![[ 딥러닝 - 모델구현 ] - VGG11/16/19 Net](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbp6Kfl%2FbtsmO4AGtEj%2FLUR8zZ3TM6VJV1IwXw4yxK%2Fimg.png)
이번에는 VGG Net을 실제로 PyTorch로 구현해 보고 성능까지 검증해보도록 하겠습니다.
from google.colab import drive import os import sys drive.flush_and_unmount() drive.mount('/content/drive/') sys.path.append("/content/drive/MyDrive/DeepLearning")
먼저 위와같이 colab과 google 드라이브를 마운트 해줍니다.
''' 필요 라이브러리들을 불러온다. ''' import copy import numpy as np import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import torch.utils.data as data import torchvision import torchvision.transforms as transforms import torchvision.datasets as Datasets device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
그리고 관련 라이브러리들을 싹다 불러옵니다.
class VGG(nn.Module): def __init__(self, features, output_dim): super().__init__() self.features = features self.avgpool = nn.AdaptiveAvgPool2d(7) # 입력 텐서가 7x7로 평균 폴링된다 (폴링 영역 크기, 스트라이드는 자동계산된다. self.classifier = nn.Sequential( # fully-connected 레이어를 정의한다. nn.Linear(512*7*7, 4096), nn.ReLU(inplace=True), # 메모리를 아까기 위해 inplace로 연산을 수행한다. nn.Dropout(0.5), nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Dropout(0.5), nn.Linear(4096, output_dim), # 출력층 정의 ) def forward(self, x): x = self.features(x) x = self.avgpool(x) h = x.view(x.shape[0], -1) # 미니배치 빼고 flattening을 해서 fc에 넣을 준비를 함 x = self.classifier(h) return x, h
그 후, 논문에 있는 그대로를 nn.Module을 통해 옮깁니다. forward pass에서는 최종적으로 feature -> avgpool -> fc -> softmax 이런식으로 거쳐가게 될 것입니다. 그 다음은 모델 정의입니다.
''' 여기서 숫자(output channel)은 Conv2d를 수행하라는 의미이다. -> 출력채널은 다음 레이어의 입력 채널(input channel)이 된다. M은 최대 폴링(max pooling)을 수행하라는 것이다. ''' vgg11_config = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'] vgg13_config = [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'] # 13(Conv) + 3(Pooling) = 16 = VGG16 vgg16_config = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'] vgg19_config = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']
주석 그대로입니다. 저희는 간단히 vgg11_config만을 활용해서 실습할 것입니다.
def get_vgg_layers(config, batch_norm): layers = [] in_channels = 3 for c in config: assert c == 'M'or isinstance(c, int) # assert문으로 값의 무결성을 체크한다. if c == 'M': layers += [nn.MaxPool2d(kernel_size=2)] # maxpolling의 kernel-size는 논문에 2x2라고 되어 있음 else: conv2d = nn.Conv2d(in_channels, c, kernel_size=3, padding=1) # kernel_size=3x3, zerro_pading, in, out channel 정의 if batch_norm: # Batch Normalization(BN) 을 적용할 경우 BN + ReLU 적용 layers += [conv2d, nn.BatchNorm2d(c), nn.ReLU(inplace=True)] else: layers += [conv2d, nn.ReLU(inplace=True)] in_channels = c return nn.Sequential(*layers) # 네트워크의 모든 계층을 반환한다.
그 다음 vgg_layer를 위 config를 통해 batch_norm 인수와 함께 생성할 수 있는 함수를 정의합니다.
vgg11_layers = get_vgg_layers(vgg11_config, batch_norm=True) print(vgg11_layers)

우리가 원하던 대로 피처가 잘 생성된 것을 볼 수 있습니다. 그 다음은 이제 모델 전체에 대한 네트워크를 확인해 보도록 하겠습니다.
OUTPUT_DIM = 2 # 개와 고양이 두 개의 클래스를 사용 model = VGG(vgg11_layers, OUTPUT_DIM) print(model)
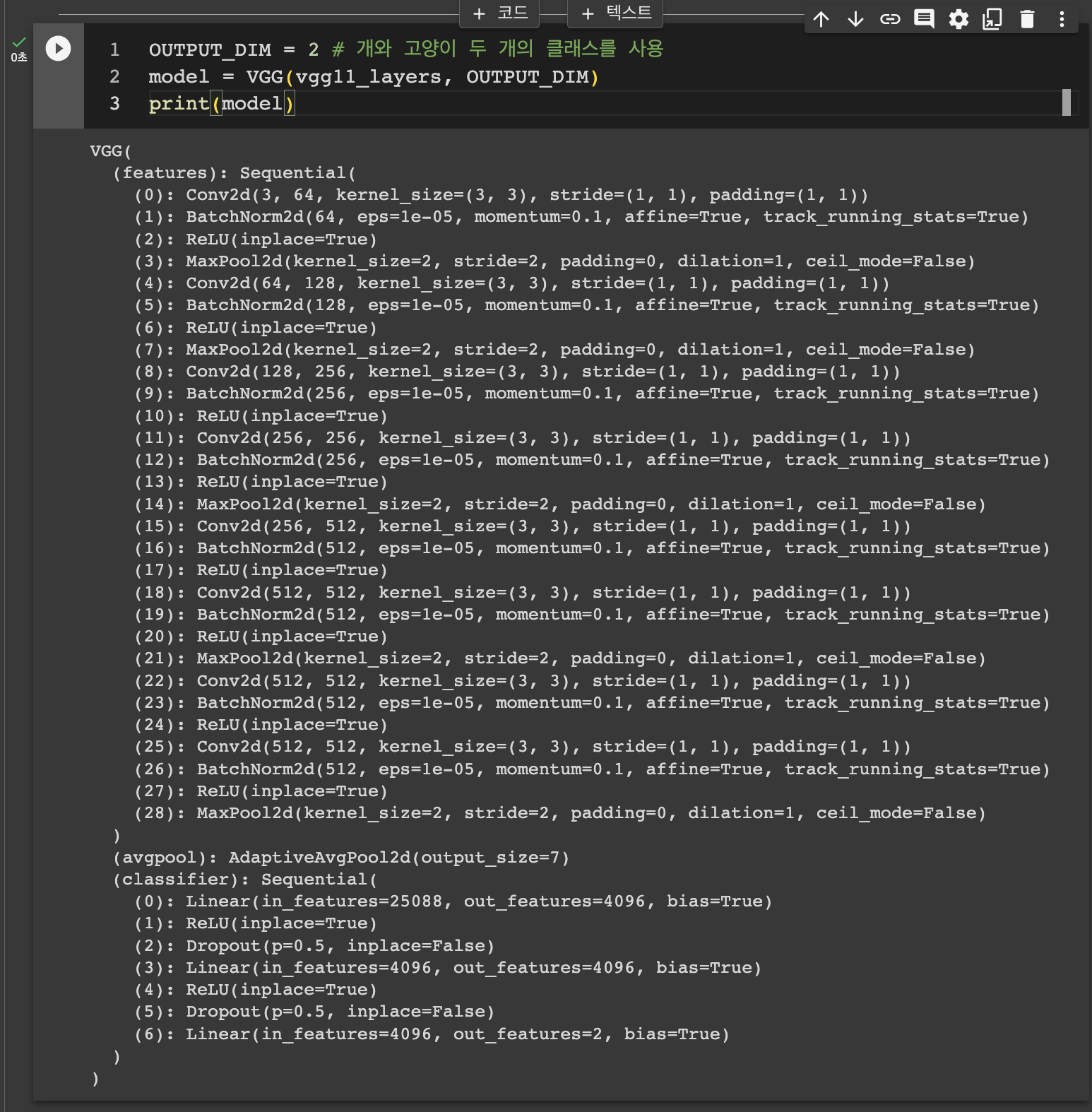
VGG11이 훌륭하게 구성되었습니다. 그 외에도 Pre-trained VGG11 모델을 torchvision에서 제공합니다.
import torchvision.models as models ''' vgg11_bn은 VGG11 기본 모델에 배치 정규화가 적용된 모델을 사용하겠다는 의미 -> pretrained=True (사전 학습된 모델을 사용하겠다.) ''' pretrained_model = models.vgg11_bn(pretrained=True) print(pretrained_model)
이를 사용해도 좋지만, 우리는 우리가 정의한 모델을 가지고, 학습을 시켜서 직접 테스트 까지 해보도록 하겠습니다.
train_transforms = transforms.Compose([ transforms.Resize((256, 256)), transforms.RandomRotation(5), transforms.RandomHorizontalFlip(0.5), transforms.ToTensor(), # 각 채널별로 이미지의 픽셀 값을 정규화하는 것이다. ex) Red -> (pixel_value - 0.485) / 0.229 # ImageNet 데이터셋으로 사전학습된 모델을 사용할 경우 이러한 정규화를 사용하는 것이 일반적 transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) test_transforms = transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])
먼저 ImageNet 데이터를 위한 전처리를 해줍니다. istropically-rescale, random rotation, horizontal flip, normalize를 해줍니다. 이는 train에서 입력의 일반화 성능을 높이고자 하는 것입니다.
train_path = './data/catanddog/train' test_path = './data/catanddog/test' train_dataset = torchvision.datasets.ImageFolder( train_path, transform=train_transforms ) test_dataset = torchvision.datasets.ImageFolder( test_path, transform=test_transforms ) print(len(train_dataset)), print(len(test_dataset))

그리고 ImageFolder를 이용해서 모델 학습에 필요한 데이터 셋을 가져옵니다. 우리가 정의한 train_dataset, test_dataset의 크기는 위와 같다는걸 확인할 수 있습니다. 그 다음으로는 훈련과 검증 데이터를 분할해보겠습니다.
VALID_RATIO = 0.9 n_train_examples = int(len(train_dataset) * VALID_RATIO) n_valid_examples = len(train_dataset) - n_train_examples train_data, valid_data =\ data.random_split(train_dataset, [n_train_examples, n_valid_examples])
그 다음으로는 검증 데이터 전처리를 해주겠습니다.
valid_data = copy.deepcopy(valid_data) valid_data.dataset.transform = test_transforms

그 다음에는 훈련, 검증, 테스트로 분류한 데이터의 길이를 확인해보았습니다. 이제는 이를 가지고 Dataloader를 batch_size를 통해 정의합니다.
BATCH_SIZE = 100 # 훈련 데이터만 임의로 섞어서 가져와야 한다. train_iterator = data.DataLoader(train_data, shuffle=True, batch_size=BATCH_SIZE) valid_iterator = data.DataLoader(valid_data, batch_size=BATCH_SIZE) test_iterator = data.DataLoader(test_dataset, batch_size=BATCH_SIZE)
그 다음으로는 이제 옵티마이저와 손실함수를 정의합니다.
optimizer = optim.Adam(model.parameters(), lr=1e-7) criterion = nn.CrossEntropyLoss() model = model.to(device) criterion = criterion.to(device) print(optimizer)
옵티마이저로는 논문에 나온 대로 Adam, 손실함수로는 다중 분류문제를 진행할 것이므로, CrossEntropyLoss를 사용해 주도록 하겠습니다. 그리고 model, criterion을 GPU에 부착해줍니다!
def calculate_accuracy(y_pred, y): top_pred = y_pred.argmax(1, keepdim=True) # 입력된 텐서에서 각 행을 따라 max의 인덱스를 반환 # 이는 y에 대한 텐서를 top_pred.size()으로 보겠다는 의미 -> 비교한다음에 개수를 센다! correct = top_pred.eq(y.view_as(top_pred)).sum() acc = correct.float() / y.shape[0] return acc
그리고 위처럼 모델의 정확도를 측정하기 위한 함수를 정의해줍니다.
def train(model, iterator, optimizer, criterion, device): epoch_loss = 0 epoch_acc = 0 for (x, y) in iterator: x = x.to(device) y = y.to(device) model.train() optimizer.zero_grad() y_pred, _ = model(x) # forward pass loss = criterion(y_pred, y) # cross entropy loss acc = calculate_accuracy(y_pred, y) loss.backward() optimizer.step() epoch_loss += loss.item() epoch_acc += acc.item() return epoch_loss / len(iterator), epoch_acc / len(iterator)
그리고 훈련 데이터 셋을 이용할 모델 학습 함수를 저으이해 주었습니다. 각 epoch 마다의 loss, acc를 반환해주게 했습니다. 검증도 비슷하게 짜주었습니다.
def evaluate(model, iterator, criterion, device): epoch_loss = 0 epoch_acc = 0 model.eval() with torch.no_grad(): for (x, y) in iterator: x = x.to(device) y = y.to(device) y_pred, _ = model(x) loss = criterion(y_pred, y) acc = calculate_accuracy(y_pred, y) epoch_loss += loss.item() epoch_acc += acc.item() return epoch_loss / len(iterator), epoch_acc / len(iterator)
여기서는 당연하지만 가중치 갱신을 하면 안됩니다. torch.no_grad를 이용해 주었습니다. 그리고 이제 학습 시간을 측정해보기 위해 함수를 하나 정의해주었습니다.
import time def epoch_time(start_time, end_time): elapsed_time = end_time - start_time elapsed_mins = int(elapsed_time / 60) elapsed_secs = int(elapsed_time - (elapsed_mins * 60)) return elapsed_mins, elapsed_secs
이제 모델 학습 시작합니다!
import torch, gc gc.collect() torch.cuda.empty_cache()
torch gc 초기화 한번 해주고~
EPOCHS = 5 best_valid_loss = float('inf') for epoch in range(EPOCHS): start_time = time.monotonic() train_loss, train_acc = train(model, train_iterator, optimizer, criterion, device) valid_loss, valid_acc = evaluate(model, valid_iterator, criterion, device) ''' valid_loss가 가장 작은 값을 구하고 그 상태의 모델을 VGG-model.pt 이름으로 저장한다. ''' if valid_loss < best_valid_loss: best_valid_loss = valid_loss torch.save(model.state_dict(), './data/VGG-model.pt') end_time = time.monotonic() epoch_mins, epoch_secs = epoch_time(start_time, end_time) print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s') print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%') print(f'\t Valid. Loss: {valid_loss:.3f} | Valid. Acc: {valid_acc*100:.2f}%')
총 5번의 에폭을 돌면서 우리가 필요한 값들을 찍어보았습니다. vgg11이고 colab의 GPU를 사용중이기 때문에 학습하는데 시간이 많이 안걸릴 것으로 예상했습니다.
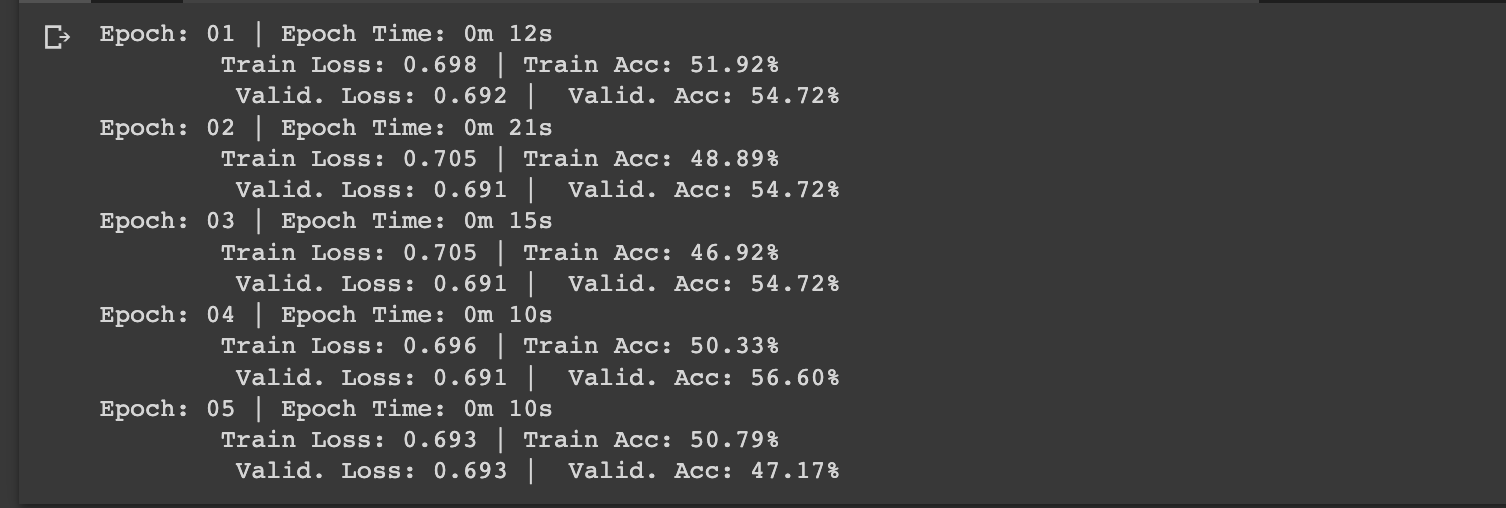
위 코드에서 best_valid_loss인 시점의 모델을 ./data/VGG_model.pt의 경로에 저장했습니다. 이제 이를 통해 테스트 데이터 셋에 대한 성능을 측정해보겠습니다.
model.load_state_dict(torch.load('./data/VGG-model.pt')) test_loss, test_acc = evaluate(model, test_iterator, criterion, device) print(f'Test Loss: ${test_loss: .3f} | Test Acc: {test_acc*100: .2f}%')

성능이 썩 그리 좋지는 못하네요,,, 아마 데이터 개수가 너무 적어서 그런거 같습니다. 이제는 직접 테스트 데이터 셋을 이용한 모델의 예측 결과를 알아보기 위한 함수를 정의해주겠습니다.
def get_prediction(model, iterator): model.eval() images = [] labels = [] probs = [] with torch.no_grad(): for (x, y) in iterator: x = x.to(device) y_pred, _ = model(x) y_prob = F.softmax(y_pred, dim=1) top_pred = y_prob.argmax(1, keepdim=True) images.append(x.cpu()) # detach한다. labels.append(y.cpu()) probs.append(y_prob.cpu()) images = torch.cat(images, dim=0) labels = torch.cat(labels, dim=0) probs = torch.cat(probs, dim=0) return images, labels, probs
테스트를 돌면서, image, labels, probs를 torch.cat을 이용해서 붙여주었습니다. 그리고 우리는 예측 중에서 정확하게 예측한 것을 추출해보겠습니다.
images, labels, probs = get_prediction(model, test_iterator) pred_labels = torch.argmax(probs, 1) corrects = torch.eq(labels, pred_labels) # 예측과 정답이 같은지 비교 correct_examples = [] for image, label, prob, correct in zip(images, labels, probs, corrects): if correct: correct_examples.append((image, label, prob)) correct_examples.sort(reverse=True, key=lambda x: torch.max(x[2], dim=0).values) print(correct_examples[0], correct_examples[0][2].shape)
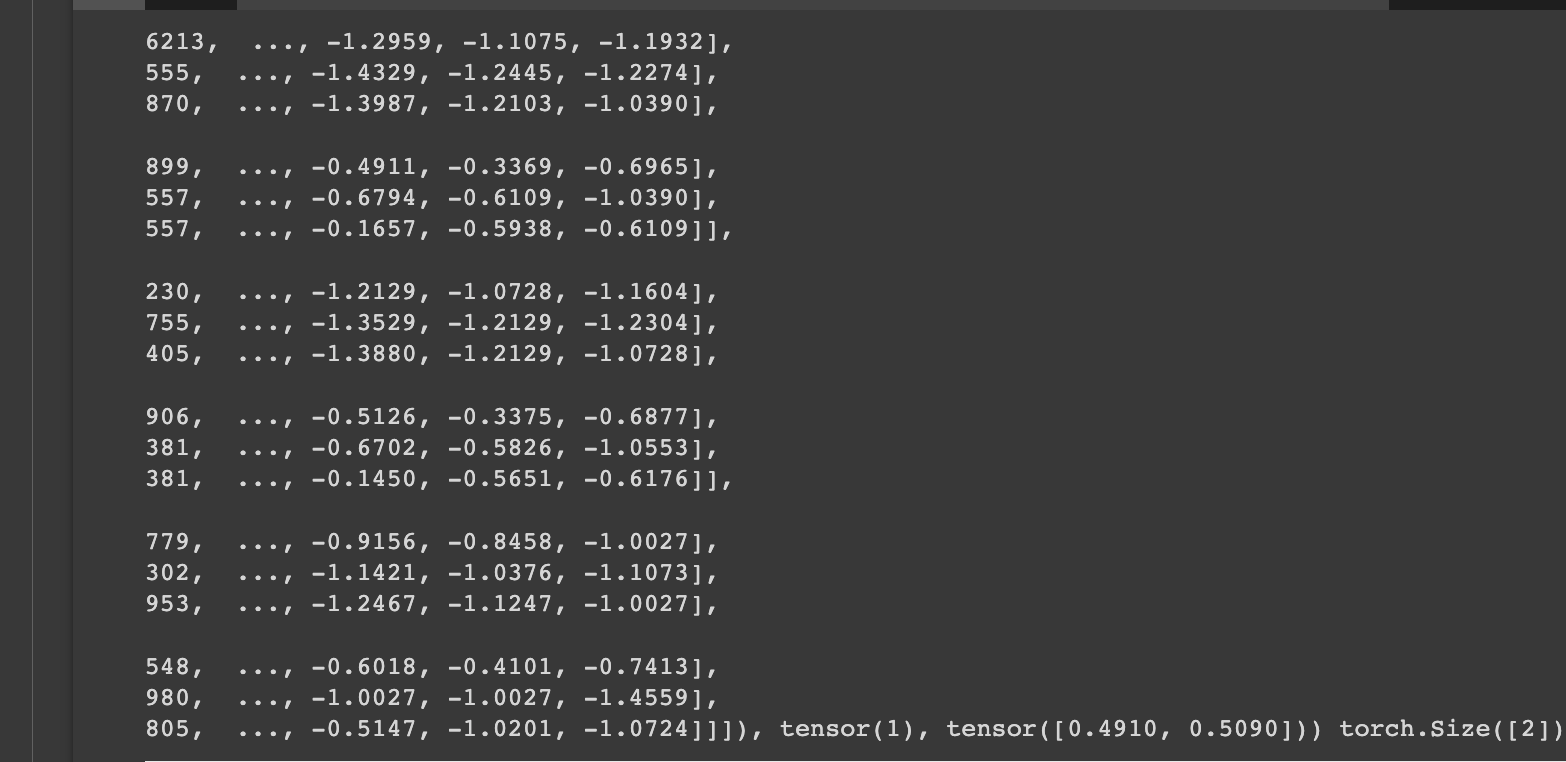
대충 우리가 원하는대로 결과가 나왔네요, 위 결과는, (image, label, prob) 이런 식으로 맞은 데이터 중에 첫번째만 가져온 것입니다. 그리고 우리는 dog or cat으로 분류할 것인데, 강아지(1), 고양이(2) 이 순서대로 뽑아내고 싶어서 sort를 통해 정렬도 해주었습니다.
그리고 이미지를 matplotlib로 그려볼거기 때문에, 이미지 출력을 위한 전처리 과정도 진행해 주어야 합니다.
def normalize_image(image): image_min = image.min() image_max = image.max() image.clamp_(min=image_min, max=image_max) image.add_(-image_min).div_(image_max - image_min + 1e-5) return image
우리가 위에서 이미지에 대한 전처리를 transform을 통해 일반화 성능을 높이기 위해 많이 바꿨었습니다. 본래 이미지를 출력하기 위해서, 위와같이 정규화를 진행해주었습니다. 각 픽셀 값을 다시 [0, 1]로 재설정해주었습니다.
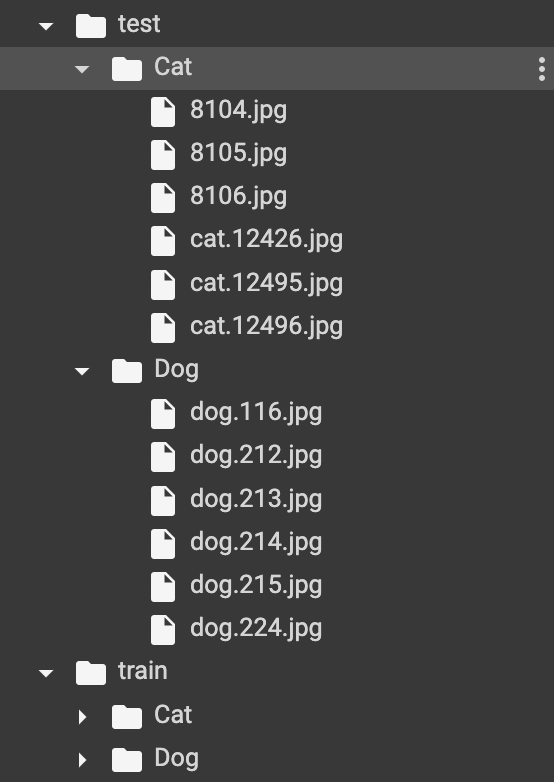
위는 우리가 ImageFolder를 통해 불러온 폴더의 구조입니다! 언급을 안한거 같아서요
import matplotlib.pyplot as plt def plot_most_correct(correct, classes, n_images, normalize=True): rows = int(np.sqrt(n_images)) cols = int(np.sqrt(n_images)) fig = plt.figure(figsize=(25, 10)) for i in range(rows*cols): ax = fig.add_subplot(rows, cols, i+1) # 출력하는 그래프 개수만큼 subplot을 만들어 준다. image, true_label, probs = correct[i] image = image.permute(1, 2, 0) true_prob = probs[true_label] correct_prob, correct_label = torch.max(probs, dim=0) true_class = classes[true_label] correct_class = classes[correct_label] if normalize: image = normalize_image(image) ax.imshow(image.cpu().numpy()) ax.set_title(f'true label: {true_class} ({true_prob: .3f})\n' \ f'pre label: {correct_class} ({correct_prob: .3f})') ax.axis('off') fig.subplots_adjust(hspace=0.4)
그 다음 우리가 추출한 correct_examples을 가지고 간단히 그림을 그려보겠습니다. 여기에는 true_class와 true_prob를 통해 실제 정답에 대한 정보, correct_class, correct_prob을 통해 우리가 추측한 정보를와 해당하는 정규화한 그림을 뽑아냈습니다.

생각보다 너무 성능이 좋지 않았습니다. 이 또한 데이터 셋을 늘려주면 성능이 늘어날 것으로 기대합니다.