School/DataStructure

Data Structure - Hashing ( Introduce )
Dictionary 딕셔너리의 search, insert, delete는 다음과 같은 시간 복잡도를 가지게 됩니다. array에서 O(n)의 시간복잡도 balance binary search tree 에서 O(log n) 하지만 우리는 hasing이라는 개념을 정의해야 합니다. 이 hashing은 위에서 O(n), O(logn)의 시간복잡도를 가졌던 연산이 O(1)로 획기적으로 죽어들게 하는 자료구조 입니다. Hashing technique에는 static hashing과 dynamic hashing이 존재합니다. Hash Tables static hashing에서는 dictinary의 쌍들이 table에 저장됩니다. 여기서 이것을 ht ( hash table )이라고 부릅니다. 이러한 hash tabl..
Data Structure - Sorting ( Bubble, Selection Sort )
Bubble Sort 서로 인접한 두 원소를 검사하여 정렬하는 알고리즘입니다. 인접한 2개의 레코드를 비교하여 크기가 순서대로 되어 있지 않으면 서로 교환하는 방법입니다. 선택 정렬과 기본 개념이 유사합니다. 버블 정렬의 기본적인 과정을 서술하겠습니다. 버블 정렬은 첫 번쨰 자료와 두 번째 자료를, 두 번쨰 자료와 세번째 자료를, 세 번째와 네 번째를, ...이런 식으로 (마지막 - 1)번쨰 자료와 마지막 자료를 비교하여 교환하면서 자료를 정렬합니다. 1회전을 수행하고 나면 가장 큰 자료가 맨 뒤로 이동하므로 2회전에서는 맨 끝에 있는 자료는 정렬에서 제외되고, 2회전을 수행하고 나면 끝에서 두 번째 자료까지는 정렬에서 제외됩니다. 이렇게 정렬을 1회전 수행할 때마다 정렬에서 제외되는 데이터가 하나씩 늘..

Data Structure - Sorting ( Several Keys && Radix Sort && External Sort )
MSD vs LSD 모든 예제는 A deck of card에서 시작해 보도록 하겠습니다. 이 카드를 순서대로 정렬하는데 쓰이는 정렬에는 2가지 방법이 있습니다. (Key -> (기준이 되는) 가 여러개) Most-significat-digit-first(MSD) sort입니다. 이는 K1에 대해서 먼저 정렬하고 -> K2에 대해서 정렬을 하는 방법입니다. unordered list (170, 45, 65, 60, 802, 4, 2, 66) [045, 065, 060, 004, 002, 066], [170], [802] [004, 002], [045], [065, 060, 066], [170], [802] 002 004 045 060 065 066 170 802 < LSD sort ..
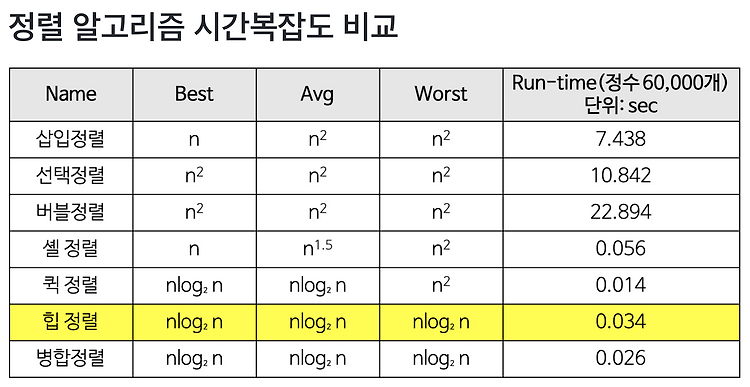
Data Structure - Sorting ( Heap Sort )
Heap Sort 최대 힙 트리나 최소 힙 트리를 구성해 정렬을 하는 방법입니다. 내림차순 정렬을 위해서는 최대 힙을 구성하고 오름차순 정렬을 위해서는 최소 힙을 구성하면 됩니다. 과정 정렬해야 할 n개의 요소들로 최대 힙(완전 이진 트리 형태)를 만듭니다. 그 다음에 한 번에 하나씩 요소를 힙에서 꺼내서 배열의 뒤부터 저장하면 됩니다. 삭제되는 요소들(최댓값부터 삭제)는 값이 감소되는 순서로 정렬되게 됩니다. max Heap을 삭제하고 추가하는 과정은 이미 안다고 가정하고 코드를 바로 짜 보도록 하겠습니다. 아래 코드는 Max Heap을 구현한 다음에 최댓값 부터 pop해 가면서 배열의 뒷 쪽 부터 삽입해 가는 코드라고 보시면 됩니다. /heap_sort.c #include #include #inclu..