![[ 딥러닝 구현 - PRMI Lab ] - 트랜스포머(Transformer)의 구현](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fn1hqB%2FbtspNPUa7sH%2FKTHNugdDOtkhnKKcKXH6mK%2Fimg.png)
Self-attention vs CNN vs RNN

위의 그림에서 computation power를 비교하고 있습니다. Self-attention이 per layer마다 computation complexit가 O(n2˙d가 나오게 되는데, 여기서 n은 시퀀스의 길이, d는 인풋, 아웃풋 채널(size)라고 가정합니다. k는 커널 사이즈입니다.
그 이유는 Query, key, Value들은 [n, d]의 매트릭스일 것입니다. 바나다우 어텐션이 아니라 로웅 어텐션(=dot-attention)이라면 [n, d] matrix가 [d, n]과 곱해져 [n, n] matrix를 만들것이기 때문이죠. 그리고 Sequence operation은 O(1)로서 모든 토큰이 동시에작동합니다. 그리고 Maximum path length도 O(1)이 되는데, 한번에 계산되기 때문입니다.
이제 이전에 구현한 Attention Based (GRU | LSTM) Seq2Seq 모델을 Transformer형태로 3개의 (Self) Attention을 사용하여 그대로 PyTorch로 구현해보도록 하겠습니다.
auto-regressive한 decoder도 그대로 RNN에서 self-attention으로 교체할 수 있습니다. -> decoder의 masked attention로 autoregressive한 구조를 재현할 수 있기 때문!
그리고 구현하기 전에 Transformer에서 사용될 주요 파라미터를 정리하고 가겠습니다.
모델 파라미터 정리!
- dk,dq,dv=512: key, query, value의 차원 크기
- dff=2048: Transformer내 feedforward net의 은닉층의 차원 크기
- dmodel=512: 인코더 디코더 치원크기
- numlayers(N)=6: transformer layer의 총 층의 개수
- numheaders(h)=8: Attention을 병렬로 분할할 숫자 (분할 후 합치는 방식)
Attention 방법 정리!
- 인코더 self-atteiton: (k, q, v 모두 같음; encoder가 source)
- 디코더 masked self-attention: (k, q, v 모두 같음; decoder가 source)
- 디코더의 인코더-디코더 attention: (k, v: encoder, q: decoder)
- scaled dot-product attention을 사용
- multi-head attention: 집중에 필요한 부분을 분산해서 파악할 수 있게 함
Embedding 방법 정리!
- positional encoding: RNN과 다르게 attention 자체는시퀀스의 순서를 인지 못함.
- 삼각 함수(sin ,cos)을 이용하여 넣어줌
이제 본격적으로 PyTorch로 코딩을 시작해보도록 하겠습니다. 차고로 저는 대부분 아래의 코드는 아래의 링크에서 참고했습니다.
16-01 트랜스포머(Transformer)
* 이번 챕터는 앞서 설명한 어텐션 메커니즘 챕터에 대한 사전 이해가 필요합니다. 트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 Attention i…
wikidocs.net
https://pytorch.org/docs/stable/generated/torch.nn.Transformer.html
Transformer — PyTorch 2.0 documentation
Shortcuts
pytorch.org
Transformer 구현 시작!
https://hyunseo-fullstackdiary.tistory.com/413
[ 딥러닝 구현 - PRMI Lab ] - LSTM Based seq2seq model, Attention Based GRU seq2seq model
동기 CNN의 다양한 모델들에 대해 공부하면서, RNN과 관련된 시계열 데이터 관련 모델 뿐만 아니라 생성형 모델, 자연어 처리등에 대한 사전 지식의 필요성을 느꼈습니다. DETR을 공부하면서 Panoptic
hyunseo-fullstackdiary.tistory.com
우선 기본 뼈대는 위 링크를 참조하시기 바랍니다. 위 코드에서 그냥 핵심 모듈만 갈아끼운 예제 시작하겠습니다.
''' 트랜스포머 용으로 LightningModule을 새로 정의해준다. ''' class TransformerTranslateLightningModule(BaseTranslateLightningModule): def __init__(self, cfg: DictConfig): super().__init__(cfg) @abstractmethod def forward(self, src, tgt): raise NotImplementedError() def _forward(self, src, tgt, mode: str): # teacher forcing: # seq2seq 에서 많이 쓰인다. # src -> tgt autoregressive 학습하면, 맨 최초는 학습을 빠르게 한다. 근데, 미래부분 학습은? (앞부분 될때까지 기다리기 너무 힘들다...) # 랜덤으로 미래 정보도 조금 둬서 뒤에 있는 정보도 학습이 가능하게 하자 ! # 근데 0.5다? ==> 0.5 확률로 teacher_forcing을 하겠다 ! assert mode in ["train", "val", "test"] # get predictions # teacher_forcing 용 input --> tgt_inputs = tgt[:-1, :] # delete ends outputs = self(src, tgt_inputs) tgt_outputs = tgt[1:, :] # delete start tokens. loss = self.loss_function( outputs.reshape(-1, outputs.shape[-1]), # [[batch X Seq_size], other_output_shape] tgt_outputs.reshape(-1), ) logs_detail = { f"{mode}_src": src, f"{mode}_tgt": tgt, f"{mode}_results": outputs, } if mode in ["val", "test"]: _, tgt_results = torch.max(outputs, dim=2) src_texts = [] tgt_texts = [] res_texts = [] # convert [L X B X others] --> [B X L X others] for src_i in torch.transpose(src, 0, 1).detach().cpu().numpy().tolist(): res = vocab_transform[self.cfg.data.src_lang].lookup_tokens(src_i) src_texts.append(_text_postprocessing(res)) for tgt_i in torch.transpose(tgt, 0, 1).detach().cpu().numpy().tolist(): res = vocab_transform[self.cfg.data.tgt_lang].lookup_tokens(tgt_i) tgt_texts.append(_text_postprocessing(res)) for tgt_res_i in torch.transpose(tgt_results, 0, 1).detach().cpu().numpy().tolist(): res = vocab_transform[self.cfg.data.tgt_lang].lookup_tokens(tgt_res_i) res_texts.append(_text_postprocessing(res)) text_result_summary = { f"{mode}_src_text": src_texts, f"{mode}_tgt_text": tgt_texts, f"{mode}_results_text": res_texts, } print(f"{self.global_step} step: \n src_text: {src_texts[0]}, \n tgt_text: {tgt_texts[0]}, \n result_text: {res_texts[0]}") logs_detail.update(text_result_summary) return {f"{mode}_loss": loss}, logs_detail def training_step(self, batch, batch_idx): src, tgt = batch[0], batch[1] logs, _ = self._forward(src, tgt, "train") self.log_dict(logs) logs["loss"] = logs["train_loss"] return logs def validation_step(self, batch, batch_idx): src, tgt = batch[0], batch[1] logs, logs_detail = self._forward(src, tgt, "val") self.log_dict(logs) logs["loss"] = logs["val_loss"] logs.update(logs_detail) return logs def test_step(self, batch, batch_idx): src, tgt = batch[0], batch[1] logs, logs_detail = self._forward(src, tgt, "test") self.log_dict(logs) logs["loss"] = logs["test_loss"] logs.update(logs_detail) return logs
저는 transformer용으로 LightningMoudle을 새로 정의해 주었습니다. 저희는 이번 예제에서 teacher_forcing을 사용하지 않을 것이기 때문에, 다 없애줍니다. 이부분만 변경이 있었고, 나머지는 기존 BaseTranslateLightningModule과 동일합니다.
우리가 이번 트랜스포머를 구현함에 있어서 해야 하는 과정은 크게 아래 3가지 과정입니다.
- token_embedding
- positional_embedding
- nn.Transformer
먼저 token_embedding과 tokenembedding을 위한 nn.Module을 작성해줍니다.
class PositionalEncoding(nn.Module): def __init__( self, embed_size: int, # d_model dropout: float, maxlen: int = 5000 ): super().__init__() den = torch.exp(-torch.arange(0, embed_size, 2)*math.log(10000) / embed_size) pos = torch.arange(0, maxlen).reshape(maxlen, 1) pos_embedding = torch.zeros((maxlen, embed_size)) # [maxlen, embed_size] # sin: 2i pos_embedding[:, 0::2] = torch.sin(pos * den) # cos: 2i+1 pos_embedding[:, 1::2] = torch.cos(pos * den) pos_embedding = pos_embedding.unsqueeze(-2) # [1, max_len, embed_size] self.dropout = nn.Dropout(dropout) self.register_buffer("pos_embedding", pos_embedding) # nn.Module 내에서 cache처럼 사용할 수 있음 def forward(self, token_embedding: torch.Tensor): # token_embedding: [seq_len, embed_size(=d_model)] # token_embedding + pos_embedding <-- 딱 token_embedding 사이즈만큼만 취해서 element_wise하게 더해주어야 함. return self.dropout(token_embedding + self.pos_embedding[:token_embedding.size(0), :]) class TokenEmbedding(nn.Module): def __init__( self, vocab_size: int, embed_size: int, ): super().__init__() self.embedding = nn.Embedding(vocab_size, embed_size) self.embed_size = embed_size def forward(self, tokens: torch.Tensor): return self.embedding(tokens.long()) * math.sqrt(self.embed_size) # scaling for embedding
코드에 주석을 잘 이해할 수 있도록 짜보았습니다. PositionalEncoding에서는, 논문에서의 d_model(=embed_size), dropout rate, max_len(=seq_len최대길이)를 입력받도록 한다음에
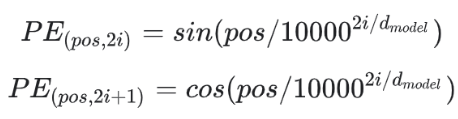
위 식을 그대로 구현해 주었습니다. 그리고 실제 token_embedding을 forward시에 받아서 positional_embedding의 matrix와 element wise하게 더해주었습니다.
그리고 TokenEmbedding은, 그냥 vocab_size, embed_size를 받아서 nn.Embedding을 늘 해오던 대로 Word2Vec 원리를 이용해서 구현한 것입니다. 참고로, 여기서 forward를 할 때에 math.sqrt(self.embed_size)는 아래와 같이 scale.dot attention을 사용했기 때문에 scaling을 해준것입니다.
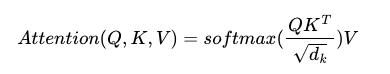
참고로 트랜스 포머에서 Attention(Q, K, V)의 결괏값의 matrix shape은 입력 src나 tgt와 동일한 것이 이전 포스팅에서도 큰 특징이라고 했었습니다.
이제 그럼 사전작업이 완료된거 같으니, Transformer를 구축해봅시다.
class TransformerSeq2Seq(TransformerTranslateLightningModule): def __init__(self, cfg: DictConfig): super().__init__(cfg) self.cfg = cfg num_encoder_layers = self.cfg.model.num_encoder_layers num_decoder_layers = self.cfg.model.num_decoder_layers embed_size = self.cfg.model.embed_size nhead = self.cfg.model.nhead src_vocab_size = self.cfg.model.src_vocab_size tgt_vocab_size = self.cfg.model.tgt_vocab_size dim_feedforward = self.cfg.model.dim_feedforward dropout = self.cfg.model.dropout self.transformer = Transformer( d_model = embed_size, nhead = nhead, num_encoder_layers = num_encoder_layers, num_decoder_layers = num_decoder_layers, dim_feedforward = dim_feedforward, dropout = dropout ) self.generator = nn.Linear(embed_size, tgt_vocab_size) # emb_size를 tgt_vocab_size로 바꿔주는 generator가 필요하다. self.src_token_emb = TokenEmbedding(src_vocab_size, embed_size) self.tgt_token_emb = TokenEmbedding(tgt_vocab_size, embed_size) self.positional_encoding = PositionalEncoding(embed_size, dropout=dropout) def generate_square_subsequent_mask(self, sz: int): # [sz, sz](type=bool)의 하각삼각행렬을 mask로 만들어 주는 util함수를 만들어 준다. mask = (torch.triu(torch.ones((sz, sz), device=self.device)) == 1).transpose(0, 1) # mask == 0 인 곳을 -inf로 만들어 버린다. mask == 1인 곳은 그냥 0으로 취해준다. mask = mask.float().masked_fill(mask == 0, float("-inf")).masked_fill(mask == 1, float(0.0)) return mask def create_mask(self, src, tgt): src_seq_len = src.shape[0] # [seq_len] tgt_seq_len = tgt.shape[0] # [seq_len] # --> 두개의 seq_len은 다를 수 있음, 그 이유는 배치에서 가장 큰 사이즈에 맞춰서 <pad>를 박아버리기 때문 # mask self-attention을 위한 과정 tgt_mask = self.generate_square_subsequent_mask(tgt_seq_len) # encoder self-attention을 위한 과정 src_mask = torch.zeros((src_seq_len, src_seq_len), device=self.device).type(torch.bool) src_padding_mask = (src == self.cfg.data.vocab.special_symbol2index["<pad>"]).transpose(0, 1) tgt_padding_mask = (tgt == self.cfg.data.vocab.special_symbol2index["<pad>"]).transpose(0, 1) return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask def forward(self, src: torch.Tensor, tgt: torch.Tensor): src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = self.create_mask(src, tgt) memory_key_padding_mask = src_padding_mask src_emb = self.positional_encoding(self.src_token_emb(src)) tgt_emb = self.positional_encoding(self.tgt_token_emb(tgt)) outs = self.transformer( src_emb, tgt_emb, src_mask, tgt_mask, None, src_padding_mask, tgt_padding_mask, memory_key_padding_mask ) return self.generator(outs) def encoder(self, src: torch.Tensor, src_mask: torch.Tensor): # transformer.encoder에 접근해서 encoder가 어떻게 생겨먹었는지 확인할 수 있다. return self.transformer.encoder(self.positional_encoding(self.src_token_emb(src)), src_mask) def decoder(self, tgt: torch.Tensor, memory: torch.Tensor, tgt_mask: torch.Tensor): # transformer.decoder에 접근할 수 있다. TRANSFORMERDECODERLAYER의 forward부분을 참고하면된다. return self.transformer.decoder(self.positional_encoding(self.tgt_token_emb(tgt)), memory, tgt_mask)
torch.nn.Transformer의 파라미터에는 많은 매개변수가 필요합니다.

이는 우리가 위에서 정의할 파라미터를 설명할때 나온것과 일치하는 것이지요. 우리는 d_model은 그대로 512을 사용할 것이기 때문에, 냅두겠습니다. 그리고 nhead=8 논문값 그대로를 사용할 것입니다. num_encoder_layers, num_decoder_layers는 논문 상에서는 6이지만, 실제로는 빠르게 학습시키기 위해 3으로 설정할 것입니다. dim_feedforward도 적당히 512로 설정해주고, dropout은 0.5이렇게 설정해 줄것입니다.
그리고 우리는 트랜스포머의 학습을 더 빠르고 효율적으로 하기 위해 encoder, decoder의 임베딩 결과에 masking을 해줄것입니다.
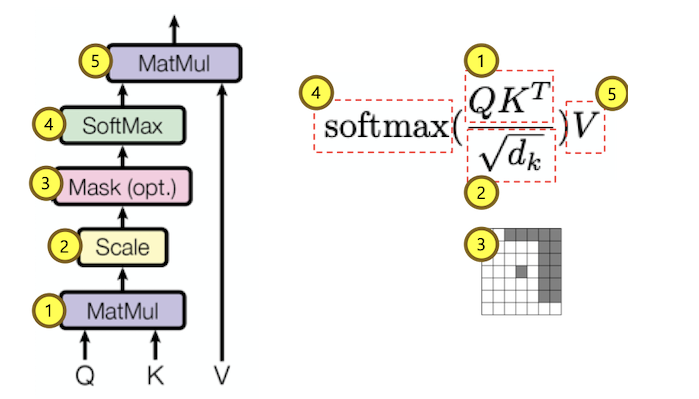
우리가 임베딩 하고 나면, <pad> 이런게 Attention matrix에 포함되게 되는데, 불필요하니까 그냥 −inf로 설정해 주어서, softmax값을 취하면 0으로 수렴하게 하겠다는 것이죠. 또, decoder self-attention에서는 mask가 cheating을 방지하기 위해 무조건 필수적으로! 수행되어야 합니다. 그래서 위 모델에서는 encoder, decoder용 mask를 공통 util함수를 정의하고 따로 만들어 주었습니다.

이 부분이, 설명한 부분입니다. 아마 연습으로 찍어보시면서 주석을 읽어보시면, 무슨 말인지 충분히 이해할 수 있을겁니다. 이해가 안되더라도 많은 소스에 위와관련된 구현 내용이 있으므로 보시길 추천드립니다.

그리고 위와같이. 실제로 torch.nn.Transformer의 encoder, decoder 구현체를 참조해서 찍어볼 수도 있습니다.
https://pytorch.org/docs/stable/_modules/torch/nn/modules/transformer.html#Transformer
torch.nn.modules.transformer — PyTorch 2.0 documentation
Shortcuts
pytorch.org
여기 실제 SOURCE에서. ".encoder", ".decoder"를 검색하면 충분히 찾아서 참조할 수 있을겁니다. encoder, decoder의 pytorch에서의 구현체 타입이 달라서 인자도 다르게 넣어주어야 한다는점 주의하시고요!
그다음에 우리가 정의한 모델 하이퍼파라미터를 정의합니다.
model_translate_transformer_seq2seq_cfg = { "name": "TransformerSeq2Seq", "num_encoder_layers": 3, "num_decoder_layers": 3, "embed_size": 512, "nhead": 8, "src_vocab_size": len(vocab_transform[data_cfg.src_lang]), "tgt_vocab_size": len(vocab_transform[data_cfg.tgt_lang]), "dim_feedforward": 512, "dropout": 0.5, }
그리고 hydra에 설정한 configuration을 적용합니다.
# initialization & compose configs hydra.initialize(config_path=None, version_base="1.1") cfg = hydra.compose("transformer_based_seq2seq_de_en_translate")
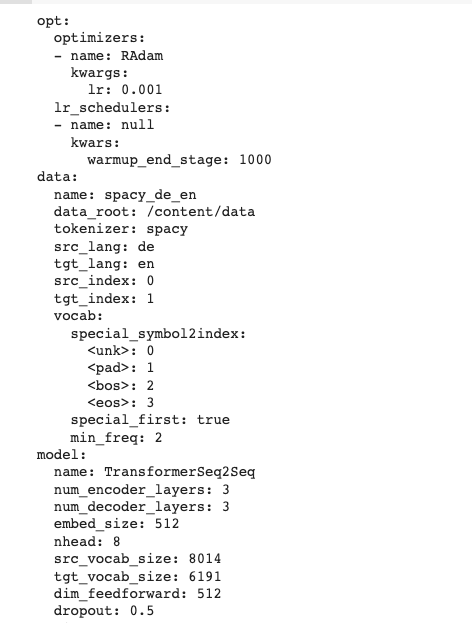
잘 적용이 되었군요! 그 다음에는 get_pl_model을 통해 cfg.model.name == "TransformerSeq2Seq"에 대한 모델을 추가해줍니다.
def get_pl_model(cfg: DictConfig, checkpoint_path: Optional[str] = None): if cfg.model.name == "LSTMSeq2Seq": model = LSTMSeq2Seq(cfg) elif cfg.model.name == "AttentionBasedSeq2Seq": model = AttentionBasedSeq2Seq(cfg) elif cfg.model.name == "TransformerSeq2Seq": model = TransformerSeq2Seq(cfg) else: raise NotImplementedError("Not implemented model") if checkpoint_path is not None: model = model.load_from_checkpoint(cfg, checkpoint_path=checkpoint_path) return model model = None model = get_pl_model(cfg) print(model)

아나볼릭하게 잘 정의가 되었군요. torch.nn.Transformer의 실제 구현체는 아까도 말했지만 SOURCE를 참고하세요! 아마 위 내용이 다 이해가실겁니다. 저희는 encoder-decoder attention, layer-normalization, FFN의 구체적인 구현은 다루지 않았으니까요
그리고 Trainer를 통해 validation set을 찍어본 결과는 아래와 같습니다.

어느정도 맥락을 잘 파악하고 있는 것을 볼 수 있죠?? wandb matric도 보겠습니다.
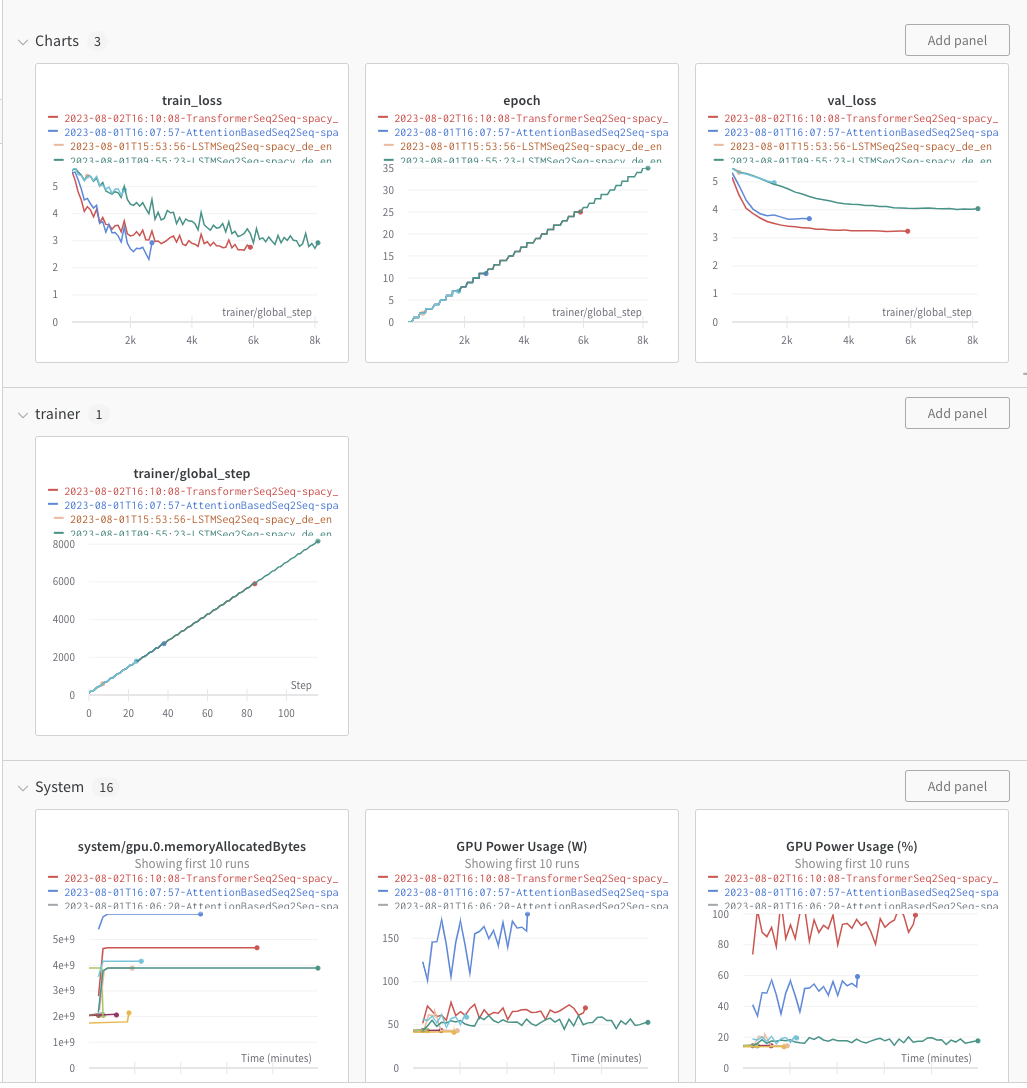
실제 논문상과 다르게 layer의 크기도 다르게 하였고 FFN의 hidden-dim도 다르게 설정해주어서 이전에 보았던 Attention Based GRU Seq2Seq보다 성능이 어떻게 보면, 아주 조금만 개선이 된것을 볼 수 있습니다.
다음 포스팅에서는 이 transformer의 Variation등에 대해서 간단히 훑고 BERT, GPT모델들에 대해서 잠깐 보고, VAE --> GAN으로 가는 식으로 살펴보도록 하겠습니다.