[ 딥러닝 최신 알고리즘 - PRMI Lab ] - ViT: Vision Transformer(2021)
https://arxiv.org/pdf/2010.11929.pdf
오늘 제가 알아볼 논문은, 비전 Task분야에서 Convolution Network 구조였던 걸 Transformer구조로 변경하는데에 시작점이 된 Vision Transformer(ViT) 입니다.
기존에 Transformer구조는 NLP를 공부하면서 접한 내용이였습니다. 하지만 지금 Text Task에서는 이미 Transformer(=Bert, ELECTRA, T5 etc,...)로 지배적인 상황이였습니다. 하지만 ViT가 비전 Task에 적용된 이후로부터 Swin ViT, DeiT,,.. 등 많은 변형과 이를 Classification, Segmentation, Captioning,,.. 다양한 비전 Task로도 적용하는 추세가 되었습니다.
현재 또한 다양한 Transformer 구조를 사용한 Architecture가 SOTA를 찍고 있기 때문에, 비전에서의 그 시작점이 된 ViT를 처음으로 리뷰하고, 다음 포스트에서 코드를 리뷰하며 pre-trained된 모델을 통해 Tensorboard로 시각화를 해보도록 하겠습니다
.
Abstract

위에서 말한 그대로입니다.
- NLP분야에서는 사실상 Transformer가 점령했고, 이가 컴퓨터 비전에 적용되기에는 아직 한계점이 존재했습니다.
- 그래서 기존에는 Transformer와 Convolution network가 결합되어 사용되거나 어떻게든 Convolution 이 사용되었습니다.
- 그래서 해당 논문에서는 CNN이 필요하지 않고, pure transformer가 image를 patch로 나누어 sequence로 생각해서 transformer에 투입하면 이가 이미지 분류 작업에서 잘 동작함을 보이겠다 합니다.
- 대용량 데이터셋을 Pre-train시키고 Small Image 데이터셋인(ImageNet-1k, Cifar100)으로 Transfer learning을 시킨다고 합니다.
- 이때에, 훨씬 적은 리소스로 우수한 benchmark를 얻을 수 있다고 합니다.
- 하지만 더욱 많은 학습 데이터가 필요하다는 단점이 있다고 합니다.
- ImageNet과 같은 Mid-sized 데이터셋으로 학습 시, ResNet보다 낮은 성능을 보인다고 합니다.
2. Related Work

- Attention is All you Need! (Vaswani et al. 2017) -> Transformer
- NLP에서 가장 대표적인 구조 "Self-Attention"을 활용한 Transformer
- 이중 대표모델 BERT는 Large Dataset(Corpus)를 사전학습시키고 -> 작은 downstream task에서 미세조정 합니다.
- Naive Application: 기존에 이미지를 transformer에 적용하려면 모든 pixel을 self-attention을 시켜주어야 했으므로, input의 quadratic cost가 발생했다고 합니다.
- Parmar: 전역적으로 적용 X -> 쿼리를 픽셀 주변에만 Self-attention을 적용
- Weissenborn: 다양한 크기의 Block을 Scale Attention 적용, 하지만 이는 효율적인 GPU사용을 위한 복잡한 엔지니어링이 필요합니다.
- Cordonnier: 2x2 Image Patch를 추출하여, Full Self-attention을 사용합니다.
- 하지만 이는 2x2 Image Patch를 사용하므로 낮은 해상도에만 적용가능하다고 합니다.
- Image GPT: 이미지 해상도와 color space를 줄인 후, image pixel단위로 Transformer를 적용한 생성모델이라고 합니다.
- ViT의 목적
- ImageNet dataset보다 큰 Large scale에서 동작하는 image recognition을 만드는것
- 일반적인 Transformer를 바로 적용하는것
- Medium-Resolution 이미지에도 바로 적용하는 것
본 논문에서는, Large Scale dataset인 ImageNet-21k, JFT-300M과 같은 데이터셋에서, empirical exploration을 CNN과 transformer를 비교해서 진행할 것이라고 합니다. 그리고 이미지 데이터셋 크기에 따라 어떻게 CNN 모델이 확장되는지도 보겠다 합니다.
3. Method
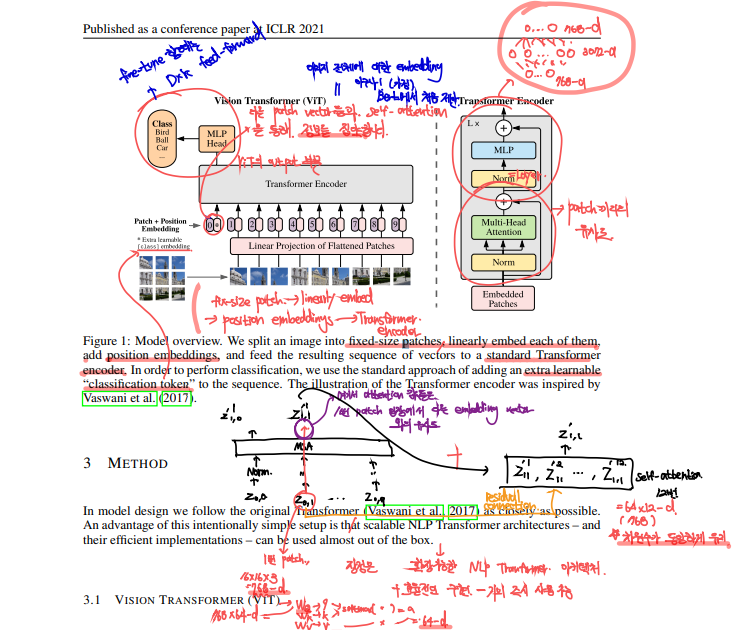
이는 전체적인 ViT의 구조입니다. 우리는 기존의 Transformer구조를 그대로 사용할 수 있습니다. 기존의 scalable한 NLP Transformer를 그대로 사용할 수 있다는 장점과, 이의 효율적인 구현은 이를 많이 사용할 수 밖에 할 수 없습니다. 이제 세부적인 부분을 살펴보도록 하겠습니다.

- 입력 Token Embedding
- Transformer는 Token Embedding을 1D sequence로 입력받는다고 합니다.
- 2D이미지인 $x_p \in \mathbb{R}^{H x W x C}$를 $x_p \in \mathbb{R}^{N x (P^2 \cdot C})$로 flatten시킵니다.
- $(H, W)$가 기존 이미지의 해상도, $C$가 이미지의 채널수입니다. $(P, P)$는 이미지 패치 하나하나의 해상도입니다.
- 실제 실험에서는 $P = 14, 16, 32$등 다양한 값이 됩니다.
- $N$은 Patch의 수로서 $HW/P^2$입니다.
- $D$는 모든 layer에서 동일한 dim의 vector로서, 논문에서는 constant latent vector size라고 되어있습니다.
- 학습가능한 Linear Projection($E$)를 사용하여, $x_p$를 D차원으로 투영시킵니다.
- Transformer는 Token Embedding을 1D sequence로 입력받는다고 합니다.
- [CLS] Token
- BERT가 문장의 의미를 파악하고 분류하기 위해 사용하는 [CLS] 토큰과 같습니다. ViT에서도 학습 가능한 Embedding patch $z_{0}^{0} = x_{class}$를 추가합니다.
- $z_{L}^{0}$는 L번째 Layer의 0번째 token이라고 정의됩니다.
- 이때, Pre-training과 Fine-Tuning을 수행하는 Classification Head가 부착되는 것입니다.
- Classification Head는 fine-tuning시에는 single layer, Pre-training시에는 hidden layer1개를 가진 MLP층이됩니다.

위와같이 classification을 수행하기 위해 encoder최종 아웃풋의 가장 첫번째 벡터인 y를 하나의 hidden layer($DxC$)로 구성된 MLP Head에 통과시킵니다. -> 당연히 fine-tuning시에는 single layer
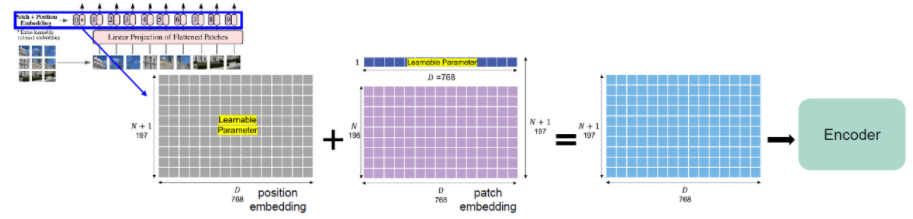
- Position embedding
- Patch Embedding의 Position 정보를 유지하기 위해서 추가하는 것입니다.
- Patch로 쪼개버리면 그 안에서 위치 정보를 다 잃어버리기 때문입니다. -> fc layer와 비슷
- 2D-Position Embedding은 1D와 비교했을때에, 성능이 더 좋지도 않고 계산 효율적이지도 않았다고 합니다.
- --> 이미지여도 1D Position Embedding사용
- Patch Embedding의 Position 정보를 유지하기 위해서 추가하는 것입니다.
- Transformer
- 위의 과정을 다 거친 embedding sequence는 Encoder의 입력으로 들어가게 됩니다.
- Transformer의 Encoder는 Multi-Head로 구성된 Self-Attention매커니즘을 적용합니다.
- MLP Block을 사용합니다.
- MLP Block은 GELU(=Activation Function)를 통해서 non-linearity를 추가합니다.
- 기존의 Transformer와 같게, Hidden layer의 expansion_ratio를 4로 합니다 -> bottle-neck구조 ex) 768d -> 3072d -> 768d
- 모든 Block마다 "이전"에 Layer Normalization또한 적용한다고 합니다.
- 기존에는 모든 블럭 "이후"에 적용되었지만, 해당 LN의 위치가 Transformer 학습에 중요한 역할을 한다는 (Wang et al., 2019)가 나왔습니다.
- Residual Connection으로 Gradient Vanishing문제를 해결한다고 합니다.
기존의 Vanilla Transformer와 ViT Transformer는 매우 유사합니다. 이미지를 토큰화시켜서 임베딩 시키는 방법에만 차이가 있을 뿐입니다. 그리고 Multi-head Self-attention의 작동 방식은, Transformer 포스팅 https://hyunseo-fullstackdiary.tistory.com/406 을 참고하시기 바랍니다.
[ 딥러닝 논문 리뷰 - PRMI Lab ] - Transformer: Attention is all you need (NIPS, 2017)
이번에는 DeTR을 읽기 위해 "Attention Is All You Need (NIPS, 2017)" 에서 소개된 Transformer에 대해 사전 지식으로서 알아가 보도록 하겠습니다. 먼저 논문과 함께 아래와 같은 자료들을 참고했습니다. https:/
hyunseo-fullstackdiary.tistory.com

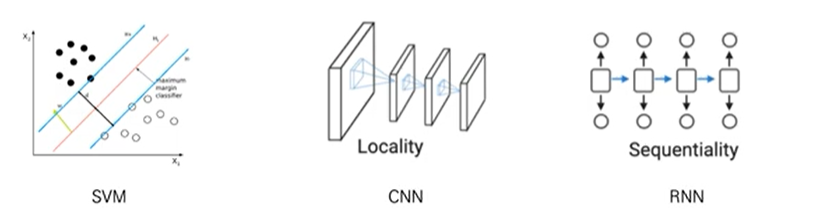
- Inductive Bias
- CNN은 locality가정을 하고 있습니다. pixel 주변에 관련이 있는 pixel들이 존재합니다. RNN또한, Sequentiality를 가정하고 있고, SVM또한, margin을 높이는 것이 분류기를 최적화 하는 것이라고 가정합니다.
- 이렇게 하게되면, Global한 영역의 처리는 어렵게 됩니다. -> ViT는 가능!
- ViT는 그래서 일반적인 CNN과는 다르게 공간(=Spatial)에 대한, Inductive Bias가 없다고 할 수 있습니다.
- 그러므로, ViT는 더 많은 데이터를 통해, 원초적인 관계를 Robust하게 학습시켜야 합니다.
- 실험결과로 알겠지만, Inductive Bias때문에, ViT가 더 많은 학습 dataset을 가져야 하는 것입니다.
- * ViT는 MLP Layer에서만 Local및 Translation Equivariance합니다. -> CNN또한 그럼
- Self-Attention 매커니즘은 Global한 관계를 학습할 수 있습니다.
- 2D 구조를 매우 드물게 사용합니다.
- 이미지 patch를 잘라서 input에 넣습니다. -> 1D
- Fin-tuning시에, 다른 해상도의 이미를 위한 위치 임베딩을 조정하게 됩니다.
- 이렇게 되면 공간관계를 처음부터 학습해야 합니다. (Position Embedding 초기화 시 위치정보 전달 X)
- CNN은 locality가정을 하고 있습니다. pixel 주변에 관련이 있는 pixel들이 존재합니다. RNN또한, Sequentiality를 가정하고 있고, SVM또한, margin을 높이는 것이 분류기를 최적화 하는 것이라고 가정합니다.
- Hybrid Architecture
- Image Patch의 대안으로, CNN의 backbone을 사용해서 Feature map의 sequence를 사용할 수 있습니다.
- Patch Embedding층 계산식의 $E$가 CNN의 feature map에 적용되는 것입니다.
- CNN의 feature는 spatial size가 1x1가 될 수 있음
- 즉 CNN으로 feature 추출 -> Flatten -> Embedding Projection($E$) 적용
- Image Patch의 대안으로, CNN의 backbone을 사용해서 Feature map의 sequence를 사용할 수 있습니다.
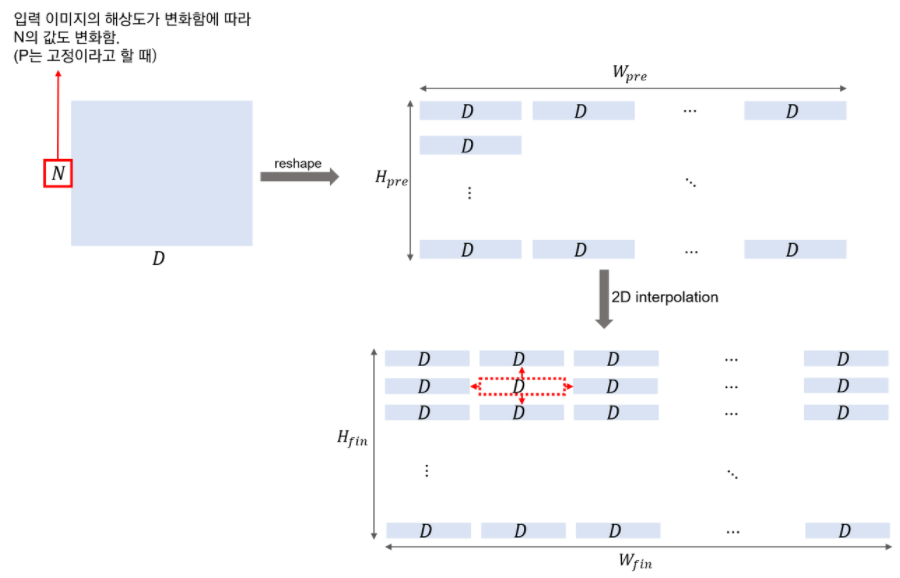
- Fine-Tuning & Higher Resolution
- fine-tuning할 때에 해상도를 설정합니다.
- Pre-train 때보다 더 높은 해상도로 Fine-tuning하는 것이 성능에 더 도움이 됩니다.
- 더 높은 해상도 및 Patch Size를 동일하게 하면 -> Sequence($N$)의 길이는 증가할 것입니다.
- 이로 인해 Fine-tuning시에 Pre-trained된 Position Embedding은 소용이 없게 됩니다. -> 애초에 크기도 안맞을 뿐더러..
- -> Pre-trained Position Embedding을 2D 보간(interpolation)을 수행하게됩니다.Fine-Tuning & Higher Resolution
- fine-tuning할 때에 해상도를 설정합니다.
4. EXPERIMENTS

여기에서는 ResNet, ViT, ViT(Hybrid)에 대해서 representation learning capabilities를 평가합니다. 그리고 각 모델의 data requirements를 알아보기 위해 datasets의 크기를 다양한 사이즈로 하면서 다양한 benchmark task를 평가 기준으로 pre-train시켜본다 합니다.
결과적으로 ViT가 보다 낮은 계산 비용으로 favourably하게 SOTA benchmark를 달성했다고 합니다. 뿐만 아니라 self-supervision에 대한 작은 실험도 수행했는데, self-supervised ViT가 미래에 촉망받을 것을 장담한다고 합니다.

그리고 여기서는 19-task VTAB classification suite (Zhai et al. 2019b)를 활용합니다. 이는 1000개 정도의 적은 데이터셋을 활용한 transfer-learning을 다양한 task에 대해 평가하는 것입니다. task의 분야는 논문을 보시기 바랍니다.
Model Variants
또 ViT에는 다양한 variants들이 있는데, ViT-Base, ViT-Large, ViT-Huge입니다. 뒤로갈수록 모델 Parameters가 많아져 모델의 표현력이 높아질 것으로 예상됩니다. 그리고 위와같이 (Base, Large)와 같이 모델을 나누는 것은, BERT (Devlin et al., 2019)에서 참고했다고 합니다. 또한, 더 큰 Huge모델을 자체적으로 정의했다고 합니다. 그리고 ViT-L/16와 같이 앞으로 표기하는 것의 의미는 ViT-Large모델에 16x16 patch_size을 의미합니다. 여기에서는 해당 patch_size는 sequence_len(=$N$)에 qudratic 하게 반비례하므로 smaller patch는 더 비싼 계산 비용을 의미한다고 논문에 나와있습니다.
그리고 baseline CNN에 대해서는 ResNet을 사용합니다. 여기에서 detail은 BN(=Batch Normalization)대신에 Group Normalization (Wu & He. 2018)을 사용하고, standardized convolutions (Qiao et al. 2019)를 사용한다고 합니다. 관련 내용이 궁금하면 찾아보시기 바랍니다. 이와같은 변형 모델은 transfer learning 수렴 속도를 더 빠르게 하고 (Kolesnikov et al., 2020) 이와 같은 변형 모델을 ResNet(BiT)라고 명명한답니다.
그리고 하이브리드 모델에 대해서 연구진은, ResNet의 중간 feature map을 ViT의 입력으로 사용하겠다 합니다. 여기서 패치의 크기는 하나의 pixel입니다. 그리고 서로 다른 시퀀스의 길이를 실험하기 위해 아래와같은 2가지 옵션을 사용합니다.
- 일반 ResNet50의 4단계의 출력을 사용
- 4단계를 제거하고, 같은 수의 레이어를 3단계 배치한 후, 이 확장된 3단계의 출력을 사용합니다. -> 이는 결과적으로 시퀀스의 길이를 4배 늘리게 되고, 더 많은 비용이 드는 ViT모델을 생성하게 됩니다.
이러한 접근방식은, ResNet과 ViT의 장점을 결합하여, 더 강력한 이미지 특징 추출및 분류 능력을 가진 하이브리드 모델을 만드는데에 목적이 있습니다. ResNet의 효율적인 특징 추출 능력과 ViT의 global context 인식 능력을 함께 활용함으로써, 이미지 처리 작업에서 더 높은 성능을 보일 수 있습니다.
Training & Fine-tuning
논문에서 모든 모델은 Adam을 $\beta_1 = 0.9, \beta_2 = 0.999$와, batch size = 4096, weight decay (high) =0.1을 사용합니다. 해당 ResNet 실험 셋팅에서는 기존과는 다르게 SGD보다 Adam이 더 잘 작동했다 합니다. 그리고 linear learning rate warmup과 decay를 사용합니다 + dropout, label smoothing. fine-tuning시에는 SGD를 momentum과 함께 사용하고 batch size = 512를 사용합니다. 아래 그림에 나오겠지만 Table2에서 ViT-L/16, ViT-H/14를 higher resolution에서 fine-tuning을 했다 합니다.
Metrics
- Fine-tuning Accuracy
- 이는 특정 데이터셋에 모델을 fine-tuning한 후의 성능을 나타냅니다.
- 모델이 특정 데이터셋에 얼마나 잘 적응하고, 해당 데이터셋에서 얼마나 잘 수행하는 지를 의미합니다.
- Few-shot Accuracy
- Few-shot learning은 매우 제한된 데이터를 사용하여 모델을 학습하거나 평가하는 것을 의미합니다.
- 이는 이미지의 일부의 (고정된) 표현을 {1, -1}K 타겟 벡터에 매핑하는 것을 포함합니다. -> 회귀문제
- k: 클래스의 총 수를 의미
- {1, -1}: 각 클래스를 나타내는 이진값으로서, "1"은 해당 클래스에 속함, "-1"은 해당 클래스에 속하지 않음을 의미
4.2. COMPARISION TO STATE OF ART
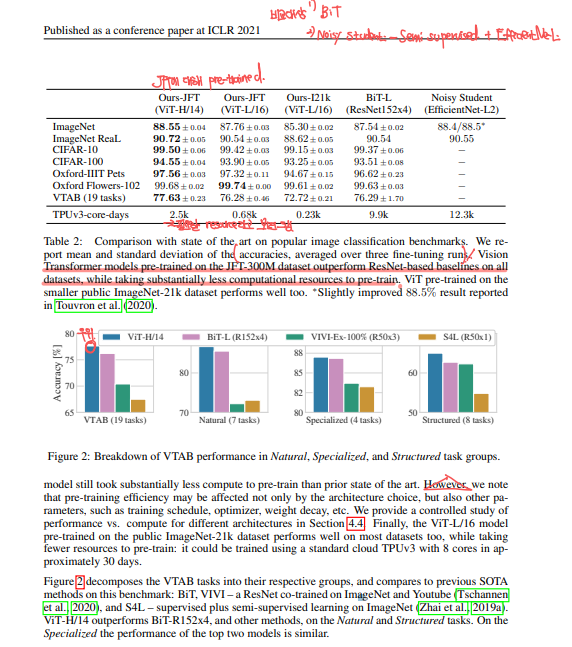
우선 ViT-H/14, ViT-L/16과 문헌상에 2021년에 문헌상 SOTA라고 되어있는 BiT(large ResNet)를 비교합니다. 두번째 SOTA로는 Noisy Student (Xie et al., 2020)인데, Efficient Net기반 모델로서, semi-supervised learning을 ImageNet과 JFT-300M에서 라벨을 지우고 knowledge distillation을 통해 작은 네트워크로 큰 네트워크를 훈련하는 방식으로 진행합니다. Noisy Student에 대해서는 이전에도 다루었고 추후에 있을 포스팅에서 더 전문적으로 다루어보겠습니다. 그리고 Table2에는 TPUv3-core-days가 있을텐데 이는 pre-train시킬때에 하루에 다시킬려면 몇개의 TPUv3 core가 필요한지에 대해 수치화한 값으로서 높으면 많은 리소스가 필요하다는 의미입니다.
Table2결과를 정리해보겠습니다. JFT-300M(303M)에 대해 pre-trained된 ViT-L/16모델이 이보다 더 큰 모델인 BiT-L보다 모든 task에 대해서 우월합니다. 또한, pre-train시에 더 적은 계산 리소스가 필요합니다. 또한 더 큰모델인 ViT-H/14는 더 많은 성능 향상이 있습니다. 심지어 ViT를 더 적은 데이터셋인 ImageNet-21k(14M)에서 pre-train시에도 성능이 좋았다 합니다.
4.3. PRE-TRAINING DATA REQUIREMENTS

ViT는 JFT-300M에서 pre-trained할때에 성능이 가장 좋습니다. 이는 ResNets보다 더 적은 inductive biases를 가지고있는데, 그럼 dataset의 크기는 얼마나 중요할지 살펴보겠습니다.
논문에서는 ViT 모델을 ImageNet, ImageNet-21k, JFT-300M순으로 데이터셋을 적은순으로 실험했습니다. 그리고 더 적은 데이터셋에서 성능을 높이기 위해, weight decay, dropout, label smoothing을 최적화했다고 합니다. 위에있는 Figure3는 ImageNet에 대해서 fine-tuning시킨 결과이고, Appendix에 다른 데이터셋에 대해 fine-tuning시킨 결과도 있다니 한번 보시기 바랍니다. Figure3에서 ImageNet와 같이 작은 데이터셋에 대해서는 ViT-Large 모델이 ViT-Base에 비해 underperform되는 경향이 있음을 확인할 수 있습니다. ImageNet-21k도 비슷합니다. 하지만 303M개의 JFT-300M은 ViT-Large의 이점을 최대한 끌어올릴 수 있습니다. 그리고 Figure3에 있는 영역은 BiT에 의해 span된 performance영역입니다. 이러한 결과를 일으키는 원인은 --> ViT가 Convolutional Inductive Bias가 적기때문에 더 많은 데이터가 필요하기 때문입니다!
Figure4는 Linear few-shot 평가를 Pre-train을 JFT에서 시킨 모델에 대해 ImageNet데이터에 진행한 결과를 나타냅니다. 여기서 ResNet기반 모델이 pre-training sample이 적을수록 ViT에 비해 outperform하는 것을 볼 수 있습니다. 여기서 ViT-b와 ViT-B는 hidden dimensions가 1/2이 된 것을 말합니다.
4.4 SCALING STUDY

Figure5는 controlled scaling study로서, JFT-300M를 통해 pre-trained된 각기 다른 모델에 대해서 transfer performance를 측정한 결과입니다. 실험 모델은 7ResNets: R50x1, R50x2, R101x1, R152x1, R152x2, pre-trained for 7epochs, plus R152x2, R200x3 pre-trained for 14 epochs; 6 ViT: ViT-B/32, B/16, L/32, L/16, pre-trained for 6 epochs, plus L/16, H/14 pre-trained for 14 epochs; 5 hybrids, R50+ViT-B/32, B/16, L/32, L/16 pre-trained for 7 epochs, plus R50+ViT-L/16 pre-trained for 14 epochs. 여기서 hyprid의 /32는 patch-size가 아니며, ResNet Backbone에서 총 downsampling ratio를 의미합니다.
정리하면 작은 크기의 모델은 Hybrid > ViT이고, 일반적으로는 ViT > BiT이라고 할 수 있습니다. 또한, 여기서 눈여겨볼 점은 ViT의 성능이 아직 Saturate(=포화)되지 않았으므로 성능향상의 여지가 더 남아있다는 점입니다.
4.5 INSPECTING VISION TRANFORMER

ViT의 데이터 처리 방법을 이해하기 위해, Internal Representation을 확인해야합니다.
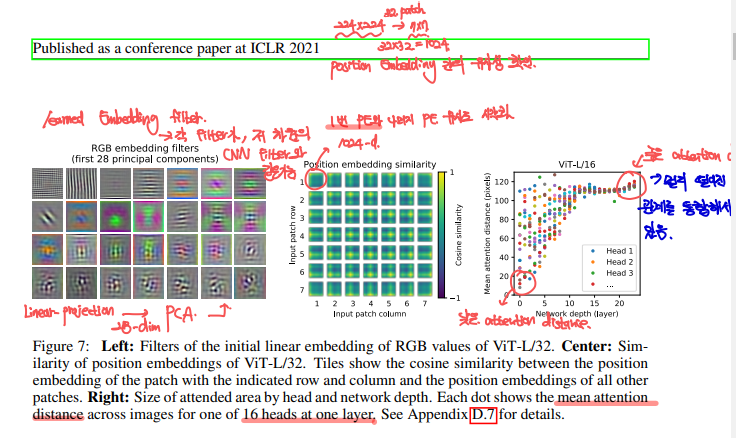
ViT의 첫번째 layer는 linearly project를 해서 patch를 lower-dim space로 매핑하는 역할이였습니다. Figure7의 왼쪽 그림을 보면, 해당 learnable matrix를 시각화 한 것입니다. 이는 low-dim에서의 CNN conv filter와 매우 유사한 것을 볼 수 있습니다.
ViT의 두번째 layer는 learned position embedding이였는데, 이는 patch representation에 더해졌었습니다. Figure7의 가운대 그림을 보게되면, 가까운 patch간에는 유사성이 높은 것을 볼 수 있습니다. 이는 Input Patch간의 공간정보가 잘 학습되었다고 할 수 있습니다.
ViT의 Self-attention은 ViT로 하여금, 전체 이미지 정보의 통합 가능 여부를 확인할 수 있습니다. 논문에서는 Attention의 가중치를 기반으로 Image Space간 평균 거리를 계산한 값을 Attention Distance로 설정했습니다. 그리고 그림에는 각 head별로 구한 Attention Distance(=Receptive Field)를 network depth에 따라 점을 찍어놓았습니다. 위와같은 결과는 낮은 layer의 self-attention head는 CNN처럼 localization효과를 보인다는 것을 알 수 있습니다. -> 네트워크의 depth가 깊어질 수록 Attention Distance도 증가하는데, 이는 더 깊은 곳에서는 이미지의 더 넓은 부분을 의미하는 것을 말합니다. 그리고 다른 어텐션 헤드들은 초기 레이어에서 지속적으로 작은 Attention Distance를 보이는데, 이는 초기 Convolution layer와 유사한 기능을 함을 알 수 있습니다. Hybrid model에서는 이러한 고도로 로컬화된 어텐션이 더 두드러진다고 합니다.
4.6 SELF-SUPERVISION
NLP Task에서 수행되는 Self-supervision 학습 방법을 시도해봤다고 합니다 (BERT의 경우는 input을 masking한 후, 한 단어를 올바르게 예측하도록 학습합니다). ViT Self-Supervision의 결과는 ViT-B/16모델은 79.9%의 정확도를 보여 우수하다고 합니다. 하지만 여전히 Supervised 방식보다는 낮은 수치입니다.
5. CONCLUSION

Image specific Inductive Baises를 사용하지 않고, Self-attention을 적용했습니다 (초기 patch단계 제외). ViT는 Large Dataset(JFT-300M)급에서 매우 잘 작동함이 실험적으로 보여졌습니다. 또한, Pre-train cost가 ResNet(BiT)와 비교했을때에 상대적으로 저렴했습니다.
이제 남은 과제는 Detection, Segmentation, Self-Supervised learning등이 있을것입니다. 또한, 여전히 Scaling 여지가 있다고 했었는데, Scaling을 통한 추가적인 성능 향상을 기대해볼 수 있겠습니다.
To be Continue
ViT의 한계점을 극복한, DeIT, CvT,.. 등을 알아보겠습니다. 또한, Detection의 DETR과 현재 SOTA모델인 CO-DETR, segmentation의 Segformer, oneformer,.. 이미지에 색입히는 ColTrans, Low-Shot Learning의 CT,.. 갈길이 멉니다.
우선 DeIT를 리뷰하기 위해서는 Knowledge Distillation의 개념에 대해 알아야합니다. 그리고, ViT에서 활용했던 Noisy student가 Knowledge Distillation과 비슷한 맥락에 있는 것 같아, 현재 SOTA를 찍은 김에 한번 알아보겠습니다.
https://hyunseo-fullstackdiary.tistory.com/420
[ 딥러닝 최신 알고리즘 - PRMI Lab ] - ViT 구현과, huggingface를 이용한 fine-tuning
https://github.com/eunoiahyunseo/rofydeo-model-archiving/tree/main/models/ViT 해당 github 주소에 코드들은 올려 놓았습니다. 모델 구현 # pytocrh와 기타 util라이브러리를 import해온다. import torch import torch.nn.functional as
hyunseo-fullstackdiary.tistory.com
코드 구현입니다.