![[ DevOps ] - (테라폼을 이용한 인프라 관리) 테라폼 HCL count와 for_each](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fr5LHZ%2FbtrHTIDcwXU%2FVthVdkv9enAQ8H00gQ95FK%2Fimg.png)
우선 먼저 aws의 iam유저를 많이 생성하는 코드를 count를 통해서 고치는 작업을 해보도록 하겠습니다.
count
/main.tf
provider "aws" {
region = "ap-northeast-2"
}
# resource "aws_iam_user" "user_1" {
# name = "user-1"
# }
# resource "aws_iam_user" "user_2" {
# name = "user-2"
# }
# resource "aws_iam_user" "user_3" {
# name = "user-3"
# }
# output "user_arns" {
# value = [
# aws_iam_user.user_1.arn,
# aws_iam_user.user_2.arn,
# aws_iam_user.user_3.arn,
# ]
# }
/**
* count
*/
resource "aws_iam_user" "count" {
count = 10
name = "count-user-${count.index}"
}
output "count_user_arns" {
value = aws_iam_user.count.*.arn
}기존의 코드로 여러번 짜려면 resource를 여러번 선언해주고, 출력도 하나씩 다 적어주어야 했습니다. 하지만 terraform은 이를 더 효율적으로 코딩할 수 있도록 count문을 제안합니다.
위와같이 안에 count = 10을 써주게 되면 이게 10번 반복하게 도와주는 역할을 합니다. 그리고 name은 count가 1개씩 증가하는 것을 참조하기 위해 블럭 안에서 count.index와 string interpolation을 통해 지정해 주었습니다. 그리고 output에 모든 iam user의 arns를 출력하고 싶다고 해 봅시다. 여기서는 배열의 인덱스로 값을 참조할 수 있게끔 할 수 있습니다. [user1, user2, ... user9]까지 저장되어 있습니다. 그리고 aws_iam_user.count.*.arn으로 0~9까지 모두 다 참조할 수 있게 됩니다.
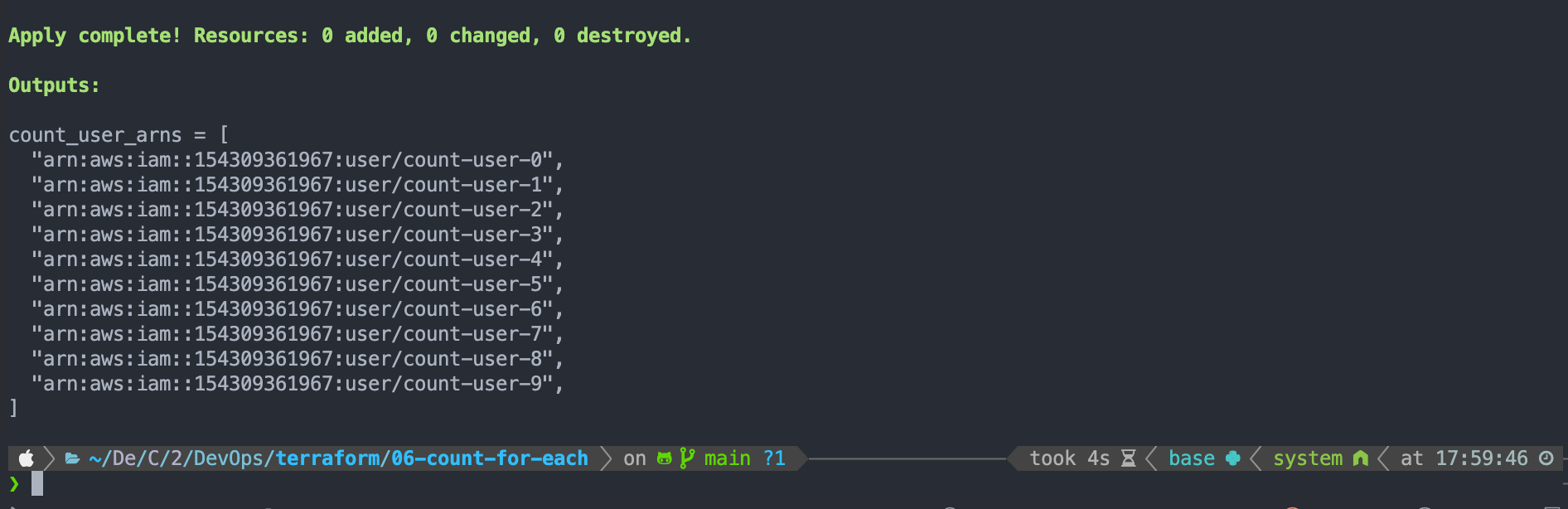
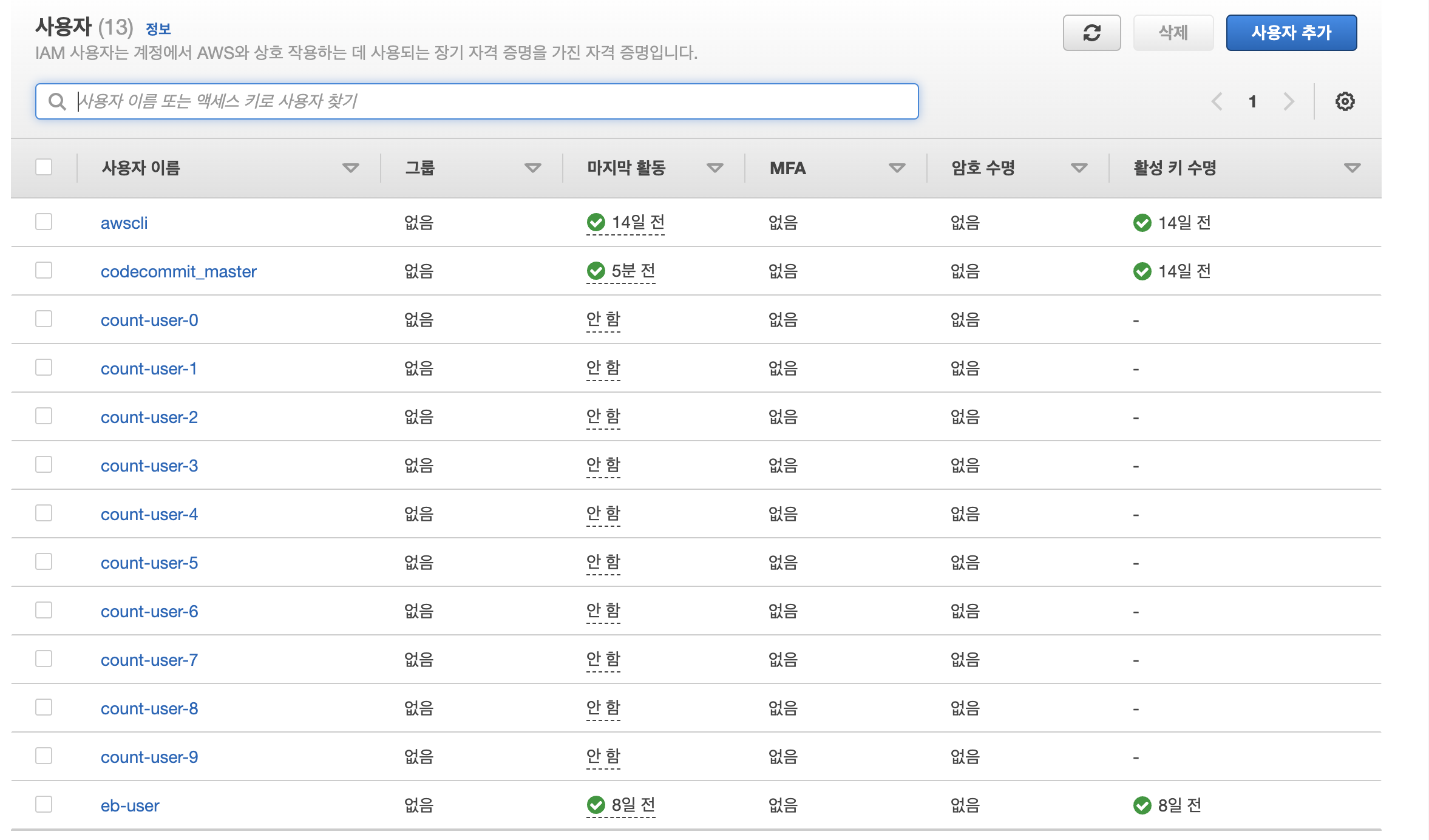
다음과 같이 apply하면 정상 작동하는 것을 보실 수 있습니다.
for_each
/main.tf
resource "aws_iam_user" "for_each_set" {
for_each = toset([
"for-each-set-user-1",
"for-each-set-user-2",
"for-each-set-user-3"
])
name = each.key
}
output "for_each_set_user_arns" {
value = values(aws_iam_user.for_each_set).*.arn
}이 코드는 간단합니다. 그냥 toset은 집합인데 key-value쌍으로 key가 중복되지 않게 들어갑니다. 그리고 각 aws_iam_user의 tag에 name을 각 키의 key값으로 지정합니다. 그리고 output을 출력할 때는 keys()와 values()가 있는데, 지금 아래와 같은 json파일이 있단것입니다.
{
for-each-set-user-1: { user info1... },
for-each-set-user-1: { user info2... },
for-each-set-user-1: { user info3... }
}여기서 keys를 하면 for~~이 값을 가져오는 것이고, values를 하면 user info...를 가져오는 것입니다. 이제 위 코드를 apply시켜보겠습니다.

결과적으로 이도 count와 똑같은 형태가 됩니다.
그 다음에는 set이 아니라 map을 사용해서 이를 짜보겠습니다.
/main.tf
...
resource "aws_iam_user" "for_each_map" {
for_each = {
alice = {
level = "low",
manager = "posquit0"
}
bob = {
level = "mid",
manager = "posquit1"
}
john = {
level = "high",
manager = "posquit2"
}
}
name = each.key
tags = each.value
}
output "for_each_map_user_arns" {
value = values(aws_iam_user.for_each_map).*.arn
}
...이렇게 map을 표현할 수 있습니다. 하지만, 이를 작성할 떄 주의할 점이 있습니다. key값이 무조건 문자열이여야 하고, value는 아무런 형태나 와도 된다는 점입니다.



다음과 같이 다 잘 작동하는 것을 보실 수 있습니다.
정리
마지막으로 이러한 값들이 count, set, map이 어떻게 저장되는지 terraform이 관리하는 인프라를 보면서 확인해보겠습니다.

다음과 같이 보면 위에서 실습했던 4개의 저장 형태가 나옵니다. count를 사용하면 인덱스로 배열의 값을 참조할 수 있습니다. 그리고 set, map을 사용하면 key로 value값을 참조할 수 있습니다. 그리고 기본적으로 하나하나 생성하게 되면 맨 아래 3개와 같이 그냥 이름 그대로 나옵니다.
'DevOps > AWS Architecture' 카테고리의 다른 글
| [ DevOps ] - (테라폼을 이용한 인프라 관리) 테라폼 HCL 반복문 (For) (0) | 2022.07.21 |
|---|---|
| [ DevOps ] - (테라폼을 이용한 인프라 관리) 테라폼 HCL 조건문 (Conditional) (0) | 2022.07.21 |
| [ DevOps ] - (테라폼을 이용한 인프라 관리) 테라폼 HCL variable & local & output (0) | 2022.07.21 |
| [ DevOps ] - (테라폼을 이용한 인프라 관리) 테라폼 HCL module (0) | 2022.07.21 |
| [ DevOps ] - (VPC) VPC를 구성하는 기본 원리 ( 복습 ) (0) | 2022.07.21 |