 대해 개별적으로 self-attention을 적용시켜줍니다. self.attn을 뜯어보면, WindowAttn(nn.Module)이 있을건데 이를 통해 수행됩니다.
그러고 나온, window_reverse함수를 통해 기존 shape (B, 56x56, 96)으로 복구가 됩니다.
또한, window_partion전에 cyclic shift를 통해 계산된다고 논문에서 소개했죠? 이는 torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))을 통해, (B, 56, 56, 96)차원에서 56, 56이 부분에 대해서 왼쪽으로 돌려버립니다. 마지막으로, 반대방향으로 다시 돌려버림으로써 reverse cyclic shift를 수행하고 종료합니다.
마지막으로 PatchMerging이 어떻게 구현되었나 살펴보겠습니다.

이 부분은, 제가 생각했던 patch merging과는 사뭇 달랐습니다. 저는 그냥 이웃 window를 묶어버리는건줄 알았는데, 한칸 씩 띄워서 이를 만들고 있었습니다. x0 = x[:, 0::2, 0::2, :]만 봐도 2의 배수로 indexing을 하고 있습니다. 그리고 생성된 (B, H/2, W/2, C)를 임베딩 차원(=-1)으로 concat해버립니다.
그후에는, 예상한대로 (B, (H/2) * (W/2), 4C) -- Linear 계층 --> (B, (H/2) * (W/2), 2C)으로 nn.Linear(4*dim, 2*dim)으로 사영시켜버립니다. 이를 그림자료로 표현한 것이 있어 가져왔습니다.
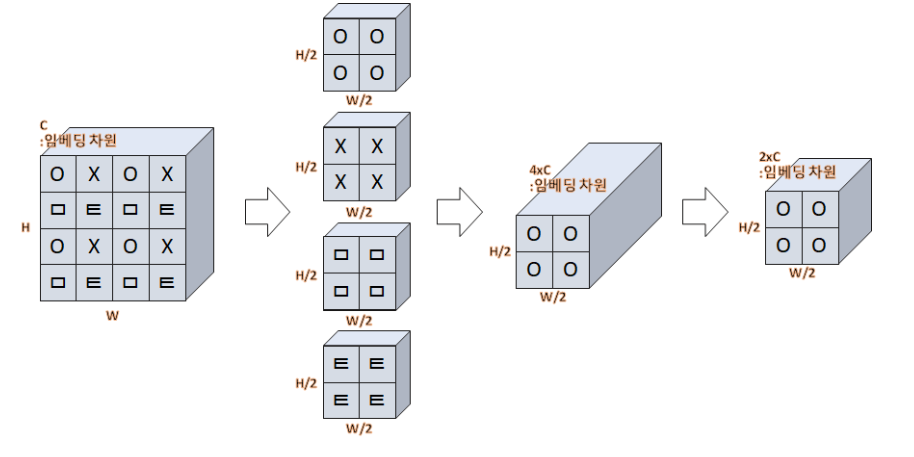
이 외에도, WindowAttention클래스에서 마스크를 계산하는법과 relative bias를 계산하는 방법도 심심하면 자세히 보시길 바랍니다. 또한, 논문에 나와있지 않은 기술들도 코드에 사용되어있습니다. 예를 들면 residual connection부분에서 timm라이브러리의 DropPath를 통해 확률적으로 connection이 이루어지게 했다던가, Stochastic Path를 사용했다던가. 논문에는 말 그대로 학샘 개념들만 정재해서 소개했다는걸 알 수 있었습니다.
3.3 Architecture Variants
Swin Transformer에서 window size인 이 기본입니다. 그리고 각각 head의 query dimension은 가 기본입니다. 또한, MLP에서 사용될 expansion ratio인 가 기본입니다.

Stage1에서 hidden layer의 channel개수인, layer number에 따라 Swin-T, S, B, L로 나누게 됩니다.
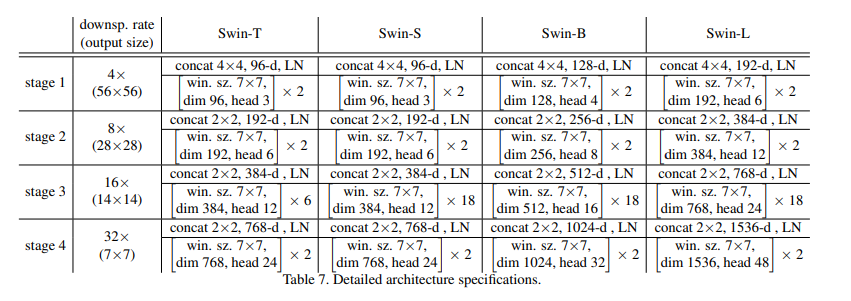
이는 Swin Transformer의 디테일한 레이어 구조입니다. 공식 코드와 비교하면서 보시기 바랍니다. 주의할 점은 224x224에서의 window size는 7이지만, 384x384일때에는 window size를 12로 설정하고 있습니다.
4. Experiment
Swin Transformer를 다양한 Vision Task에 대하여 Backbone으로서의 가능성을 평가해야합니다. 이에 Classification은 ImageNet 1K로 실험(ImageNet-22K를 Pre-train에 사용), Object Detection은 COCO 2017 사용, Semantic Segmentation은 ADE20K를 사용합니다.
4.1 Image Classification on ImageNet-1K
해당 실험에서는, 다양한 Augmentation과 Regularization이 필요하답니다. 하지만, ViT에서 중요했던 repeated augmentation과 EMA는 오히려 성능을 낮추어서 필요없었다 합니다. 또한, AdamW Optimizer를 기본적으로 사용합니다. 그 외에도 batch size를 1024, 300 epochs동안 cosine decay를 사용하며, 20 epochs동안 linear warm-up을 사용하며, 초기 lr은 0.001, weight decay는 0.05로 설정합니다. 당연히 ImageNet-22K를 사용한 Pre-train시에는 다른 하이퍼파라미터 값을 사용하게됩니다. 이는 논문을 참고하시기 바랍니다.
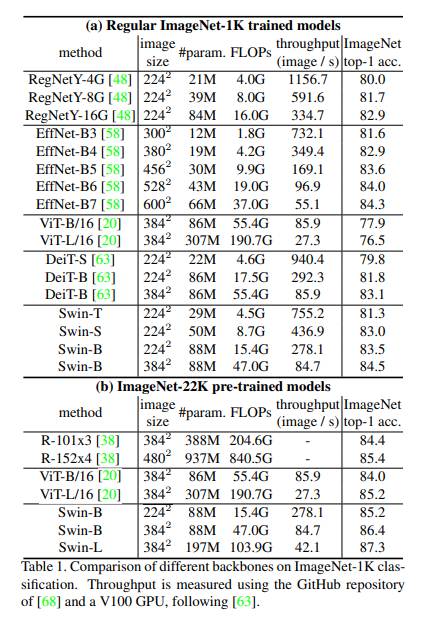
Table 1은 기존 ConvNet(=RegNetY, EffcientNet), ViT기반(=ViT, DeiT) sota backbone과 Swin Transformer와의 비교 결과를 보여줍니다. Swin Transformer는 대응되는 크기의 DeiT와 비교했을때, DeiT-S(79.8%) <--> Swin-T(81.3%)와 같이 1.5% 능가하는 결과를 보여줍니다. ConvNet과 비교했을때에는, Swin Transformer가 더 좋은 speed-accuracy trade-off를 가져갑니다. 뿐만이니라, RegNetY, EfficientNet은 최적의 아키텍처를 search기반으로 찾아낸 구조기때문에, 잠재 발전 가능성이 적지만, Swin Transformer는 Pure Transformer기반이기 때문에 발전 가능성이 무궁무진하다고 볼 수 있습니다.
scratch부터 ImageNet 22K를 이용해 pre-train을 시켰을 경우에도 Swin Transformer가 다른것들을 능가합니다.
*참고!
제가 Vision Task의 트랜드를 확인할때 자주보는 papers with code에서 Image Classification benchmark를 찾아보았습니다.



예상외로, benchmark 결과는 ViT-L/16 > Swin-L > DeiT-B 384였습니다. 아마 Pre-train 데이터셋도 다를거고, 모델의 확장 가능성과 모델의 크기가 영향을 많이 끼친것 같습니다. 그 외에도 현재 ImageNet Classificaation SOTA는 NosiyVit-B입니다.
후에, Vision Task에서의 Transformer와 관련된 Survey를 리뷰해보려고 하는데, Swin Transoformer의 단점중에 하나가, Small dataset에서부터 scratch로 train 시키기 어렵다는 점입니다. 또한, Swin Transformer의 의의는 마지막에 정리하겠지만 General Backbone으로서의 활용 가치입니다. 뒤늦게 나온 모델이라고 benchmark점수가 무조건 좋을 것이라는 고정관념을 이번 계기로 알 수 있었고, 낮다면 해당 모델이 이전 모델과는 어떤점이 다르기에 주목받았는지에 대해 찾아볼 수 있는 견목을 가지게되었습니다.
4.2 Object Detection on COCO
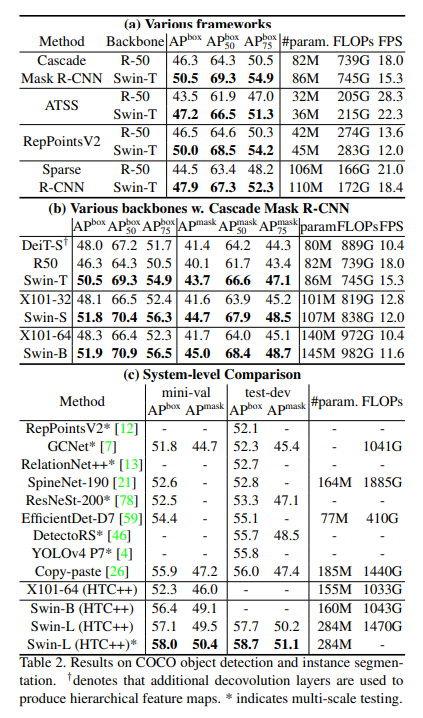
Object Detection에서 모델마다 같은 조건을 유지한체 ablation study를 해주기 위해서, multi-scale training, AdamW, weight decay, batch size을 통일시켜줍니다. 그리고 HTC, stronger multi-scale training, 6x schedule, soft-NMS, imageNet-22K pre-train등을 system-level comparision을 위해 동일하게 적용했다고 합니다. 추가로 DeiT와 비교할때는 DeiT가 계층구조의 feature map을 생산 못하므로, DeiT에 Deconvolution layer를 추가해주었다고 합니다.
Table 2 (a)에서는, 보통의 Object Detection프레임워크인 Cascade mask R-CNN, ATSS, RepPoint v2, Sparse RCNN등에 대에 Resnet-50 <--> Swin-T를 backbone으로 사용했을떄의 benchmark를 보여주고 있습니다. 결과는, Swin-T가 모든 AP부분에서 높은 수치를 보였습니다.
Table 2 (b)에서는, Cascade Mask R-CNN에서 CNN 기반 모델과 Swin Transformer를 비교한 결과입니다. Swin-B 는 모델 사이즈, FLOPs, latency가 비슷한 ResNeXt101-64x4d와 비교했을때, +3.6 box AP, +3.3 mask AP를 달성했습니다.
Table 3 (c)에서는, System-level 비교를 다양한 모델을 바탕으로 min-val, test-dev COCO 2017 dataset에 대해 진행되었습니다. ResNeXt101-64xd에 HTC++를 적용하니 52.3 box AP를 달성했고, 46.0 mask AP를 달성했습니다. 또한, 위에서와 비슷하게 Swin-B에 HTC++를 적용하니 ResNext101-64xd에 비해 +4.1 box AP, +3.1 mask AP를 달성했다고합니다.
추가로 Table 2 (b)에서 DeiT와 비교했을때 Swin-T가 더 빠른 추론 속도를 가지는 것은 DeiT가 Swin과는 다르게 input image size에 대해 qudratic 계산 복잡도를 가지기 때문이라고 합니다. 또한, Table 3 (c)에서 SOTA모델과 비교하는데, 이와 비교해서 Swin이 견줄만하거나 더 우월하다고 주장합니다.
4.3 Semantic Segmentation on ADE20K
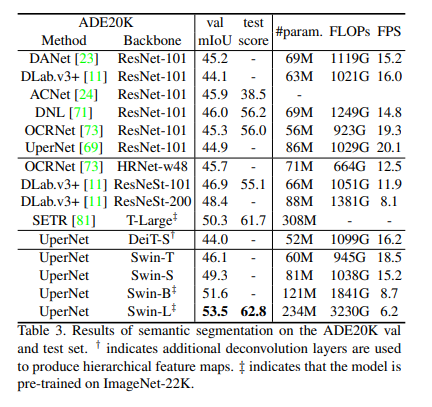
Table 3에서 Semantic Segmentation에 대한 method/backbone pair에 대한 mIoU와 기타 수치를 제시하고 있습니다. 결과에서 계산 코스트가 비슷한 UperNet, DeiT-S와 UperNet, Swin-S를 비교했을 때에 후자가 +5.3 mIoU가 나왔습니다. 또한, SOAT모델인 SETR, T-Large(308M)보다 UperNet, Swin-L(234M)이 더 적은 모델 사이즈임에도 불구하고 +3.2 mIoU가 나왔습니다.
4.4 Ablation Study
이제 Relative Positional Bias의 여부와 Shifted Window의 여부에 따른 Ablation Study를 간단히 보고가겠습니다.
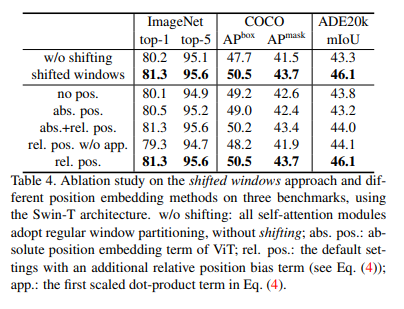
Shifted windows: Swin-T모델에서 shifted window를 사용하는 것이 w/o shifting(기존 shifting window 방식)보다 imageNet-1K에서 +1.1% top-1 accuracy를, COCO에서 +2.8 box AP/+2.2 mask AP를, ADE20K에서 +2.8 mIoU를 달성했습니다. 이는 shifted window가 이전 레이어간의 connection을(=window간의 관계를 학습)시키는 것이 Vision Task에 더 좋은 영향을 끼쳤음을 의미합니다.
Relative position bias: Swin-T모델에서 rel pos.가 no pos, abs pos와 비교했을때 ImageNet-1K에서 +1.2%/+0.8% top-1 accuracy를, COCO에서 +1.3/+1.5 box AP, +1.1/+1.3 mask AP를, ADE20K에서 +2.3/+2.9 mIoU의 성능개선을 이루어냈습니다. 또한, no pos, abs pos를 비교했을때에 abs pos가 image classification에서는 +0.4%좋지만, object detection, semantic segmentation쪽에서는 (-0.2 box/mask AP, -0.6 mIoU)만큼 떨어지며 좋지 않았습니다.
최근의 ViT/DeiT가 translation invariance를 image classification에서 사용하지 않습니다. 저자들은 여전히 translation invariance를 위한 inductive bias가 여전히 general-purpose vision modeling에는 꼭 필요하다고 역설합니다. 특히 dense prediction과 같은 detection, segmentation분야에서 말이죠.
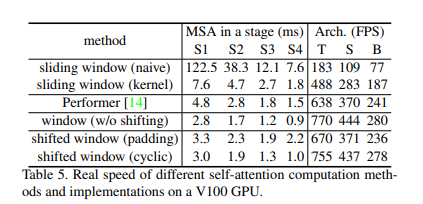
Different self-attention methods: Table 5에서는, 다양한 self-attention방식에 대한 FPS를 실험한 결과입니다. 이는 Section3 Method부분에서도 자세히 설명했었는데, 저자들의 cyclic shifted window방식이 naive한 padding 방식보다 하드웨어 효율적이여서 더 깊은 stage에서도 빠르다고 합니다.
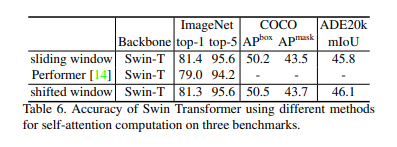
위와같이, 3개의 self-attention방식에 따른 Swin-T의 3개의 Task에 대한 정확도를 비교한 Table 6도 확인하시길 바랍니다. generalize 성능이 더 좋고, 위에서 봤듯이 더 빠른 shifted window방식을 저자들이 선택한 이유를 알 수 있을것입니다.
5. Conclusion
본 Swin Transformer는 Transformer인데, 계층 구조의 feature map을 통한 표현학습이 가능했습니다. 또한, linear computational 계산 복잡도로 self-attention을 개선시켰습니다. 이러한 개선으로 COCO, ADE20K에서 당시(2021년)에 SOAT를 찍은 기념비적인 논문입니다.
Swin Transformer의 핵심은 shifted window방식의 self-attention이 Vision에서 어떻게 효과적으로 적용되는지 확인한 것입니다. 이를 통해 shifted window의 NLP나 다른 활용 분야에 대해서도 생각해보고 적용해보아야 한다고 생각합니다.