
서버를 개발할 때 데이터베이스를 사용하면 웹 서비에서 사용되는 데이터를 저장하고, 효율적으로 조회하거나 수정할 수 있습니다. 기존에는 MySQL, OracleDB, PostgreSQL같은 RDBMS(관계형 데이터베이스)를 자주 사용했습니다.
그런데 관계형 데이터베이스에는 몇가지 한계가 있습니다.
RDBMS의 한계점
첫 번째는 데이터 스키마가 고정적이라는 점입니다. 여기서 스키마란 데이터베이스에 어떤 형식의 데이터를 넣을지에 대한 정보를 가리킵니다. 예를 들어 회원 정보 스키마라면 계정명, 이메일, 이름 등이 되겠습니다. 새로 등록하는 데이터 형식이 기존에 있던 데이터와 다르다면 기존 데이터를 모두 수정해야 새 데이터를 등록할 수 있습니다. 그래서 데이터양이 많을 때는 데이터베이스의 스키마를 변경하는 작업이 매우 번거로워질 수 있습니다.
두 번째는 확장성입니다. RDBMS는 저장하고 처리해야 할 데이터양이 늘어나면 여러 컴퓨터에 분산시키는 것이 아니라, 해당 데이터베이스 서버의 성능을 업그레이드하는 방식으로 확장해 주어야 했습니다. MongoDB는 이런 한계를 극복한 문서 지향적 NoSQL 데이터베이스입니다. 이 데이터베이스에 등록하는 데이터들은 유동적인 스키마를 지닐 수 있습니다. 새로 등록해야 할 데이터 형식이 바뀐다고 하더라도 기존 데이터까지 수정할 필요는 없습니다. 서버의 데이터양이 늘어나도 한 컴퓨터에서만 처리하는 것이 아니라 여러 컴퓨터로 분산하여 처리할 수 있도록 확장하기 쉽게 설계되어 있습니다.
MongoDB가 무조건 기존의 RDBMS보다 좋은 것은 아닙니다. 상황별로 적합한 데이터베이스가 다를 수 있습니다. 예를 들어 데이터의 구조가 자주 바뀐다면 MongoDB가 유리합니다. 그러나 까다로운 조건으로 데이터를 필터링해야 하거나, ACID특성을 지켜야 한다면 RDBMS가 더 유리할 수도 있습니다.
ACID 특성은 원자성(Atomicity) 일관성(Consistency), 고립성(Isolation), 지속성(Durability)의 앞 글자를 따서 만든 용어로, 데이터베이스 트랜잭션이 안전하게 처리되는 것을 보장하기 위한 성질을 의미합니다.
스키마 디자인
MongoDB에서 스키마를 디자인하는 방식은 기존 RDBMS에서 스키마를 디자인하는 방식과 완전히 다릅니다. RDBMS에서 블로그용 데이터 스키마를 설계한다면 각 포스트, 댓글마다 테이블을 만들어 필요에 따라 JOIN해서 사용하는 것이 일반적입니다.
하지만 NoSQL에서는 그냥 모든 것을 문서 하나에 넣습니다. 문서 예시의 형식을 한번 살펴봅시다.
{ _id: ObjectId, title: String, body: String, username: String, createdDate: String, comments: [ { _id: ObjectId, text: String, createdDate: Date }, ], };
이런 상황에서 보통 MongoDB는 댓글을 포스트 문서 내부에 넣습니다. 문서 내부에 또 다른 문서가 위치할 수 있는데, 이를 서브다큐먼트(subdocument)라고 합니다. 서브다큐먼트 또한 일반 문서를 다루는 것처럼 쿼리할 수 있습니다.
또한 서브다큐먼트에서 이 용량을 초과할 가능성이 있다면 컬렉션을 분리하는 것이 좋습니다.
MongoDB
우선 기존에 만들었던 koaFramwork에 이 mongodb를 연동시켜보겠습니다.
가장 처음으로 우리는 모든 프로젝트를 아직 node에서 지원하지 않는 ES6문법을 사용하고 싶기 때문에 esm이라는 모듈을 따로 설치해 주어야 합니다. 그 후 기존의 src폴더 안의 index.js를 main.js로 바꾸고 index.js을 다음과 같이 작성해야 합니다.
/* eslint-disable no-global-assign */ require = require('esm')(module /*, options*/); module.exports = require('./main.js');
그러면 이제 main.js에서 ES6문법을 사용할 수 있게 됩니다. 그리고 이제 src안의 모든 폴더 안의 문법들을 CommonJS에서 ES NEXT문법으로 바꿔주는 작업을 해야 합니다.
// src/main.js /* eslint-disable no-undef */ require('dotenv').config(); import Koa from 'koa'; import Router from 'koa-router'; import bodyParser from 'koa-bodyparser'; import mongoose from 'mongoose'; const { PORT, MONGO_URI } = process.env; mongoose .connect(MONGO_URI) .then(() => { console.log('Connected to MongoDB'); }) .catch((e) => { console.error(e); }); import api from './api'; const app = new Koa(); const router = new Router(); router.use('/api', api.routes()); app.use(bodyParser()); app.use(router.routes()).use(router.allowedMethods()); const port = PORT || 4000; app.listen(port, () => { console.log(`Listening to port ${port}`); });
// src/api/index.js import Router from 'koa-router'; import posts from './posts'; const api = new Router(); api.use('/posts', posts.routes()); export default api;
// src/api/posts/index.js import Router from 'koa-router'; import * as postsCtrl from './posts.ctrl'; const posts = new Router(); posts.get('/', postsCtrl.list); posts.post('/', postsCtrl.write); posts.get('/:id', postsCtrl.read); posts.delete('/:id', postsCtrl.remove); posts.put('/:id', postsCtrl.replace); posts.patch('/:id', postsCtrl.update); export default posts;
// src/api/posts/posts.ctrl.js let postId = 1; // id의 초깃값 // posts 배열 초기 데이터 let posts = [ { id: 1, title: '제목', body: '내용', }, ]; /** * 포스트 작성 * POST /api/posts * { title, body } */ export const write = (ctx) => { // REST API의 Request Body는 ctx.request.body에서 조회할 수 있습니다. const { title, body } = ctx.request.body; postId += 1; const post = { id: postId, title, body }; posts = [...posts, post]; ctx.body = post; }; /** * 포스트 목록 조회 * GET /api/posts */ export const list = (ctx) => { ctx.body = posts; }; /** * 특정 포스트 조회 * GET /api/posts/:id */ export const read = (ctx) => { const { id } = ctx.params; const post = posts.find((p) => p.id.toString() === id); if (!post) { ctx.status = 404; ctx.body = { message: '포스트가 존재하지 않습니다.', }; return; } ctx.body = post; }; /** * 특정 포스트 제거 * DELETE /api/post/:id */ export const remove = (ctx) => { const { id } = ctx.params; const index = posts.findIndex((p) => p.id.toString() === id); if (index === -1) { ctx.status = 404; ctx.body = { message: '포스트가 존재하지 않습니다.', }; return; } posts.slice(index, 1); ctx.status = 204; }; /** * 포스트 수정(교체) * PUT /api/posts/:id * { title, body } */ export const replace = (ctx) => { // PUT 메서드는 전체 포스트 정보를 입력하여 데이터를 통째로 교체할 때 사용합니다. const { id } = ctx.params; const index = posts.findIndex((p) => p.id.toString() === id); if (index === -1) { ctx.status = 404; ctx.body = { message: '포스트가 존재하지 않습니다.', }; } posts[index] = { id, ...ctx.request.body, }; ctx.boy = posts[index]; }; /** * 포스트 수정(특정 필드 변경) * PATCH /api/posts/:id * { title, body } */ export const update = (ctx) => { // PATCH 메서드는 주어진 필드만 교체합니다. const { id } = ctx.params; const index = posts.findIndex((p) => p.id.toString() === id); if (index === -1) { ctx.status = 404; ctx.body = { message: '포스트가 존재하지 않습니다.', }; } // 기존 값에 정보를 덮어 씌웁니다.\ posts[index] = { ...posts[index], ...ctx.request.body, }; ctx.body = posts[index]; };
또한 다음과 같이 루트 디렉토리에 jsconfig.json을 만들어 줍니다.
{ "compilerOptions": { "target": "es6", "module": "es2015" }, "include": ["src/**/*"] }
이 파일을 위 코드와 같이 작성해 주면 나중에 자동 완성을 통해 모듈을 불러올 수 있게 도비니다. 이 코드의 의미는 src를 루트 디렉토리르 만들고 컴파일을 할때 es6을 참고해 줘라 라는 뜻입니다.
마지막으로 eslint에서 es6문법에 오류를 내는 것을 방지하기 위해 다음과 같이 .eslintrc.json파일의 parserOptions에 sourceType을 module로 바꿔줍니다.
{ "env": { "browser": true, "commonjs": true, "es2021": true }, "extends": ["eslint:recommended", "prettier"], "parserOptions": { "ecmaVersion": "latest", "sourceType": "module" }, "rules": { "no-unused-vars": "warn", "no-console": "off" } }
mongoose
mongoose에는 스키마와 모델이라는 개념이 있는데, 이 둘은 혼동하기 쉽습니다. 스키마는 컬렉션에 들어가는 문서 내부의 각 필드가 어떤 형식으로 되어 있는지 정의하는 객체입니다. 이와 달리 모델은 스키마를 사용하여 만드는 인스턴스로, 데이터베이스에서 실제 작업을 처리할 수 있는 함수들을 가지고 있는 객체입니다.
< schema >
// src/models/post.js import mongoose from 'mongoose'; const { Schema } = mongoose; const PostSchema = new Schema({ title: String, body: String, tags: [String], publishedDate: { type: Date, default: Date.now(), }, });
이렇게 mongodb의 스키마를 설정해 줄 수 있습니다. Schema에서 지원하는 타입은 대충 아래와 같이 정리할 수 있습니다.
- String
- 문자열
- Number
- 숫자
- Date
- 날짜
- Buffer
- 파일을 담을 수 있는 버퍼
- Boolean
- true 또는 false 값
- Mixed(Schema.Types.Mixed)
- 어떤 데이터도 넣을 수 있는 형식
- ObjectId(Schema.Types.ObjectId)
- 객체 아이디, 주로 다른 객체를 참조할 때 넣음
- Array
- 배열 형태의 값으로 []러 감싸서 사용
< model >
import mongoose from 'mongoose'; const { Schema } = mongoose; const PostSchema = new Schema({ title: String, body: String, tags: [String], publishedDate: { type: Date, default: Date.now(), }, }); const Post = mongoose.model('Post', PostSchema); export default Post;
모델 인스턴스를 만들고, export default를 통해 내보내 주었습니다. model함수의 첫번쨰 파라미터는 스키마의 이름이고, 두 번쨰 파라미터는 스키마 객체입니다. 데이터베이스는 스키마 이름을 정해주면 그 이름의 복수 형태로 데이터베이스에 컬렉션 이름을 만듭니다.
예를 들어 스키마 이름을 Post로 설정하면, 실제 데이터베이스에 만드는 컬렉션 이름은 posts입니다. MongoDB에서 컬렉션 이름을 만들 때, 권장되는 컨벤션은 구분자를 사용하지 않고 복수 형태로 사용하는 것입니다. 이 컨벤션을 따르고 싶지 않다면 세 번째 파라미터에 원하는 이름을 적어주시면 됩니다.
데이터 생성
... export const write = async (ctx) => { // REST API의 Request Body는 ctx.request.body에서 조회할 수 있습니다. const { title, body, tags } = ctx.request.body; const post = new Post({ title, body, tags, }); try { await post.save(); ctx.body = post; } catch (e) { ctx.throw(500, e); } }; ....
포스트의 인스턴스를 만들 때는 new키워드를 사용합니다. 그리고 생성자 함수의 파라미터에 정보를 지닌 객체를 넣습니다.
인스턴스를 만들었다면 save()함수를 실행시켜야 비로소 데이터베이스에 저장됩니다.
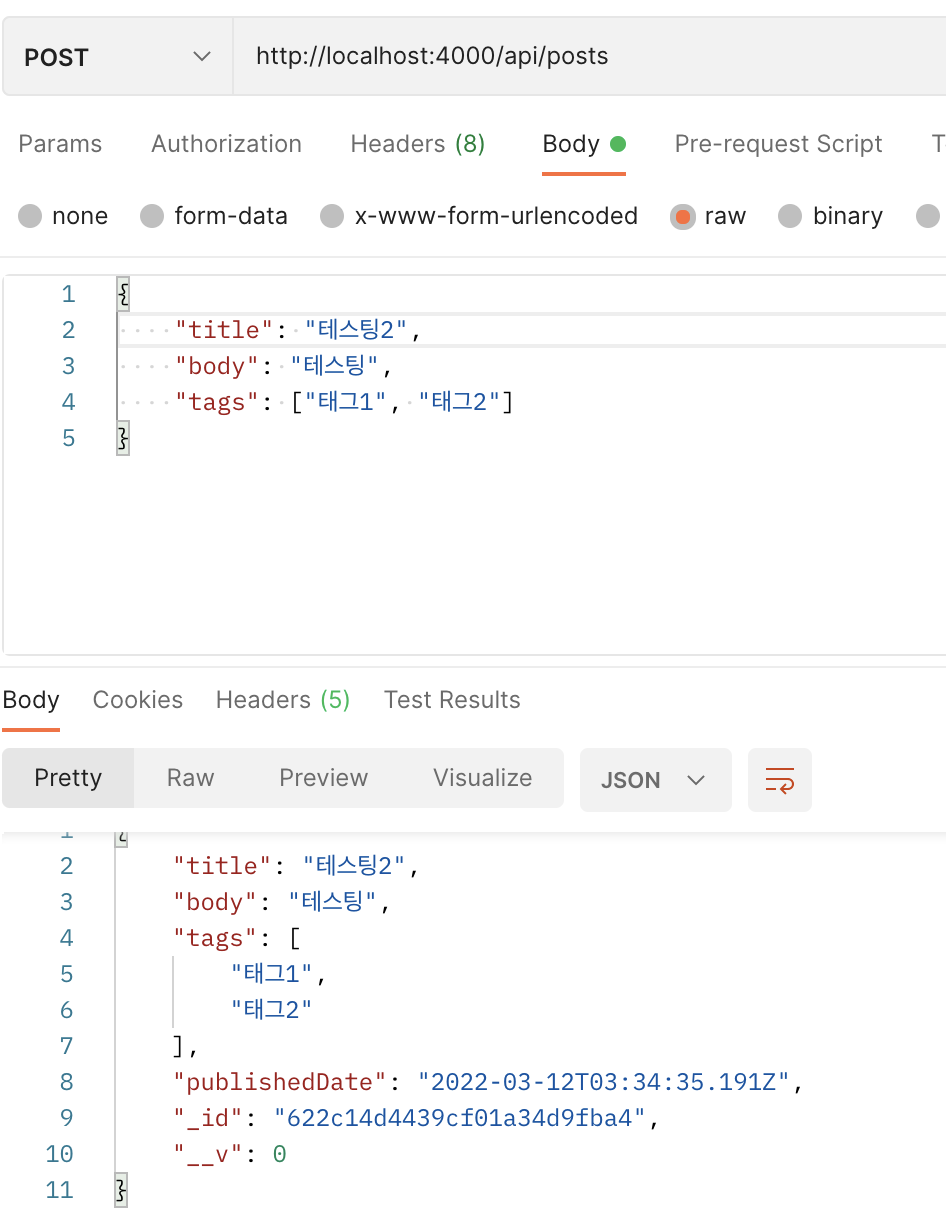
postman에서 write요청이 잘 작동하는 것을 볼 수 있습니다.
데이터 조회
... export const list = async (ctx) => { try { const posts = await Post.find().exec(); ctx.body = posts; } catch (e) { ctx.throw(500, e); } }; ...
컬렉션에서 문서들을 조회하고 싶다면 모델 인스턴스의 find()함수를 사용합니다. find()함수를 호출한 후에는 exec()를 불러주어야 서버에 쿼리를 요청합니다.
데이터 삭제
데이터 삭제에는 여러 가지 함수가 있는데 그냥 보고만 넘어가겠습니다.
- remove() >> 특정 조건을 만족하는 데이터를 모두 삭제합니다.
- findByIdAndRemove() >> id를 찾아서 지웁니다.
- findOneAndRemove() >> 특정 조건을 만족하는 데이터 하나를 찾아서 제거합니다.
이중 findByIdAndRemove()의 사용법을 간단히 보자면
... export const remove = async (ctx) => { const { id } = ctx.params; try { await Post.findByIdAndRemove(id).exec(); ctx.status = 204; } catch (e) { ctx.throw(500, e); } }; ...
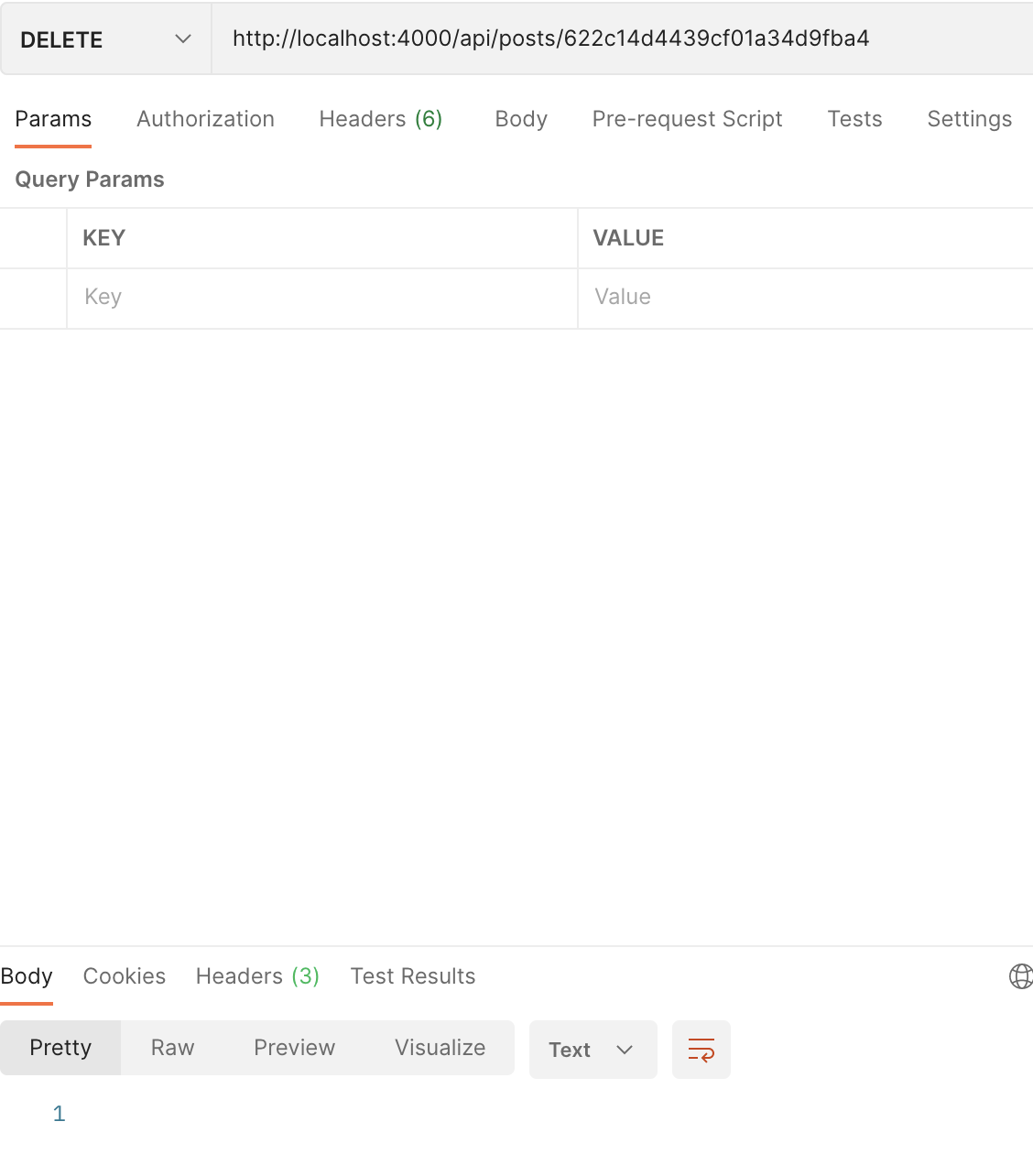
위와 같이 쿼리문을 발송시킬 수 있다.
데이터 수정
데이터 수정으로는 findByIdAndUpdate()함수가 존재한다. 이 함수를 사용할 때는 세 가지 파라미터를 넣어 주어야 합니다. 첫 번쨰 파라미터는 Id, 두 번쨰 파라미터는 업데이터 내용, 세 번쨰 파라미터는 업데이터의 옵션입니다.
... export const update = async (ctx) => { // PATCH 메서드는 주어진 필드만 교체합니다. const { id } = ctx.params; try { const post = await Post.findByIdAndUpdate(id, ctx.request.body, { new: true, }).exec(); if (!post) { ctx.status = 404; return; } ctx.body = post; } catch (e) { ctx.throw(500, e); } }; ...
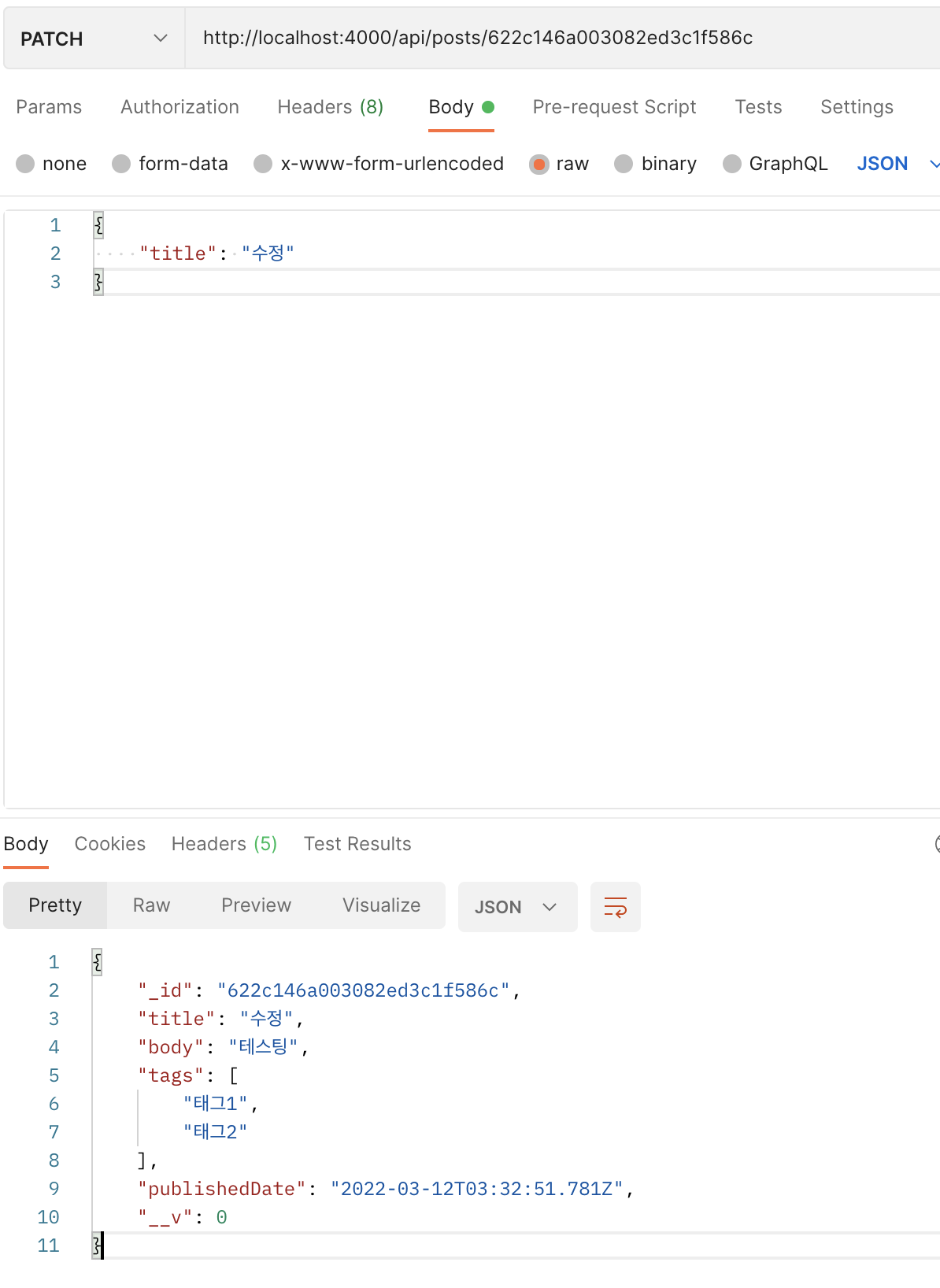
위와 같이 제목이 잘 바뀌는 것을 볼 수 있습니다.
Mongoose query
위 내용과는 별개로 mongoose의 쿼리문이 정확히 어떻게 작동하는지 궁금해서 더 조사해보았다.
Finding documents is easy with Mongoose, which supports the rich query syntax of MongoDB. Documents can be retrieved using amodel's find, findById, findOne, or where static methods
즉 쿼리문을 연달아 쓸 수 있다는 것이다.
const data = await Post.find({ title: '수정' }) .where('body', '테스팅') .exec();
또한 찾아본 결과 나머지 모델이나 쿼리문의 메소드들은 찾아보면서 가능할 것 같았다.
가장 중요한 mongoose의 동작 방식을 찾아본 결과 아래와 같았다.
기본적으로 mongoose를 이용할 때, 문서가 helper에 의해 반환되어 집니다. 또한 모든 쿼리의 상태를 인자로 받는 모델의 메소드는 callback이나 exec의 메소드로 실행되어 질 수 있다는 점입니다.
쉽게 아래 두가지 버전이 있다는 겁니다.
< callback >
User.findOne({ name: 'daniel' }, function (err, user) { // });
< exec >
User .findOne({ name: 'daniel' }) .exec(function (err, user) { // });
또한 mongoose의 쿼리문을 Promise와 쓸 때 주의해야 할 점이 있다. 바로 mongoose의 쿼리문들은 promise가 아니라는 점이다. 쿼리들은 그저 thenable 을 리턴하는 것이고, 우리는 then으로써 그 결과를 이어줄 뿐이다. 만약 우리가 진짜(real) Promise를 쓰고 싶다면 exec메소드를 붙여서 써 주어야 한다.
ObjectId 검증
// src/api/posts/index.js import Router from 'koa-router'; import * as postsCtrl from './posts.ctrl'; const posts = new Router(); posts.get('/', postsCtrl.list); posts.post('/', postsCtrl.write); const post = new Router(); post.get('/', postsCtrl.read); post.delete('/', postsCtrl.remove); post.patch('/', postsCtrl.update); posts.use('/:id', postsCtrl.checkObjectId, post.routes()); export default posts;
// src/api/posts/posts.ctrl.js ... const { ObjectId } = mongoose.Types; export const checkObjectId = (ctx, next) => { const { id } = ctx.params; if (!ObjectId.isValid(id)) { ctx.status = 400; return; } return next(); }; ...
코드를 작성하고 GET /api/posts/:id요청을 하면 aaaa와 같이 일반 ObjectId의 문자열 길이가 다른, 잘못된 Id를 넣게 되면 500대신 400 Bad Request라는 에러가 발생하게 됩니다.

Request Body 검증
포스트를 작성할 떄 서버는 title, body, tags값을 모두 전달받아야 합니다. 그리고 클라이언트가 값을 빼먹었을 때는 400오류가 발생해야 합니다. 여기서는 이러한 작업을 수월하게 해 주는 라이버리인 Joi를 설치하여 사용하였습니다.
write와 update에 request body검증하는 작업을 해주었습니다.
// src/api/posts/posts.ctrl.ks ... export const write = async (ctx) => { // REST API의 Request Body는 ctx.request.body에서 조회할 수 있습니다. const schema = Joi.object().keys({ // 객체가 다음 필드를 가지고 있음을 검증 title: Joi.string().required(), body: Joi.string().required(), tags: Joi.array().items(Joi.string()).required(), }); const result = schema.validate(ctx.request.body); if (result.error) { ctx.status = 400; ctx.body = result.error; return; } const { title, body, tags } = ctx.request.body; const post = new Post({ title, body, tags, }); try { await post.save(); ctx.body = post; } catch (e) { ctx.throw(500, e); } }; export const update = async (ctx) => { // PATCH 메서드는 주어진 필드만 교체합니다. const { id } = ctx.params; // write에서 사용한 schema와 비슷한데, required()가 없습니다. const schema = Joi.object().keys({ title: Joi.string(), body: Joi.string(), tags: Joi.array().items(Joi.string()), }); const result = schema.validate(ctx.request.body); if (result.error) { ctx.status = 400; ctx.body = result.error; return; } try { const post = await Post.findByIdAndUpdate(id, ctx.request.body, { new: true, }).exec(); if (!post) { ctx.status = 404; return; } ctx.body = post; } catch (e) { ctx.throw(500, e); } }; ...
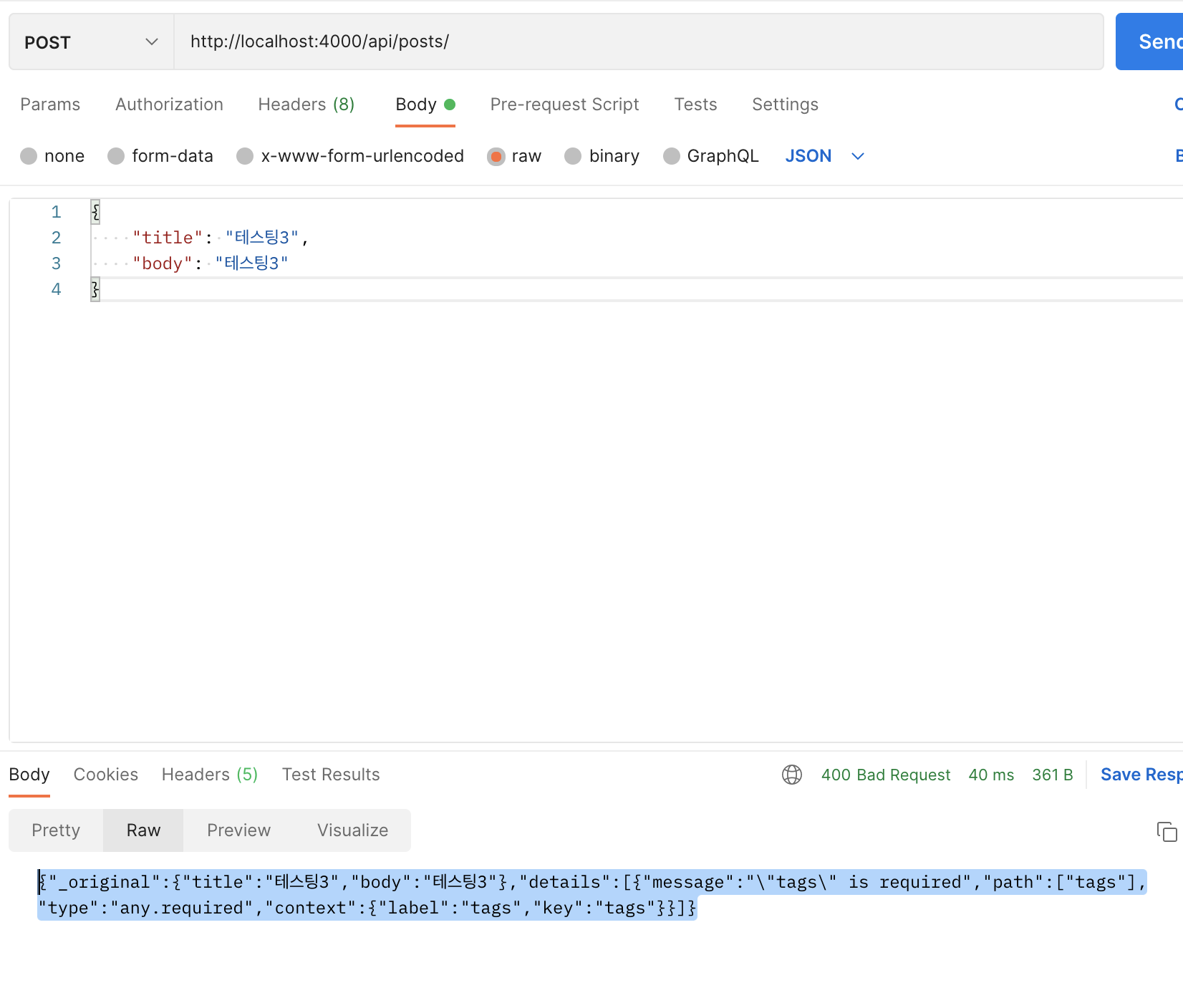
위와 같이 잘못된 형식의 body request를 보내면 400 Bad request를 띄우는 것을 보실 수 있습니다.
페이지네이션 구현
블로그에 포스트 목록을 볼 때 한 페이지에 보이는 포스트의 개수는 10~20개 정도가 적당합니다. 지금 만든 list API는 현재 작성된 모든 포스트를 불러옵니다. 포스트 개수가 몇 백 개라면 로딩 속도가 느려지겠죠? 또 포스트 목록을 볼 때 포스트 전체 내용을 보여 줄 필요는 없고, 처음 200자(글자) 정도만 보여 주면 적당합니다. 불필요하게 모든 내용을 보여 주면 역시 로딩 속도가 지연되고, 트래픽도 낭비될 것입니다.
따라서 list API에 페이지네이션(pagination)기능을 한번 구현해 보겠습니다.
간단히 가짜 데이터를 posts컬렉션에 추가하는 createFakeData.js를 생성하겠습니다.
// src/createFakeData.js import Post from './models/post'; export default async function createFakeData() { // 0, 1, ... 39로 이루어진 배열을 생성한 후 포스트 데이터로 변환 const posts = [...Array(40).keys()].map((i) => ({ title: `포스트 #${i}`, body: 'Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.', tags: ['가짜', '데이터'], })); await Post.insertMany(posts, (err, docs) => { console.log(docs); }); }
그 후, GET /api/posts 를 조금만 수정해 줍니다.
// src/api/posts/posts.ctrl.js ... export const list = async (ctx) => { const page = parseInt(ctx.query.page || '1', 10); if (page < 1) { ctx.status = 400; return; } try { const data = await Post.find({}) .sort({ _id: -1 }) .limit(10) .skip((page - 1) * 10) .exec(); ctx.body = data; } catch (e) { ctx.throw(500, e); } }; ...
쿼리로 ?page=1을 하면 오름차순으로 정렬된 문서들이 post39~post30이 나오게 되고 ?page=2를 하게 되면 post29~post20가 보여지는 식으로 페이지네이션의 틀을 잡았습니다.
마지막 페이지 번호 + 내용 길이 제한
// src/api/posts/posts.ctrl.js ... export const list = async (ctx) => { const page = parseInt(ctx.query.page || '1', 10); if (page < 1) { ctx.status = 400; return; } try { const posts = await Post.find({}) .sort({ _id: -1 }) .limit(10) .skip((page - 1) * 10) .lean() .exec(); const postCount = await Post.countDocuments().exec(); ctx.set('Last-page', Math.ceil(postCount / 10)); ctx.body = posts.map((post) => ({ ...post, body: post.body.length < 200 ? post.body : `${post.body.slice(0, 200)}...`, })); } catch (e) { ctx.throw(500, e); } }; ...
위와 같이 페이지네이션 작업을 진행해 줄 수 있습니다. 이에 대한 postman의 결과는 다음과 같습니다.
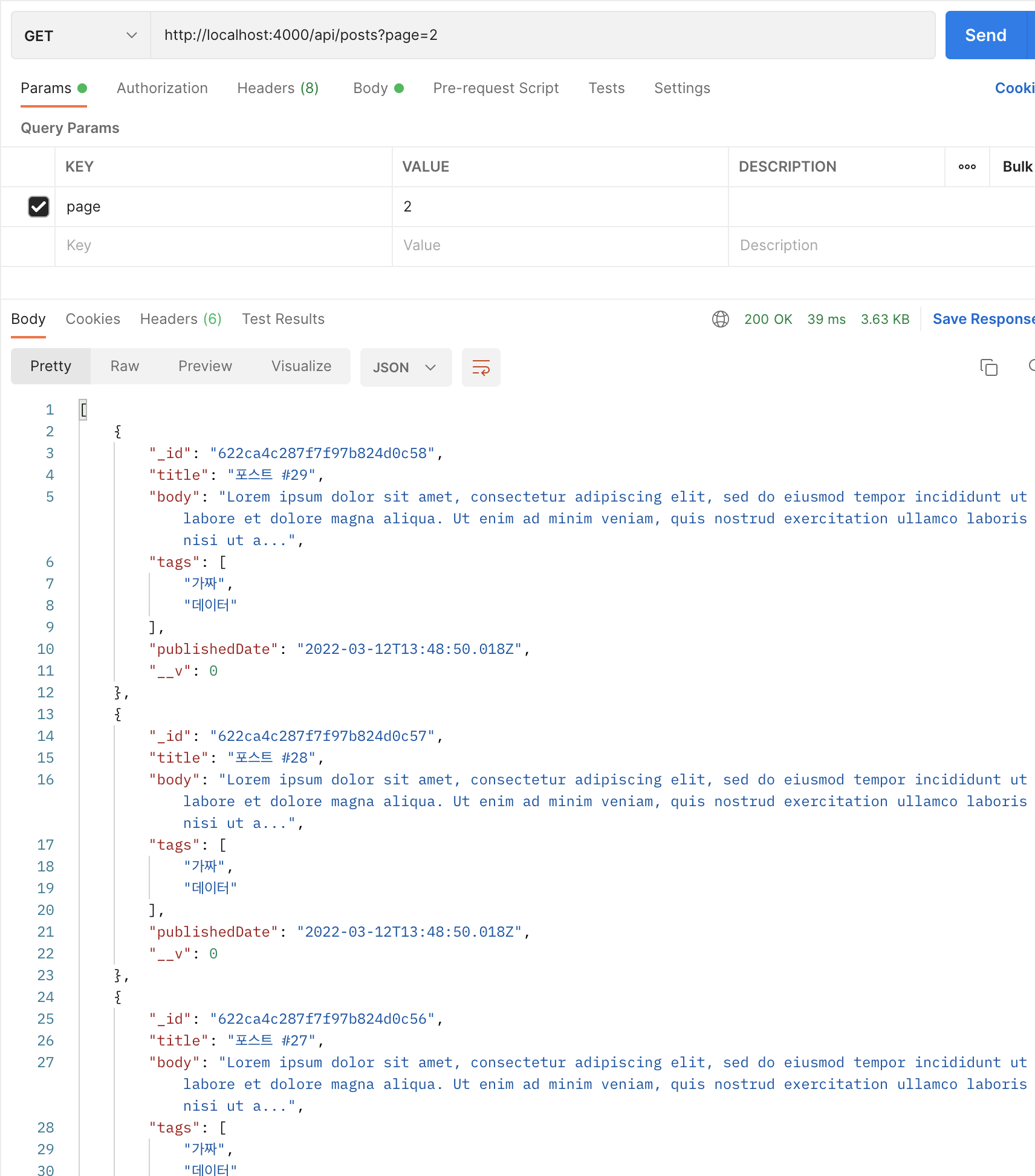
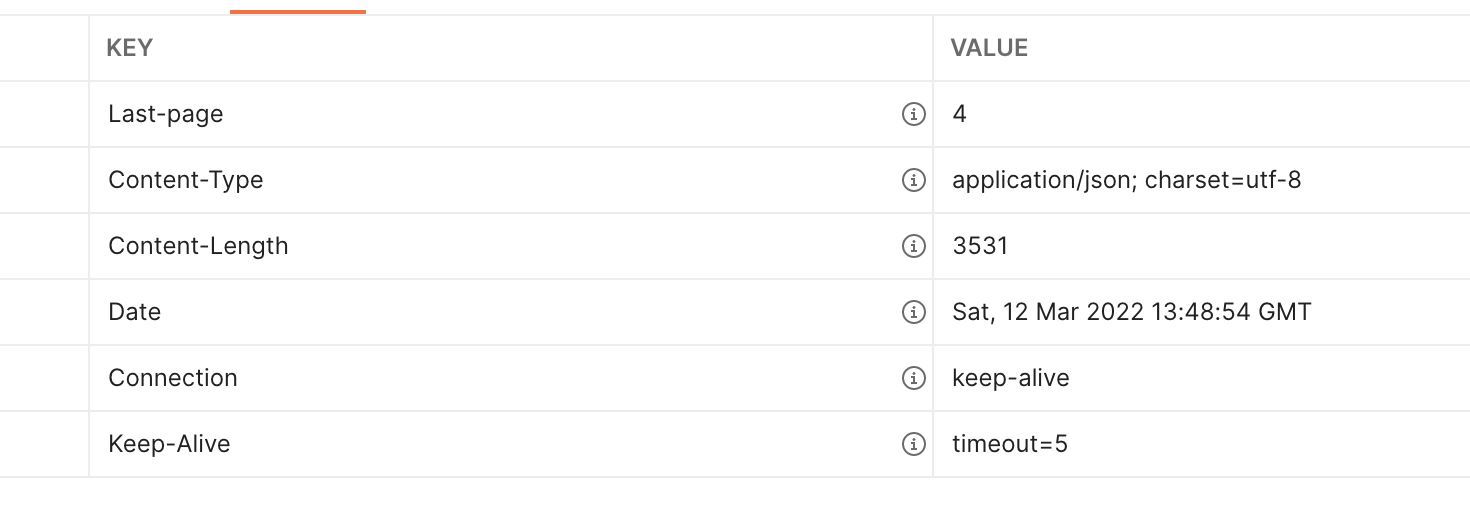
body의 길이가 200자로 제한 된 것을 볼 수 있고 Last-page가 4로 custom response header에 잘 설정 된 것을 보실 수 있습니다.
'React > ReactJs' 카테고리의 다른 글
| React - JWT (0) | 2022.03.13 |
|---|---|
| React - API의 활용을 위한 prototype (0) | 2022.03.13 |
| React - koa FrameWork (0) | 2022.03.09 |
| 나만의 Webpack 개발환경 만들기 plugin ( React ) (0) | 2022.02.27 |
| HTML - History API (0) | 2022.02.23 |