
sequential Search
sequential search는 리스트 레코드를 left-to-right order로 비교하면서 하나의 값을 찾는 것입니다.
/sequentialSort.c
#include <stdio.h> #include <stdlib.h> int seqSearch(int a[], int k, int n) { int i; for (i = 1; i < n && a[i] != k; i++) ; if (i >= n) return -1; return i; } int main(void) { int sortArr[100] = {0}; int count = 0; FILE *fp_read = fopen("sort.txt", "r"); while ((fscanf(fp_read, "%d", sortArr + count) != EOF)) { count++; } for (int i = 0; i < count; i++) printf("%d ", sortArr[i]); putchar('\n'); printf("[ 4 ] is in index %d\n", seqSearch(sortArr, 4, count)); return 0; } // 3 2 4 1 9 8 // [ 4 ] is in index 2
- 이는 평균적으로 (n + 1) / 2번의 comparison을 거치므로 O(n)의 시간 복잡도를 갖습니다.
- 하지만 sequential list에서 binary search의 시간복잡도는 O(log n)입니다.
Sorting
sorting은 computing을 배울 때 엄청난 중요한 개념이 됩니다.
- optimization, graph theory, job scheduling에 사용됩니다.
- 불행하게도 어느 하나의 sorting method도 모든 applications에 최적화 된 것은 찾아 볼 수 없습니다.
- 각 상황마다 최적화 된 sorting method가 존재한다는 애기입니다.
Stable Sort
중복된 키를 순서대로 정렬하는 정렬 알고리즘을 뜻합니다.
예를 들어, 다음과 같은 list가 있다고 해 봅시다.
list = [1, 7, 3, 5, 3, 7, 9]
이 리스트에서는 7이 2번 나옵니다. 구분을 위해서 ()을 이용해 (1), 뒤는 (2)를 표시하면
list = [1, 7(1), 3, 5, 4, 7(2), 9]
와 같게 됩니다.
이 때 리스트를 정렬 했을 때
- list = [1, 3, 4, 5, 7(1), 7(2), 9]
- list = [1, 3, 4, 5, 7(2), 7(1), 9]
(1)처럼 나오면 안정(stable) 정렬, (2)처럼 나오면 불안정(Unstable)정렬 이라고 합니다.
즉, 정렬을 했을 때 중복된 값들의 순서가 변하지 않으면 안정(Stable) 정렬, 변하면 불안정(Unstable)정렬 인 것입니다.
Stable Sorting Algorithm
- Inserion Sort
- Merge Sort
- Bubble Sort
- Counting Sort
Unstable Sorting Algorithm
- Selection Sort
- Heap Sort
- Shell Sort
- Quick Sort
Insertion Sort
#include <stdio.h> #include <stdlib.h> #include <string.h> #define ARR_SIZE 100 int seqSearch(int a[], int k, int n) { int i; for (i = 1; i < n && a[i] != k; i++) ; if (i >= n) return -1; return i; } int swap(int *a, int *b) { int temp; temp = *a; *a = *b; *b = temp; } void insertionSort(int a[], int n) { /* sort a[0:n - 1] into nondecreasing order( 오름 차순 ) */ int i, j, key; for (i = 1; i < n; i++) { key = a[i]; // 현재 정렬된 배열은 i - 1까지 이므로 i - 1번째부터 역순으로 조사합니다. for (j = i - 1; j >= 0 && a[j] > key; j--) a[j + 1] = a[j]; a[j + 1] = key; } } void printArr(int a[], int n) { for (int i = 0; i < n; i++) printf("%d ", a[i]); putchar('\n'); } int main(void) { int sortArr[ARR_SIZE] = {0}; int count = 0; FILE *fp_read = fopen("sort.txt", "r"); while ((fscanf(fp_read, "%d", sortArr + count) != EOF)) { count++; } printf("original array: "); printArr(sortArr, count); // printf("[ 4 ] is in index %d\n", seqSearch(sortArr, 4, count)); int sortArr_2[ARR_SIZE]; memcpy(sortArr_2, sortArr, sizeof(int) * ARR_SIZE); printf("insertion sort: "); insertionSort(sortArr_2, count); printArr(sortArr_2, count); return 0; } // original array: 3 2 4 1 9 8 // insertion sort: 1 2 3 4 8 9
insertion sort의 핵심은 순서대로 정렬된 배열의 사이즈를 1씩 증가시키는데에 있습니다. 초기에 첫번째 배열은 정렬되어 있다고 치고 for문을 2번 돌려 주면 됩니다. 간단한 순서도는 다음과 같습니다
( 배열의 정렬 인덱스는 다를 수 있습니다. )
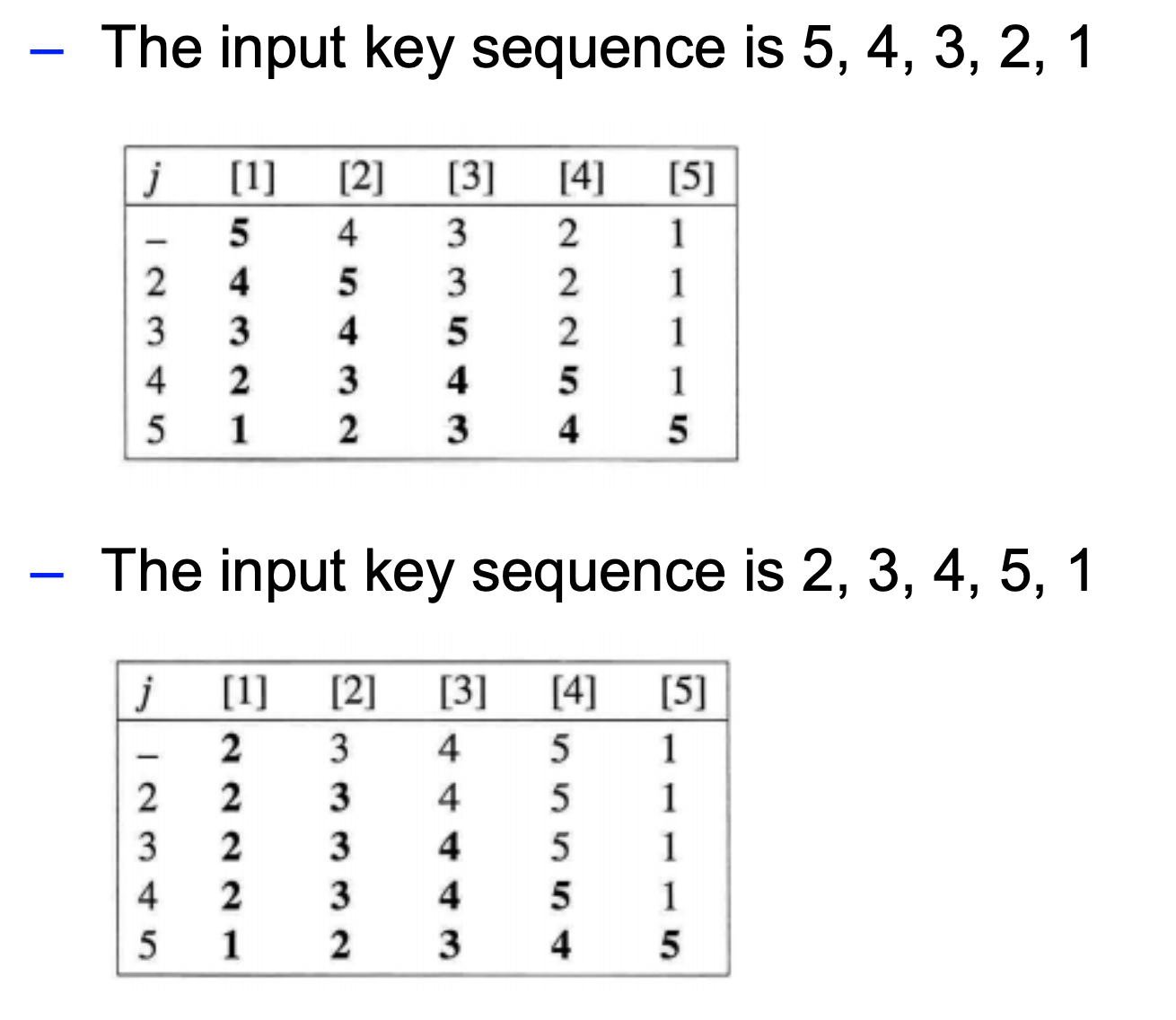
이러한 insertion sort는 stable sort중 하나 입니다. 그리고 small size list를 정렬 하는데 매우 유리합니다.
정리
- 장점
- 안정한 정렬 방법
- 레코드의 수가 적을 경우 알고리즘 자체가 매우 간단하므로 다른 복잡한 정렬 방법보다 유리할 수 있다.
- 대부분의 레코드가 이미 정렬되어 있는 경우에 매우 효율적일 수 있다.
- 단점
- 비교적 많은 레코드들의 이동을 포함한다.
- 레코드 수가 많고 레코드 크기가 클 경우에 적합하지 않다.
복잡도
- 최선의 경우
- 비교 횟수
- 이동 없이 1번의 비교만 이루어 집니다.
- 외부 루프 (n - 1)번
- Best T(n) = On(n)
- 비교 횟수
- 최악의 경우 ( 입력 자료가 역순일 경우 )
- 비교 횟수
- 외부 루프 안의 각 반복마다 i번의 비교 수행
- 외부 루프 (n - 1) + (n - 2) + ... + 2+ 1 = n(n - 1)/2 = O(n^2)
- Worst T(n) = O(n^2)
- 비교 횟수
'School > DataStructure' 카테고리의 다른 글
| Data Structure - Sorting ( Merge Sort ) (0) | 2022.05.28 |
|---|---|
| Data Structure - Sorting ( Quick Sort ) (0) | 2022.05.28 |
| Data Structure - Graph ( AOV, AOE Network ) (0) | 2022.05.27 |
| Data Structure - Graph ( Floyd-Warshall Algorithm && Transitive Closure ) (0) | 2022.05.27 |
| Data Structure - Graph ( Dijkstra && Bellman and Ford Algorithm ) (0) | 2022.05.27 |