[ 딥러닝 최신알고리즘 - PRMI Lab ] - DeiT (data-efficient image transformers & distillation through attention)
이전에 ViT를 살펴보았고, data-efficient하지 못하다는 단점이 있었습니다. 이런 문제점등을 개선한 ViT모델을 찾아보다 DeiT를 볼 수 있게 되었고, 다양한 ViT의 변형모델을 볼 수 있었습니다. 예를 들면 Swin Transformer, CvT,...는 추후 포스팅에서 알아보도록 하겠고, 이번에는 DeiT논문을 기반으로 코드도 참고하며 디테일하게 파고들어보겠습니다.
Abstract
이전의 ViT는 좋은 성능을 이끌어 내기 위해서는 JFT-300M(=300M)의 어마무시한 크기의 dataset으로 pre-train시켰습니다. 이렇기에 ViT를 채택하기에는 한계점이 있는 상황입니다.
해당 논문에서는, 오직 Imagenet만으로 top-1 accuracy (83.1%)를 찍은 convolution-free transformer를 소개합니다. 뿐만 아니라, transformer에 기반한 teacher-student strategy를 소개합니다. 이는 뒤에서 소개할 distillation token으로 인해 구현되는데, student model이 teacher의 지식을 attention을 통해 배울 수 있게 됩니다. 그리고 teacher model을 convnet기반으로 사용하게 되는데, 이는 EfificientNet과 같은 기존의 convnet기반 아키텍처 모델과 다양한 task에 대해 경쟁력을 가질 수 있게 됩니다.
1. Introduction
introduction부분에서는 기존 ViT모델의 한계점에 대해 다시한번 상기시킵니다. 그리고 DeiT모델에 대한 ablation study 결과를 토대로 어떻게 기존의 ViT모델의 한계점을 극복할 수 있었는지에 대해 간단히 소개합니다. 그리고 DeiT모델이 기존 연구에 기여한 점에 대해 서술합니다.

Figure 1을 보면, 기존 결과에 대해 DeiT모델이 얼마나 성능 향상을 가져왔는지에 대해 보여줍니다. DeiT-B는 ViT-B와 동일한 아키텍처이지만, data가 부족한 환경에서 더 적합하게 최적화한 모델이라고 보면 됩니다. 그리고 위 그림에서 증류(=distillation)그림이 붙어있는건, 위 논문의 핵심인 transformer에서의 knowledge distillation을 convnet으로부터 지식을 물려받은 모델이라고 생각하면 됩니다. 같은 image throughput에 대해 ViT < DeiT < EfficientNet < DeiT(증류) 라는 걸 한눈에 파악할 수 있습니다.
해당 모델이 후행 연구에 대해 기여한 점을 정리해보았습니다.
- DeiT모델은 conv-layer없이 ImageNet 데이터만으로 기존의 SOTA모델과 견줄만 합니다.
- DeiT-S, DeiT-Ti <--> ResNet-50, ResNet-18 비교할 수 있다.
- 새로운 distillation 과정을 소개합니다.
- ViT에서의 cls token과 같은 역할을 하는 distillation token을 transformer구조에 도입합니다. (물론 distillation token은 teacher에 의해 생성된 label을 reproducing 한다는 역할에서 다른점이 있습니다. -> 뒤에서 더 자세히 다룹니다.
- DeiT모델은 fine-grained 분류문제와 같은 downstream tasks(-> CIFAR-10, CIFAR-100,...)에 대해서도 잘 수행됩니다.
Section3에서 기존 ViT에 대해 다시 살펴봅니다. Section4에서 distillation token을 자세히 살명합니다. Section5에서 convnet과 ViT에 대해서 비교하는 실험을 합니다. Section6에서 tranining scheme을 서술합니다. -> data-efficient요소에 대해 ablation study를 진행해서, DeiT에 대한 통찰력을 제공하겠다 합니다. Section7에서 결론을 언급하며 마칩니다.
2. Related Works
Transformer architecture가 나오게된 계기와, NLP task에서 적용되는 부분에 대해서 다룹니다. 그리고 Trasnformer가 Image의 다양한 task에도 적용될 수 있는 가능성에 대해 언급하는데 ViT가 이의 스타트를 끊었다고 언급하고 있습니다. ViT: Vision Transformer 포스팅을 참고하시기 바랍니다.
[ 딥러닝 최신 알고리즘 - PRMI Lab ] - ViT: Vision Transformer(2021)
https://arxiv.org/pdf/2010.11929.pdf 오늘 제가 알아볼 논문은, 비전 Task분야에서 Convolution Network 구조였던 걸 Transformer구조로 변경하는데에 시작점이 된 Vision Transformer(ViT) 입니다. 기존에 Transformer구조는
hyunseo-fullstackdiary.tistory.com
그리고 KD(=Hinton's)도 소개하는데, DeiT의 distillation token의 핵심 기반 지식입니다. 이는 KD: Knowledge Distillation 포스팅을 참고하시기 바랍니다.
[ 딥러닝 최신 알고리즘 - PRMI Lab ] - KD: Knowledge Distillation
이전에는 ViT의 논문을 리뷰하고 이에대한 코드를 짜보고 Pre-train과 fine-tuning까지 해보았습니다. 하지만 ViT의 고질적인 문제인 데이터 효율적이지 못하다는 점이 가장 아쉬웠습니다. 이에, 데이
hyunseo-fullstackdiary.tistory.com
3. Vision transformer: overview
여기서는 Multi-head Self Attention layers(MSA), Transformer block for images, class token, fixing the positional encoding across resolutions로 나뉘는데, 이 내용들은 Transformer 포스팅을 참고하시기 바랍니다.
[ 딥러닝 최신 알고리즘 - PRMI Lab ] - ViT: Vision Transformer(2021)
https://arxiv.org/pdf/2010.11929.pdf 오늘 제가 알아볼 논문은, 비전 Task분야에서 Convolution Network 구조였던 걸 Transformer구조로 변경하는데에 시작점이 된 Vision Transformer(ViT) 입니다. 기존에 Transformer구조는
hyunseo-fullstackdiary.tistory.com
다만 여기서 간단히 정리를 다시하겠습니다. MSA는 key, value, query는 같은 $\mathbb{R}^d$의 행렬에서 나옵니다. 그리고 sclaed-dot attention을 사용하므로 $Attention(Q, K, V) = Softmax(QK^T / \sqrt{d})V$로 계산될 수 있습니다. 이의 계산 행렬은 $N x d$가 됩니다. 도한, mult-head값인 h를 반영해주면 $N x dh$가 되어 attention계층에 다시 투영시킬 수 있는 꼴이 됩니다.
Transformer block에서는, MSA블럭 위에 FFN블럭을 추가한다고 했습니다. 여기에서 hidden layer의 expansion ratio는 4로 설정합니다(D -> 4D). 당연히 skip-connection도 사용하고 layer-normalization(LN)도 사용합니다.
class token또한, 처음 layer의 첫번째 sequence에 dim만큼의 차원의 토큰을 붙혀서 수행됩니다. 그래서 transformer에 투입시키는 시퀀스는 총 N+1개입니다. 이는 역전파를 통해 학습되면서 이미지 전체의 정보를 내포하게 됩니다.
그리고 ViT에서 해상도를 높혀서 fine-tuning시킨다고 했습니다. 이는 training의 속도를 높히며, data augmentation 에서 더 높은 성능을 낼 수 있게 도와줍니다. 이러한 상황에서 image patch가 고정시키면, iamge patch seuqnece length는 늘어나게 되는데 ViT구조상 이는 문제가 되지 않습니다. 하지만, positional embedding을 다시 고해상도 상황에서의 환경으로 적응시켜야 하는데 이때에 원본 이미지를 참고하여 interpolation을 한 positional embedding을 사용합니다. 이는 fine-tuning stage에서 잘 작동한다고 실험적으로 증명되었습니다.
4. Distillation through attention
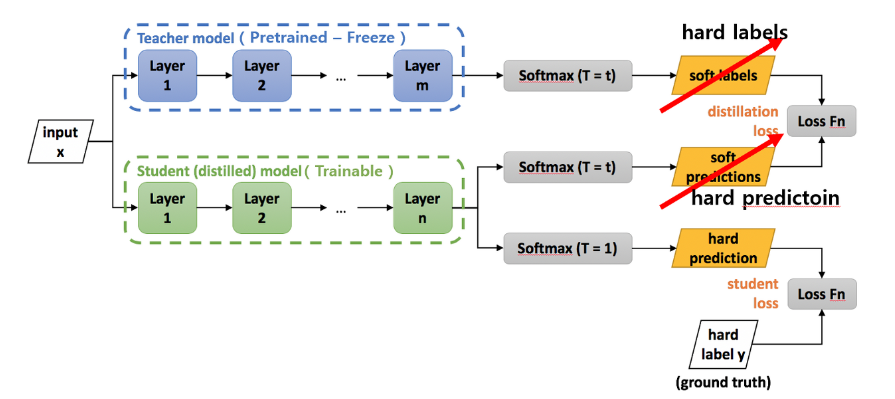
먼저, hard distillation과 soft distillation에 대해서 알아봅니다. 그리고 classical distillation과 distillation token에 대해서도 알아봅니다.
Soft distillation: KD의 목적은 teacher와 student model의 output에 softmax를 취한 값의 KLD(Kullback-Leibler divergence)를 최소화하는데 목적이 있습니다.
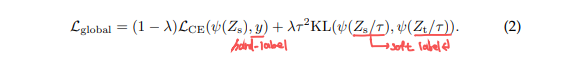
이는 KD포스팅에서도 봤지만, $\eta$는 distillation의 temperature로써, 해당 값이 높을수록 정보를 부드럽게 분배해줍니다.
Hard-label distillation: 는 teacher의 hard label을 그대로 distillation과정에서 사용하는 것을 말합니다. 여기서 $y_t$는 teacher의 hard decision입니다.
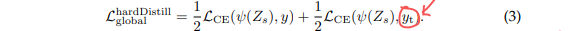
저자들은, soft label은 data-augmentation시에 label과 image사이의 mis-alignment를 발생시킬 수 있기에 hard-label을 사용하는 것이 더 좋다고 주장합니다. 예를 들어 crop augmentation을 해서 cat이 label되어있는데 cat이 사라지고 주변 풍경만 보이게 바뀌었다고 해봅시다. 이러한 상황에서 soft label을 사용한다면 soft label은 implicit하게 label을 바꾸게 될 것입니다. 즉, 해당 이미지의 label은 cat인데 soft label기준에선 다른 label의 값이 높아져 왜곡된다는 것입니다.
추가로 hard label은 label smoothing을 통해 soft-label로 변환될 수 있습니다. 이렇게 원하면 class들에 확률을 나눠주는 방식을 사용할 수도 있다고 저자들은 말합니다.
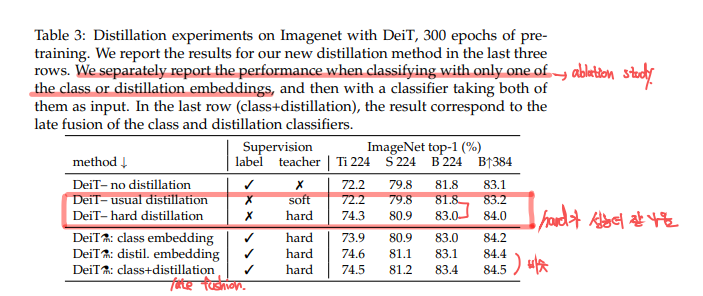
저자들은 DeiT에서 label에 대한 ablation study를 진행했습니다. hard label을 사용한 것이 soft label을 사용한 것보다 정확도가 더 높은 것을 볼 수 있습니다. 이제 ViT에 distillation token이 어떻게 적용되는지에 대해 보겠습니다.
Distillation token: 그림 그대로 initial embedding에 class token처럼 distillation token을 랜덤으로 초기화해서 넣어주는 것으로 구현됩니다. 이는 self-attention을 다른 embedding vector와 상호작용하며 layer의 마지막 층에 결과로 나오게됩니다. distillation embedding의 목적은 (student) model이 teacher의 output으로부터 distillation방식으로 학습할 수 있게 함에 있습니다. class token은 이와 상호보완적인 관계로서, Ground truth와 Cross-entropy를 계산하게되며 실제 label을 학습하게 됩니다.
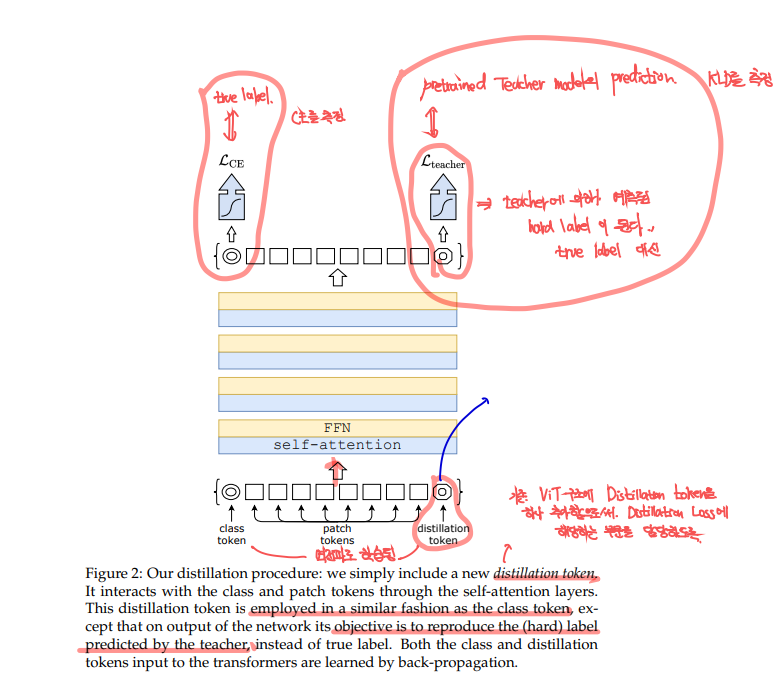
그리고 class token과 distillation token의 결괏값은 점진적으로 비슷해지는데, cosine similarity를 측정했더니 0.93이라는 값이 나왔습니다. 이는 1보다 작은 값으로 true label(=class token)과 유사하지만 identical하지 않은 결과를 말합니다. 이가 성능적으로는 긍정적인 영향을 가져옵니다. 반면 distillation token대신에 calss token을 2개써서 해본다면 두개의 유사도는 0.99999..가 되며, 성능에 유의미한 영향을 미치지 않는 identical 한 결과를 만들어낸다고 합니다.
Classification with joint classifiers: Section 5.2에서 다루는 Table3에서도 class embedding, distil embedding에 대한 ablation study를 볼 수 있습니다. distil embedding만을 사용한 DeiT가 성능이 가장 높았고, 두개를 혼합한 late fusion방식도 성능이 괜찮은 것을 볼 수 있습니다.
late fusion방식이 괜찮은 성능을 띌수 있는 이유는, classification을 할때에 두개가 상호보완적인 정보를 주고받기 때문이라고 합니다.
Fine-tuning with distillation: DeiT를 fine-tuning할때에는 true label과 teacher prediction을 higher resolution이미지를 활용하여 진행합니다. teacher는 기존의 lower-resolution을 그대로 활용하는 것이 일반적이라고 합니다. 그리고 teacher prediction을 ground truth값으로 하면 오히려 성능은 더 낮아진다고 합니다.
이는 아무래도 teacher의 representation을 transformer distillation 방식으로 습득을 하게 되는데, 이를 제거해서 성능이 더 낮아진 것으로 보입니다.
5. Experiments
여기서는 distillation 전략에 대한 실험을 진행합니다. convnet과 ViT기반 모델간의 efficiency와 accuracy를 비교를 포함합니다.
5.1 Transformer models
DeiT는 특별한 것이 없다고 언급했습니다. 해당 논문에 DeiT의 주요 특징이라고 하면 아래와 같습니다.
- convolution 층이 없다.
- distillation token이 추가되고 training 전략이 달라졌다(transformer KD)
- pre-training 시에 MLP head가 없고, 대신 linear classifier만 있다.
- DeiT와 DeiT⚗.의 차이
- DeiT는 ViT와 architecture는 같지만, DeiT에서 d = D / h = 64(constant)가 유지되게끔 합니다. 여기서 D는 임베딩 차원이고, h는 self-attention에서의 head입니다.
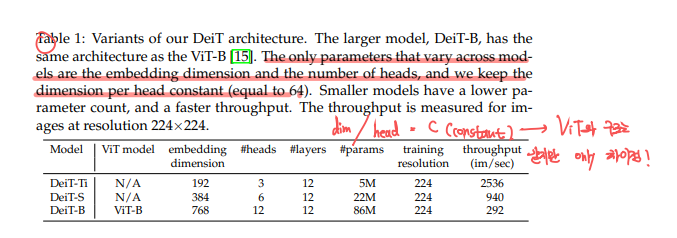
DeiT의 크기에 따른, 파라미터의 예시입니다. 추후 Table에서 나오는 실험 값을 볼때에 참고하면 도움이 됩니다.
5.2 Distillation
DeiT에서 distillation 방법을 사용했더니, 기존의 sota인 convnet 모델들과 accuracy와 throughput trade-off측면에서 견줄만 해졌습니다. 아래 표를 참고하시면 됩니다. 비슷한 throughput(EfficientNet-B7 RA <--> DeiT- ⚗/384up)인데도 ImNet top-1 accuracy에서 견줄만 한 값이 나온것을 볼 수 있습니다.
그리고 이전에 살펴본 ViT-B (pre-train with JFT-300M) 보다 성능이 85.2% > 84.15%로 우월합니다.
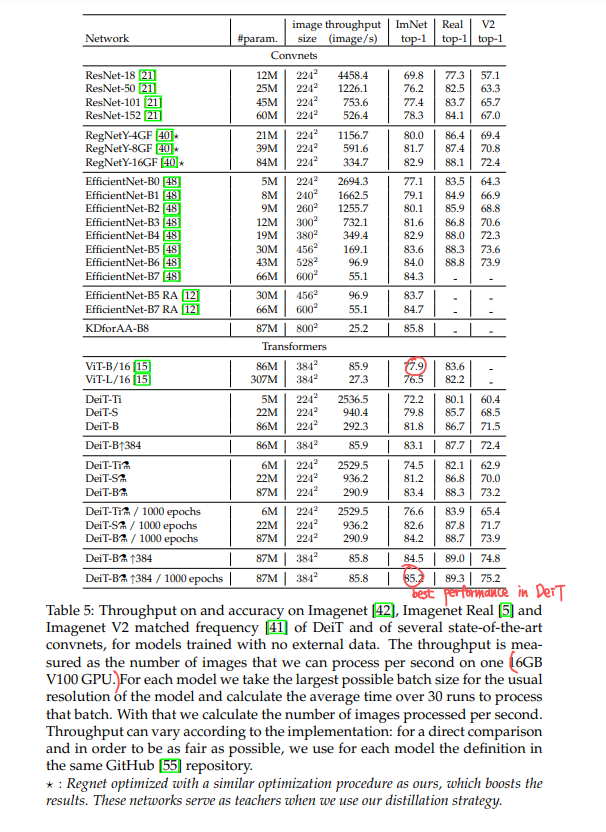
Convnet teachers: DeiT는 convnet을 teacher로 주어졌을때에 transformer보다 더 좋은 성능을 낼 수 있다고합니다.
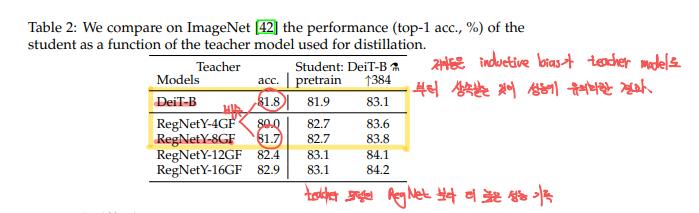
위 실험 결과가 저자들의 주장을 뒷받참합니다. 이전에, ViT는 inductive bias가 별로 없기 때문에, 많은 데이터셋이 pre-train시에 필요하다고 했었습니다. 같은 맥락으로 DeiT를 훈련시킬때에도, inductive bias를 가지고 있는 것이 좋을것입니다. 따라서, Transformer를 효율적으로 활용하기 위해서 student를 transformer로 사용하고 inductive bias를 더 효율적으로 전달하기 위해 convnet을 teacher model로 사용하는 것을 적극 권장하고 있습니다.
이러한 이유에서 conv teacher의 Knowledge distillation방식은 많은 이미지 데이터셋이 없이도 학습 가능한 data-efficient한 transformer학습에 도움을 주는 핵심 요소입니다.
Agreement with the teacher & inductive bias: 그럼 과연, inductive bias를 convnet이 student에게 물려주는 것이 training을 진짜로 촉진시키는지 의문이듭니다. 저자들은 이것에 대한 명확한 답변을 제시하기 어렵다고 합니다.
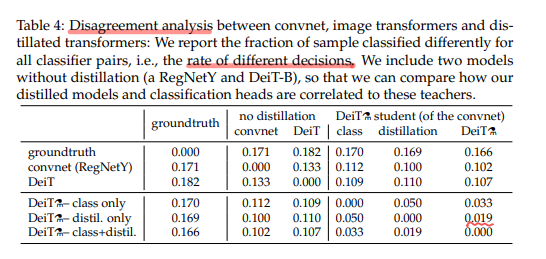
이에, disagreement analysis를 진행합니다. 저자들은 서로 다른 분류기 쌍 간에 서루 다르게 분류된 샘플의 비율을 측정합니다. 이는 다양한 분류 모델이 얼마나 다른 결정을 내리는지 측정하는 것으로, 각 모델의 의사 결정 차이를 분석하는 데 사용됩니다.
지식 증류를 거치지 않은 두 모델(RegNetY, DeiT-B)를 포함합니다. 이를 통해 지식 증류를 통해 학습된 모델이, teacher와 어떤 연관을 가지는지 파악하려는 것입니다. 위 실험결과에서 DeiT⚗ student(of the convnet)을 보면, distillation token이 class embedding보다 더 convnet(teacher)의 결정과 유사함을 볼 수 있습니다. 반대로 class token은 뭐랑 비슷하나 보니 distillation 없이 학습한 DeiT의 결정과 유사합니다. 당연히 joint classifier(class + distil)은 중간값을 나타냈습니다. 정말 놀랍습니다!
Number of epochs: ViT와 비슷하게, Transformer기반이기 때문에 epochs를 늘리면 performance가 증가합니다.
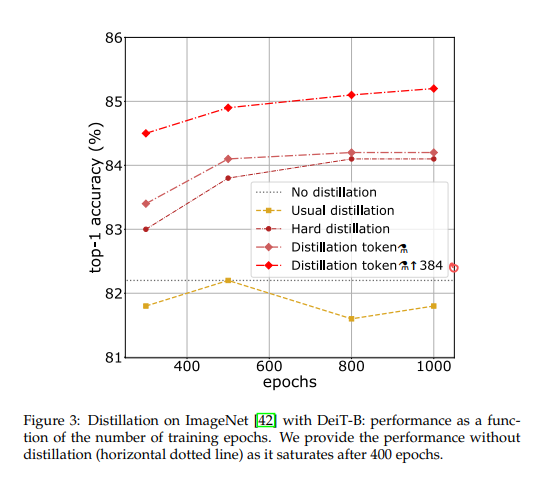
위 실험결과를 보면, distillation없이 학습한 것은 400epochs이후에 saturates되는 것을 볼 수 있고, DeiT ⚗는 400epochs이후에도 성능이 꾸준히 증가하는 것을 볼 수 있습니다.
5.4 Transfer learning: Performance on downstream tasks
당연히 ImageNet에 대해 잘 작동하는 것을 봤으면, fine-tuning도 잘되는지 확인해야합니다.
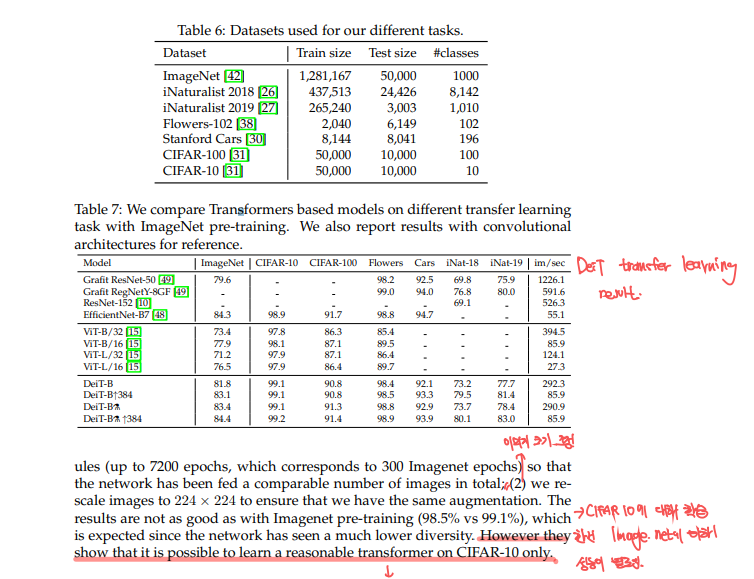
위 Table6, Table7에서 DeiT의 transfer learning을 ViT와 sota convnet과 비교한 결과입니다. 성능은 말 안해도 아시죠?? 견줄만한 결과였습니다.
Comparision vs training from scratch: DeiT모델을, CIFAR-10과 같이 작은 데이터셋에 대해 scratch부터 학습시켜본다음에, pre-train했던 것과의 성능을 비교해보겠다 합니다. 이를 위해 이전과 같은 data-augmentation 조건을 만들어주기 위해서 아래와같이 셋팅해주었습니다.
- CIFAR-10의 크기가 더 작으니까, 더 많은 epoch로 훈련을 했다.
- CIFAR-10 이미지를 224x224로 rescale했습니다.
이는 98.5%로 이전 결괏값인 99.1%보다 살짝 낮은 정확도가 나왔습니다. 그 이유는 아마도 이미지의 다양성이 떨어지기 때문일 것입니다. 하지만, 이는 CIFAR-10와 같은 작은 데이터셋으로도 transformer를 학습시킬 수 있다는 것을 의미하게 됩니다.
6. Training details & ablation
저자들은, DeiT 훈련을 PyTorch로 빌드하고 timm library를 사용했습니다. Section6에서는 실험에 사용한 모델의 hyper-parameters와 다양한 data-agumentation, regularization에 대한 ablation study를 진행합니다.
Initialization and hyper-parameters: Transformer는 hyper-parameter초기화에 아주 예민합니다. 이전 ViT의 값으로는 수렴이 안되는 경우가 있어서 자기만의 방식으로 설정했다고 합니다.
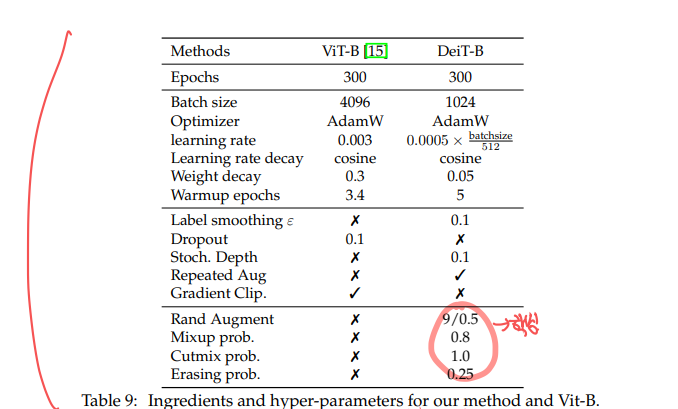
weights를 truncated normal distribution을 통해 초기화하며, $\eta = 3.0$, $\lambda = 0.1$을 사용합니다((soft) distillation 방식일때). 관련 식은 위에 올려다보시기 바랍니다.
Data-Augmentation: convolution과 같은 것과 비교했을때에, transformer는 많은 데이터를 필요로합니다. 그래서, DeiT는 확장성있는 data-augmentation에 많은 의존을 합니다.
Auto-Augment, Rand-Augment, random erasing,..에 대한 ablation study결과입니다.
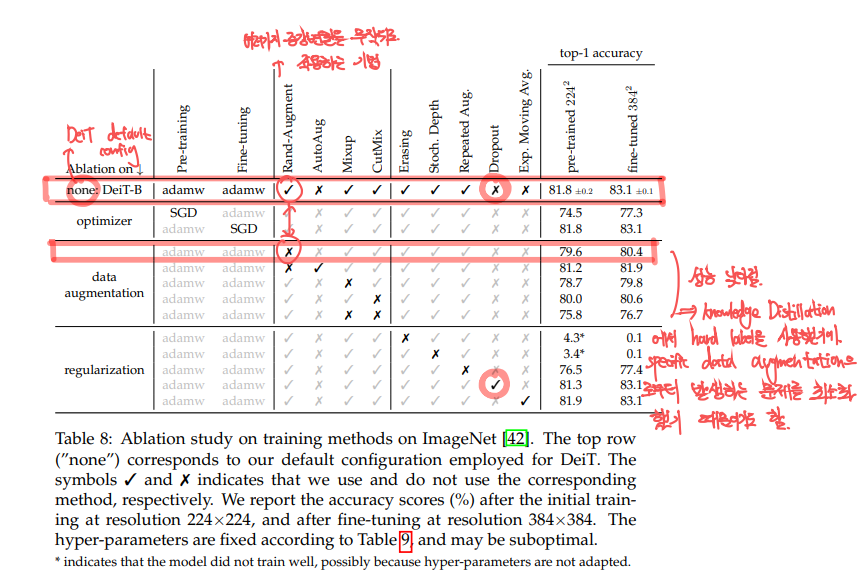
전체적으로 transformer는 대부분의 strong data-augmentation방법을 필요로 하다는 것을 볼 수 있습니다. 거의 모든 방법이 모델의 성능을 올렸기때문입니다. 하지만, dropout만은 성능을 낮추었다고 합니다. 그래서 실제로 모델 구현에서도 dropout은 제외합니다.
Regularization & Optimizers: 기본적인 값은 아래 표와 같습니다.
- cross-validate를 할때에 서로 다른 3개의 learning rate와 서로 다른 3개의 weight decay값을 사용해, 모델에 적합한 값을 찾았다고 합니다.
- learning rate를 batchsize에 비례해 scale하는 방법을 사용합니다. -> warmup방법임
- AdamW를 ViT와 동일하게 사용합니다.
- 보다 작은 weight decay값을 사용합니다.
- stochastic depth를 사용합니다.
- 이는 transformer에서 수렴 속도를 개선시킨다 합니다.
- Mixup, Cutmix와 같은 agumentation & regularization기법이 모델의 성능을 높힙니다.
- + repeated data agumentation또한 사용합니다.
Fine-tuning at different resolution: DeiT에서 FixEfficientNet과 같은 schedule, regularization, optimization을 fine-tuning때에 사용합니다. 여기에서 data-aguemtnation방법을 추가합니다.
position-embedding interpolate도 진행합니다. 이때, bilinear interpolation이 사용될 수 있는데, 이는 주변 이웃 vector와의 l2-norm을 떨구는 효과가 있다고 합니다. 이는 pre-trained된 트랜스포머모델에 부적합하고, 정확도를 떨구는 효과도 있다고 합니다. 그래서 우리는 bicubic interpolation을 l2-norm의 크기를 최대한 유지시키는 방법을 채택합니다.
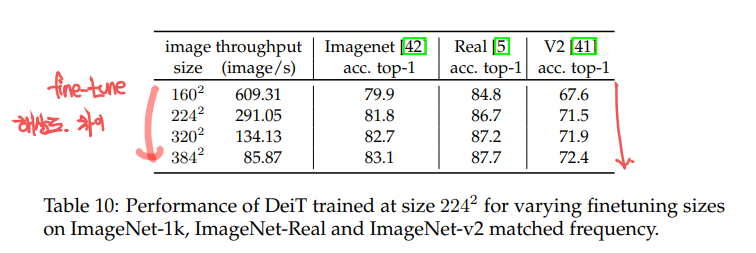
fine-tuning시에 해상도에 따른, 모델의 정확도는 위와같습니다. 이처럼 higher resolution으로 fine-tuning 했을 때 성능이 더 좋아졌고 이를 활용합니다.
7. Concolusion
DeiT는 iamge transformer로서, 학습시킬때에 큰 데이터셋이 필요없습니다. 이는 DeiT만의 차별적인 training방법과, transformer 기반 knowledge distillation 때문입니다. DeiT는 기존 ViT와 비교했을때 distillation token만을 추가하고 convnet에 적용되는 data-agumentation, regularization을 적용을 시작했습니다.
이렇게 보다 data-efficient한 transformer인 DeiT를 통해 기존의 convnet과 견줄만한 성능을 가질수 있게 되었습니다. DeiT의 실험 결과는 convnet보다 더 적은 메모리를 활용하여 모델의 성능을 올리는데에 기여할 것으로 보입니다.
DeiT의 모델 코드는 여기서 볼 수 있습니다. 코드를 보면 DistialledVisionTransformer모델이 정의되어있고, dist_token, pos_embed토큰의 크기와, 위에서 언급한 truncated normal distribution방법으로 초기화를 시키는 것을 볼 수 있습니다.
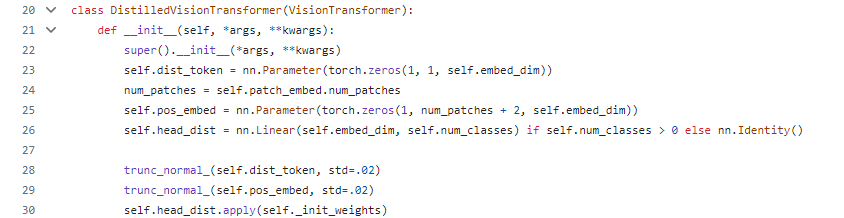
코드에서는 DeiT의 다양한 버전을 models.py에 만들어놓고, timm의 VisionTransformer를 활용해 모델을 구현해놓았으니, 한번 살펴보며 자신이 아는 내용과 비교해보시기 바랍니다.