![[딥러닝 - 논문 리뷰 PRMI Lab] - Going Deeper with Convolutions (CVPR 2015) - GoogLeNet](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcMaalM%2FbtsmPAl2OOg%2Fwo1Csu4k0HC8Td1uizerC0%2Fimg.png)
이번에는 ILSVRC 2014에서 이전에 본 VGGNet을 제치고 1등을 차지한 GoogLeNet을 다루어 보려고 합니다. 그리고 이름이 좀 특이했는데, 이는 연구팀 대부분이 Google 직원이여서 아마 이름을 GoogLeNet이라고 하지 않았나 유추해봅니다.
이 모델은 1x1 Conv layer의 사용이나 depth를 늘려 모델의 성능을 개선시키는 등 VGGNet과 유사한 점이 꽤 많습니다. 하지만 GoogLeNet은 아주 독특한 구조를 가지고 있는데, 그 이름은 그 유명한 인셉션(Inception) 입니다. 이제부터 Google팀에서 왜 이 구조의 이름을 인셉션이라 지었는지, VGGNet과는 어떤 점에서 다른지 알아보겠습니다.

초록에서는 GoogLeNet의 특징에 대해 간략히 나타내고 있습니다. 이의 가장 주요한 특징은 연산을 하는 데 소모되는 자원의 사용 효율이 개선되었다는 점입니다. 즉, 정교한 설계 덕에 네트워크의 depth와 width를 늘려도 연산량이 증가하지 않고 유지된다는 점입니다 (qudratic하게 변하지 않음). 이때 Google팀은 Hebbian principle과 multi-scale processing을 적용하였고, 이 구조를 GoogLeNet이라고 합니다.
그래고 소개부분에서는, GoogLeNet이 나오게 된 배경, 그리고 설계 주안점 등이 소개되고 있습니다. Google 팀에서는 CNN분야의 큰 발전에서 단지 더 좋은 하드웨어의 성능, 더 큰 dataset, 더 큰 모델이라기 보다는 새로운 아이디어와 알고리즘, 그리고 개선된 신경망 구조를 사용했습니다.
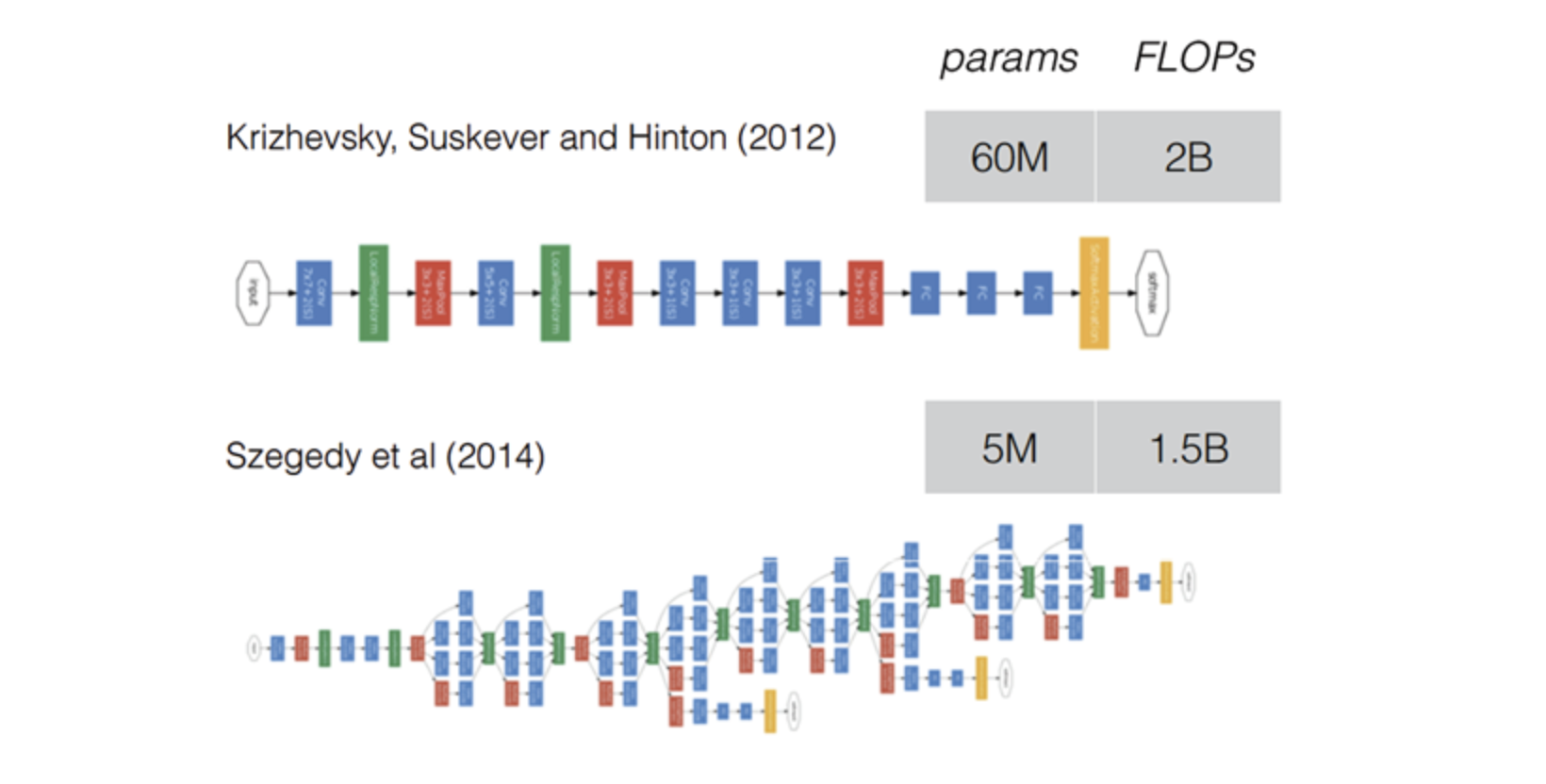
위 그림만 봐도 이전에 소개된 AlexNet보다 파라미터 수가 12배가 더 적음에도 불구하고 훨씬 더 정확했다고 합니다. 이러한 개선은 마치 R-CNN처럼 deep 한 구조와 클래식한 컴퓨터 비전의 시너지 덕분이라고 말합니다.
그리고 이는 Mobile 및 Embedded 환경에서 전력과 메모리 사용량 관점에서 효율적인 알고리즘의 중요성이 대두되고 있기에, 이 논문에서는 모델이 엄격한 고정된 구조를 가지는 것보다 유연한 구조를 가지게끔 하였다고 합니다. 추론 시간에는 1.5billion 이하의 연산량만을 수행하도록 설계하여, 현실세계에 적합하게 설계했다고 합니다.
그리고 GoogLeNet의 Inception이란 이름은 Network In Network(NIN)이라는 논문에서 소개되었으며, 더 정확하게는 인셉션 영화의 대사인 "we need to go deeper"에서 착안했다고 합니다. 여기서 deep이라는 단어의 의미는 이 논문에서 2가지 의미를 가집니다.
- Inception module의 형태로 새로운 차원의 구조 도입
- 네트워크의 깊이가 단순히 증가하였다는 의미

그 다음으로는 관련된 작업들입니다. LeNet-5를 시작으로 CNN은 거의 일반적인 표준 구조를 가지게 되었습니다. Conv ->... -> 1개 이상의 FC 이런식의 구조말이죠. 또한 ImageNet과 같이 대용량 데이터에서의 요즘 트렌드는 layer의 수와 사이즈를 늘리고, 오버 피팅을 해결하기 위해 dropout을 적용한다는 점입니다. 따라서 GoogLeNet에서도 이를 똑같이 사용했습니다.
그 다음으로 Network-in-Network의 논문 내용이 나옵니다. 이는 GoogLeNet에서 가장 많은 영향을 끼친 논문입니다. 먼저 해당 논문은 신경망의 표현력을 높이기 위해 제안된 접근법인데, 1x1 Conv layer가 추가되며, ReLU가 뒤따릅니다. 이 떄 1x1 Conv layer는 두가지 목적으로 사용됩니다.
- 병목현상을 제거하기 위한 차원 축소
- 네트워크 크기 제한
그래서 Network-in-Network에서의 1x1 Conv layer의 사용을 간단히 알아보면
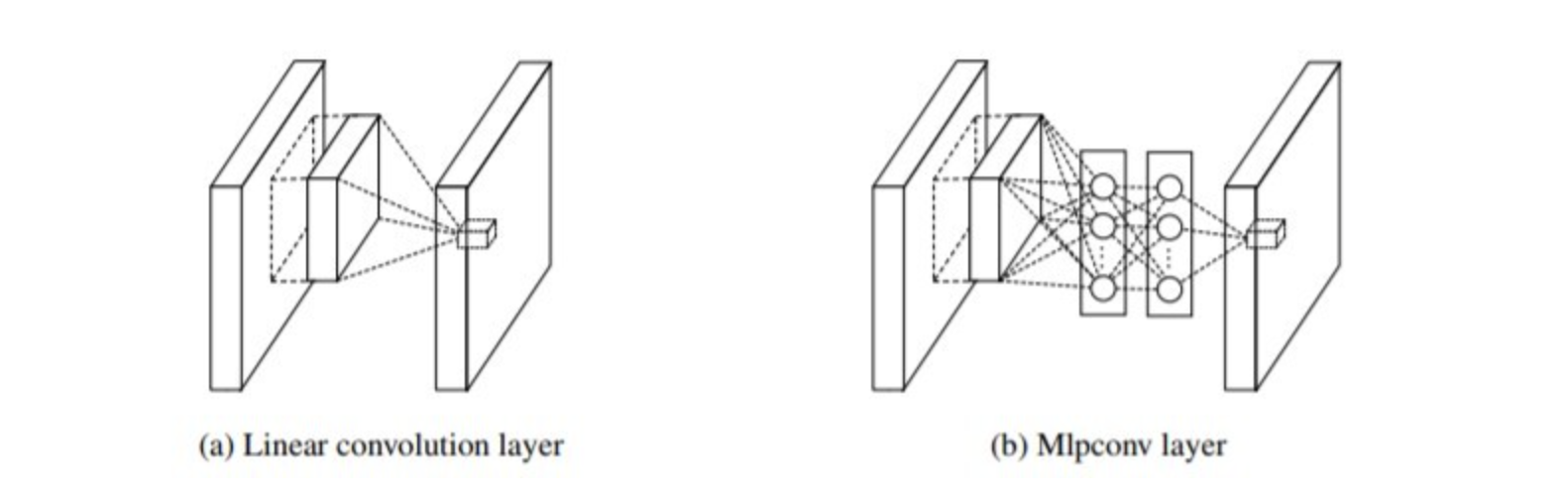
즉 Network-in-Network에서는 비선형적인 관계를 표현할 수 있도록 단순한 Convolution 연산이 아닌, MLP를 중간에 넣게 됩니다.
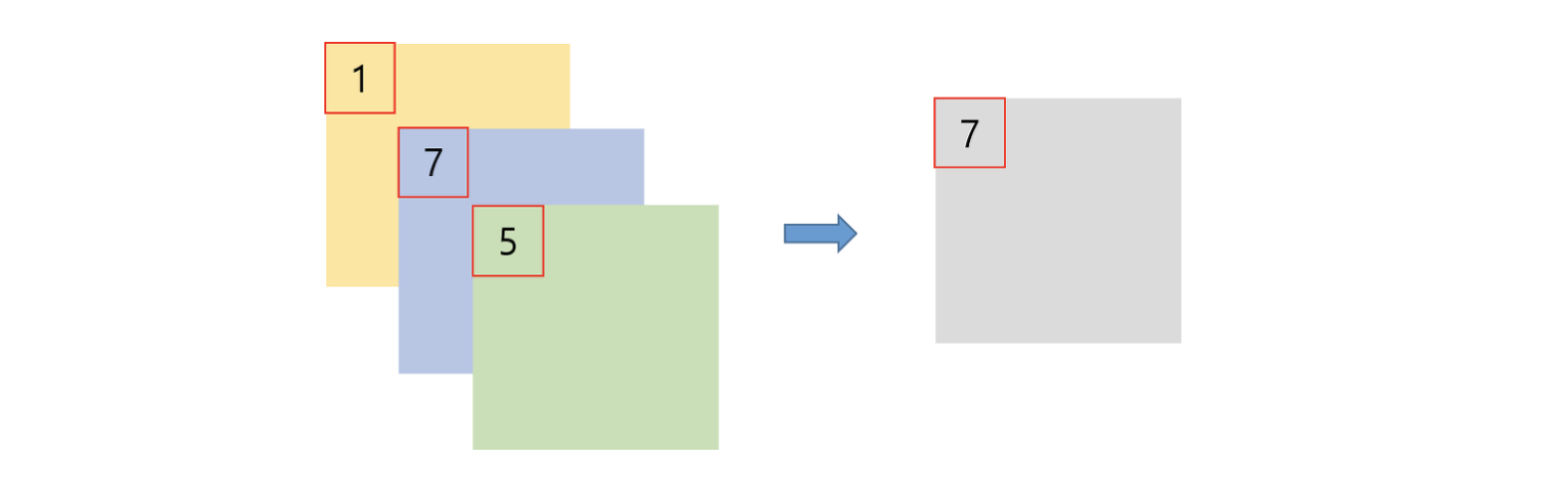
이때 NIN에서 이용하였던 CCCP (Cascaded Cross Channel Pooling)이라는 기법이 있습니다. 이는 단순히 하나의 feature map에 대하여 수행하는 일반적인 pooling기법과 달리 channel을 직렬로 묶어 픽셀별로 pooling을 수행하는 것입니다. 이러한 CCCP 연산의 특징은 feature map의 크기는 그대로이고, channel 수만 줄어들게 하여 차원 축소의 효과를 가져오게 된다는 점입니다.
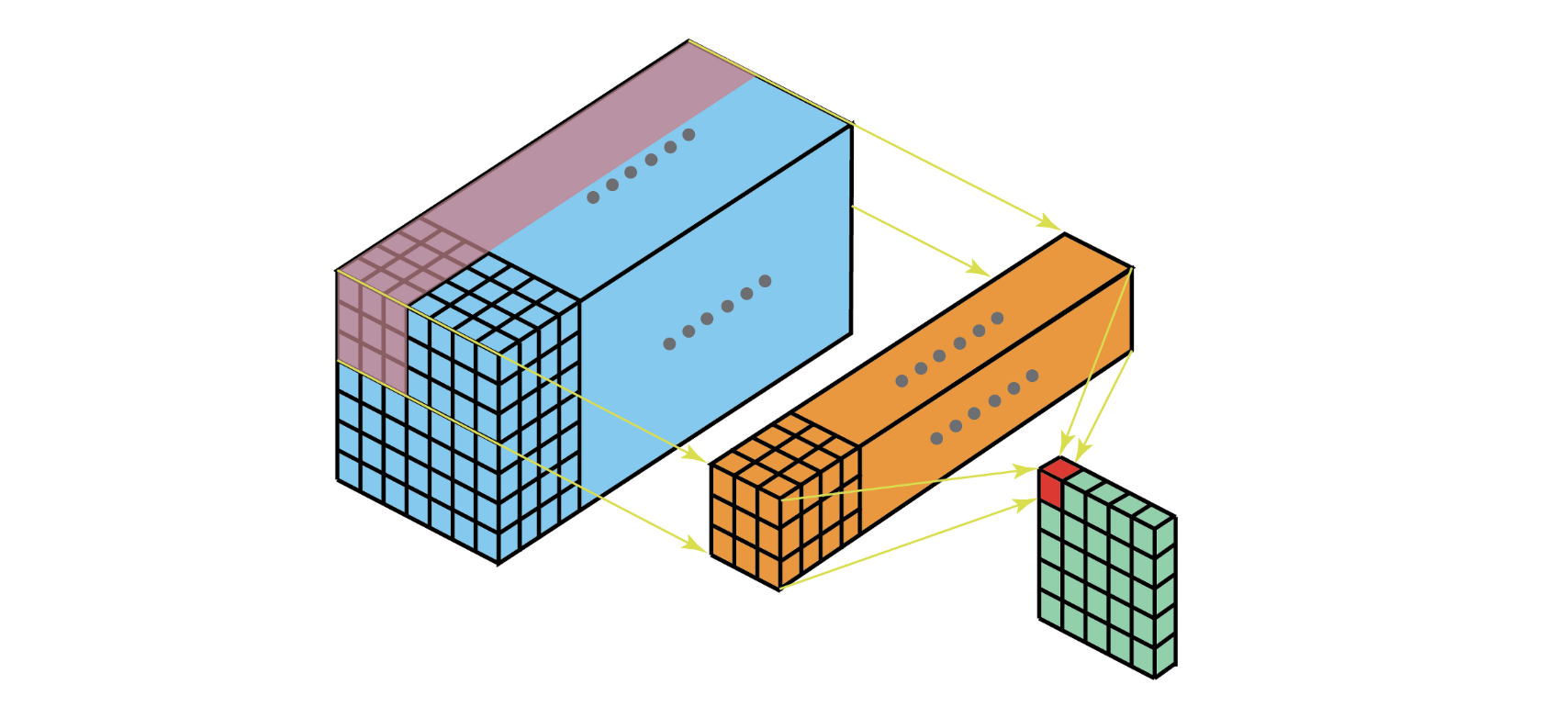
이 CCCP 기법은 1x1 Conv layer과 그 연산 방식 및 효과가 매우 유사합니다. 그래서 GoogLeNet에서 1x1 Conv layer를 Inception module에 적용한 것입니다!
그 다음은 GoogLeNet이 나오게 된 배경입니다. 심층 신경망의 성능을 개선하기 위한 가장 간단한 방법은 신경망의 크기를 무작정 늘리는 것이라고 소개하고 있습니다. 여기서 신경망의 크기를 늘린다는 것은 아래 2가지 의미를 뜻하게 됩니다.
- depth의 증가 (level 수의 증가)
- width의 중가 (각 level의 유닛 수의 증가)
이는 좋은 모델을 얻을 수 있는 가장 쉽고 안전한 방법이지만, 두 가지 문제점이 있습니다. 먼저 크기가 커진다는 것은 파라미터의 수가 늘어난다는 것인데, 이는 학습 데이터의 수가 적은 경우에 오버피팅이 일어나기 쉽다는 점입니다. 논문에서 시베리안 허스키와, 에스키모 강아지를 ILSVR 2014에서 사용된 품질 높은 이미지라고 소개하고 있습니다. 이는 주요 병목현상이 될 수 있는데 ImageNet처럼 세밀한 카테고리를 구별해야 하는 경우, 고품질의 트레이닝 셋을 생성하는 것은 매우 treaky하며 비용이 높을 수 있습니다.
두번째로 네트워크가 커질 수록 컴퓨터의 자원의 사용량이 늘어난다는 점입니다. 만약 두 Convolutional layer가 연결되어 있다고 가정해 보겠습니다. 그리고 필터의 수가 늘어날 때 연산량이 quadratic하게 증가될 것이라고 되어 있습니다. 만약 3x3 conv filter C1개와 3x3xC1 conv filter C2개가 연결되어 있을 시, 이는 3x3xC1 3x3xC1xC2가 됩니다. 연산량이 C1==C2라고 가정하면 거의 quadratic하게 증가한 것인데, 만약 대부분의 기울기가 0이라면 이러한 연산은 엄청난 낭비가 됩니다!
그래서 해당 논문에서는 컴퓨팅 자원을 효율적으로 분배하는 것이 더욱 중요하다고 합니다.

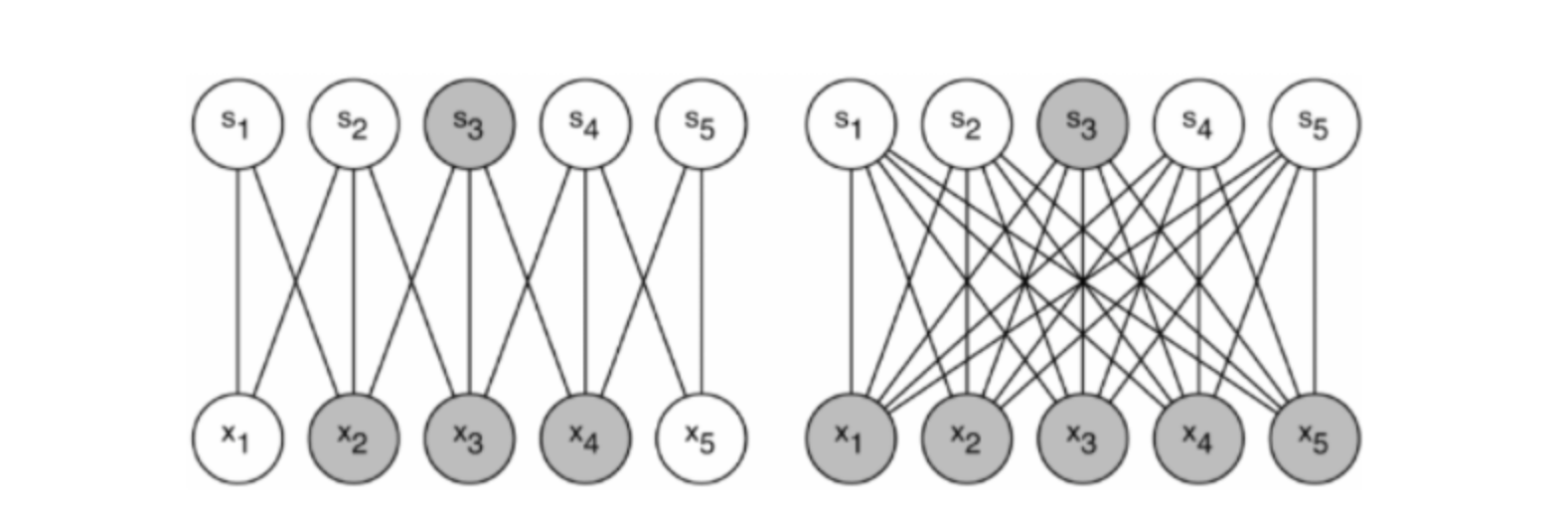
위 두 문제를 해결하는 방법은 dense한 FC구조에서 Sparsely Connected 구조로 바꾸는 것이라고 합니다. 만약 dataset의 분배 확률을 Sparse 하면서도 더 큰 심층 신경망으로 표현 가능하다면, 입력 layer에서 출력 layer로 향하는 layer간의 관계를 통계적으로 분석한 후, 연관 관계가 높은 것들만 연결하여 최적의 Sparse 한 네트워크를 만들 수 있다고 합니다.
하지만 오늘날의 컴퓨팅 환경은 균일하지 않은 Sparse data 구조를 다룰 때 매우 비효율적이라고 합니다. 이러한 격차는 더욱 커졌는데, Dense data 는 꾸준히 개선되고 고도로 조정된 수치적인 라이브러리와 CPU, GPU의 사용으로 빠른 연산이 가능해진 반면, Sparse data의 연산은 미미했습니다.
그래서 초기에는 일부러 대칭성을 깨기 위해 CNN에 Sparse Connection을 적용했지만, 병렬 컴퓨팅 GPU환경에서 더 최적화하기 위해서 Fully-Connected로 트렌드가 다시 바뀌었다고 합니다. 이와 더불어, 균일한 모델 구조와 많은 filter 수, 더 큰 배치 사이즈는 효율적인 Dense 연산이 가능하게끔 하였습니다.
글고 사실 Google 팀의 Inception 구조는 위에서 말한 유사 Sparse 구조를 시험하기 위해 시작되었다고 합니다. 그리고 러닝 레이트와 하이퍼 파라미터를 조정하고 훈련 방법등을 개선한 결과, Localization 및 Object detection 분야에서 특히 좋은 성능을 보였다고 합니다.

이제 본격적으로 Inception 구조에 대해 논문에서 설명합니다.
Inception 구조의 주요 아이디어는 CNN에서 각 요소를 최적의 local sparse structure로 근사하고, 이를 dense component로 바꾸는 방법을 찾은 것입니다. 즉, 최적의 local 구성 요소를 찾고 이를 공간적으로 반복하면 됩니다. 이를 쉽게 말하자면 Sparse matrix를 서로 묶어 (클러스터링) 상대적으로 Dense한 Submatrix를 만든다는 것입니다.
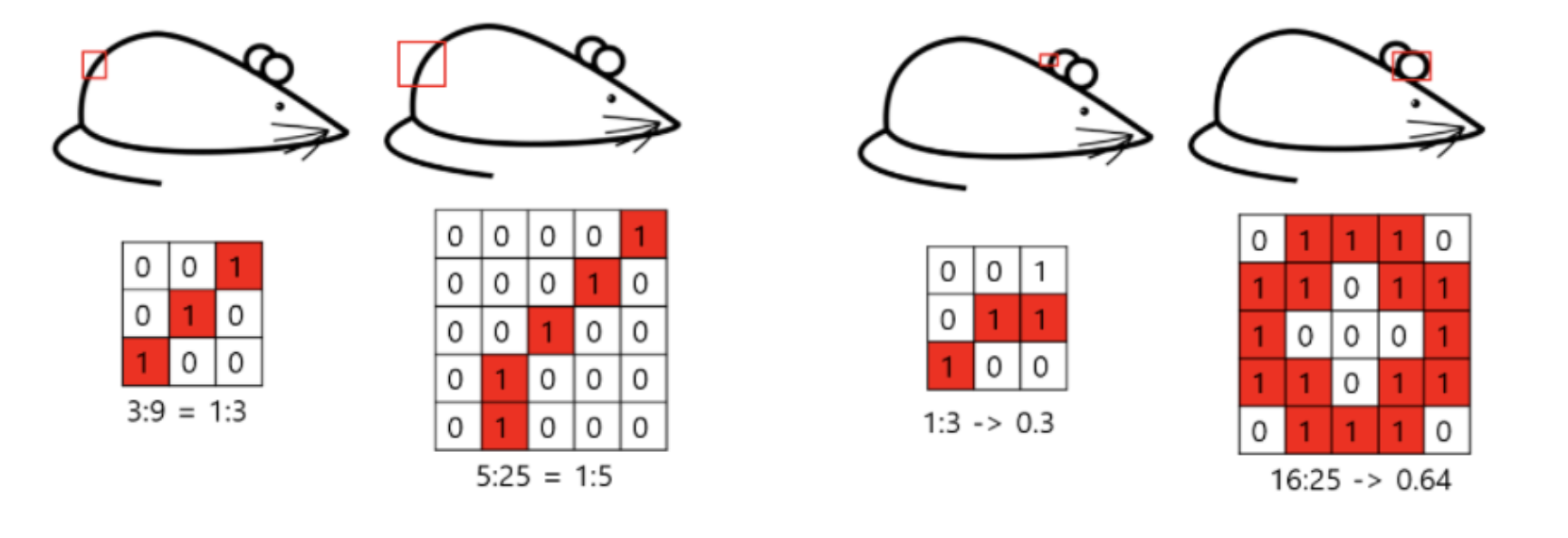
우선 input image와 가까운 낮은 layer에서는 특정 부분에 대해 Correlated unit들이 집중되어 있습니다. 이는 단일 지역에 많은 클러스터들이 집중된다는 뜻이기에 1x1 Convolution으로 처리할 수 있습니다. 하지만 몇몇 위치에서는 위 그림에서처럼 좀 더 넓은 영역의 Convolutional filter가 있어야 Correlated unit의 비율을 높일 수 있는 상황이 나타날 수도 있습니다. 따라서 feature map을 효과적으로 추출할 수 있도록 1x1, 3x3, 5x5 conv 연산을 병렬적으로 수행합니다. 뿐만 아니라 CNN에서 pooling layer의 성능은 이미 검증되었으므로 이와 함꼐 높이와 폭을 맞추기 위해 padding도 추가해줍니다.
즉 1x1, 3x3, 5x4등 다양한 크기의 conv filter를 동시에 사용하는 것은, 네트워크가 다양한 스케일의 피처를 동시에 학습할 수 있게 하기 위함입니다.
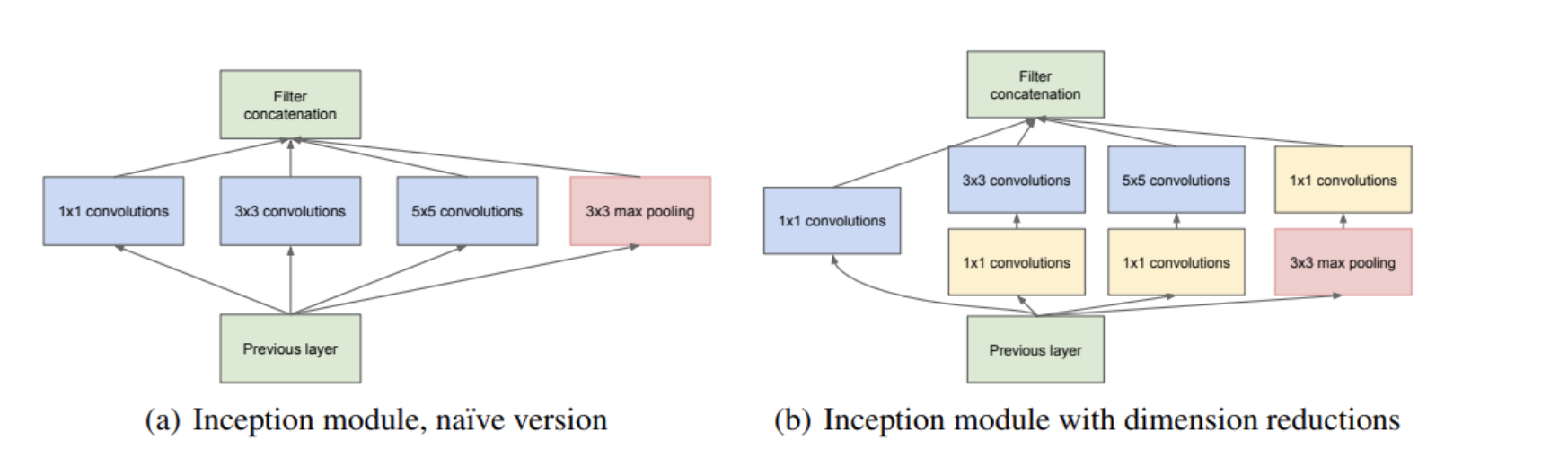
하지만 위 논문에서도 볼 수 있다 싶이 큰 문제가 발생합니다. 3x3 conv filter 뿐만 아니라 5x5 conv filter도 사용할 경우, 연산량이 많아지는데 입력 feature map의 크기가 크거나 5x5 conv filter의 수가 많아지면 연산량은 더욱 증가하게 됩니다.
이를 해결하기 위해서 1x1 conv filter를 통해 차원을 축소하였습니다. 3x3, 5x5 앞에 1x1을 두어 차원을 줄이는데, 이를 통해 여러 scale을 확보하면서도 연산량을 낮출 수 있게 됩니다. 추가적으로 conv 연산 뒤에 추가되는 ReLU를 통해 비선형적 특징을 추가할 수 있습니다.
또한 Google 팀에서는 효율적인 메모리 사용을 위해 낮은 layer에서는 기본적으로 CNN모델을 사용하고, 높은 layer에서는 Inception module을 사용하는 것이 좋다고 합니다. 이러한 특징들을 가진 Inception module을 사용하면 다음 두가지 효과를 노려볼 수 있습니다.
- 과도한 연산량 문제없이 각 단계에서 유닛 수를 상당히 증가시킬 수 있습니다. 이는 차원 축소를 통해 다음 layer의 input수를 조절할 수 있기 떄문입니다.
- Visual 정보다 다양한 Scale로 처리되고, 다음 layer는 동시에 서로 다른 layer에서 특징을 추출할 수 있습지다. 1x1, 3x3, 5x5 conv연산을 통해 다양한 특징을 추출할 수 있기 때문입니다.
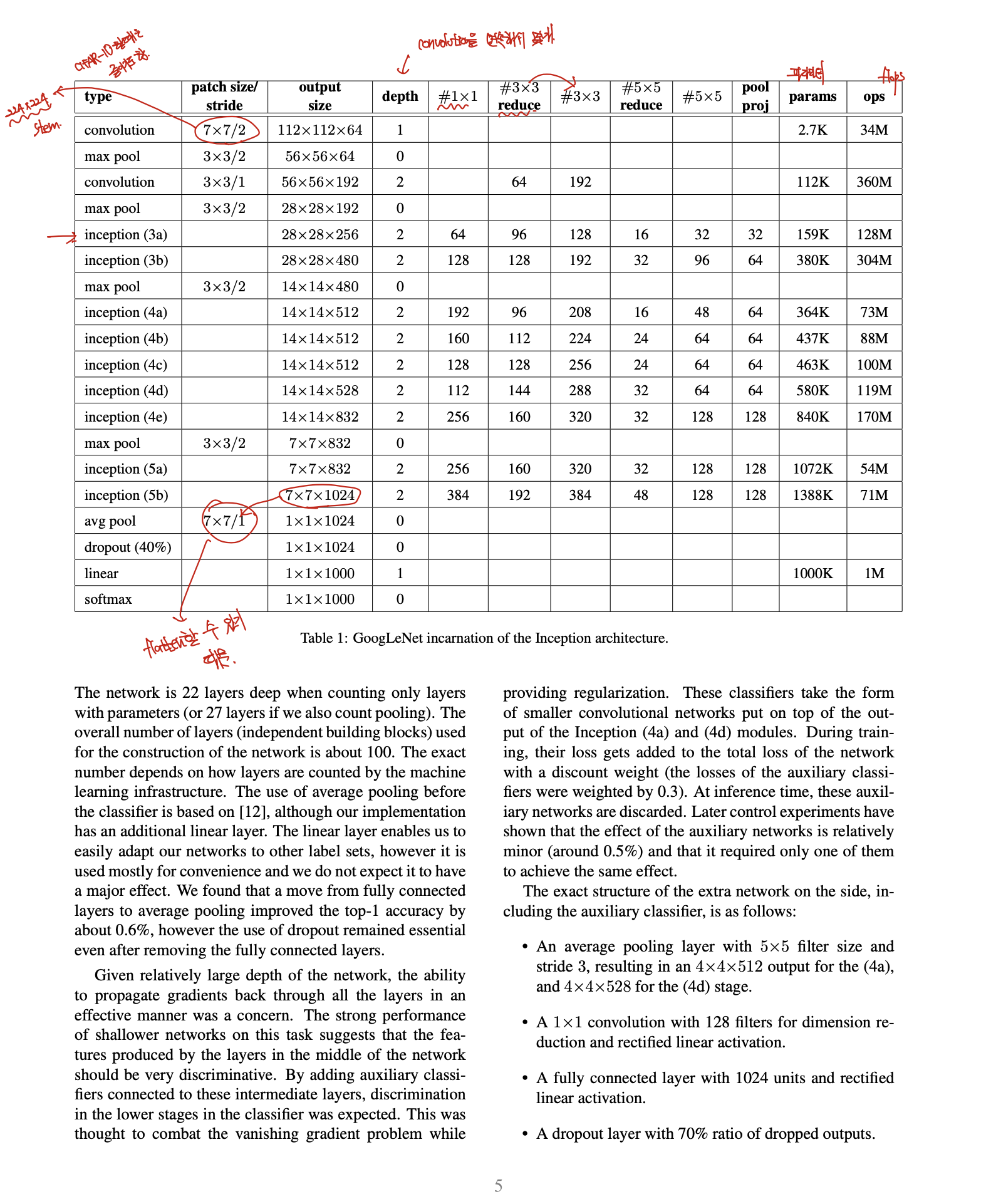
이제 Inception module에 적용된 GoogLeNet의 구조에 대해 알아보겠습니다.
Inception module 내부를 포함한 모든 conv layer에는 ReLU가 적용되었습니다. 또한 receptive field의 크기는 224x224로 RGB 컬러 채널을 가지며, mean subtraction도 적용합니다.
위 표에서 # 3x3 reduce와 # 5x5 reduce는 3x3과 5x4 Convolutional layer의 앞에 사용되는 1x1 필터의 채널 수를 의미합니다. 그리고 pool proj 열은 max pooling layer 뒤에 오는 1x1 필터의 채널 수를 의미합니다. 여기서도 모든 reduction 및 projection layer에 ReLU가 사용됩니다.
이제 GoogLeNet을 4가지 부분으로 나누어 살펴보겠습니다.
Part 1 (stem module)
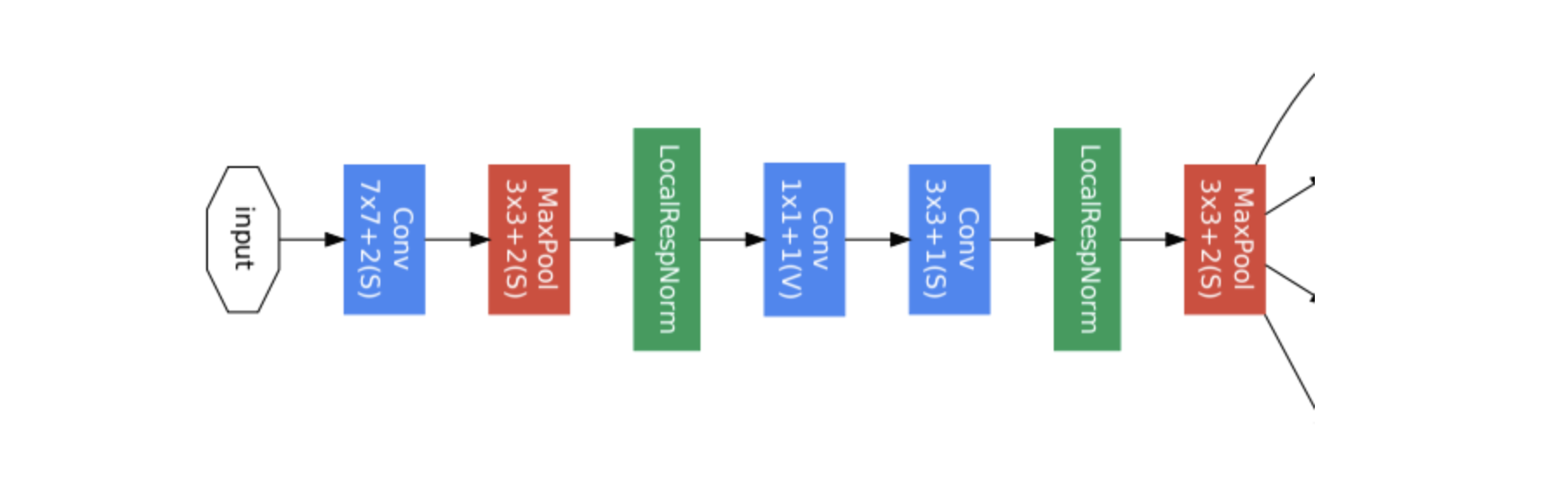
stem module은 입력 이미지와 가까운 낮은 레이어가 위치해있는 부분입니다. 이는 위에서 설명했듯이 효율적인 메모리 사용을 위해 낮은 layer에서는 기본적인 CNN모델을 적용한다고 했었습니다. 여기서는 Inception module이 사용되지 않습니다.
Conv(7x7) -> Max pool -> LocalRespNorm -> Conv 1x1 - Conv 3x3 -> LocalRespNorm -> MaxPool 을 하게 되는데, 위 표를 보면 Conv 3x3에 # 3x3 reduce의 값이 192입니다. 그래서 그 앞에 1x1 conv filter가 192개가 있음을 쉽게 파악할 수 있을 겁니다.
Part 2
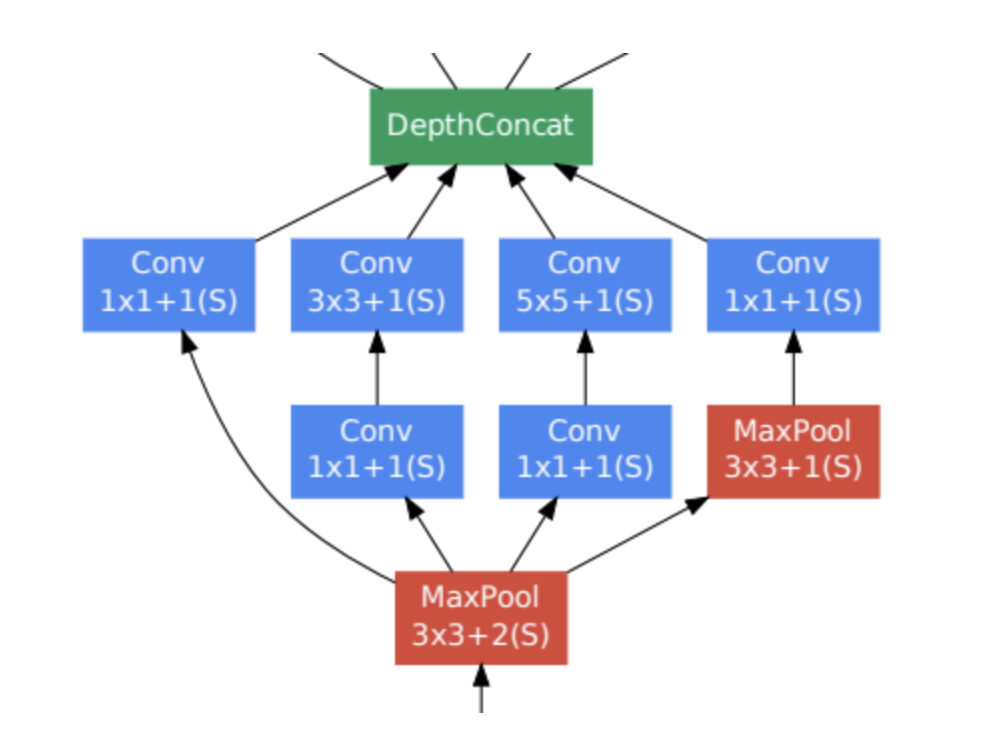
이는 Inception module로서 다양한 특징을 추출하기 위해 1x1, 3x3, 5x5 conv layer가 병렬적으로 연산을 수행하고 있는 것을 볼 수 있습니다. 여기서 핵심은 차원을 축소하여 연산량을 줄이기 위해 1x1 conv layer가 적용되었다는 점? 정도고 max pool도 적용되었다는 점입니다. 정확히 왜 추가되었는지는 나와있지 않습니다.
Part 3
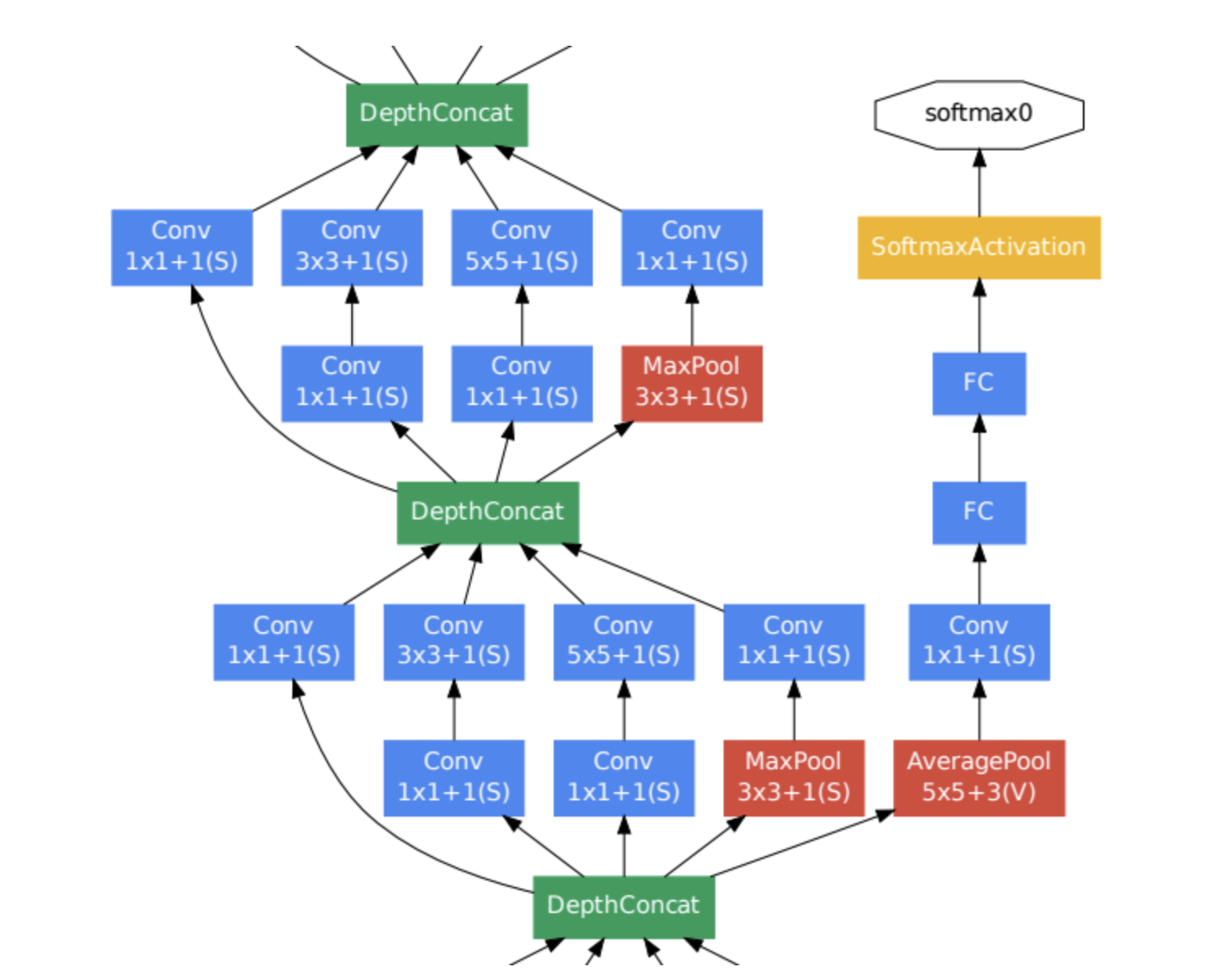
Part 3는 auxiliary classifier가 적용된 부분입니다. 모델의 깊이가 깊을 경우, back prop과정에서 기울기가 input layer로 갈수록 0으로 수렴하는 gradient vanishing 문제가 발생할 수 있습니다. 그리고 중간 layer에 auxiliary classifier를 추가하였는데, 그 이유는 inception module을 통과하면서 신경망의 강한 성능을 신경망의 중간 layer에서 생성된 특징이 가장 차별적이기 때문입니다. 아래쪽에 넣으면 아마 성능이 낮아지지 않을까 예측합니다.
추가적으로 지나치게 영향을 주는 것을 막기 위해 auxiliary classifier의 loss에 0.3을 곱하였고, 실제 테스트 시에는 auxiliary classifier를 제거한 후, 제일 끝단의 softmax 층만을 이용했다고 합니다.
Part 4
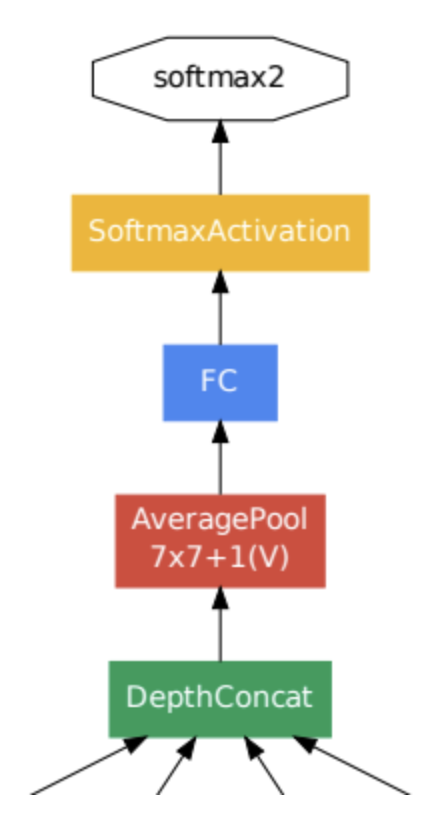
Part4는 예측결과가 나오는 모델의 끝부분입니다. 여기서 최종 Classifier 이전에 average pooling layer를 사용하고 있는데, 이는 GAP (Global Average Pooling)가 적용된 것으로 이전 layer에서 추출된 feature map을 각각 평균 낸 것을 이어 붙혀 1차원 벡터로 만들어 준 것입니다. 이는 1차원 열벡터로 만들어야 최종적으로 이미지 분류를 위한 softmax layer와 연결할 수 있기 때문입니다.
FC와 다르게 GAP은 파라미터가 필요하지 않고, 나중에 fine tuning을 하기 쉽게 만든다는 장점이 있습니다.

위와같이 inception module이 여러개가 연결되어 있고, 위에서 살펴본 Part1~4가 그대로 적용되어 있고, 정확한 수치는 위에서 표를 참고하면 되겠습니다.

모델을 훈련할때 Google 팀에서 SGD에서 0.9 momentum값을 이용하였다 하고, lr(learning rate)는 8 epoch마다 4%싹 감소하게 했다고 합니다. 또한 이미지의 가로, 세로 비율을 3:4와 4:3사이로 유지하며 본래 사이즈의 8%~100%가 포함되도록 다양한 크기의 patch를 사용했다고 합니다. 그리고 photometric distortions를 통해 학습 데이터를 늘렸다고 합니다.
결론입니다. Inception 구조는 Sparse 구조를 Dense 구조로 근사하여 성능을 개선하였습니다. 이는 기존에 CNN 성능을 높이기 위한 방법과는 다른 새로운 방법이였으며, 성능은 대폭 상승하였지만 연산량은 약간만 증가한다는 장점이 있습니다!
하지만 ILSVR 2014에서 VGG net을 제치고 우승을 하였지만, 실제로 이미지에서 feature를 뽑아내는 기술 같은게 VGG net이 더 좋고, 일반화 성능이 좋다고 합니다. 그래서 GoogLeNet보다는 실제로 VGG net이 추후 연구에 더 많이 reference되며 활용된다고 합니다.
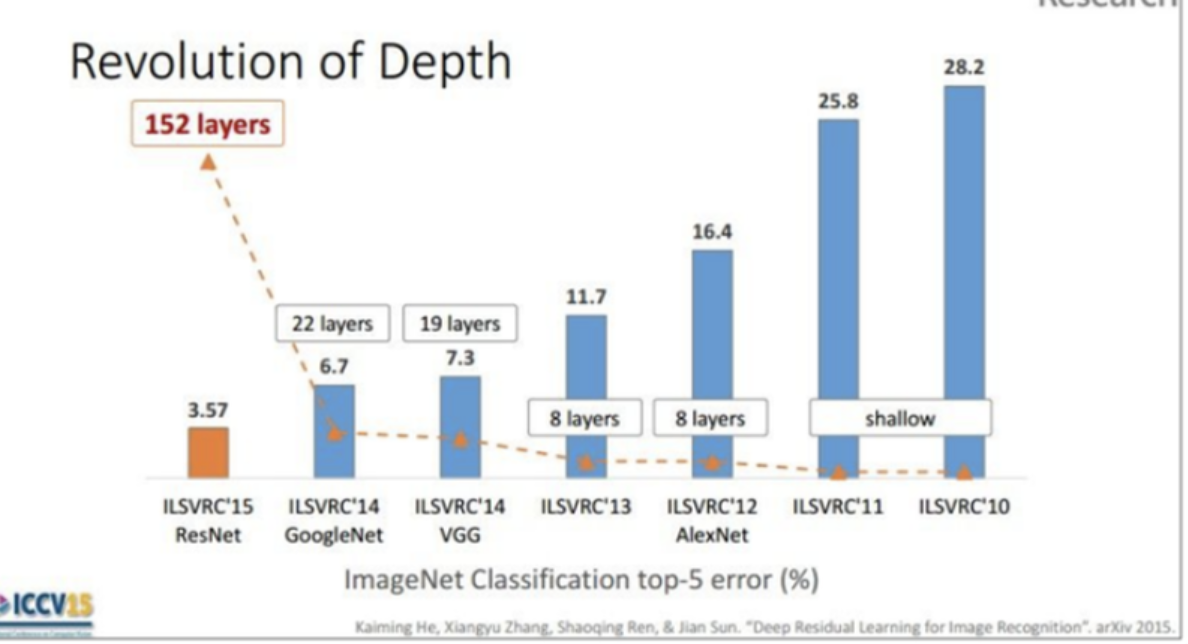
위 그림은 ILSVRC 의 역대 top-5 error rate와 수상작을 나타냅니다. GoogLeNet은 22 layers를 사용하였고, VGG도 비슷한 19-layers를 사용한 것을 볼 수 있습니다. 이는 기존의 Shallow한 AlexNet보다는 높은 depth입니다. 그리고 그 다음에 소개된 ResNet은 이전에 알아본 residual connection (skip connection)을 사용해 152 layer를 쌓으며 가장 좋은 성능을 보였습니다.
이와같이, ResNet과 VGG net은 현재까지도 백본 논문입니다. 하지만 GoogLeNet은 inception이라는 새로운 발상에서 높은 의미를 가진다고 합니다. 그다음으로는 실제 VGG net을 PyTorch로 코딩해보겠습니다!