![[ 딥러닝 최신 알고리즘 - PRMI Lab ] - CNN의 응용 (R-CNN계열, YOLO., SSD., FPN., RetinaNet., EfficientDet., FCN., DeConvNet., UNet., SegNet.,.. )](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FnQxWK%2FbtsplrmiD4t%2FuHi7ZCydfCxYJkGFlWQPXk%2Fimg.png)
CNN의 응용분야에는, 이전에 포스팅이서도 다루었지만 Object classification, Object detection, Sementic segmentation, Inst ance segmentation,.. 등등이 있었습니다. 말 그대로 물체 분류, 객체 탐색, 의미론적 분할, 인스턴스 분할입니다.

여기에는 R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN, FPN,.... 등등 많은 응용 네트워크등이 있었습니다. 이번에는 이러한 흐름에 제가 다루지 않았던 네트워크를 포함해서 흐름을 타고타고 들어가서 CNN 응용분야의 트렌드를 한눈에 알아보겠습니다.
좋은 Object proposal 방식
좋은 Object proposal 방식이란, Localization시 bottlenect이 되지 않아서 FPS가 빨라야 합니다. 또한 Recall(=재현율) 객체를 포함하고 있는 bounding box를 높치지 않아야 하며, 최소한의 지도학습이 포함되어야 합니다.
이러한 방법에는, 각각의 윈도우에서 객체를 인식하는 Slinding Window detection, 각 패치 및 키포인트를 찾은 후, Voting을 하는 방법, Segmentation 기반 Selective search등이 있었습니다.
Selective search를 거쳐 나온 물체가 존재하는 후보 영역중에 ground table과 overlap되는 부분이 20~50%되는 것을 "negavite sample"로 정의하고 Ground Truth; positive sample과 함께 SVM에 학습시킬 수 있습니다.
위와같이 반복적으로 FP(=False Positive)를 넣고 재학습을 하여 모델 성능을 개선시키는 방법이 바로 R-CNN이였죠!
R-CNN (2014)
위와같이 R-CNN(=Regional proposal + CNN), CNN을 Object Detection 분야에 접목한 첫번째 네트워크입니다. 이는 Selective serach와 CNN feature를 결합하고, 최종적으로 linear SVM을 분류하고자 하는 class 개수 N + 1(=배경)으로 최종적으로 분류합니다.
여기서의 주요 특징을 다시 짚고 가면, 이때는 pre-trainede된 VGG Net, Alex Net등을 Feature extract model로 사용하였기 때문에, input이 특정 크기에 맞추어 주었어야 했습니다.(=VGG는 input 224x224x3) 그래서 Region Proposal 결과를 Warp하는 과정을 통해 CNN feature map을 추출했습니다.
그 후, linear-SVM을 통해 최종 분류를 하고, Bounding Box Regression을 통해 Bounding box를 fine tune하는 과정을 거치는 일련의 과정을 반복하는 것입니다.
이는 2014년 당시 SOTA였습니다. 하지만 이는 상용화되기 매우 느렸고, End-to-End가 아니였습니다. 또한, 모델이 깊어지면 깊어질 수록 너무 모델이 느려서 실시간 이미지 처리를 Applciation 단에서 처리할 수 없어서 실제로 FPS가 5도 나오지도 않아서 많은 한계점이 있었습니다. 하지만 딥러닝 모델을 중간중간 많이 써서 성능 향상할 수 있는 요소가 많아서 Obejct Detection의 연구가 본격적으로 활성화 되었습니다. (R-CNN은 많은 Baseline 논문이 되었음)
SPP-Net & Fast R-CNN (2014~2015)
기존에 R-CNN에서는 만약 Regional Proposal의 결과가 2K개였는데, 이의 전체가 CNN에 들어가서 엄청난 연산 오버헤드가 일어난다는 단점이 있었습니다. SPP-Net과 Fast R-CNN은 이 부분을 전체 이미지를 convolutional net에 한번 통과시키는 것만으로도 feature map을 추출할 수 있다는 장점이 있는 네트워크 입니다.
SPP-Net
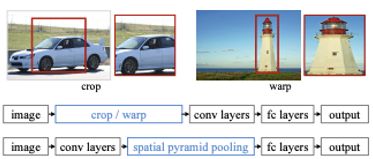
위와같이 R-CNN방식에서 warp을 하면 데이터의 localization이 잘 하지 못합니다. 왜냐하면 실제 물체의 정보가 많이 손실되기 때문이죠.
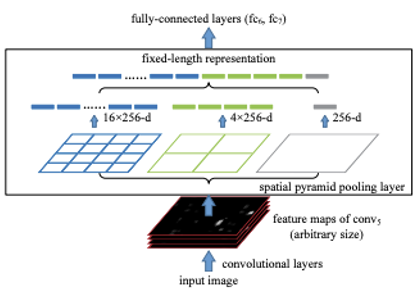
그래서 위와같이 spatial pyramid pooling layer를 두어서 격자를 많이 두어서 다양한 공간상에서의 Regional feature를 뽑아낼 수 있게 했었습니다. 여기서 만약 pyramid level이 4라면 {6x6, 3x3, 2x2, 1x1} 이런식의 conv filter를 사용합니다. 그리고 뒤에서 보겠지만 Fast R-CNN방식에서 RoI pooling의 경우는 level이 1인 특수한 경우를 말합니다.
Fast R-CNN
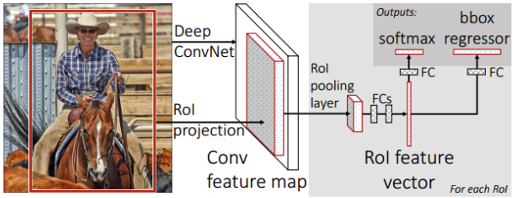
Fast R-CNN은 위와 비슷하게, 먼저 전체 이미지를 Pre-trained된 CNN에 넣어 가변 size의 feature map을 추출합니다. 참고로 Fast R-CNN의 입력 이미지는 FCN에 집어넣기 때문에 사이즈에 제한이 없습니다.
이제 본 이미지에서 Selective Search의 결과를 feature map에 RoI Pooling을 진행하고, 그 결과로 고정된 크기의 feature vector를 얻게 됩니다.
그 후에, feature vector는 fully-connected layer들을 통과한 뒤, 두 개의 브랜치로 나뉘어 Multi-task Loss를 계산하게 됩니다. 여기에서 한쪽은 해당 RoI가 어떤 물체인지 Classification하는 것이고, 다른 한쪽은 bounding box regression을 통해 selective search 박스의 위치를 fine tune하게 됩니다.
Recap) Multi-task loss: Classification Loss + Bounding Box Regression Loss를 합친 식으로써 전자는 softmax를 통해 계산되는 cross-entropy loss가 일반적이고, 후자는 Fast R-CNN에서는 Smooth L1 loss라는 특정한 손실 함수가 사용됩니다.
이런식으로 여러 작업에 대한 손실을 결합하는 방식을 'multi-task loss'라고 합니다
이는 기존에 R-CNN과 비교했을 때, End-to-End 학습이 가능해지며, R-CNN이 47sec가 걸리던 것을 Fast R-CNN은 0.32sec만에 처리할 수 있는 성능의 변화를 이끌어 냈다고 합니다.
Faster R-CNN
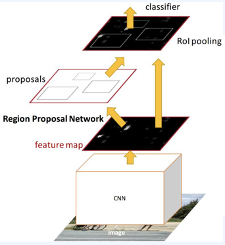
어떻게 보면 Fast R-CNN에서 성능을 제한하는 bottleneck 요소가 Selective Search부분이였습니다. 그래서 Faster R-CNN은 이를 해결하고자 selective search를 제거하고 RPN을 통해 region proposal을 생성했었습니다.
RPN은 이미지의 일부를 인풋으로 받고, binary classification(존재/비존재를 파악하는), bounding-box regression(Fast R-CNN에서와 동일)이 2가지 task를 수행하는 작은 네트워크를 구성합니다. 그리고 최종적으로 마지막 공유 컨볼루션 레이어의 컨불루션 feature map위로 작은 네트워크를 slide하며 결괏값을 얻습니다.
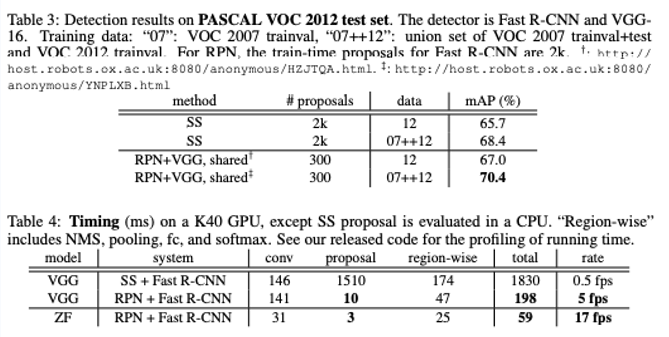
그 결과 selective search + Fast R-CNN 대비 accuracy와 speed 둘다 개선되었었습니다. 이는 17fps(frame per seconds)는 거의 real-time이어서 실제 상업적으로 이용할 수 있는 최초의 모델이였습니다.
YOLO (2015: v1, 2016: v2, 2018: v3, 2020: v4, v5, PP-YOLO, ...)
기존에 region proposal + classification 2단계로 이루어졌는데 이러한 방식이 어떻게 보면 real-time을 해치는 bottleneck일 수 있습니다. 그래서 이를 개선하기 위해 1-stage 모델인 YOLO (=You Only Look Once)가 등장하게 되었습니다. 이는 제가 논문 리뷰를 올리지 않았는데, 추후에 올려보도록 하겠습니다. 대신 지금은 간단히 정리하는 시간을 가지겠습니다.
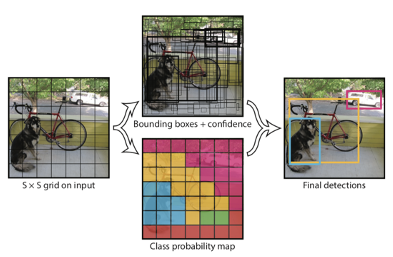
YOLO는 regional proposal 대신에 direct하게 한번에 객체를 찾는 과정을 수행합니다. 이에 대한 수행방법을 아래에 정리해보겠습니다.
1) S x S grid영역으로 나누고 B 개의 bounding box를 예측합니다. (x, y, w, h)
2) 신뢰도를 나타내는 confidence score를 계산
-> 그리드에 물체가 있을 확률 X 예측한 박스의 ground truth 박스와의 겹치는 영역을 비율로 나타내는 IoU를 계산. 위에서 색칠해져있는 S x S 그리드가 이에 해당합니다.
그리고 최종적으로 grid를 결합하면서 Final detection을 하는 과정을 거치게 됩니다. 이는 현재 v8까지 나오며 real-time object detection을 이끌고 있는 연구 시리즈입니다! 너무 흥미롭네요
SSD (2016)
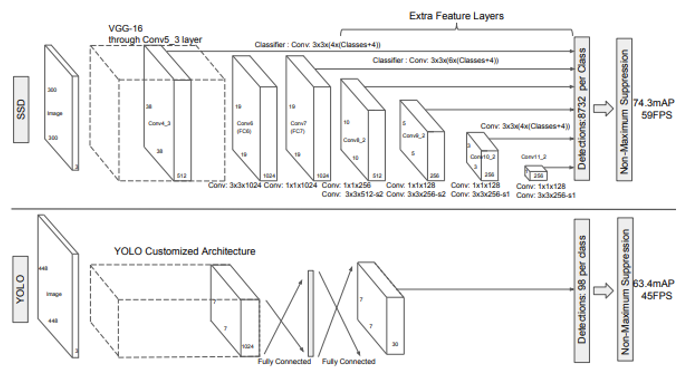
SSD (= Single shot multi-box detector)는 기존에 유행하던 VGGNet에 추가적인 layer를 추가하고, ResNet의 skip connection으로 여러 개의 feature map을 구성해보면 어떨까에서 시작되었습니다.
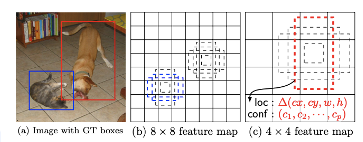
기존의 YOLO에서는 고정된 grid여서 취약한 점이 많았습니다. 그래서 위 그림을 보면 SDD에서는 다양한 feature map의 결과를 skip-connection의 결과로 classification의 식에 투입하고 있는걸 볼 수 있습니다. 이를 통해 다른 사이즈의 객체를 훨씬 잘 인식할 수 있었다고 합니다.
이를 통해 YOLO v1보다 더 좋은 AP를 지녔지만 YOLO v2에 다시 역전당했다고 합니다.
Feature Pyramid Network (2017)
한편, 객체 탐색 분야의 난제 중 하나인 '작은 물체'를 탐색하는 문제가 있습니다. 이는 SDD에서 어느정도 개선을 했지만, SDD보다 더 개선한 모델을 제시한것이 FPN (=Feature Pyramid Network)입니다.
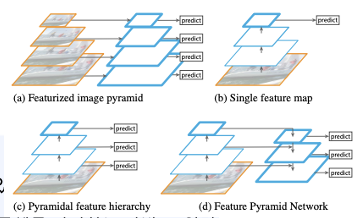
(a) 는 입력 이미지 자체를 여러 크기로 resize한 뒤, 각각의 이미지에서 물체를 탐지하는 방법입니다.
-> 입력 이미지 자체를 여러 크기로 복사하여 연산량 자체가 많습니다.
(b) 는 CNN 신경망을 통과하여 얻은 최종 단계의 피쳐맵으로 Object Detection을 수행하는 기법입니다. (YOLO)
(c) 는 CNN 신경망을 통과하는 중간 과정에 생성되는 피쳐맵들 각각에 Object Detection을 수행하는 기법입니다. (SSD)
-> 피처맵의 크기를 다양한 형태로 rescale 하는 접근 방식을 사용한 것입니다.
(d) 는 먼저 신경망을 통과하면서 단계별로 피쳐 맵들을 생성합니다. 그리고 가장 상위 레이어에서부터 거꾸로 내려오면서 피쳐를 합쳐준 뒤, Object Detection을 진행합니다.
-> b, c만큼 빠르지만, 보다 정확하다고 합니다.

위와같이 그냥 계산된 피쳐맵을 재활용하기 때문에 추가적인 연산 없이 nearest neighbor upsampling(=upsampling)과 1x1 convolution을 통해 더해주는 과정을 통해서 구현이 간단히 가능합니다.

위와같은 방법만으로도 다른 모델들에 비해 성능이 높아졌음을 확인할 수 있습니다.
RetinaNet (2017~2018)
기존에 Object detection 모델은 이미지 내의 객체의 영역을 추정하는 Regional Proposal을 진행하고 IoU threshold에 따라 positive/nevagitive sample을 구분한 후, 이를 활용하여 학습을 진행시켰습니다.
하지만 일반적으로 이미지 내 객체의 수가 적기 때문에 positive sample(객체 영역)은 negative sample(배경 영역)에 비해 매우 적습니다. 그래서 class imbalance 문제가 발생해서 모델의 성능이 하락하게 되는 문제가 있었습니다.
이러한 문제가 Two-stage detector 계열의 모델(i.e Fast R-CNN)은 이러한 문제를 해결하기 위해
1) two-stage cascasde, 즉 region proposals를 추려내는 방법을 적용하여 대부분의 background sample을 걸러주었습니다.
2) positive/negative sample의 수를 적절하게 유지하는 sampling heuristic 방법(i.e. hard negative mining, OHEM)등을 적용해주었었습니다.
하지만 이러한 방법을 one-stage detector에는 적용하기 어려웠습니다. 그이유는 one-stage detector(i.e. YOLO)는 region proposal 과정이 없어 전체 이미지를 빽빽하게 순회하면서 sampling하는 dense sampling 방법을 수행합니다. 그래서 two-stage detector보다 거르는 작업이 없어 훨씬 많은 후보 영역을 생성해서 Class imbalance 문제가 two-stage detector보다 더 심각했습니다.
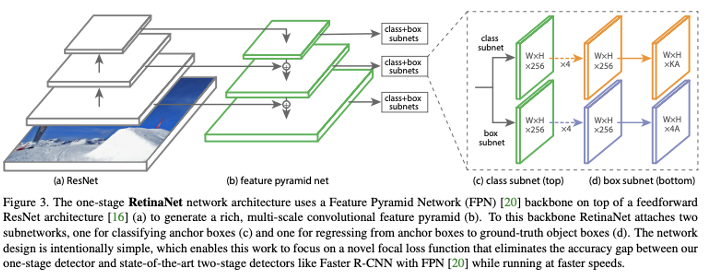
그래서 RetinaNet은 기본적으로 FPN 백본과 두 가지 스케일에 대한 클래스 및 박스 예측을 위한 두 가지 작업 특정 헤드로 이루어지게 됩니다. 또한 RetinaNet은 Focal Loss라는 특수한 손실 함수를 도입하였습니다. 이는 훈련 데이터 중에서 쉬운 예제(simple example)과 어려운 예제 간의 균형을 맞추는 것을 목표로 하는 손실함수입니다.
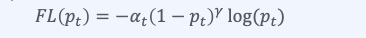
위와같이 cross entropy loss에 class에 따라 변하는 동적인 scaling factor를 추가한 상태입니다. 이는 easy example의 기여도를 자동으로 down-weight하며, hard example에 대해 가중치를 높혀 학습을 집중할 수 있게 합니다.
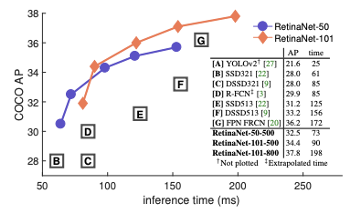
이에 위와같은 기존 one-stage 모델보다 model imbalance를 개선하여 AP성능이 좋았다고 합니다.
EfficientDet (2019~2020)
그리고 이제 Auto-ML로 효율적인 구조를 찾았던 efficientNet의 object detection으로의 응용 연구가 진행되었습니다.
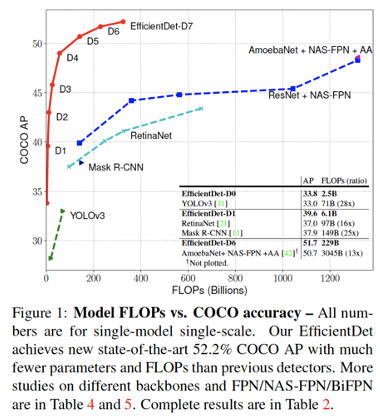
이는 앞선 FPN연구에서 사용하는 feature fusion 방법을 nerual architecture search (NAS) 방법을 이용해 찾을 수 있었다고 합니다.
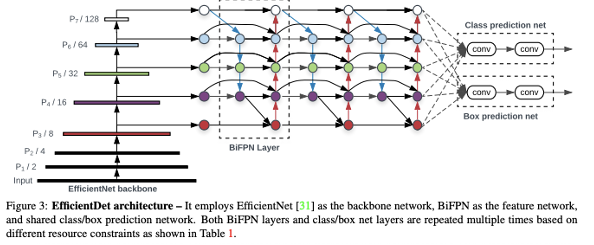
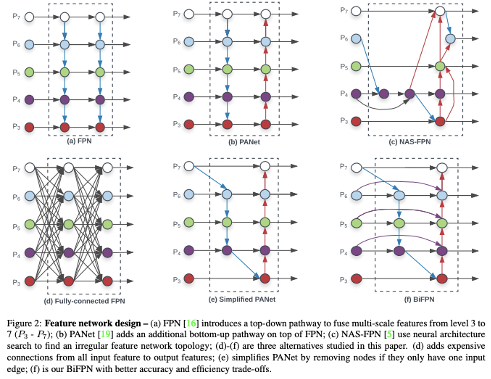
위와같은 FPN에서 사용되는 feature fusion의 다양한 방법을 NAS(=Auto-ML)을 통해 찾은 bi-direction 형태의 BiFPN을 NAS가 변형한 (f)가 선택되어 결과가 나와서 기존보다 파라미터수가 적고 성능도 좋은 모델이 탄생하였습니다.
Fully Convolution Net (2014~2015)
바로 FCN입니다. 이는 다룬적이 있지만, Semantic Segmentation에서 주로 사용되는 네트워크입니다. 이는 맨 마지막, Dense layer 대신 1x1 conv를 사용하여, output의 heatmap을 만들어 냅니다.
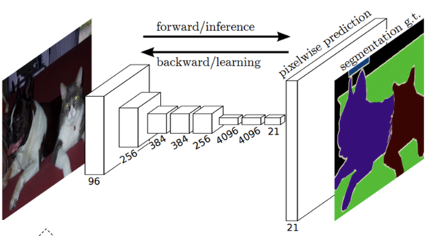
최종적으로 heatmap에 upsampling 기법을 활용하여 semantic segmentation을 만들어내는 방법입니다.
FCN: Upsampling
맨 마지막에 upsampling을 통해서 semantic segmentation을 만들어낸다고 했습니다.
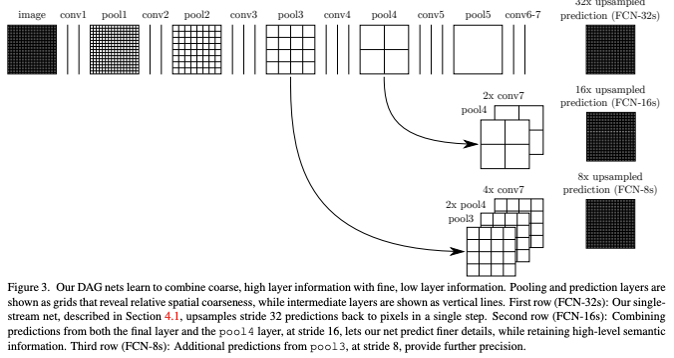
위와같이 heatmap을 여러 레이어에서 upsampling 기법을 활용하여 semantic segmentation을 FCN에서는 만들어 냅니다. 여기서 어떤 레이어를 쓰느냐에 따라 segmentation의 resolution이 달라지겠죠.

그리고 upsampling 방법에는 크게, Unpooling (pooling의 복원)과 transpose convolution (stride에 의한 축소 복원)이 있습니다.
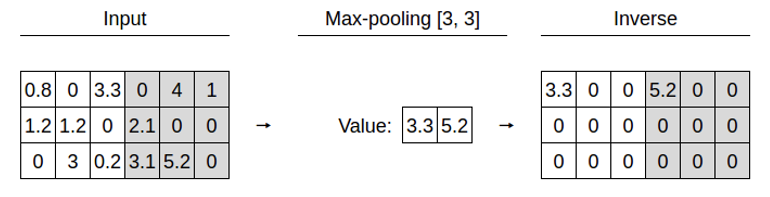
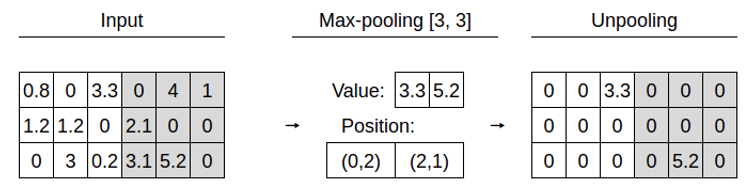
위와같은 방법이 Unpooling입니다.
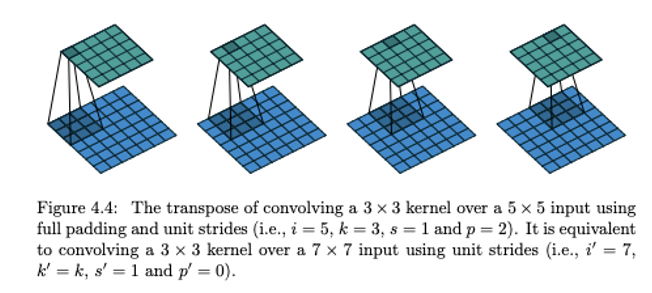
위는 역 convolution이라고도 말하는 transpose convolution입니다. 위에서 feature map(5x5)에서 각 값을 선택하고 선택한 scalar값과 필터 (3x3)를 곱합니다. 그리고 출력의 3x3 공간에 그 값을 넣습니다. 그리고 filter의 크기와 stride의 크기에 의해 overlap되는 부분은 전부 더하면 됩니다.
Deconvolution Net (2015)
FCN은 fixed-size receptive field 때문에, 신경망이 오직 하나의 scale 이미지만을 다룰 수 있습니다. 그러므로 receptive field보다 작거나 큰 객체는 mislabeled되거나, 잘개 쪼개집니다.

그래서 DeepConvNet이 등장하게 됩니다.
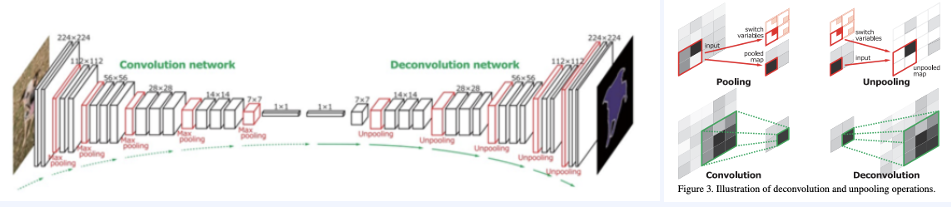
FCN에서 발전시켜 점진적, 대칭적으로 unpooling을 한 것입니다. 이는 VGGNet을 통과한 후에 2개의 Fully Connected layer를 Conv, Transposed Conv사이에 사용합니다.
여기서 convolution은 입력 이미지에서 특징을 추출하기 위해 사용되고, deconvolution은 convolution이 추출한 특징에서 segmentation을 수행합니다. 당연히 deconvolution의 깊이가 깊을 수록 세밀한 mask를 더 잘 추출할 수 있게 됩니다.
Deconvolution Net은 2stage Training을 진행합니다. 1-stage에서는 쉬운 예제로 train하고 2-stage는 어려운 데이터 진행합니다.
1-stage) 실제 정답 object를 crop하여 이를 중앙으로 하는 bounding box를 만들어 학습 (ground-truth annotation)
2-stage) 실제 정답을 crop하기 전에 실제 정답과 잘 겹치는 것들을 활용하여 2차 학습을 진행합니다.
U-Net (2015~2016)
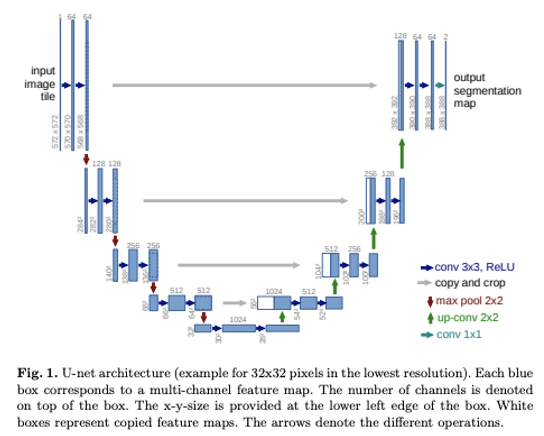
U-Net의 과정은 말 그대로 U모양입니다. 여기서 Pooling indice를 사용하는 대신, 전체 feature map이 encoder에서 decoder로 skip-connect형태로 수행되고 concatenate됩니다. 그리고 이는 데이터가 적은 Biomedical domain에서 처음 활용하도록 제시되었습니다.
U-Net은 3부분으로 나누어 볼 수 있습니다.
1) Contracting Path: 점진적으로 넓은 범위의 이미지 픽셀을 보며 의미정보 (Context Information)을 추출합니다.
2) Bottle Neck: 수축 경로에서 확장 겨로로 전환되는 전환 구간
3) Expanding Path: 의미정보를 픽셀 위치정보와 결합(Localization)하여 각 픽셀마다 어떤 객체에 속하는지를 구분
이를 잘 가시화한 위키독스 그림을 통해 설명하겠습니다.
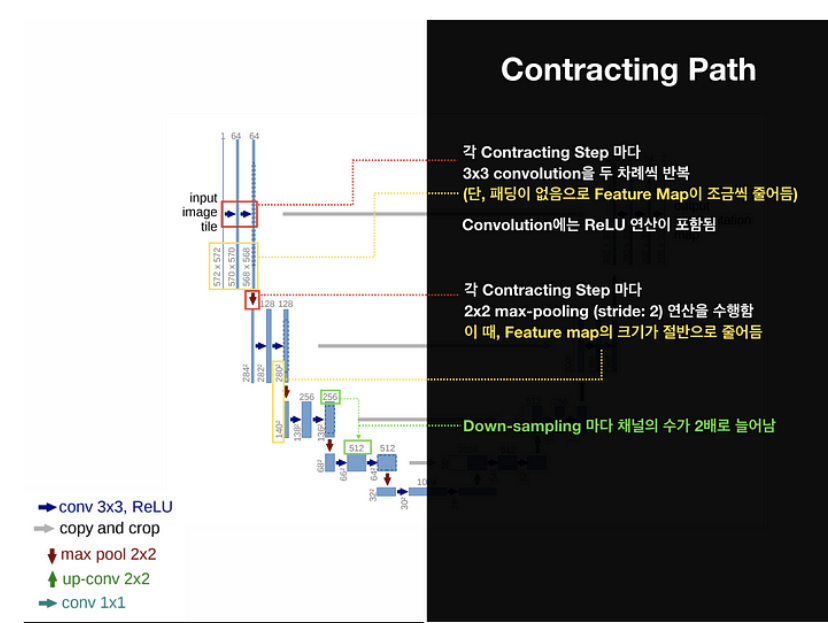
위와같이 각 Contracting Step마다 3x3 conv을 두차례 반복합니다. 여기서는 패딩을 사용하지 않아서 Feature map이 조금씩 줄어드는걸 552 -> 570 -> 558로 줄어드는 것을 볼 수 있죠. 그리고 각 Contracting Step마다 2x2 max-pooling (stride=2)를 수행해서, Feature map의 크기를 절반으로 만듭니다. 즉 Down-sampling마다 채널 수가 2배로 늘어나는걸 볼 수 있죠.
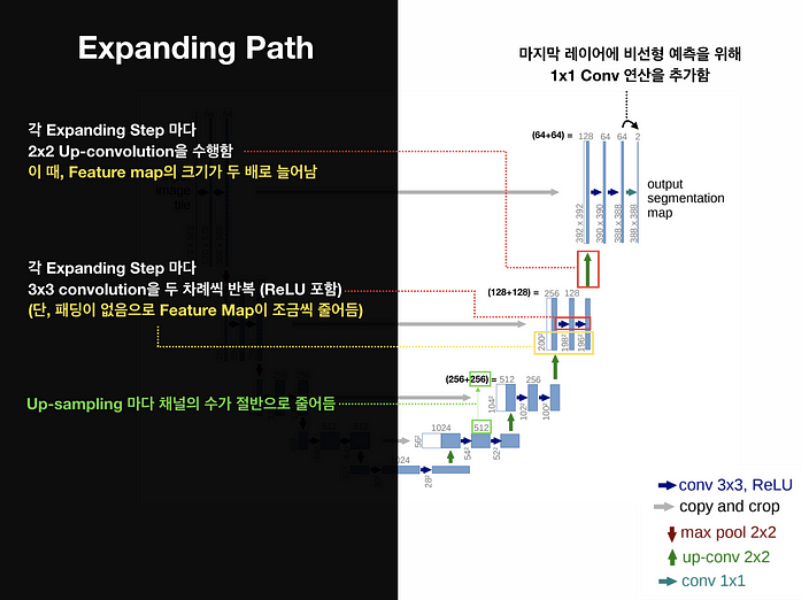
Expanding Step마다 2x2 Up-convolution을 수행합니다. 이때, 당연히 Feature map의 크기가 2배로 늘어나겠죠. 또, 각 Expanding Step마다 3x3 conv을 두 차례씩을 반복하게 됩니다(ReLU포함). 여기서도 패딩을 사용하지 않아 feature map의 크기가 점점 줄어드는걸 볼 수 있죠.
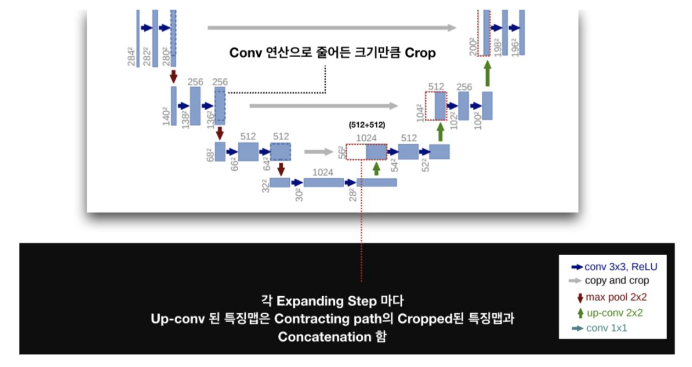
그리고 FCN과 비슷하게 Skip-Architecture를 활용하였습니다. 동일한 level에서 나온 Feature map을 더한다는 점이 FCN의 Skip architecture와 다른점이라고 할 수 있습니다. 그림을 보면, Contracting Path의 Feature map이 Expanding path의 feature map보다 큰 것을 알 수 있습니다. 이는 당연히 3x3 conv layer를 지나면서 feature map의 크기가 줄어들기 때문일겁니다. 그래서 Expanding feature map의 크기에 맞추어 Contracting Path의 feature map의 테두리 부분을 자른 후 크기를 동일하게 맞추어 두 feature map을 concatenate하여 합쳐줍니다.
그리고 디테일한 부분인 Overlap-tile strategy & Mirroing Extrapolation 데이터 전처리 부분은 실제 논문을 읽으며 추후에 자세히 알아보겠습니다. 그냥 의료 데이터의 특징에 맞게 데이터 Augmentation과 보간을 사용한것이라고 생각하면 됩니다!
SegNet (2015~2017)

SegNet은 DeConvNet, UNet과 비슷한 구조를 띄고있습니다.
DeConvNet과의 차이점은 Fully-connected layer를 사용하지 않아서 모델의 크기가 감소했다는 점이 있습니다. 그리고 End-to-End (2-stage 학습X)이라는 특징도 있습니다.
U-Net과의 차이점은 전체 feature map을 전달하는 것이 아닌 max indice만을 전달해서 Upsampling에 사용하는 것에 있겠습니다. 디테일한 부분은 생략하겠습니다.
Super Resolution (저화질 -> 고화질)

그리고 CNN은 BioMedical 분야에서 저화질에서 고화질로 변환하는데에도 많이 사용됩니다. 그리고 추후에 살펴볼 Generative Model, Transformer등과도 많이 결합되어 사용됩니다.
그 외에도, 강화학습(i.e. Deep Q-Network)의 이미지/영상 인식을 위한 인코더 모듈, 생성 모델 제작과정에서 모듈로서의 CNN, Neural style transfer 등에 여러 분야에 활용됩니다. 그래서 CNN은 DNN분야에서 매우 중요한 분야라고 할 수 있겠습니다!
'AIML > 딥러닝 최신 트렌드 알고리즘' 카테고리의 다른 글
- 좋은 Object proposal 방식
- R-CNN (2014)
- SPP-Net & Fast R-CNN (2014~2015)
- SPP-Net
- Fast R-CNN
- Faster R-CNN
- YOLO (2015: v1, 2016: v2, 2018: v3, 2020: v4, v5, PP-YOLO, ...)
- SSD (2016)
- Feature Pyramid Network (2017)
- RetinaNet (2017~2018)
- EfficientDet (2019~2020)
- Fully Convolution Net (2014~2015)
- Deconvolution Net (2015)
- U-Net (2015~2016)
- SegNet (2015~2017)
- Super Resolution (저화질 -> 고화질)