![[딥러닝 최신 트렌드 알고리즘] - (Practice Session with Pytorch) Implement Feedforward Network](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FPDKk8%2FbtsltWCzxw0%2FmhzVwR7mF6O2KpwyALsKP1%2Fimg.png)
본 게시물에서는 실제로 제가 pytorch 공식 문서를 보고 이전에 강의 세션에서 공부했던 개념들로 신경망을 구축하고 학습하는 과정들을 정리해보겠습니다.
https://pytorch.org/vision/stable/datasets.html
Datasets — Torchvision 0.15 documentation
Shortcuts
pytorch.org
Built-in DATASETS

모든 pytorch의 데이터 셋들은 torch.utils.data.Dataset 에 포함되어 있습니다. 그리고 pytorch의 데이터 셋은 __getitem__과 __len__메소드가 구현되어 있습니다. 그리고 torch.utils.data.DataLoader는 데이터를 배치로 불러오는 역할을 하는데, 이 클래스는 멀티프로세싱을 활용하여 데이터를 병렬로 불러올 수 있습니다.
여기서 저희가 쓸 dataset은 FASHIONMNIST데이터 입니다.
여기에서 인자들을 볼 수 있습니다. 먼저 transform: Optional[Callable] = None이라고 되어 있습니다. transform은 A function/transform that takes in a PIL image and returns a transformed version 이라고 되어 있는데, PIL은 강력한 이미지 처리와 그래픽 기능을 제공하는 이미지프로세싱 라이브러리의 한 종류라고 합니다. 여기에는 픽셀 단위의 조작, 마스킹 및 투명도 제어, 흐림, 윤곽 보정 다듬어 윤곽 검충 등의 이미지 필터,,,.. 등의 기능이 있습니다.
우리는 Optional[Callable]( 이는 null과 Callable의 합타입 ) 을 여기다가 집어 넣을 것인데, 우선 PyTorch에서 텐서(Tensor)는 기본적으로 다차원 배열을 나타내는 데 사용되는 데이터 구조입니다. 이는 다양한 차원과 크기를 가질 수 있으며, 단일 값(스칼라), 1D 배열(벡터), 2D 배열(행렬), 또는 그 이상의 차원을 가진 배열 등을 표현할 수 있습니다. 이는 Numpy의 ndarray와 매우 유사하며, 텐서 연산은 CPU또는 GPU에서 수행될 수 있습니다. 이는 GPU연산을 통해 병렬 연산이 가능해서 대규모 텐서 계산을 효율적으로 할 수 있습니다.


우리는 ToTensor()와 normalize(tensor, mean, std[,inplace])를 사용해서 일단 FASHIONMNIST datasets를 변형해서 우리가 지정한 경로에 다운로드까지 시켜보겠습니다. 그리고 Compose를 통해 이 transform을 묶을 수 있습니다. 아참 그리고 데이터를 정규화도 할 거기 때문에 Noramlize를 해서 mean=0.5, std=0.5 가우시안 분포를 따르도록 정규화하겠습니다.

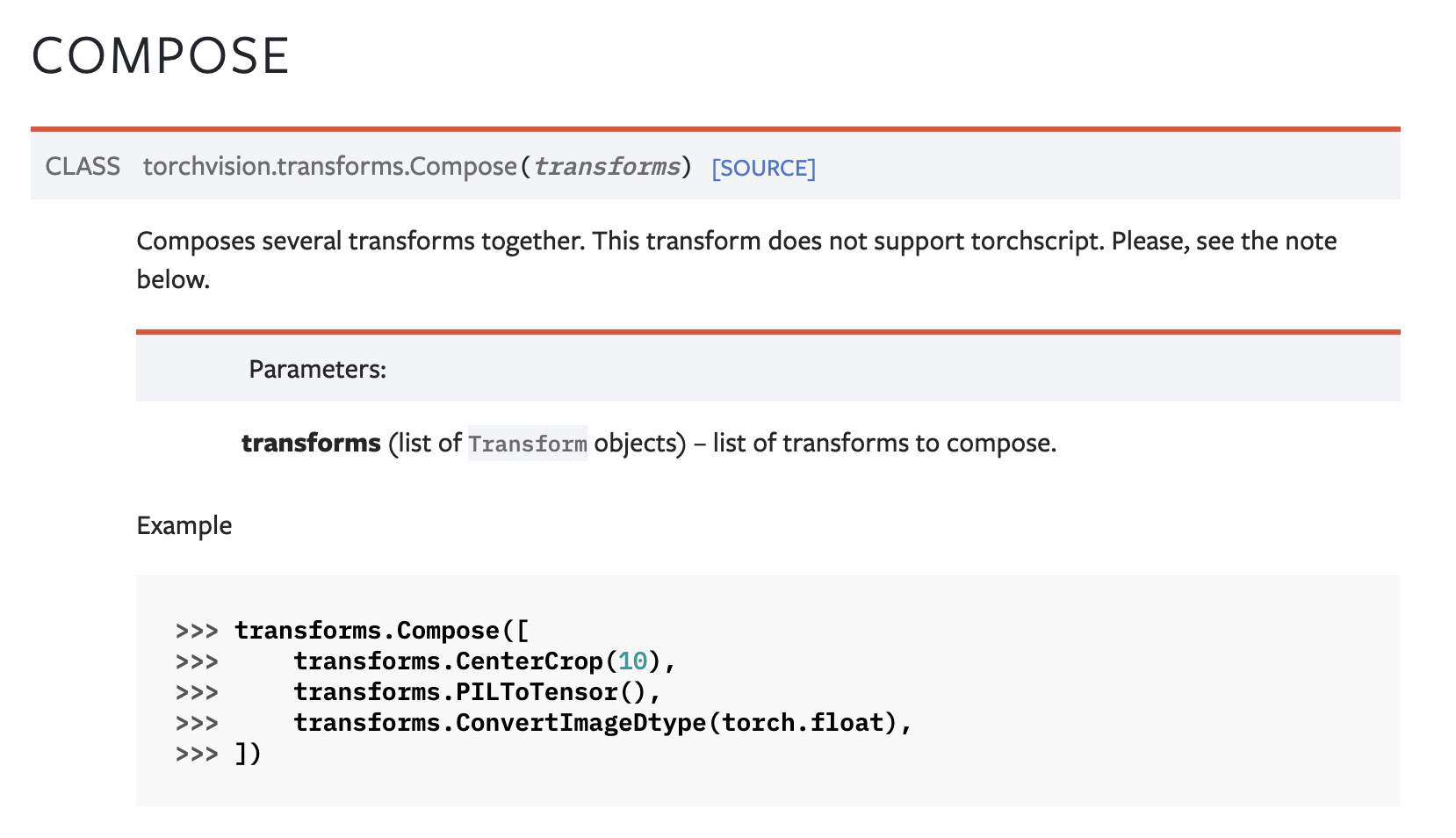
compose의 인자로는 transforms즉 list of Transform objects가 들어간다고 되어있습니다.
data_root = os.path.join(os.getcwd(), "data") # 전처리 부분 (preprocessing) & 데이터 셋 정의 transform = transforms.Compose( [ transforms.ToTensor(), transforms.Normalize([0.5], [0.5]), # mean, # std ] ) fashion_mnist_dataset = FashionMNIST(data_root, download=True, train=True, transform=transform)
이렇게 코드를 짜겠습니다.
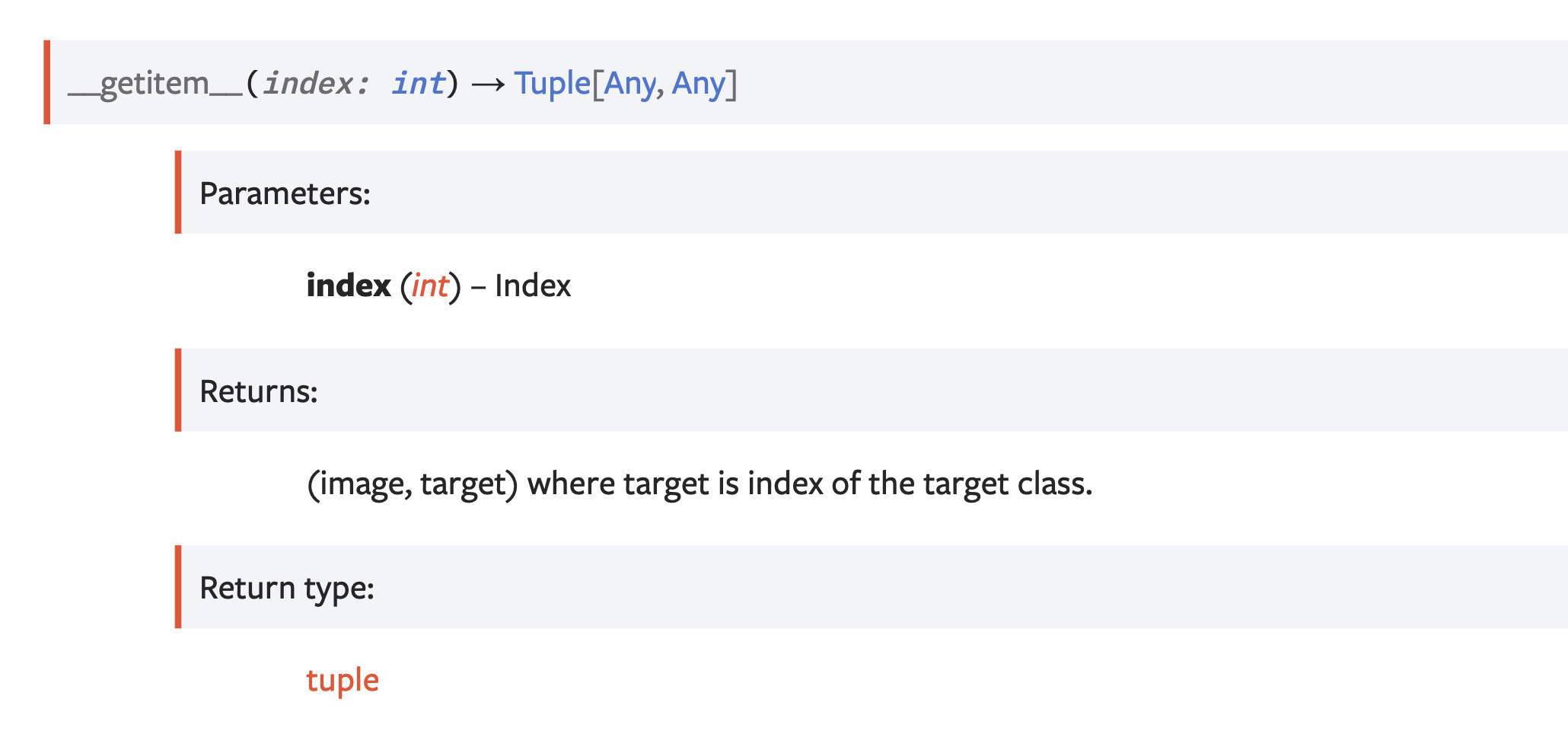
그리고 __getitem__을 구현해 놓았기 때문에, [0], [1]로 image, target이 잘 접근되는지도 확인해보도록 하겠습니다.
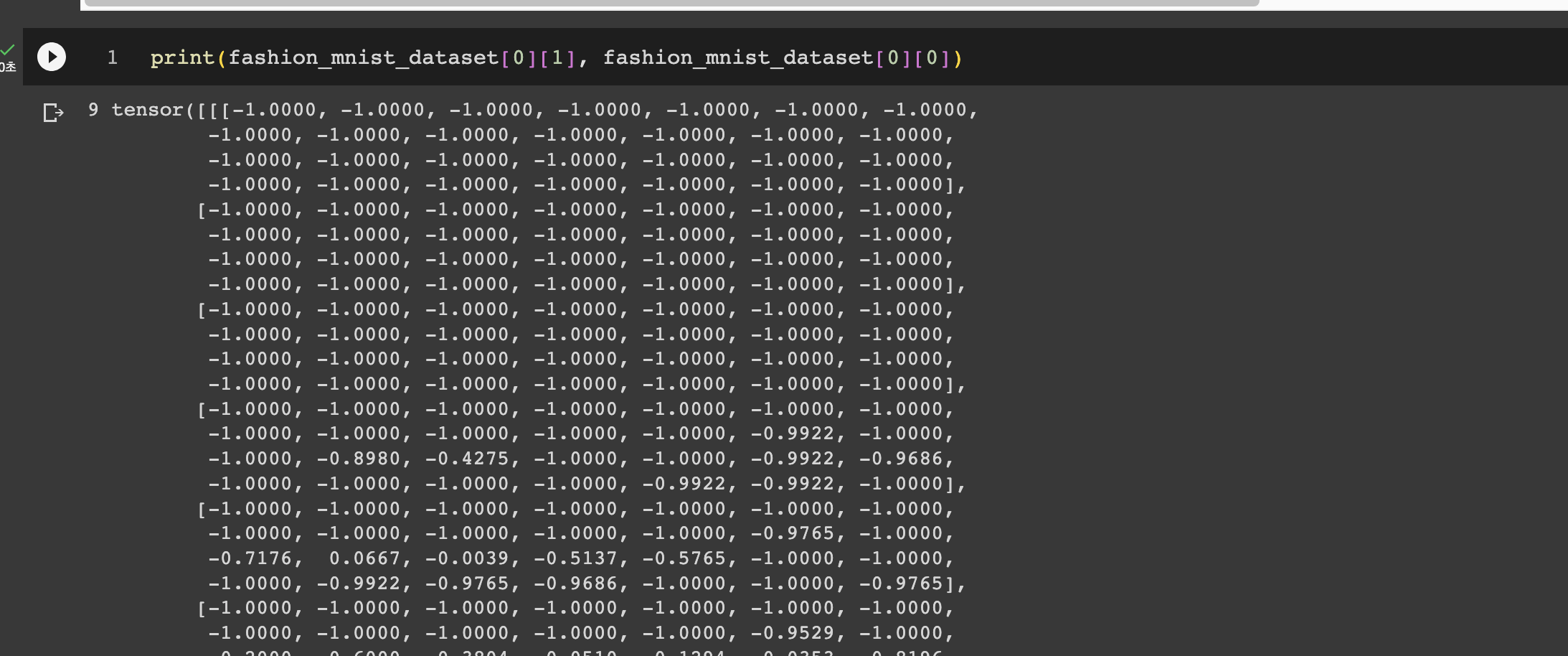
잘 출력됩니다. 그리고 random_split을 사용해서 데이터셋을 분할해보도록 하겠습니다.
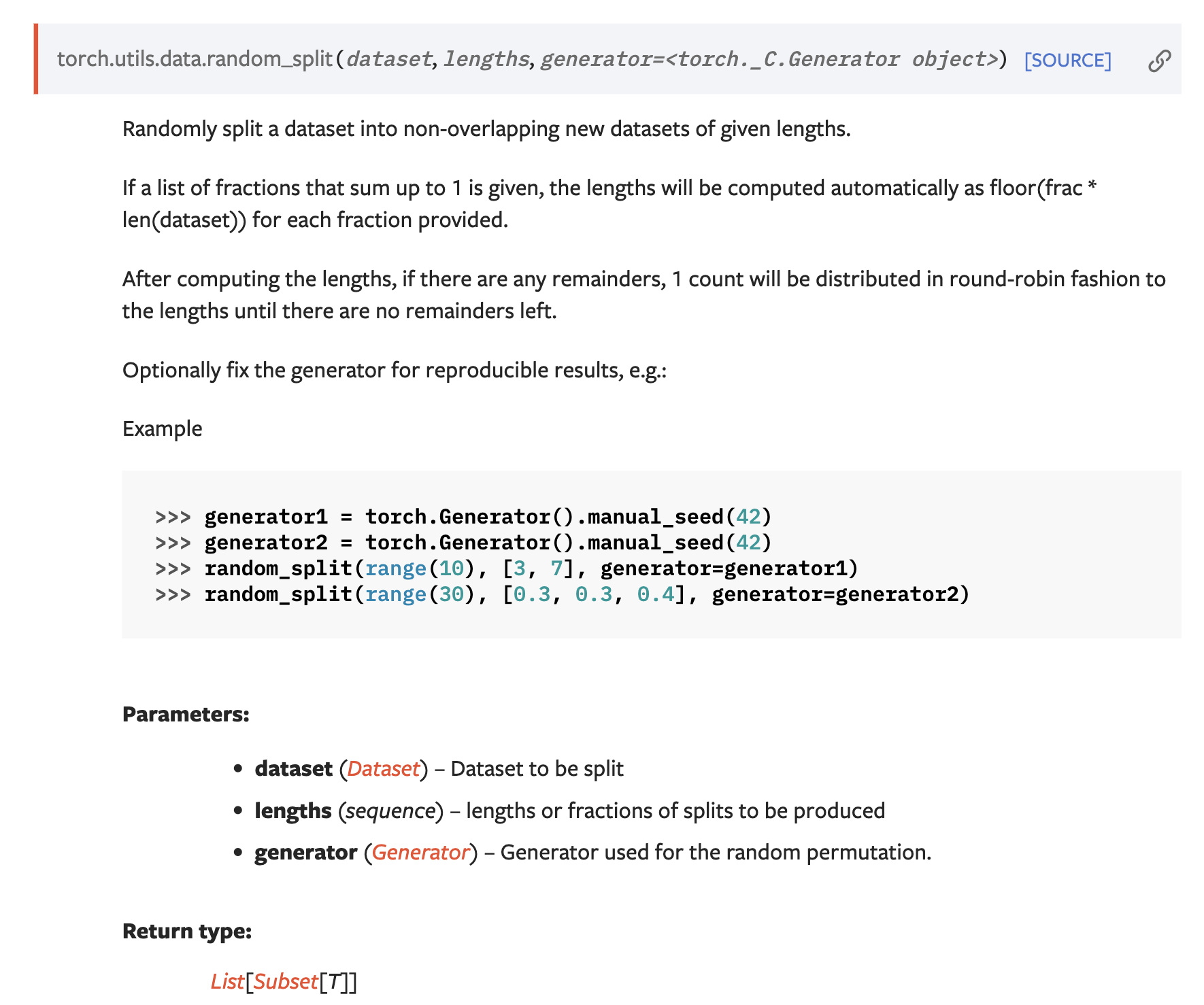
이 random_split함수는 주어진 길이 리스트에 따라 데이터 셋을 무작위로 분할합니다. 이것은 즉시 무작위성을 적용하기 때문에 데이터 셋의 원래 순서를 무시하고 데이터를 무작위로 섞습니다. 이것은 종종 원치 않은 결과를 초래할 수 있습니다. 그래서 우리는
from typing import List, Dict import numpy as np import torch def dataset_split( dataset: torch.utils.data.Dataset, split: List[float] = [0.9, 0.1], random_train_val_split: bool = False, ) -> Dict[str, torch.utils.data.dataset.Subset]: """split torch.utils.data.Dataset by given split ratio. Written by Jungbae Park. Args: dataset (torch.utils.data.Dataset): input interaction dataset. split (List[float], optional): split ratio. len(split) should be in [2, 3] & sum(split) should be 1.0 if len(split) == 2: return { "train": train_dataset, "val": val_dataset } elif len(split) == 3: return { "train": train_dataset, "val": val_dataset, "test": test_dataset } Defaults to [0.9, 0.1]. random_train_val_split (bool, optional): if it's True, will randomly mix mix of train, val indices. In that case, test_dataset will remain as the last portion of all_dataset. else, will keep order for splits (sequential split) Defaults to False. Returns: Dict[str, torch.utils.data.dataset.Subset]: return subset of datasets as dictionaries. i.e. { "train": train_dataset, "val": val_dataset, "test": test_dataset } """ assert len(split) in [2, 3] assert sum(split) == 1.0 for frac in split: assert frac >= 0.0 indices = list(range(len(dataset))) modes = ["train", "val", "test"][: len(split)] sizes = np.array(np.cumsum([0] + list(split)) * len(dataset), dtype=int) # sizes = [0, train_size, train_size+val_size, len(datasets)] if random_train_val_split: train_and_val_idx = indices[: sizes[2]] random.shuffle(train_and_val_idx) indices = train_and_val_idx + indices[sizes[2] :] datasets = { mode: torch.utils.data.Subset( dataset, indices[sizes[i] : sizes[i + 1]] ) for i, mode in enumerate(modes) } return datasets
위와같이 새로 작성된 dataset_split함수를 통해 분할 비율과 함께 선택적인 무작위 분할 기능을 제공하는 함수를 통해 분할해보겠습니다. 즉 랜덤성이 덜 보장되게 해서 값을 예측할 수 있게 해보겠다는 것입니다.
datasets = dataset_split(fashion_mnist_dataset, split=[0.9, 0.1]) train_dataset = datasets['train'] val_dataset = datasets['val'] train_batch_size = 100 val_batch_size = 10
위와같이 train_dataset과 val_dataset을 나누었습니다. 그리고 mini-batch size도 위와같이 설정해 주었습니다. 그리고 데이터를 배치 단위로 묶기 위해서 DataLoader를 통해 코드를 짜줍니다.
train_dataloader = torch.utils.data.DataLoader( train_dataset, batch_size=train_batch_size, shuffle=True, num_workers=1 ) val_dataloader = torch.utils.data.DataLoader( val_dataset, batch_size=val_batch_size, shuffle=False, num_workers=1 )
그리고 shuffle을 통해 데이터 셋을 섞을 수도 있고, num_workers를 통해 병렬 프로세싱도 할 수 있습니다.
for sample_batch in train_dataloader: print(sample_batch) print(sample_batch[0].shape, sample_batch[1].shape) break
그리고 위와같은 코드로 for문을 돌면서 train batch를 확인하고 shape도 확인해보겠습니다.
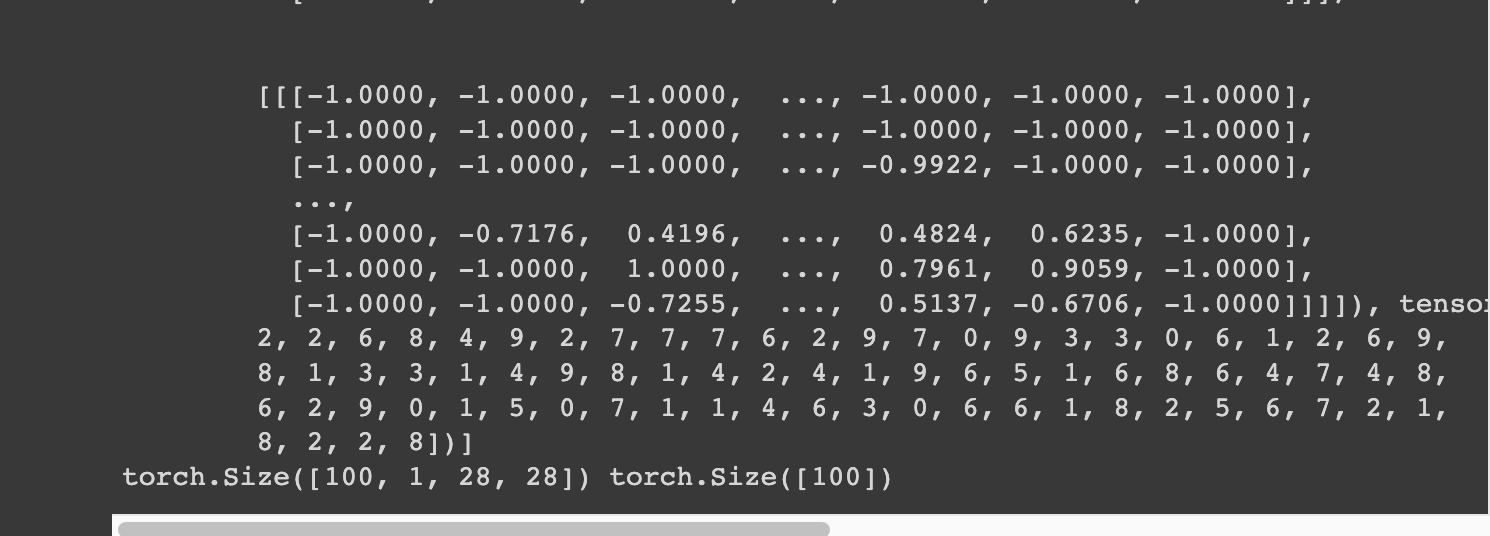
그럼 결과가 잘 나오게 되는데, 첫번째는 image, 두번째는 label이 들어고게 되는데 image의 shape을 보면 [100, 1, 28, 28]입니다. 이는 각각 [batch_size, channel, width, height]입니다. 여기서 우리가 batch_size를 100으로 해줬고 channel은 fashion_mnist dataset이 흑백 사진이므로 1, 그리고 width*height는 28*28임을 확인할 수 있습니다. 그리고 label의 크기는 100이 나온 것을 볼 수 있습니다. 이는 당연히 우리가 정한 미니배치 사이즈와 일치해야 하는 것이겠죠
이제 모델을 정의해야 하는 일이 남았습니다. 여기서는 torch.nn을 사용해서 모델링해보겠습니다.
# Define Model. class MLP(nn.Module): def __init__(self, in_dim: int, hl_dim: int, h2_dim: int, out_dim: int): super().__init__() self.linear1 = nn.Linear(in_dim, hl_dim) self.linear2 = nn.Linear(hl_dim, h2_dim) self.linear3 = nn.Linear(h2_dim, out_dim) self.relu = F.relu pass def forward(self, input): x = torch.flatten(input, start_dim=1) x = self.relu(self.linear1(x)) x = self.relu(self.linear2(x)) out = self.linear3(x) # dout = F.softmax(out) return out
우리는 모델을 정의할 때 무조건 nn.Module을 상속해서 해야합니다. 그 이유는 CPU -> GPU환경으로 마이그래이션이 가능하게 하려면 무조건 해야하는 것이죠. 위는 MLP의 전형적인 모습입니다.
생성자로 우리는 우선 input dimension, hidden-layer의 dimension, hidden2-layer의 dimension, output-dimension을 알아야 합니다. 그리고 당연히 nn.Module의 생성자를 통해 MLP class를 초기화 해야합니다. 우리는 MLP를 할 때 중간 hidden layer에서 linear function의 결과를 activation function을 거쳐서 다음 입력으로 넘어간다고 했습니다.

공식문서에서 nn.Linear는 위와같습니다. 이는 in_features, out_feature, bias를 받게 됩니다.

그리고 activation function으로는 ReLU를 사용해주도록 하겠습니다. 그리고 우리의 인풋은 미니배치 100을 빼면 [1, 28, 28]이라고 했습니다. 근데 이를 linear function에 집어넣어주려면 이를 flattening해주어야 합니다. 그래서 start_dim=1을 해줘서 1차원 배열로 flattening해주었습니다. 그리고 forward에다가 x값을 linear, activation function을 차례대로 적용해줍니다. 그리고 맨 마지막에 일단은 softmax를 감싸주어서 classification을 해주지 않겠습니다. 이로써 모델의 1차 정의가 끝났습니다.
그리고 우리는 모델 선언 및 손실함수, 최적화정의, Logger를 정의해주겠습니다.
# define model. # 10가지 종류로 classification model = MLP(28*28, 128, 64, 10) # define loss loss_function = nn.CrossEntropyLoss() # define optimizer -> Adam의 learning rate를 10-3으로 설정 optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) max_epoch = 15 # define tensorboard logger writer = SummaryWriter() log_interval = 100
우선 input dimension은 1*28*28이였습니다. 그리고 h1은 128, h2는 64, output은 10개로 classification할거니까 10으로 지정해주었습니다. 그리고 loss function은 이전에 살펴보았던 Cross entropy를 사용해주도록 하겠습니다. 그리고 optimizer로는 Adam을 사용해주었습니다. 이건 나중에 더 자세히 살펴보겠습니다. 그리고 epoch는 15개로 일단 돌아보도록 하겠습니다, 마지막으로 tensorboard logger를 설정해주겠습니다. 그리고 마지막으로 나중에 학습할때 배치마다 100개의 interval로 train_loss, train_acc를 찍기 위해 100을 interval로 주었습니다.
%load_ext tensorboard %tensorboard --logdir runs/ # train_step을 초기화 해준다. train_step = 0 # epoch를 돌면서 미니배치들을 학습해간다. -> train dataset shuffle=True를 해서 과적합 방지 for epoch in range(1, max_epoch+1): # valid step을 통해 variance등을 체크하여 overfitting을 체킹할 수 있을 것이다. with torch.no_grad(): val_loss = 0.0 val_corrects = 0 # train을 하면서 validate까지 해준다. for val_batch_idx, (val_images, val_labels) in enumerate( tqdm(val_dataloader, position=0, leave=True, desc="validation") # tqdm을 통해 가시화 ): # forward step -> model의 forward실행 val_outputs = model(val_images) _, val_preds = torch.max(val_outputs, 1) # predict한 index를 추출한다. # los & acc val_loss += loss_function(val_outputs, val_labels) / val_outputs.shape[0] # batch size만큼 나눠서 평균을 내겠다 val_corrects += torch.sum(val_preds == val_labels.data) / val_outputs.shape[0] # valid step logging -> 최종적으로 len(val_dataloader)만큼 나누어 주어야 한다. val_epoch_loss = val_loss / len(val_dataloader) val_epoch_acc = val_corrects / len(val_dataloader) # epoch마다 validate셋의 loss, acc를 찍는다. print(f"{epoch} epoch, {train_step} step: val_loss: {val_epoch_loss}, train_acc: {val_epoch_acc}") # tensorboard에 가시화 writer.add_scalar("Loss/val", val_epoch_loss, train_step) writer.add_scalar("Acc/val", val_epoch_acc, train_step) writer.add_images("images/val", val_images, train_step) val_loss = 0.0 val_corrects = 0 # train data set학습 for batch_idx, (images, labels) in enumerate( tqdm(train_dataloader, position=0, leave=True, desc="train")): current_loss = 0.0 current_corrects = 0 # get prediction -> 이 2개를 계속 체크 할것임 outputs = model(images) # model에 대해 forward를 수행 _, preds = torch.max(outputs, 1) # get loss (Loss 계산) loss = loss_function(outputs, labels) # plogQ 형태 # Backpropagation # optimization 초기화 optimizer.zero_grad() # Perform backward pass loss.backward() # Perform Optimization optimizer.step() current_loss += loss.item() # 우리가 얼마나 맞추었는지도 알아야 한다. -> torch.sum을 통해 텐서연산 최적화 current_corrects += torch.sum(preds == labels.data) if train_step % log_interval == 0: train_loss = current_loss / log_interval train_acc = current_corrects / log_interval print(f"{train_step}: train_loss: {train_loss}, train_acc: {train_acc}") writer.add_scalar("Loss/train", train_loss, train_step) writer.add_scalar("Acc/train", train_acc, train_step) writer.add_images("images/train", images, train_step) writer.add_graph(model, images) current_loss = 0 current_corrects = 0 train_step += 1
코드의 주석으로 충분히 이해할 수 있을 것입니다. 이를 실행하면 아래와 같이 됩니다.
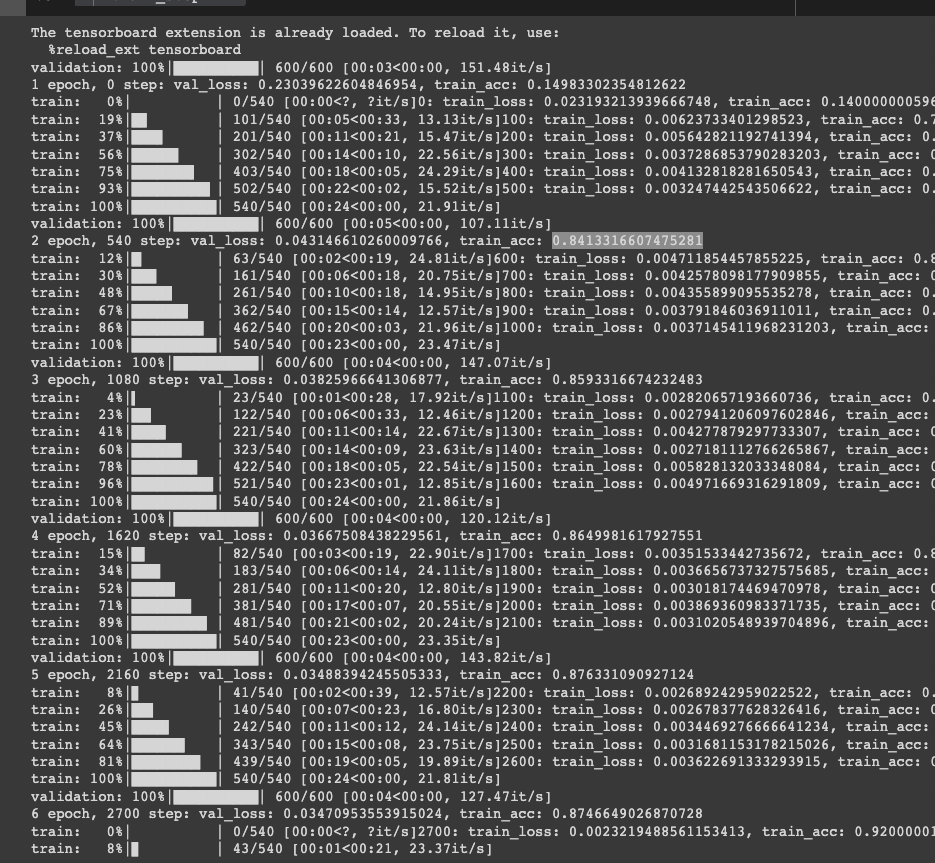
우리는 이를 validation과정을 통해 실제 variance가 높아지고 있는지 확인할 수 있고 이를 통해 과적합도 피해서 early stopping을 할 수 있습니다. 보면 train_loss는 계속 줄고(무조건 계속 줌), train_acc는 과적합이 되진 않았지만 들쭉날쭉하게 미세한 차이로 증가하는 것을 볼 수 있습니다. 우선 6epoch 까지 학습한 모델을 tensorboard에서 확인도 하고 저장해보도록 하겠습니다.
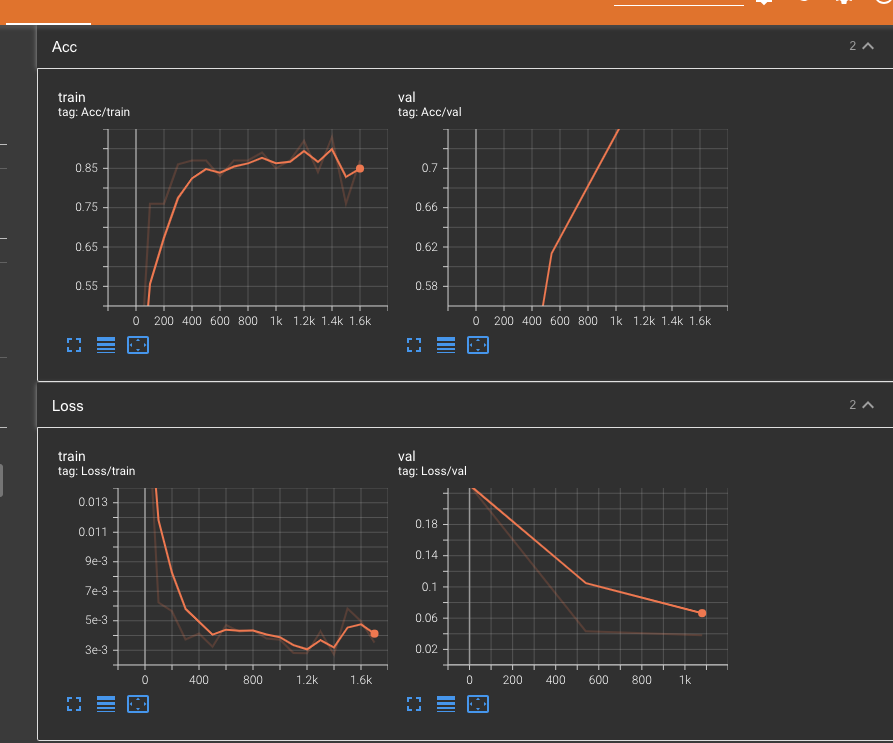
실제로 그래프로 볼 수 있으며, 실제 val acc이 train acc보다 작음을 알 수 있습니다.
# save model os.makedirs("./logs/models", exist_ok=True) torch.save(model, "./logs/models/mlp.ckpt") # load model loaded_model = torch.load("./logs/models/mlp.ckpt") loaded_model.eval() print(loaded_model)
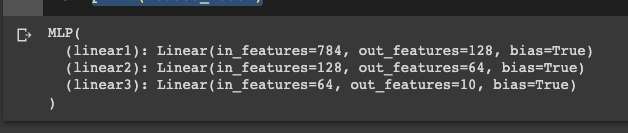
그 다음으로 모델을 저장해주었습니다. 이제 저장한 모델을 마지막으로 softmax를 씌워서 정확도와 ROC Curve를 그려보도록 하겠습니다.
def softmax(x, axis=0): "numpy softmax" max = np.max(x, axis=axis, keepdims=True) e_x = np.exp(x - max) sum = np.sum(e_x, axis=axis, keepdims=True) f_x = e_x / sum return f_x l = np.array([[1.3, 5.1, 2.2, 0.7, 1.1], [7.3, 2.1, 3.1, 2.7, 1.6]]) softmax(l, axis=1)
여기서 각 값들을 정규화 하고 softmax를 진행해 주었습니다.
test_batch_size = 100 test_dataset = FashionMNIST( data_root, download=True, train=False, transform=transforms.ToTensor()) test_dataloader = torch.utils.data.DataLoader( test_dataset, batch_size=test_batch_size, shuffle=False, num_workers=1) test_labels_list = [] test_preds_list = [] test_outputs_list = [] for i, (test_images, test_labels) in enumerate( tqdm(test_dataloader, position=0, leave=True, desc="testing")): # forward step test_outputs = loaded_model(test_images) _, test_preds = torch.max(test_outputs, 1) # apply softmax activation function final_outs = softmax(test_outputs.detach().numpy(), axis=1) test_outputs_list.extend(final_outs) test_preds_list.extend(test_preds.detach().numpy()) test_labels_list.extend(test_labels.detach().numpy()) test_preds_list = np.array(test_preds_list) test_labels_list = np.array(test_labels_list) print(f"\nacc: {np.mean(test_preds_list == test_labels_list)*100}%")
위와 동일하게 fashion mnist dataset의 test set을 가져온다음에 우리가 학습시킨 모델의 정확도를 측정하였습니다.

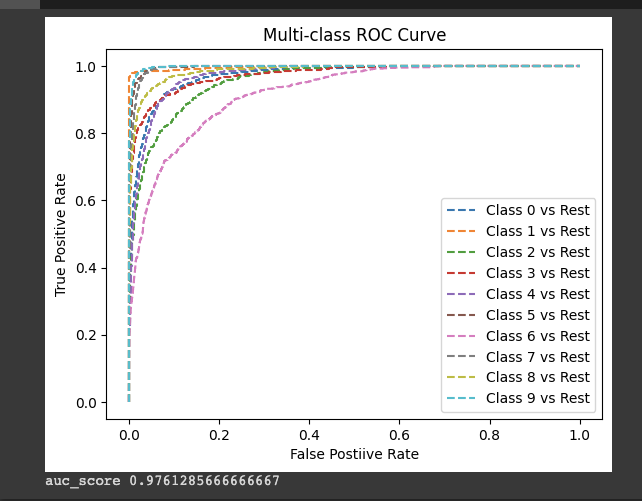
그리고 ROC Curve를 sklearn을 통해 그려보았는데, 각 class별로 fpr, tpr을 통해 성능을 확인해보았습니다.
# ROC Curve from sklearn.metrics import roc_curve from sklearn.metrics import roc_auc_score fpr = {} tpr = {} thresh = {} n_class = 10 for i in range(n_class): fpr[i], tpr[i], thresh[i] = roc_curv = roc_curve(test_labels_list, np.array(test_outputs_list)[:, i], pos_label=i) # plot. for i in range(n_class): plt.plot(fpr[i], tpr[i], linestyle="--", label=f"Class {i} vs Rest") plt.title("Multi-class ROC Curve") plt.xlabel("False Postiive Rate") plt.ylabel("True Positive Rate") plt.legend(loc="best") plt.show() print("auc_score", roc_auc_score(test_labels_list, test_outputs_list, multi_class="ovo", average="macro"))
'AIML > 딥러닝 최신 트렌드 알고리즘' 카테고리의 다른 글
| [딥러닝 논문 리뷰 - PRMI Lab] - Deep Residual Learning for Image Recognition (CVPR 2016) + 실습 (0) | 2023.06.29 |
|---|---|
| [딥러닝 논문 리뷰 - PRMI lab] - 배치 정규화(Batch Normalization) + 보편적 근사 정리(Universal Approximation Theorem) (0) | 2023.06.29 |
| [딥러닝 최신 트렌드 알고리즘] - Feedforward Network (0) | 2023.06.26 |
| [딥러닝 최신 알고리즘] - 정보이론 (엔트로피, KL 발산, 크로스 엔트로피) (0) | 2023.06.25 |
| [딥러닝 기초 알고리즘] - ML 기초 (0) | 2023.06.25 |