[ 딥러닝 최신 트렌드 - PRMI Lab ] - CNN 발전 방향 (SeNet., EfficientNet., Noisy Student., Meta Pseudo Labels.)
이번에는 ResNet이후에 CNN의 발전 과정에 대해 간단하게 정리해보는 시간을 가져보도록 하겠습니다. 사실 CNN의 응용 분야에서 Object-detection, Sementic-Segmentation,.,. 많지만 오직 Classification에서만 살펴보도록 하겠으며, 응용분야의 발전에서는 다음 포스팅에서 조사하고 글을 작성해보도록 하겠습니다.
저는 이번 글을 작성하면서 정말 짧은 시간 내에 CNN이 발전을 많이했고, 앞으로도 발전 가능성이 유망하다는 것을 다시한번 느꼈습니다. 이에 좀 재밌기도 하였고 공부할 의지가 더 샘솟게 되는 계기가 되었답니다 ㅎㅎ. 한번 함께 보시죠.
Before Trend

2016년도에 ResNet이 이 기존의 SOTA모델보다 레이어를 훨씬 깊이 쌓아서 Top-5 error를 3.57%까지 줄였었습니다. 여기에서는 Skip-connection이 사용되어서 Gradient Vanishing 문제가 발생하지 않게끔 했었습니다.

사실 그 이후에도 DenseNet이라고 해서 skip connection을 보다 일반화 하여 옆의 붙어있는 layer뿐만이 아닌 모든 layer간에 skip connection을 붙인 모델이 있었습니다. 이를 통해 gradient vanishing 문제를 더 완화할 수 있었습니다. 위에 보이는 구간이 Dense Block이라는 것인데, 어쨋든 이 모델에도 down sampling(=pooling)이 있어야 하므로, 해당 구간을 제외한 구간에 서로 다르게 DenseNet block을 취해서 구현이 되었습니다.

이를 통해 기존의 ResNet보다 훨씬 성능이 개선된 것을 볼 수 있습니다. 같은 FLOPs상에서의 validation error를 나타낸 것이 오른쪽 Figure 3입니다.
SeNet (2017~2018)
SeNet은 Squeeze-and-Exitatio Networks로써, ILSVRC 2017에서 SOTA모델이였습니다. 이에 대한 간단한 소개와 실험 결과를 살펴보겠습니다.

먼저 위와같이 기존의 Residual block 대신에 SE Block을 Convolutional layer뒤에 병렬적으로 (skip connection과 함께) 붙여 성능을 개선할 수 있었습니다.
SeNet은 채널간의 상호작용에 집중하여 성능을 기존 SOTA모델보다 끌어올린 모델입니다. 채널간의 상호작용을 아래 그림에서와 같이 강주치로 생각해서 이를 채널마다 가중치를 다르게 부가해서 곱합니다. 즉, SeNet은 채널 간의 가중치를 계산하여 성능을 끌어올린 모델로 생각해 볼 수 있습니다.
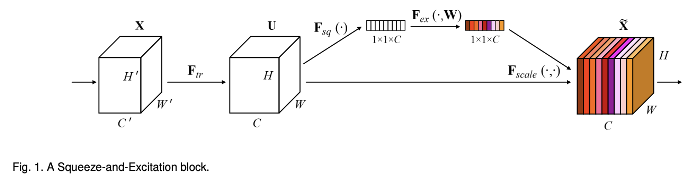
위 그림은 SE Block에서 Squeeze(압축) + Excitation(재조정)을 통해 채널별 가중치를 계산하고 피쳐맵에 곱해지는 모습입니다. 이렇게 함으로써 가지는 장점에 대해 살펴보겠습니다.
SE Block의 장점
1) 유연하다
이는 기존에 앞에 붙어있는 어떤 Convolutiaon Net에도 붙일 수 있음을 의미합니다. SE Block 앞에 오는 네트워크가 Inception이든 Residual 네트워크든 상관없다는 것입니다.
2) 추가적인 계산량이 적다
위에 보는 것과 같이 Global Average Pooling이 수행되어서 파라미터 증가량이 조금 있으나, 성능 향상이 확실하다는 장점이 있습니다. 그리고 위에 Fig3을 보시면 파라미터 $W1, W2$가 추가되지만 ratio를 작게 설정하면 파라미터 수가 작아집니다. Convolutional layer 하나당 $2C^{2}/r$개의 파라미터만을 늘어나게 됩니다. (논문에서는 r=16일때가 보통 적절하다고 합니다.)
SE Block의 성능

같은 GFLOPs상에서 같은 네트워크만 봐도, original -> re-implementation ->SeNet 으로 보면 SeNet의 top-1, top-5 에러가 준 것을 볼 수 있습니다.
즉 모든 블록 모듈이 각 모델들에 붙을 경우, 성능이 조금씩 상승하게 되는 효과가 있게 되었다! 라는 점입니다.
EfficientNet (2018~2019)
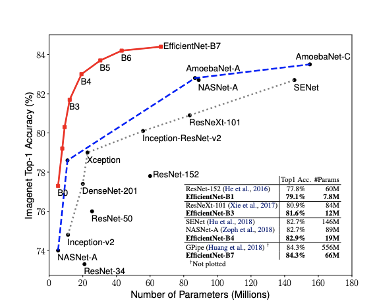
SeNet다음에 나타난 SOTA 모델이 EfficientNet입니다. EfficientNet이 등장하고 나서 CNN의 발전 방향은 아얘 다른 방향으로 흘러가게 됩니다.
바로 모델이 항상 깊은 것이 좋은게 아니라는 겁니다. 적절한 깊이의 튜닝을 잘하게 되면 모델 성능이 충분히 나오고 SOTA에 근접하다라는 겁니다. 이는 AutoML(Hyper Parameter Optimization; HPO)를 도입하여 search space내에서 최적의 값을 찾았습니다. (사실 AutoML이 발전함에 따라서 EfficientNet이 발견된게 아닌가 싶네요) 그리고 AutoML을 돌릴려면 엄청난 GPU power가 필요한데, 이를 갖춘 기업이나 연구소에서 찾은것이라고 보면 되겠습니다.
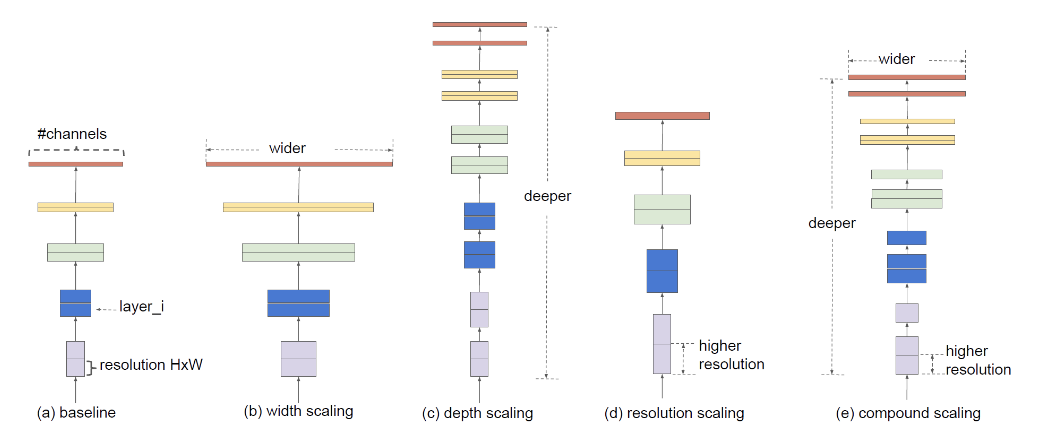
모델을 크게 만드는 방법
우선 EfficientNet을 보기 전에, 모델의 크기를 키우는 방법 3가지에 대해 간단히 살표보겠습니다.
1) network의 depth를 깊게 만드는 것
2) channel width(filter 개수)를 늘리는 것(width가 넓을수록 미세한 정보가 많이 담겨짐)
3) input image의 해상도를 올리는 것
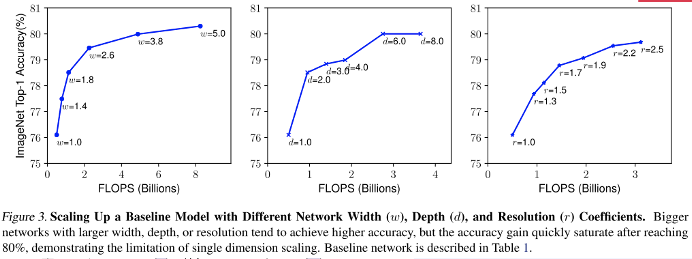
위의 실험 결과를 보면, 1, 2번째 그림에서 Width와 Depth를 늘리면 어느정도 FlOPS가 늘어날 수록 Saturation이 발생하는 걸 볼 수 있습니다. 하지만 3번째 그림을 보면, resolution은 적은 FLOPS에 비해 높은 Top-1 Accuracy가 나타나는걸 볼 수 있습니다.
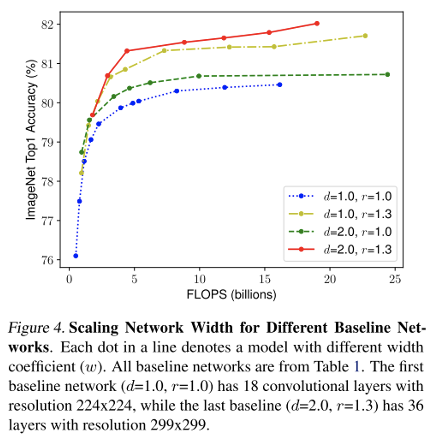
Depth와 Resolution을 고정하고 width만을 조절하여 성능 그래프를 보겠습니다. 노란색, 빨간색(d=1 -> d=2)의 성능 변화는 크게 없었습니다. 하지만 초록색, 빨간색(r=1 -> r=1.3)을 보면 성능 변화가 크게 있는 것을 파악해 볼 수 있습니다.
그럼 Resolution(=해상도)이/가 뭐냐 짚어드리고 가겠습니다. 위의 Fig2에서 앞단의 Channel의 개수를 늘린 것이라고 볼 수 있겠습니다. 이러한 Channel 개수를 늘리게 되어 이미지의 Resolution을 높이게 된다면, 모델의 성능이 크게 변화한다는걸 2019년 AutoML이 등장하고 나서 드디어 발견하게 된것입니다!
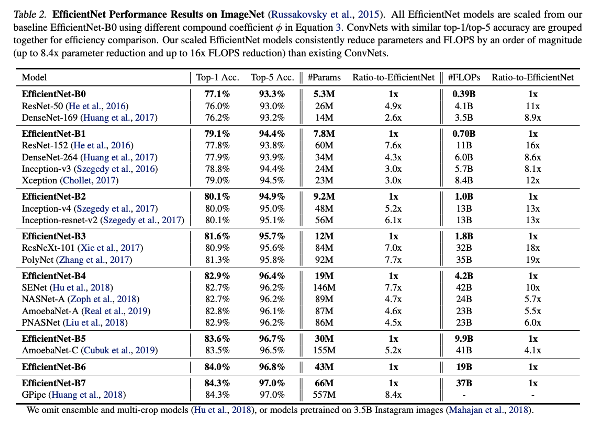
위 실험 결과에서 EfficientNet-B1을 보면, Top-1 Acc가 79.1%인데, #Params가 7.8M밖에 되지 않고 그 아래 ResNet-152,.. Xception모델은 파라미터 수가 이보다 훨씬 높지만 정확도가 낮은것을 볼 수 있습니다.
즉 ResNet, DenseNet보다 빠르고, 가볍고 성능이 좋다는 EfficientNet이 제안되었다는 것을 해볼 수 있있겠습니다.
Self-training(자가 학습 기법)과 Data augmentation (2019)
EfficientNet이 등장한 이후, 발전 방향은 모델 보다, 데이터나 학습 과정을 개선시키는 것을 위주로 CNN 트랜드가 바뀌게 되었습니다.

그래서 그 당시에 2019년 SOTA는 Efficient의 data augmentation 기법에 맞추어 train/test에 사용하는 augmentation을 할때에 맞춰 모델의 scaling을 개선한 방법이였습니다.
이에 자가 학습(self-training)에 대해 Recap하고 가보겠습니다.
1) 준지도 학습 (Semi-supervised learning)
준지도 학습은, 레이블된 데이터와 레이블 되지 않는 데이터 모두를 사용하는 학습기법입니다. 일반적으로, 다수의 레이블되지 않는 데이터와 레이블 된 골드 레이블 (glod label)데이터로 구성됩니다.
2) 자기 지도 학습 (Self-supervised learning)
자기 지도 학습은 다량의 레이블이 없는 원데이터로부터 데이터 부분의 관계를 통해 레이블을 자동으로 생성하여 지도 학습에 이용하는 것을 말합니다.

자가학습을 알고리즘 측면에서 보면, 먼저 $L$ base model $f_{\theta}$를 레이블이 있는 걸로 학습을 합니다. 그 후에, $f_{\theta}$를 unlabeled instances $U$를 적용하게 되는데, 이에 대한 예측 결과 $\hat{y}$가 있다면 이에 대한 라이블을 기존의 $L$과 합집합하여 성능이 높아질 때까지 반복하는 작업이라고 볼 수 있겠습니다.
Self-training (자가 학습 기법)과 Noisy Student (2020)
Nosiy Student는 자가 학습과, EfficientNet을 사용합니다. Noisy Student의 순서에 대해 간닪기 소개하도록 하겠습니다.
1) Efficient Net 모델을 teacher 모델로, ImageNet 데이로 학습시킵니다.
2) 학습된 teacher 모델로 라벨이 매겨져 있지 않은 3억장의 이미지에 라벨을 매깁니다.
3) teacher 모델보다 크기가 같거나 큰 student network를 생성한 뒤, ImageNet데이터와 라벨을 매긴 데이터를 합쳐서 학습시킵니다.
-> 이 과정에서 noisy를 더하게 되는데, data augmentation, dropout, stochastic depth등을 적용합니다.
4) 학습된 student 모델을 teacher 모델로 바꾸고, 2-4 과정을 반복합니다.

이를 그림으로 보면 위와 같습니다. 위 순서를 그림으로 나타낸 것인데, 실제 원 논문을 퍼온것입니다.
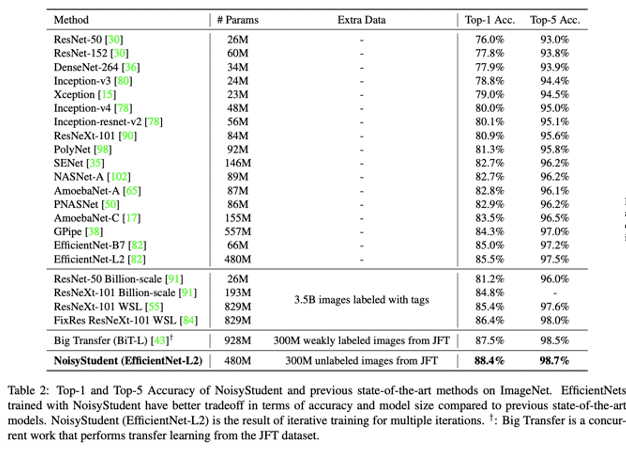
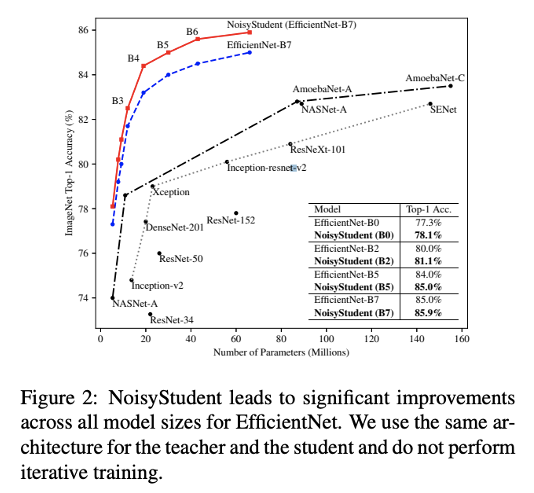
해당 Noisy Student기법을 사용하여, 기존의 EfficientNet과 비교했을 때, 더 높은 성능을 기록했다고 합니다.(같은 학습 파라미터 상에서, 더 효율적이라는 의미) 그래서 2020 SOTA를 찍은 네트워크라고 합니다.
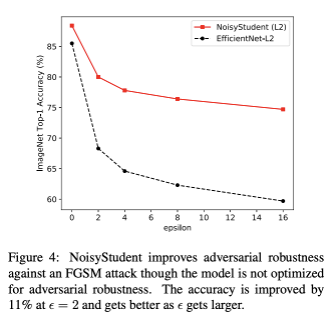
그리고 nosie를 추가했기 때문에, adversarial attack(적대적 공격)에 기존의 EfficientNet보다 훨씬 Robust함을 실험결과로 볼 수 있습니다.
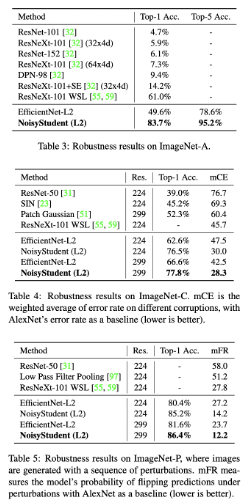
그리고 ImageNet-A,C,P란 모델의 robustness를 테스트하기 위해 ImageNet의 corruption을 담은. 데이터입니다. 여기에는 burring, fogging, rotation, scalinge등이 들어있는데, 이에 대해 Nosiy Student가 기존의 ~ResNext, EfficientNet보다 훨씬 좋은 성능을 보였다고 합니다.
Pseduo Labeling
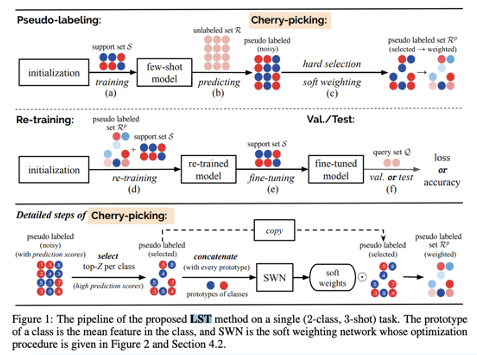
그리고 다시 Pseudo Labeling을 보면, 기존의 few-shot model을 S(=label된 데이터)를 가지고 학습시킵니다. 이를 통해 unlabeled set R을 predict합니다. 이에 대한 pseudo label을 만들어서 이 중에서 hard-selection(=모델이 확신하는 것, confidence score가 높은것만을 뽑음), soft-weighting(=모든 데이터에 대해 pseudo label을 생성하되, 예측 확신도에 따라 가중치를 부여하는 방식) 을 통해 pseudo labeled Set $R^{p}$를 만듭니다. 이를 또 Re-training을 통해 모델을 fine-tuning해가는 과정을 거칩니다.
하지만 제대로 학습을 마치지 못한 모델로 하였을 경우, 모델의 학습을 저해하는 데이터를 만들 뿐입니다. 이는 위 두 과정을 따로따로 해서 발생하는 문제로서, 기존에 SOTA였던 Noisy Student의 단점이기도 합니다. 그래서 이 두개의 작업을 따로 하는 것이 아닌, 동시에 적용해야 합니다!
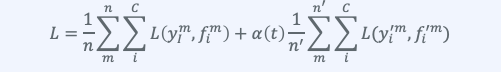
그래서 위와같이 손실함수를 정의해서 원래 학습과 Pseudo labeling된 데이터의 학습을 동시에 진행해야 합니다. 여기서 $\alpha(t)$는 두 식을 balancing하는 coefficient로 매우 중요한 하이퍼파라미터가 됩니다.
Pseudo labeling이 동작하는 이유?
Pseudo labeling이 동작하는 이유에 대해 간단히 살펴보겠습니다. 모델의 분류과정에서 decision boundary를 결정할 때, 그 경계를 구분하는 지점의 데이터가 몰려있는 밀도가 낮으면 낮을수록, 더 미세한 차이점도 구별한다고 생각할 수 있기 때문에 전체적인 성능을 높일 수 있게 됩니다.
즉 pseudo-labeling은 모델이 데이터의 복잡한 분포를 더 잘 이해하고, 데이터 공간에서의 저밀도 영역을 더 잘 인식할 수 있게 할 수 있습니다. 그래서 몇몇 논문에서는 이가 Entropy 정형화(regularization)효과가 있다고 말하기도 합니다.
Meta Pseudo Labels (2021)
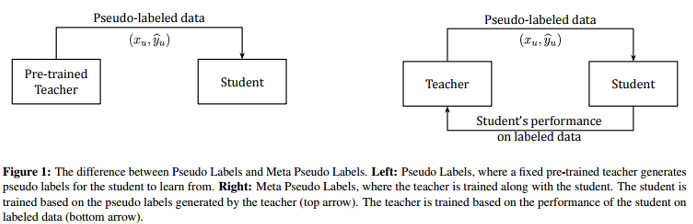
Meta Pseudo Labels는 2021 SOTA 모델입니다. 이는 teacher, student를 동시에 학습합니다. 이때, student의 labeled data에 대한 performance가 teacher에 대한 학습에 영향을 주게됩니다. (일종의 강화학습에서의 reward signal이라고 할 수 있습니다)
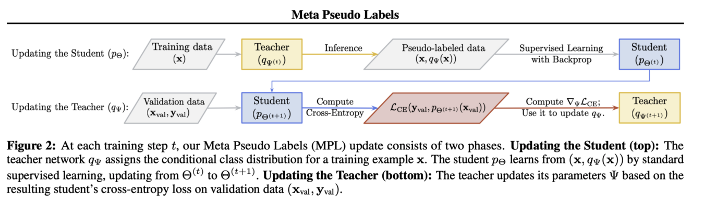
본 논문에서는 3가지 Phase를 말하고 있습니다.
Phase 1) Teacher x의 결과로 Pseudo-label을 만들고 student에게 주고 student의 weight를 supervised learning (cross entropy)로 업데이트 합니다.
Phase 2) student의 validation loss를 재사용하여, teacher의 weight역시 업데이트 합니다.
Phase 3) 부가적으로 UDA에서 제안된, UDA objective(Auxiliary terim)을 조금 더해 보완하여 완성합니다.
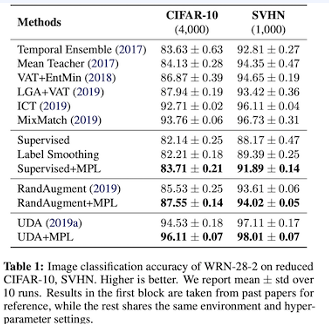
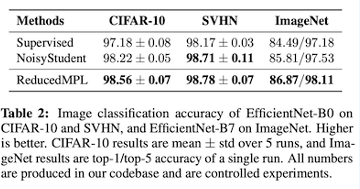
위와같이 Noisy Student보다 나은 성능을 보이게 되었습니다. 그리고 최근 이미지 처리는 앞서 본 많은 실험 결과 표에서도 나와있었겠지만, Transformer와 같은 개념들이 추가되면서 CNN에 국한되지 않게 되는 추세라고 합니다. 그래서 아마 이번주 내에 RNN에 대한 내용도 DETR을 정리하면서 어느정도 하긴 했지만, 한번에 핵심 개념만을 정리하는 시간을 가져보도록 하겠습니다.