![[딥러닝 논문 리뷰 - PRMI Lab] - Deep Residual Learning for Image Recognition (CVPR 2016) + 실습](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbNvs5u%2FbtslSmudso3%2FInw8wKuRrGzAuxKSS2dpH0%2Fimg.png)

- 본 논문에서는 깊은 네트워크를 학습시키기 위한 방법으로 잔여 학습(residual learning)을 제안했습니다.
원래 층이 깊어지면 깊어질 수록 어떠한 데이터로부터 Feature를 더 많이 추출해 낼 수 있게됩니다. 그로인해 모델이 더 높은 성능을 낼 수 있게 된다는 것이 일반적인 양상입니다. 당연히 레이어가 너무 깊어지게 되면 오히려 과적합 되서 성능이 떨어지게 됩니다.
위 그림처럼 기존의 CNN에서 layer가 더 깊으면 error rate가 더 높아지는 것을 볼 수 있습니다. 하지만 잔여 학습(Deep Residual Learning)을 적용한 CNN에서는 레이어의 깊이가 깊어져도 일반적인 양상인 error rate가 낮아지게 되었다는 것이 이 논문이 contribute한 내용입니다.
CNN 모델의 특징 맵 (Feature Map)
- 일반적으로 CNN에서 레이어가 깊어질 수록 채널의 수가 많아지고 너비와 높이는 줄어듭니다.
- 컨볼루션 레이어의 서로 다른 필터들은 각각 적절한 특징(feature)값을 추출하도록 학습됩니다.
VGG 네트워크
VGG네트워크는 Very Deep Convolutional Networks for Large-Scale Image Recognition입니다. 이는 이미지 인식 대회에서 매우 우수한 성능을 냈었던 네트워크인데요. VGG16의 경우 위와같이 conv 1_1부터 해서 fc8까지 총 Weighted Layer가 16개 임을 볼 수 있습니다.
여기서는 처음에 이미지를 224 x 224 로 만든 다음에, 컨볼루션 연산을 거쳐 채널의 수를 64로 만든 것입니다. 그리고 여기서는 3 x 3 특징맵 필터를 통해 계산되는 것을 볼 수 있습니다. 그리고 주기적으로 컨볼루션 레이어에 풀링 레이어를 추가해 down sampling을 진행할 수 있도록 합니다. 이 폴링 레이어를 나오면 width와 height가 줄어드는 것을 볼 수 있고, 그 이후에 다시 컨볼루션 네트워크를 거쳐셔 채널값을 더 증가시키는 것을 볼 수 있습니다.
최종적으로 이러한 과정을 여러번 거쳐서 fully-connected layer를 거쳐 1000개의 클래스에 대한 probability값을 뽑아내서 분류를 하는 것을 볼 수 있습니다. 이러한 VGG네트워크는 파라미터의 갯수가 많다는 단점이 있지만, 이 컨볼루션의 장점을 잘 살렸다는 점에서, 아직까지도 많은 논문에서 백본 네트워크로서 활용되고 있다는 것이 특징입니다.
그럼 우리는 궁금증을 가질 수 있습니다. VGG Net이 레이어를 많이 쌓아서 고차원적인 Feature들을 잘 뽑아냈어, 그러면 더 많이 쌓아서 좋은 성능을 낼 수 있는거 아닌가? 아닙니다. 여전히 VGG Net에서도 많은 파라미터라는 문제가 존재하고 무작정 많은 레이어를 쌓는다고 해서 성능이 결코 좋아지는 것이 아닙니다. 이러한 문제를 해결하기 위해 등장한 것이 드디어 우리가 알아볼! Res Net입니다!
잔여 블록 (Residual Block)
잔여 블록이란 실제로 네트워크의 최적화 난이도를 낮추기 위해 고안된 방법입니다. 실제로 내제한 mapping인 를 곧바로 학습하는 것은 어려우므로 대신 를 학습합니다. 즉 학습이 잘 되는 형태로 변경하는 것입니다.
왼쪽 그림을 보면, 우리는 컨볼루션 레이어와 같은 weight layer가 있었습니다. 그리고 ReLU와 같은 활성화 함수를 통해 non-linearity를 추가해줍니다.그리고 다시 이어서 컨볼루션 레이어를 붙혀서 동작하도록 합니다. 이러한 결과를 통해 로부터 나온 이상적인 결과를 우리는 라고 하겠습니다. 하지만 이런 를 학습하는 것은 어려우므로 이를 로 바꿔서 학습하자라는 것이 본 논문의 핵심 아이디어 입니다. 잘 보면 그냥 결과에다 하나만 더해주는 것으로 끝났습니다. 매우 간단합니다.
를 와 같게 학습을 유도하는 것입니다. 기존의 의 결과에 앞서 학습된 정보인 를 그대로 가져와 거기다가 추가적으로 를 더해주겠다는 겁니다. 그럼 전체를 학습하는 것보다 만 학습시키면 되는 아주 간단한 문제로 변환이 된 것입니다! 바로 수식으로 보겠습니다.
이를 수식적으로 자세히 표현하면 위와 같습니다. 그리고 를 자체가 set이기 때문에 multiple convolutional layers라고 표기되어 있고, 는 기존에 input값인 shortcut입니다. 그리고 만약 x의 input dimension과 y의 output dimension이 다르다면, 를 의 차원에 projection해서 그냥 더해주기만 하면 된다고 논문에 적혀있습니다.

자세히 논문을 보며 나중에 실제로 ImageNet, CFAR-10데이터를 학습하고 돌려보는 데 분석할 수 있는 기량을 만들어 봅시다!
Deep Residual Learning for Image Recognition (CVPR 2016)
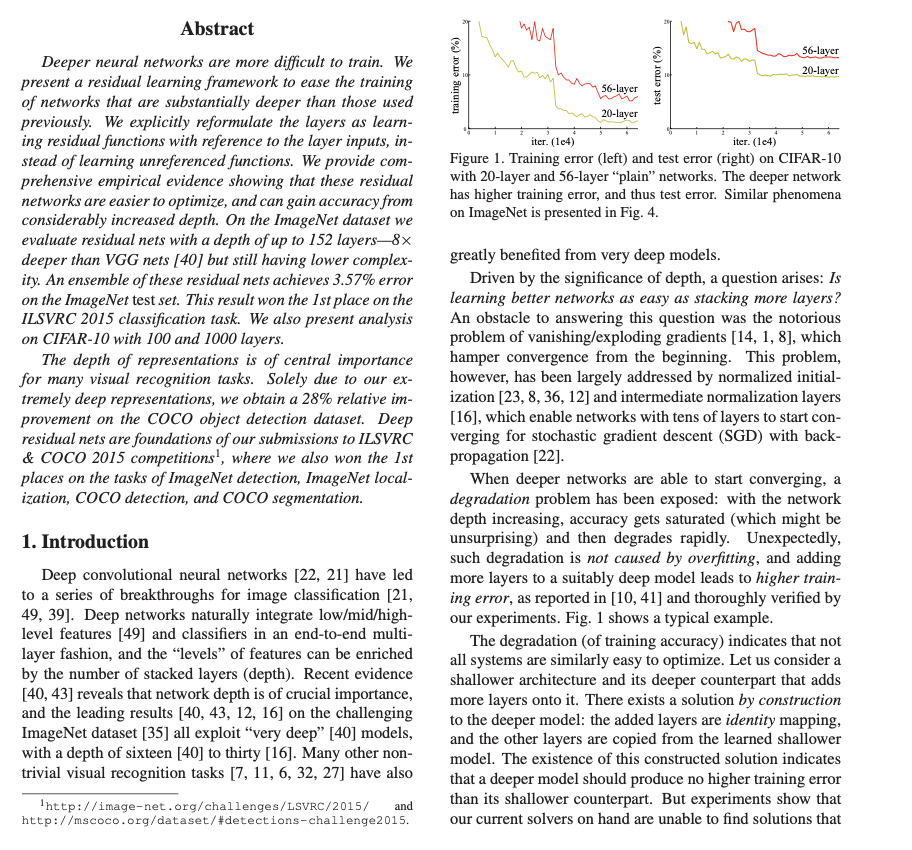
우선 초록(Abstract)입니다. 여기서는 Deeper neural networks는 학습하기 힘들다고 말하고 있습니다. 하지만 (잔차 네트워크)redisual learning framework를 쓰면 이전의 깊은 네트워크보다 더 손쉽게 train error를 줄이면서 학습이 가능하다고 합니다. 즉 이는 이전 레이어의 입력을 참조하여 레이어의 학습 잔차 함수로 명시적으로 재구성 하는 작업이라고 위에서 쭉 이야기했습니다.
즉 이를 통해 깊이가 상당히 깊어질 수록 정확도를 높일 수 있음을 보여주는 포괄적인 증거를 제공하겠다고 합니다. 본 논문에서 152개의 레어어 깊이를 가지는 잔여 네트워크를 평가하는데, VGG 네트워크 보다 8배 더 깊지만 여전히 낮은 복잡도를 가지게 할 수 있다고 합니다. 또한, 이러한 잔여 네트워크의 앙상블은 ImageNet 테스트 셋에서 3.57%의 오류를 달성했다고 합니다. 이 결과로 ILSVRC 2015 분류 대회에서 1위를 차지했으며, 100개와 1000개의 레이어가 있는 CIFAR-10에 대한 분석 결과도 뒤에 나온다고 합니다. 이전에도 쭉 말했지만, 표현의 깊이는 많은 시각 인식 작업에서 가장 중요한 요소입니다. 그래서 이 ResNet을 통해 깊은 네트워크를 쌓을 수 있게 되었다는 건 매우 큰 이점이 되는 것이죠
그 다음은 서론(Introduction)입니다. Deep network은 본질적으로 low/mid/high 레벨의 feature들을 통합합니다. 즉, deep network의 레벨이 높아진다는 것은 이러한 feature들을 표현할 수 있는 방법이 풍부해 진다는 것입니다. 그럼 레이어만 무작정 깊게 쌓으면 되는거 아니야? 라고 생각할 수 있습니다. 아닙니다! 이와 관련된 문제들은 이전부터 매우 많이 소개가 되어왔는데요, 대표적으로 vanishing/exploding gradients와 같은 문제가 있을 수 있는데요, 이러한 문제를 해결하기 위해 다양한 테크닉들이 존재합니다. 몇개만 서술하자면, 네트워크의 파라미터를 초기에 적절히 설정해서 학습이 잘 되도록 유도하는 방법이 있을 수 있습니다. 즉 여기서 말하는 내용을 정리하면, 레이어가 깊어질 수록 degrading problem이 존재할 수 있다는 것입니다.
또한, 이러한 레이어가 지나치게 깊어지면 정확도가 낮아지게 되는데, 이는 무조건 overfitting때문 만이 아닙니다. 위 그림을 보면, overffiting이라면 train error는 높아야 하는데, 레이어를 56개 쌓은게 20개를 쌓은 거보다 train error도 높고, 학습이 잘 되지 않는 양상을 볼 수 있습니다. 이러한 degradation problem이 말하는 바는, 모든 시스템이 쉽게 최적화가 될 수 있는게 아니라는 점을 시사합니다.
그러면 우리는 생각해 볼 수 있습니다. 그럼 더 깊은 모델을 만들려고 하면, shallower model로 부터의 identity mapping을 더 많이 추가하면 되는거 아닐까? 여기서는 deeper model이 shallower model보다 train error가 더 높아진다는게 상식적으로 말이 안된다는 것입니다.

그래서 본 논문에서는 위와같이 degrading problem을 해결하기 위해서 deep residual framework을 제안합니다. 이의 핵심 개념은 명시적으로 학습이 더 쉬운 형태로 모델을 변환해서 학습을 진행시키겠다는 의미입니다. 그래서 실제로 이상적인 를 학습하는 것이 아니라 이 형태를 학습시켜서 학습시킨 를 잔차에 더해주어 와 같은 형태로 output을 만들겠다는 의미입니다. 만약 우리가 학습시키고 싶은 mapping이 identity mapping이라면, 우리가 학습해야 하는 는 애초에 0으로 convergence(수렴)하게 학습시키는 것이 학습 난이도가 더 쉬울 수 있다! 라는 것이 논문에 적혀있습니다.
그리고 우리가 더해준 를 short connection혹은 skip connection이라고 합니다. 이러한 shortcut connections는 간단히 identity mapping을 진행하기 때문에, 출력값에 무슨 가중치를 곱한다거나 bias를 더해야 하는 작업이 필요없습니다. 즉 추가적으로 복잡도가 늘어나지 않아 복잡도가 낮고, 계산량도 낮아집니다. 이러한 이유에서 학습 난이도가 쉬워진다고 할 수 있습니다. 뿐만 아니라, 실험적으로 레이어가 깊어지면 깊어질 수록 정확도가 높아진 것도 장점이라고 할 수 있습니다.
그리고 이러한 ResNet을 ImageNet, CIFAR-10 set에도 동일하게 적용되므로, 특정 데이터 셋에서만 일어나는 현상이 아님을 알 수 있었다고 합니다. 넘어서 Ensemble(앙상블)기법까지 적용했을 때 top-5 error로 3.57%가 나와서 ILSVRC 2015 classification competition에서 1등을 했다고 합니다~ 짝짜짝짝. 그리고 또한! 이미지 분류 뿐만이 아니라, object detection, segmentation detection과 같은 분야에 적용해도 정확도가 높게 나와서, 다양한 분야에서도 잘 작동하는 좋은 기법이라고 합니다.
그리고 Google Net, high way network와 같이 이러한 기법들은 이전부터 쭉 연구되고 있던 분야라고 본 논문에서 말하고 있습니다.

여기서는, 기존에 말하고 있던 내용을 자세히 다룹니다. 당연히 optimal한 mapping이 identity mapping이지 않을 수 있습니다. 하지만 위와같은 reformulation은 기존의 문제를 재정의해서 손쉽게 해결할 수 있게 만든다는 거에 의미가 있습니다. 만약 optimal function이 zero mapping보다는 identity mapping에 가까워 진다면 더 학습하기 쉬워진다는거죠
그리고 맨 아래 식에서 shortcut에는 추가적인 파라미터가 들어가지 않습니다. 가 에 곱해진건 input dimension이 output dimension보다 더 높을 수 있기 때문에 linear projection과 같은 변환이 추가된 행렬(square matrix)이라고 보면 됩니다. 그리고 위 식은 bias를 고려하지 않은 식입니다. 그리고 본 논문에서 는 여러 개의 convolution층으로 이루어 져있는데, 이는 만약 가 단일 층이라면 가 되어 그냥 linear layer가 되어 학습이 잘 안될 수 있다는 단점이 있게 됩니다. 그래서 본 논문에서는 여러 레이어로 residual block을 쌓는 것을 볼 수 있습니다. 그래야 non-linear 하게 feature를 잘 학습할 수 있기 때문이죠.
그리고 이러한 shortcut connection은 gradient vanishing문제가 이기 때문에 input layer까지 gradient가 잘 도달할 수 있게 돕는다는 장점도 있게 됩니다. 그리고 이제부터 본격적으로 Plain Network와 비교하면서 실험을 진행합니다.
Plain Network는 본 논문에서 VGG네트워크 철학을 다릅니다. 그래서 3 x 3 작은 크기의 filter를 사용하고, output feature map size와 같게 맞추어 주기 위해 이의 차원과 개수를 맞춥니다. 그리고 feature map 크기가 절반으로 줄어들 때는, filter의 개수를 2배로 늘려서 다음 레이어에서 channel값을 2배로 늘리도록 했습니다. 그래서 각 layer마다 time complexity를 보존할 수 있게끔 구성하겠다고 말하고 있습니다. 또한, 별도의 pooling layer를 사용하지 않고, stride가 2인, convolution layer를 통해 downsampling을 수행하겠다고 되어있습니다. 그리고 마지막에 별도의 average pooling을 사용해서 1000개의 class로 분류할 수 있도록 했다고 말하고 있습니다. 즉 이는 기존의 VGG nets와 비교했을 때, 더 적은 파라미터를 포함하고, 복잡도 또한 낮았다고 그 장점에 대해 언급하고 있습니다.

위 그림에서 맨 왼쪽은 기존의 19-layer짜리 VGG net입니다. 그리고 그 옆은 비교를 위해 34-layer짜리 plain 네트워크를 구성한 그림이고, 그 옆은 그 왼쪽과 동일한데, residual block만 추가한 형태로 바꾼 것입니다. 34-layer짜리 plain 네트워크는 기존의 방식 그대로 3x3 필터 64개를 사용했음을 볼 수 있고, residual block(ResNet)을 추가한 것은, 2개의 convolution 층마다 residual function으로 묶어서 네트워크를 구성한 것을 볼 수 있습니다. 그리고 ResNet에서 점선으로 표시된 것은 input, output data의 dimension이 같지 않아서 dimension을 맞춰줄 수 있는 기술이 가미된 shorcut connection이라고 생각하면 되겠습니다!
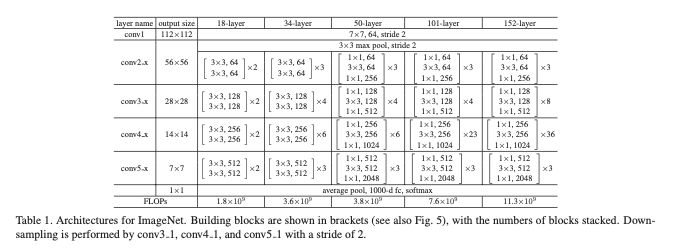
위 표에서 34-layer의 CNN구조를 따르는 것을 볼 수 있습니다. 나중에 직접 모델을 구성할 때 이 표를 참고하겠습니다. 그리고 위 논문에서는 위에서 점선으로 표시된 것이 입력 차원과 출력 차원이 달라서 shortcut connection을 할 때 차원을 맞춰주는 과정이 필요하다고 했습니다. 이를 위한 방법으로 2가지를 제시하는데, (A)는 그냥 추가할 차원만큼 zero padding을 주는 것입니다. (B)는 위에서 쭉 설명했던 것처럼 1 x 1 필터를 사용해서 linear-projection을 통해 차원을 맞춰주는 방법입니다. (A)는 불필요한 데이터가 추가되서 모델의 성능을 영향을 끼치겠지만, 그렇기 큰 영향은 미치지 않는다고 본 논문에 나와있습니다.
그리고 실제 구현방법도 본 논문에서 소개되고 있습니다. 실제 ImageNet데이터에 대해 224 x 225 crop이 randomly sampled되어서 과적합을 방지하게 했고, horizontal flip과 같은 기술이 적용될 수 있다고 소개되고 있습니다. 그리고 매convolution 층을 거칠때 마다 batch normalization(BN)을 적용해 주었다고 되어 있습니다. 그리고 learning rate도 0.1에서 시작해서 점진적으로 줄여 나가서 에러율을 줄여나갔다고 되어 있습니다. 그리고 weight decay를 0.0001, momentum값을 0.9로 설정했다는 것을 볼 수 있습니다.
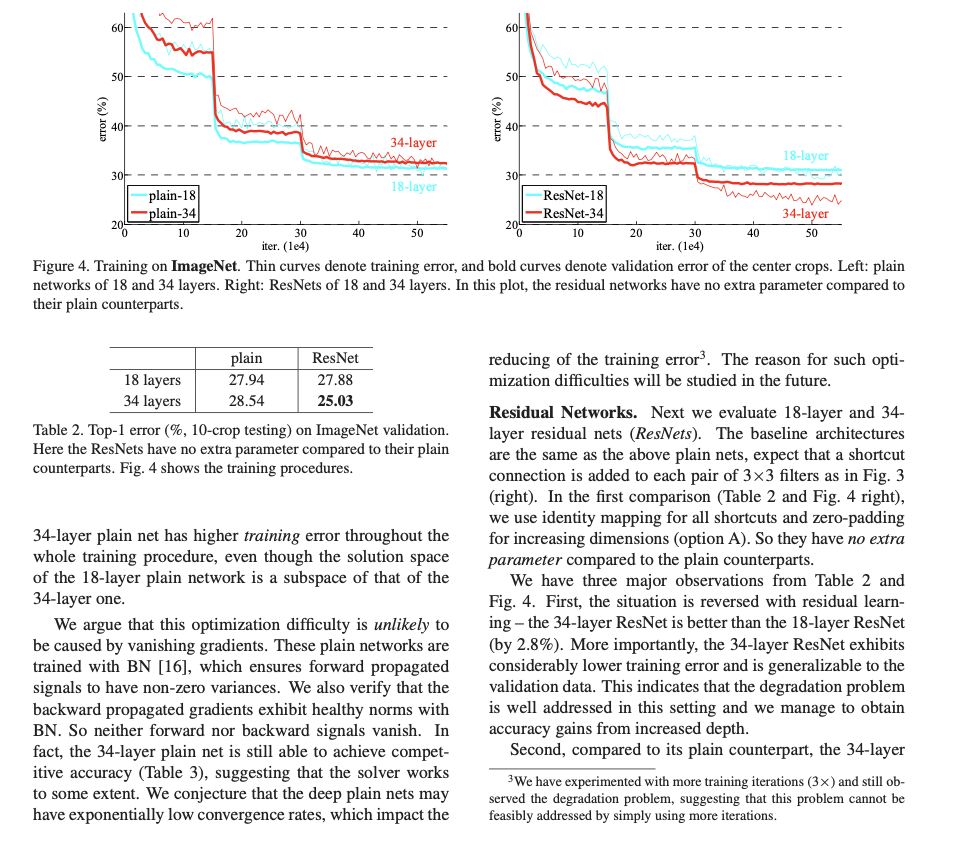
실제로 실험을 한 결과입니다. Plain layer같은 경우에서는 layer를 더 깊게 쌓았을 때 error rate가 더 증가한 것을 볼 수 있습니다. ResNet같은 경우는 반대입니다!. 이 둘의 차이는 shortcut connection이 더해진 것이 차이점이였는데도 불구하고 훨씬 성능이 개선된 것을 볼 수 있습니다. 그리고 이전에도 말했지만, 본 논문의 저자들은 해당 문제가 vanishing gradient문제 때문만에 일어난 것이 아니라고 합니다. 실제로 forward, backward path에서 signal이 없어지는 현상은 관측할 수 없었다고 합니다. 대신 본 논문의 저자들은 이러한 이유가 exponentially low convergence rate때문이라고 합니다.

그리고 실험 결과에서 ResNet이 수렴 속도가 Plain Layer에 비해 빠른것을 볼 수 있다고 하고, 적용한 SGD solver가 좋은 일반화 성능을 보일 수 있었다고 합니다.
또한! 우리가 이전에 shorcuts을 projection하는 방법이 다양하다고 했는데, 이러한 방법들에대한 실험적으로 성능을 비교한 내용이 나와있습니다. (A)는 zero padding을 이용해 dimension을 늘려주어서 identity mapping을 진행 한 것입니다. (B)는 dimension이 증가할 때만 projection연산을 진행한 것이라고 볼 수 있습니다. (C)는 그냥 모든 shorcut에 대해 projection을 사용하는 것이라고 생각할 수 있습니다. Table 3을 보면, C번이 성능 자체는 가장 높게 나오는 것을 볼 수 있습니다. 이렇게 실험적으로 (C)가 가장 높은 성능을 보였다고 할 지라도, 그렇게 projection shortcut이 필수라고 할만큼 높은 성능 개선을 보이지는 않았다고 합니다. 기본적으로도 identity shortcut으로도 충분히 에러율을 낮출 수 있다고 말하고 있습니다.
그리고 여기서 Deeper Bottleneck Architecture에 대해서도 소개합니다. 처음에 1x1 64의 필터로 시작해서 3x3 64 -> 1x1 256으로 컨볼루션을 해서, 연산량을 줄인 것을 말합니다. 이러한 bottleneck architecture에서 parameter-free identity shortcut은 매우 중요하다고 되어 있습니다. 또한 생략한 부분이 있는데, bottlenect architecture의 중요한점은 첫번째와 세번째 1x1 컨볼루션은 차원을 축소하고 복원하는 역할을 합니다. 즉, 이 구조는 고차원의 입력과 출력 사이의 저차원 특징 맵을 학습함으로써, 파라미터의 수를 파라미터의 수를 크게 줄일 수 있습니다.

실제로 34-layer net을 위에서 소개한 3-layer bottleneck block으로 대체했을 경우 50-layer ResNet을 만들 수 있었는데, 이는 이전 모델과 FLOPs가 비슷하고 성능도 준수했다고 합니다. 그리고 layer를 더 깊게 쌓으면 더 좋은 성능을 보일 수 있었다고 합니다. 실제로 기존의 VGG-16/19 net과 비교했을 때 더 낮은 복잡도를 가지면서 성능은 더 좋게 만들 수 있었다고 합니다.
그리고 CIFAR-10데이터에 대해서도 실험을 진행했다고 합니다. 기본적으로 CIFAR데이터는 ImageNet데이터에 비해 입력의 크기가 32x32로 더 작습니다. 그래서 기존의 ImageNet과 비교했을 때, 파라미터 수를 더 줄여서 별도의 ResNet을 고안해서 학습시켰다고 합니다. 구체적인 수치는 논문에 나와있습니다. 이도 동일하게 pairs of 3x3 layers마다 shortcut connection을 사용했다고 되어 있습니다. 그래서 fully-connected layer를 포함한 의 weighted layer에 개의 shortcut이 존재한다고 말하고 있습니다.
이 또한, 로 늘려감에 따라 학습을 해보았는데, 레이어가 깊어짐에 따라서 더 에러율이 낮아짐을 확인할 수 있었다고 합니다. 이는 MNIST데이터 셋에서도 동일하게 적용될 수 있다고 합니다.
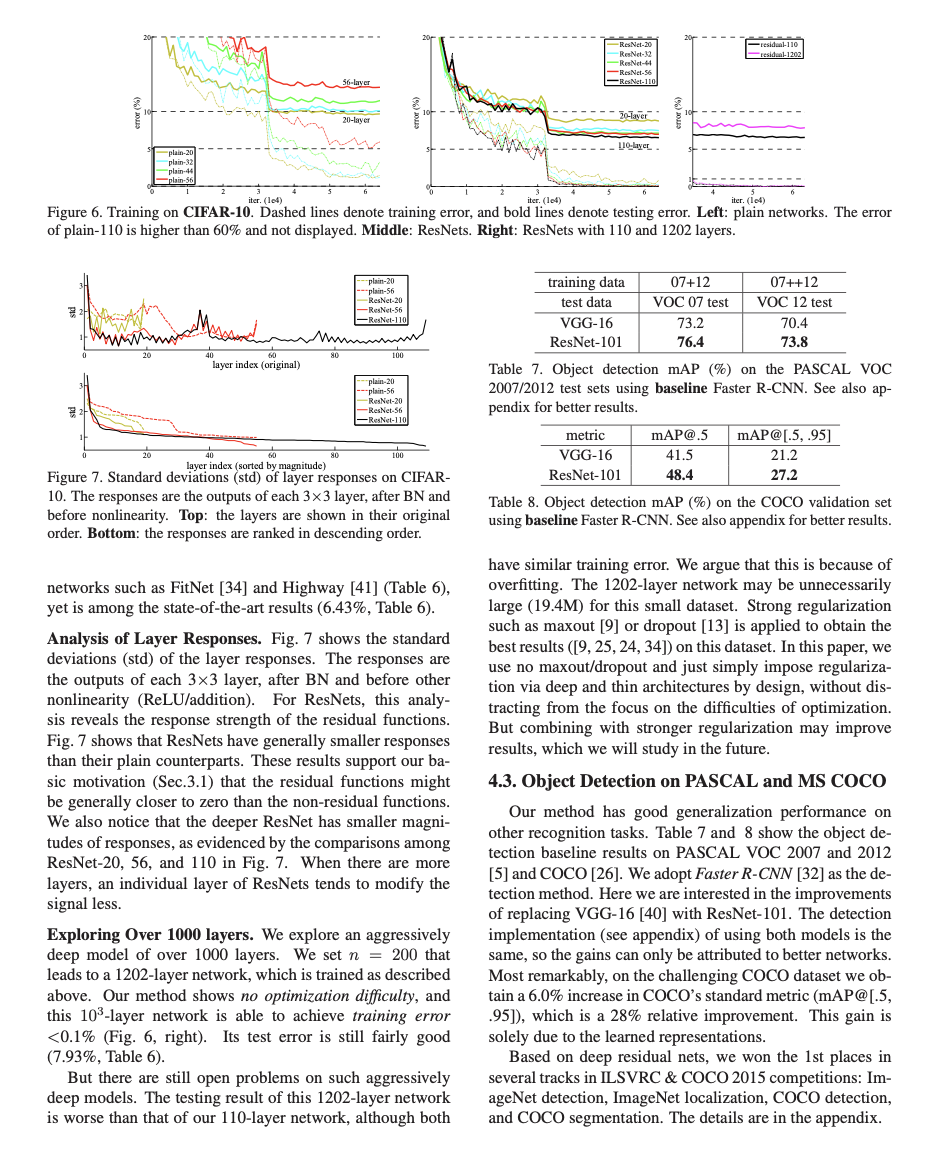
그리고 레이어의 Responses에 대해서도 평가한 것입니다. Fig 7을 보면, layer response의 standard deviations(표준편차)를 볼 수 있습니다. 이의 Response값 측정은 BN layer 이후, nonlinearity (ReLU/addition)과 같은 활성화 함수 전의 값을 측정한 것이라고 합니다. ResNets는 이러한 response값이 매우 작음을 볼 수 있습니다. 이는 논문의 처음부분에 소개한 말들을 전부 실험적으로 뒷받침합니다.
하지만 layer가 1000개가 넘어가면() 오히려 성능이 떨어질 수 있다고 말하고 있습니다. 이렇게 적은 데이터에 대해서 복잡한 모델을 사용하면, 오히려 오버피팅 문제가 발생할 수 있다고 지적합니다.
ImageNet Dataset에서 Pretrained ResNet18 모델 평가
이제 실제로 ptorch.hub에서 pretrained된 Resnet18 모델을 가져다가, 실제 입력 데이터를 정규화도 해보고, GPU환경에서 평가모드로 모델을 우리가 가져온 페르시안 고양이 사진을 잘 분류하는지 확인해 보도록 하겠습니다.
# 필요한 PyTorch 라이브러리 불러오기 import torch import torch.nn as nn import torchvision.transforms as transforms # GPU 장치 사용 설정 use_cuda = True device = torch.device("cuda" if use_cuda else "cpu")
기본적으로 device 즉 GPU cuda환경을 셋팅해 줍니다.
from urllib.request import urlretrieve import json # 이미지넷(ImageNet)에 정의된 1,000개의 레이블(클래스) 정보 가져오기 imagenet_json, _ = urlretrieve('http://www.anishathalye.com/media/2017/07/25/imagenet.json') with open(imagenet_json) as f: imagenet_labels = json.load(f) print(imagenet_labels[18]) # 까치 preprocess = transforms.Compose([ transforms.Resize(256), # 이미지의 크기를 변경 transforms.CenterCrop(224), # 이미지의 중앙 부분을 잘라서 크기 조절 transforms.ToTensor(), # torch.Tensor 형식으로 변경 [0, 255] -> [0, 1] ]) # 이미지(그림) 출력 관련 라이브러리 import matplotlib.pyplot as plt import PIL # 특정한 경로에서 이미지를 가져와 torch.Tensor로 변환하는 함수 def image_loader(path): image = PIL.Image.open(path) # 전처리 이후에 네트워크 입력에 들어갈 이미지에 배치 목적의 차원(dimension)추가 image = preprocess(image).unsqueeze(0) return image.to(device, torch.float) # torch.Tensor 형태의 이미지를 화면에 출력하는 함수 def imshow(tensor): image = tensor.cpu().clone() image = image.squeeze(0) image = transforms.ToPILImage()(image) plt.imshow(image) plt.figure() imshow(image)
실제로 pytorch의 transforms를 통해 우리의 페르시아 고양이 사진을 256으로 resize한 다음에 CenterCrop(224), ToTensor()를 통해 224x224 짜리 PyTorch Tensor를 만들어 주는 전처리 함수를 하나 만들었습니다. 그리고 이제 우리가 이렇게 전처리 한 텐서를 pyplot와 PIL 라이브러리를 통해 출력해 보도록 하겠습니다. 참고로 preprocess(image) 한 다음에 unsqueeze(0)을 한 것은 batch를 위한 차원을 하나 늘려주기 위함입니다.

이렇게 [1, 3, 224, 224] 우리가 원하는 대로 텐서의 형태가 나온 것을 확인할 수 있습니다. 그리고 이미지를 그릴때는 cpu환경으로 detach한다음에, batch 차원을 없애고, PILImage로 바꾼다음에 보여지게 했습니다.

이제 논문에 나온데로 ResNet18 모델에 대한 입력 값 정규화를 위한 Normalize 클래스를 만들어 주었습니다.
# 입력 데이터 정규화를 위한 클래스 정의 class Normalize(nn.Module) : def __init__(self, mean, std) : super(Normalize, self).__init__() self.register_buffer('mean', torch.Tensor(mean)) self.register_buffer('std', torch.Tensor(std)) def forward(self, input): mean = self.mean.reshape(1, 3, 1, 1) std = self.std.reshape(1, 3, 1, 1) return (input - mean) / std
그리고 nn.Sequetial을 통해 모듈을 여러개를 조합했습니다. 여기서 torch.hub.load를 통해 pretrained-resnet18 모델을 가져왔습니다. 그리고 gpu환경으로 붙히고 평가 환경으로 만들었습니다.
# 공격자가 가지고 있는 torch.Tensor 형식의 이미지 데이터는 입력 정규화를 거치기 전이므로, 정규화 이후에 모델에 넣도록 설정 model = nn.Sequential( # 기본적인 ResNet18과 동일한 동작을 위하여 정규화 레이어 추가 Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), torch.hub.load('pytorch/vision:v0.6.0', 'resnet18', pretrained=True) ).to(device).eval()
# 기본적인 이미지를 실제 모델에 넣어 결과 확인 outputs = model(image) percentages = torch.nn.functional.softmax(outputs, dim=1)[0] * 100 print("< 가장 높은 확률을 가지는 클래스들 >") for i in outputs[0].topk(5)[1]: print(f"인덱스: {i.item()} / 클래스명: {imagenet_labels[i]} / 확률: {round(percentages[i].item(), 4)}")

아주 잘 예측하는 것을 볼 수 있습니다. 이제 우리가 직접 모델을 구성하고 학습하고 validation, eval과정까지 하기 위해 CIFAR-10 데이터와 MNIST 데이터를 가져와서 직접 이를 실습해보도록 하겠습니다.
CIFAR-10 Dataset 에서 ResNet18 모델 학습 및 평가
일단 필요한 모듈들을 다 불러와주겠습니다.
import torch import torch.nn as nn import torch.nn.functional as F import torch.backends.cudnn as cudnn import torch.optim as optim import os
그리고 기본적으로 우리가 논문에 있던 18-layer ResNet을 코드로 구축해 보도록 하겠습니다.
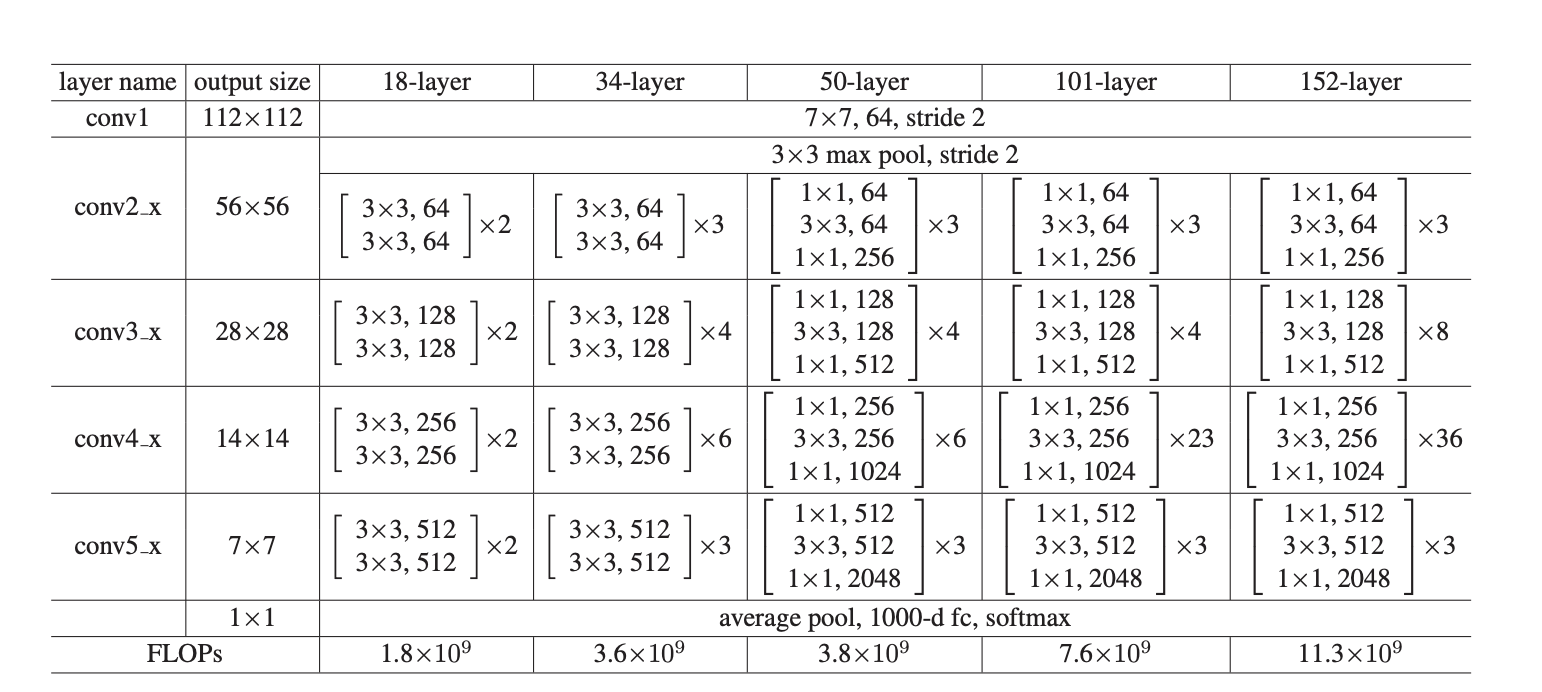
여기 나와있지는 않지만, ResNet18에서는 convolution -> BN(Batch Normalization) -> ReLU,... Average pooling, fc(fully-connected) 이런식으로 구성되어 있습니다.
from torch.nn.modules.batchnorm import BatchNorm2d # ResNet18의 BasicBlock 클래스 정의 class BasicBlock(nn.Module): def __init__(self, in_planes, planes, stride=1): super(BasicBlock, self).__init__() # 3x3 필터를 사용 (너비와 높이를 줄일 때는 stride 값 조정) self.conv1 = nn.Conv2d( in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) # 배치 정규화(batch normalization) # 3x3 필터를 사용 (패딩을 1만큼 주기 때문에 너비와 높이가 동일) self.conv2 = nn.Conv2d( planes, planes, kernel_size=3, stride=1, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.shortcut = nn.Sequential() # identity mapping인 경우 if stride != 1: # stride 가 1이 아니라면, Identity mapping이 아닌 경우이다. self.shortcut = nn.Sequential( nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes) ) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.bn2(self.conv2(out)) out += self.shortcut(x) # skip connection!!!!! out = F.relu(out) return out # ResNet 클래스 정의 ''' 충분히 Capacity가 큰 Network이기 때문에, num_classes=1000이라도 좋은 성능이 나올 수 있는 모델이라고 할 수 있다. ''' class ResNet(nn.Module): def __init__(self, block, num_blocks, num_classes=10): super(ResNet, self).__init__() self.in_planes = 64 # 64개의 3x3 커널을 사용해서 input의 dimension을 바꿔주는 작업을 해야 한다. self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(64) # basicblock으로 self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) self.linear = nn.Linear(512, num_classes) # fully-connected layerd def _make_layer(self, block, planes, num_blocks, stride): strides = [stride] + [1] * (num_blocks - 1) # 첫번째만 stride를 지정해준 만큼으로 지정 layers = [] for stride in strides: layers.append(block(self.in_planes, planes, stride)) self.in_planes = planes # 다음 레이어를 위해 채널 수를 변경해준다. return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layer1(out) out = self.layer2(out) out = self.layer3(out) out = self.layer4(out) out = F.avg_pool2d(out, 4) out = out.view(out.size(0), -1) out = self.linear(out) return out # ResNet18함수 정의 def ResNet18(): return ResNet(BasicBlock, [2, 2, 2, 2])
여기서는 ResNet의 핵심인 BasicBlock 클래스를 만들어 주었고, stride를 통해 input의 사이즈를 조절해 주는 과정을 거쳤습니다. 그리고 만약 stride가 1이 아니라면 이건 identity mapping이 아니므로 높은 차원으로 projection-mapping을 해주어야 했습니다. 이를 nn.Sequential로 표현했습니다. 그래서 forward과정을 보면, self.conv 처음에 input의 in_plaines와 planes의 차원에 따라 채널을 늘려주는 과정을 진행해주고 이를 bn1으로 감싸고 relu로 감쌌습니다. 그리고 여기서 가장 중요한 shorcut (skip connection) 또한 적용해 주었습니다. 그리고 이를 Tensor로써 반환을 해주었습니다.
ResNet 클래스에서는 이 BasicBlock을 쌓아가면서 레이어를 18개 만드는 과정이라고 할 수 있습니다. 이는 _make_layer함수가 있는데, 이는 strides배열을 통해서 2개씩 3x3 convolution층을 만듭니다. 그리고 forward층에서는 이를 다 합쳐서 avg_pool2d -> view를 [bs, weightxheight] 이렇게 2차원으로 바꿔서 fc(fully-connected) layer로 보내는 역할을 수행합니다. 그리고 ResNet18레이어에서는 논문에 있는 대로 블럭 크기를 [2, 2, 2, 2]이런식으로 주었습니다.
import torchvision import torchvision.transforms as transforms ''' RandomCrop: 이는 이미지의 일부를 무작위로 잘라내는 기법 이를 통해 이미지 내의 객체가 항상 중심에 위치하지 않을 수도 있음을 모델에게 알려주는 역할 이렇게 하면 이미지의 전체적인 부분에 대해 학습할 수 있게 되어, 특정 위치에 과적합하는 것을 방지할 수 있다. RandomHorizontalFlip: 이미지를 수평으로 뒤집는 기법, 객체가 이미지 내에서 다양한 방향으로 나타날 수 있음을 모델에게 알려주는 역할을 한다. 이렇게 하면 다양한 방향에 대해 더욱 견고하게 학습할 수 있게 된다. ''' transform_train = transforms.Compose([ transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(), transforms.ToTensor(), ]) transform_test = transforms.Compose([ transforms.ToTensor(), ]) train_dataset = torchvision.datasets.CIFAR10( root="./data", train=True, download=True, transform=transform_train) test_dataset = torchvision.datasets.CIFAR10( root="./data", train=False, download=True, transform=transform_test) train_loader = torch.utils.data.DataLoader( train_dataset, batch_size=128, shuffle=True, num_workers=4) test_loader = torch.utils.data.DataLoader( test_dataset, batch_size=100, shuffle=False, num_workers=4)
그 다음에는 이제 실제 CIFAR-10 Dataset을 불러온 다음에, Data Augmentation기법을 통해 transform_train을 만들고 이를 dataloader에 batchsize와 함꼐 넣어주었습니다. test도 마찬가지로 말이죠
device = "cuda" net = ResNet18() net = net.to(device) net = torch.nn.DataParallel(net) # 하나의 모델을 여러 GPU에 분산시켜 빠르게 학습하거나 추론을 수행하게 할 수 있다. cudnn.benchmark = True learning_rate = 0.1 file_name = 'resnet18_cifar10.pt' criterian = nn.CrossEntropyLoss() # learning_rate 0.1 -> 0.001 -> 0.0001 이렇게 줄여나가는 테크닉을 적용시켜 줄 것이다. optimizer = optim.SGD( net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.0002) def train(epoch): print("\n[ Train epoch: %d]" % epoch) net.train() train_loss = 0 correct = 0 total = 0 for batch_idx, (inputs, targets) in enumerate(train_loader): inputs, targets = inputs.to(device), targets.to(device) optimizer.zero_grad() begin_outputs = net(inputs) loss = criterian(begin_outputs, targets) # loss function (cross entropy) loss.backward() optimizer.step() # backward pass train_loss += loss.item() _, predicted = begin_outputs.max(1) total += targets.size(0) correct += predicted.eq(targets).sum().item() if batch_idx % 100 == 0: print("\nCurrent batch: ", str(batch_idx)) print("Current begin train accuracy: ", str(predicted.eq(targets).sum().item() / targets.size(0))) print("Current begin train loss: ", loss.item()) print("\nTotal begin train accuracy: ", 100. * correct / total) print("Total begin train loss: ", train_loss) def test(epoch): print("\n[ Test epoch: %d ]" % epoch) net.eval() loss = 0 correct = 0 total = 0 for batch_idx, (inputs, targets) in enumerate(test_loader): inputs, targets = inputs.to(device), targets.to(device) total += targets.size(0) outputs = net(inputs) loss += criterian(outputs, targets).item() _, predicted = outputs.max(1) correct += predicted.eq(targets).sum().item() print("\nTest accuracy: ", 100. * correct / total) print("Test average loss: ", loss / total) state = { 'net': net.state_dict() } if not os.path.isdir('checkpoint'): os.mkdir('checkpoint') torch.save(state, './checkpoint/' + file_name) print("Model Saved!") def adjust_learning_rate(optimizer, epoch): lr = learning_rate if epoch >= 100: lr /= 10 if epoch >= 150: lr /= 10 for param_group in optimizer.param_groups: param_group['lr'] = lr
그리고 이렇게 train, test 함수를 만들어서 논문에 있는 그대로 learning rate도 에폭 100마다 0.1씩 줄어들게 하였고, test마다 모델을 svae하도록 했습니다.
for epoch in range(0, 20): adjust_learning_rate(optimizer, epoch) train(epoch) test(epoch)
이를 위과정을 통해 실제로 에폭을 돌려보면 아래와 같게 나옵니다.
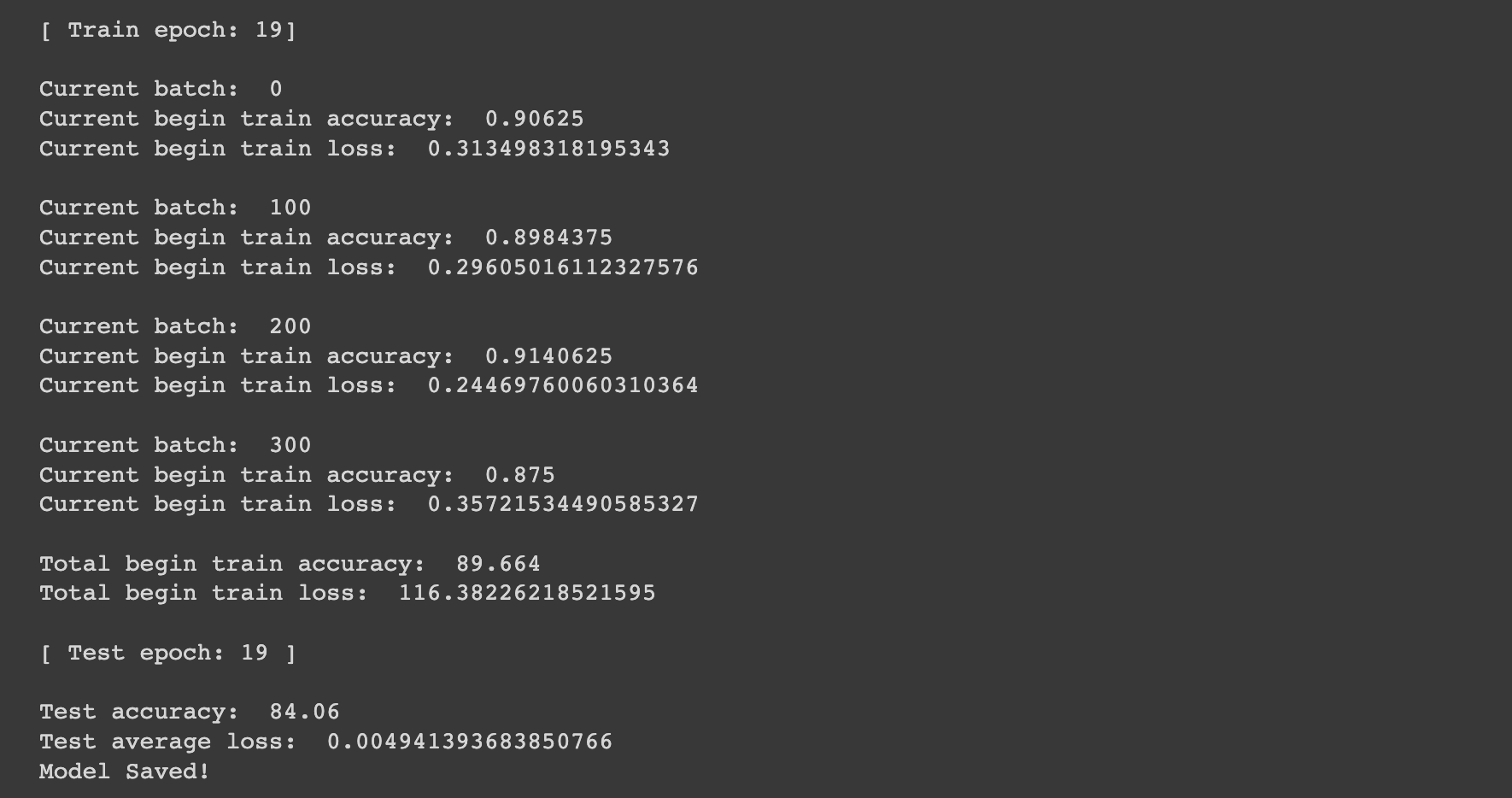
총 test accuracy는 84.06%정도가 나오며, loss값도 위와 같습니다. 당연히 train error rate도 낮아지는 것을 볼 수 있습니다.
'AIML > 딥러닝 최신 트렌드 알고리즘' 카테고리의 다른 글
| [딥러닝 - PyTorch] - TORCH.NN 이 무엇일까? (0) | 2023.07.03 |
|---|---|
| [딥러닝 기초] - ResNET을 이해하기 위한 CNN 개요 (0) | 2023.06.30 |
| [딥러닝 논문 리뷰 - PRMI lab] - 배치 정규화(Batch Normalization) + 보편적 근사 정리(Universal Approximation Theorem) (0) | 2023.06.29 |
| [딥러닝 최신 트렌드 알고리즘] - (Practice Session with Pytorch) Implement Feedforward Network (0) | 2023.06.27 |
| [딥러닝 최신 트렌드 알고리즘] - Feedforward Network (0) | 2023.06.26 |