[ 딥러닝 논문 리뷰 - PRMI Lab ] - DETR: End-to-End Object Detection with Transformers
Transformer는 주로 자연어 처리 분야에서 시작하여 뛰어난 성능을 보였습니다. 그 구조와 특성 때문에 이미지 처리 분야에서도 활용될 수 있다고 합니다. 그 이유는 아래와 같습니다.
- Self-Attention: Transformer의 가장 핵심입니다. 이는 입력 데이터의 모든 부분이 서로 상호작용하는 데에 도움이 됩니다. 이미지 분야에서, 이것은 모든 픽셀이 다른 모든 픽셀과 상호작용 할 수 있게 도와줍니다. 결과론 적으로 이는 전역적인 후보군을 NMS와 같은 preprocessor없이 후보군을 direct하게 추출할 수 있게 돕습니다.
- 병렬 처리: Transformer는 전체 시퀀스를 한 번에 처리합니다. 이것은 자연어 처리 작업에서 RNN과 비교하여 계산 효율성이 훨씬 뛰어나다는 것을 의미합니다. 이미지 처리 분야에서도 마찬가지입니다. 이미지를 픽셀 단위의 시퀀스로 처리하거나 이미지 패치를 시퀀스로 처리하는 등의 방식으로 이미지 분야에 적용할 수 있습니다.
- Scale Invariance: Transformer는 입력 데이터의 길이에 관계 없이 동작합니다. 이는 다양한 크기와 해상도의 이미지를 처리하는 이미지 인식 작업에 특히 유용합니다.
DeTR은 이후에 자세히 보겠지만, 먼저 전통적인 Pre-trained된 CNN를 사용하여 이미지에서 피처 맵을 추출합니다. 이 패처 맵은 그 후이 flattening 과정을 거쳐 1차원을 시퀀스로 만들어지며, 이 시퀀스는 Transformer의 인코더에 입력됩니다. 이 시퀀스의 각 요소는 이미지의 특정 영역을 나타내며, Transformer 인코더는 이러한 정보를 사용하여 이미지 내의 다양한 객체들 사이의 관계를 학습하게 됩니다.

Classical Apporach to Detection

기존의 Detection 순서를 나열한 것입니다. 기존의 detection문제는 bounding box를 찾고 그 안의 인스턴스를 classification하는 문제라고 할 수 있습니다. 이를 위해서는 수많은 candidate boxes중에서 subset을 선택할 필요가 있습니다. 이 subset들을 토대로 Regression을 통해서 예측을 refine해가는 스텝이 필요하죠.
그런데 이러한 과정에 필요한 기술이 anchor box, NMS라는 기술이 필요합니다. 하지만 이러한 기술들이 매우 heuristic한 기술이라는 점입니다. 이러한 기술들은 매우 differentiable하지 않기 때문에, 해당 논문의 저자들은 nice한 방법이 아니라고 지적합니다.
딥러닝의 철학은 End-to-End 인데, 해당 방법은 그렇지 못하다는 것이죠.
DETR in a nutshell

뒤에서 자세히 보면서 말하겠지만, 이 DETR은 Set prediction formulation을 사용하고, NMS, anchors와 같은 geometric priors를 사용하지 않습니다. 이로인해 Fully differentiable하고 기존의 SOTA였던 Faster R-CNN과 Competitive한 Performance를 보여줬다고 합니다. 그리고 다른 분야의 task(=panoptic segmentation,.. etc)와 확장가능하다는 점이 DETR의 주요 특징이라고 할 수 있겠습니다.
Streamlined Detection Pipeline

위는 매우 간소화된 detection 아키텍쳐를 보여줍니다. 위의 Faster R-CNN에서는 Region Proposal 방법을 위해 RPN을 두어서 200,000개의 coarse proposals를 만든다음에 NMS를 통해 한번 추리는 과정을 통해 RolAlign을 통해 classifiy를 하고 또다시 NMS통해 bounding box들에서 중복된 것을 삭제하는 과정을 수반합니다.
하지만 DETR그림을 보면, 그냥 CNN feature를 transformer encoder-decoder 구조에 넣으면 direct한 Predicted boxes하고 classes가 나오는 것을 볼 수 있습니다.
DETR

위의 그림은 DETR의 자세한 구조를 나타냅니다. 우선 transformer에 feature를 넣으면, Set of box predictions(=N)가 나옵니다. 위의 그림에 다르면 N=6즉 서로다른 6개의 prediction이 결과로 나옵니다. 그리고 이가 Biparate Matching을 통해서 실제 Loss를 가장 줄일 수 있게 하는 Matching을 Hungarian Algorithm을 통해서 Ground Truth와 실제로 매칭해주는 작업을 합니다. 위의 그림을 보면, 검은색, 파란색, 주황색은 No object {0}이고 빨간색, 노란색, 초록색이 실제 인스턴스가 있는 bounding box로 예측했는데 이를 Biparate Matching을 통해 GT와 매칭해서 학습하는 걸 볼 수 있습니다.

위에서 제가 적은 N은 실제 우리가 예측하고자 하는 인스턴스의 수보다 크게 잡아야 합니다. 이 논문에서는 COCO dataset으로 N=100을 잡고 진행했다고 합니다. 그리고 $\hat{y}$은 실제 N개가 나오게 되는데, $y$는 실제 GT의 개수이므로 남는 수만큼 $emptyset$을 (no object)의미로 추가했다고 합니다.
Bipartite Matching Cost

$\mathcal{L_{match}}(y_{i}, \hat{y_{\sigma(i)}})$는 실제 Hungarian algorithm을 통해 match 된 Cost라고 할 수 있습니다. 이 Cost를 최소화 하는 $\sigma$를 찾는 것이 $\hat{\sigma}$라고 합니다. 그리고 여기서 $(c_{i}, b_{i})$는 각각 target class label($\emptyset$ 포함), $[0, 1]^{4}$의 box coordinates와 width, height를 나타내는 vector입니다.
여기서 $\mathcal{L_{match}}(y_{i}, \hat{y_{\sigma(i)}})$의 식을 보면, $c_{i}\neq\emptyset$일 때의 $\hat{p_{\sigma(i)}}$인데, 실제 인스턴스일 확률 값이 높일 수록 -1을 곱해서 값을 최소화 시켜주려고 했고(잘 맞추면 Cost식이 작아져야 하니까), 뒤에서도 보겠지만 $\mathcal{L_{box}}$는 bounding box에 대한 식인데, 뒤에서 자세히 볼 것입니다.
여기서 주목해야할 점은 Cost함수가 cross-entropy형태가 아니라 그냥 확률을 곱하고 더했다는데에 있습니다. 이렇게 하는게 성능을 더 잘나왔다고 논문에 나와있습니다. 그리고 이 상황에서는 중복되는 상황에 나오지 않기 때문에 NMS필요 없다고 논문에 나와있습니다. 즉 Bipartite Matching Loss는 set prediction 문제에서 모든 가능한 예측-Ground Truth쌍에 대해 최적의 매칭을 찾을 수 있게 모델을 최적화 합니다.
Hungarian Entropy Loss (Hungarian Loss)
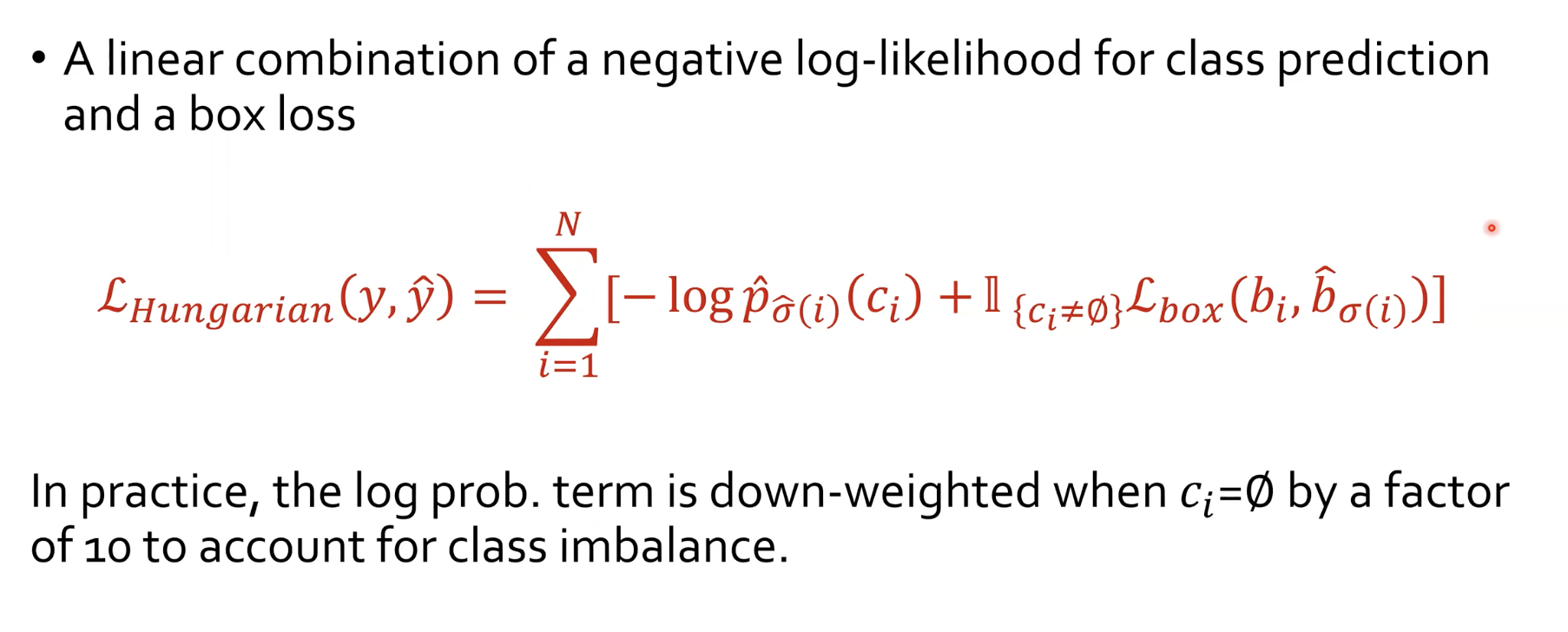
이는 실제로 위에서 찾은 (N개의)예측-Ground Truth쌍에 대한 최적의 매칭을 토대로, Negative log-likelihood(NLL)을 구하게 됩니다.여기서 주의해야 할 점은, 실제로 object detection 문제에서는 배경으로 예측하는 값들이 훨씬 많기 때문에 class imbalance가 발생하게 된다고 합니다. 그래서 이러한 불균형을 막아주기 위해 $c_{i}\eq\emptyset$인 경우 down-weighted factor를 10으로 해주어서 해결했다고 합니다.
이렇게 함으로써 DETR에서는 실제 객체가 아닌 '배경' 클래스에 해당하는 예측에 대한 손실 값을 작게 만들어서 모델은 배경 클래스에 대한 예측을 과도하게 중요하게 생각하지 않게 되어, Object Detection 성능이 향상될 수 있다고 합니다.
Bounding Box Loss

위에서 $\mathcal{L_{box}}(b_{i}, \hat{b_{\sigma_{(i)}}})$가 어떤 식으로 구성되어 있는지 보겠습니다. 위에는 실제 논문에 있는 부분입니다. 정규화 같은 상수를 참고하면 되겠습니다. (사실 정규화 상수는 그렇게 중요하지 않았다고 합니다)
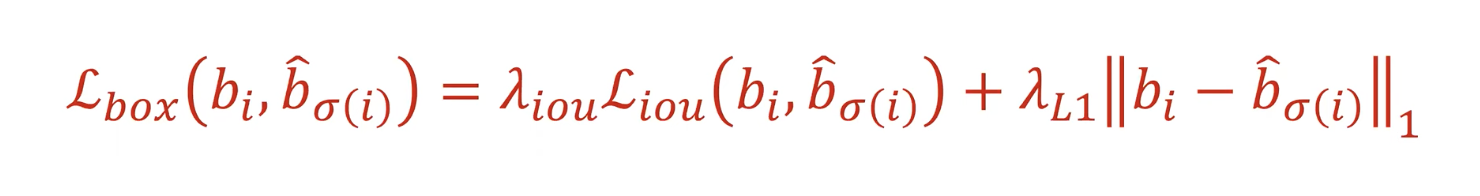
기존의 Object detection 모델에서는 anchor라는 Pre defined된 candidate이 있고, 이걸 얼마나 움직일지 $\delta$에 대한 loss를 학습하는 방식으로 되어있었습니다. 하지만 DETR은 box를 directly하게 예측하게 되고 이는 기존의 BBReg보다 손실이 더 있을 수 밖에 없습니다.
그래서 DETR에서 L1 loss를 사용하고자 하니 bounding box가 크다보면, 작은 거에비해 loss가 더 크게 형성이 되는 단점이 있습니다. 그래서 이러한 단점을 보완하기 위해 generalized IoU loss를 섞어서 쓰게 됩니다.
Overall Architecture of DETR
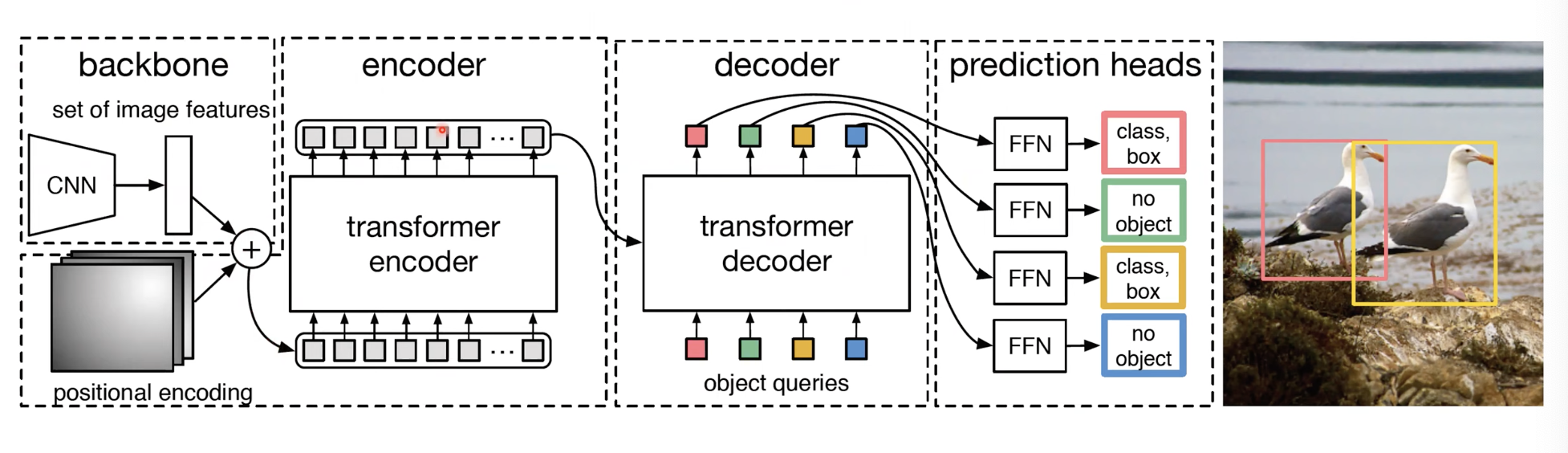
그리고 좀더 보면, Decoder에서 encoder의 츨력값과 N개의 object queries가 들어가게 됩니다. 뒤에서 더 자세히 보겠지만, 이 object queries도 학습을 하게 되고, 처음에는 random하게 채웁니다. 이 object queries가 일종의 positional encoding역할을 한다고 보시면 되겠습니다.
즉 실제 이미지에서 어떠어떠한 부분을 집중해서 볼건지와 encoder의 output을 가져와서 encoder-decoder attention을 통해서 encoder에서 들어온 Key, Value쌍과 decoder에서의 Query를 통해서 진행하게 됩니다. 그리고 decoder의 결과물 각각이 FFN을 통과해서 N개를 classification하게 됩니다.
이제 각각의 부분을 더 자세히 보겠습니다.
Backbone
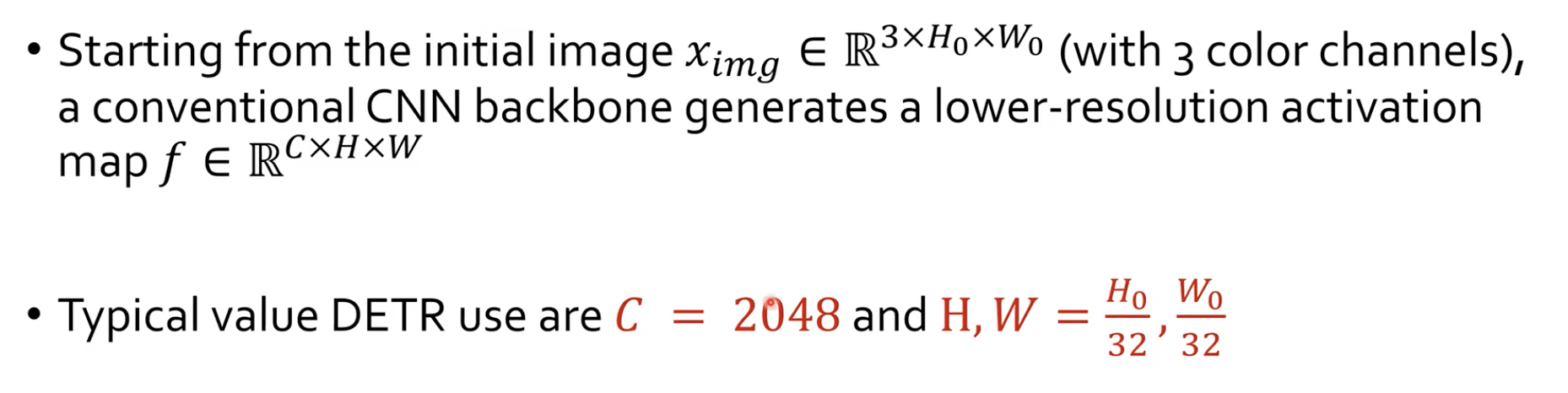
실제 initial image $x_{img} \in \mathbb{R}^{3 x H_{0} x W_{0}}$로써 3개의 channel을 가지는 RGB 이미지를 backbone에 투입하게 됩니다. 그리고 backbon CNN은 결과물로 lower-resolution activation map인 $\mathbb{R}^{C x H x W}$ 을 만들어 낸다고 합니다.
DETR에서 대표적인 C = 2048, H, W는 32배로 줄어든 값이라고 합니다. 보통 CNN에서 5번의 down-scale을 하게되는데 이에 대한 결과입니다. 그리고 DETR에서는 실제로 ResNet을 사용합니다.
Transformer Encoder

실제로 transformer의 encoder에 넣으려면 1x1 conv로 C=2048보다 작은 값인 d로 새로운 feature map을 만든다고 합니다. 그리고 encoder의 input으로 투입하려면 벡터로서 만들어주어야 하는데, 이를 위해 H, W를 flatten해서 d x HW의 feature map으로 만든다고 합니다. 즉 이의 의미는 sequence의 개수가 HW개가 되고 각각의 sequence의 벡터의 size가 d가 되게 됩니다.
그리고 transformer architecture는 permutation-invariant하게 되어서 저번 논문에서 봤다싶이 자연어 처리에서는 positional encoding방법을 사용하게 됩니다. 그래서 이와 비슷하게 DETR에서도 fixed positional encodings를 주게 됩니다.
여기서 positional encoding의 결과도 당연히 차원이 d여야 합니다. 이는 그냥 x축 따로, y축 따로 d/2씩 해서 positional encoding을 한다음에 concatenate하는 식으로 진행했다고 합니다.
Transformer Decoder

Decoder에서 학습이 가능한 object queries가 들어간다고 했습니다. 이가 필요한 이유 또한, Decoder가 permutation-invariant하기 때문에, 위치정보를 주어주기 위해 필요합니다.
이는 디코더를 통해 전달되면서, 인코더에서 나온 피처와 인코더-디코더 어텐션을 통해 상호작용하게 됩니다. 이를 통해 각, Obejct queries는 입력 이미지의 객체에 대한 정보를 포착할 수 있게 됩니다. 디코더가 각 Object queries를 처리한 후, 출력은 bounding box의 좌표와 해당 객체의 클래스를 예측하는데 사용됩니다.
그리고 Object queries는 이미지 내의 특정 위치를 가리키는 것이 아니라, 인식하려는 객체의 수를 나타냅니다. 따라서 이는 위치 정보인 Positional Encoding이 필요하지 않습니다.
Architecture of DETR's Transformer
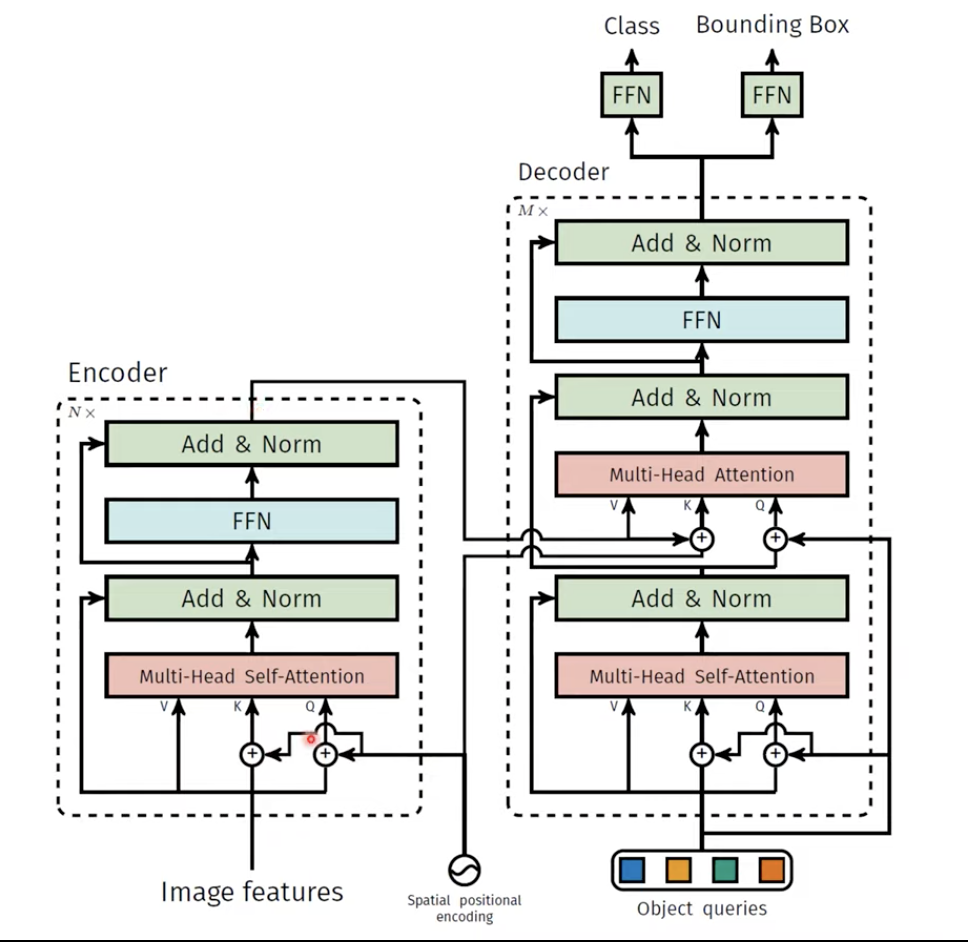
여기서 기존의 transformer의 아키텍쳐와 다른 부분은, Spatial positional encoding 정보가 매 Encoder, Decoder층에 투입이 되는 부분입니다. 그리고 Object queries도 인코더-디코더 어텐션 부분의 Query에 계속 추가되는 것도 하나의 차별적인 특징이라고 할 수 있습니다. 그 외에는 기존의 Transformer 구조와 같습니다.
그래서 최종적으로 Decoder는 FFN을 통과해서 Class, Bounding Box를 예측하게 되는데, 앞선 부분은 우리가 봤던 Hungarian Loss를 통해서 모델을 학습할 수 있게 하고, Bounding box는 앞서 봤던 GIoU와 L1 Loss를 합쳤던 식을 사용해서 모델을 최적화해 나갑니다.
Prediction FFN and Auxiliary Decoding Losses

마지막 FFN 쪽은, 3-layer percentron을 ReLU와 함꼐 hidden dimension d로 사용했다고 합니다. 그리고 FFN은 Auxiliary path를 두어서 decoder layer 하나를 통과할 때마다 매번 loss를 뽑아서, Loss가 여러군대에서 계산되도록 학습하게 했더니, 모델의 성능이 더 좋아졌다고 합니다.
Experiments

다음은 실험 결과입니다. 실험은 COCO 2017을 바탕으로 detection, panoptic segmentation을 진행했다고 합니다. 여기에는 평균 7개의 인스턴스가 각각의 이미지 상에 존재했다고 합니다.
그리고 백본으로는 ResNet-50(DETR), ResNet-101(DETR-R101)으로 사용했습니다. 그리고 backbone의 last-stage에 dilation convolution을 두어서 feature resolution을 키운 네트워크를 DETR-DC5, DETR-DC5-R101이라고 부르기로 했다 합니다.
추측이지만, 뒤에 실험 결과에서 DETR이 작은 Object에 대한 AP값을 측정해보니 큰 Object보다 성능이 좋지 않습니다. 그래서 Dilation을 두어서 작은 Object에 대한 성능을 올린 DC5 Network도 추가한 것이 아닐까 싶습니다.
Results
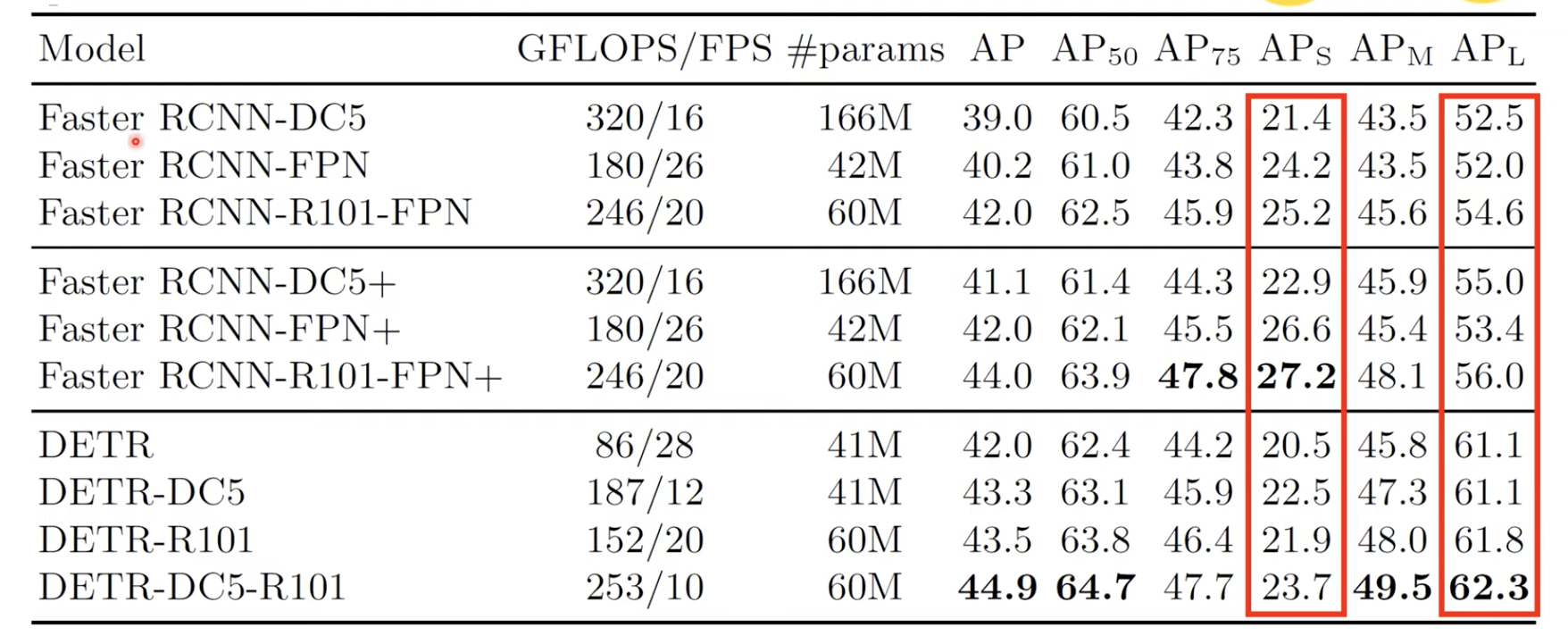
여기서 Faster RCNN과 (+)학습을 더 진행한 모델, DETR에 대한 실험 결과를 보여줍니다.
여기서 $AP_{L}$즉 Large Object에 대한 성능과 $AP_{S}$ Small Object에 대한 성능을 보여줍니다. 이는 Convolution은 지역적인 정보만을 보지만, Attention을 통해서 전역적인(global)한 정보를 한눈에 파악할 수 있기 때문입니다. 그리고 $AP_{S}$에 대한 성능이 좋지 않은 이유는 CNN으로 뽑아온 결과가 위치 정보가 많이 없어진 상태에서의 feature map이기 때문입니다. 그렇기 때문에 작은 물체에 대한 정보는 많이 사라질 것입니다. 이는 추후에 FPN(Feature Pyramid Network)로 어느정도 해결하게 됩니다.
그래서 논문에서 실제로 이는 개선되어야 하는 부분이고, FPN같은 걸 Backbone으로 하면 $AP_{S}$에 대한 AP 성능을 높일 수 있을 것이다라고 논문에서 언급하고 있습니다.
Deformable DETR
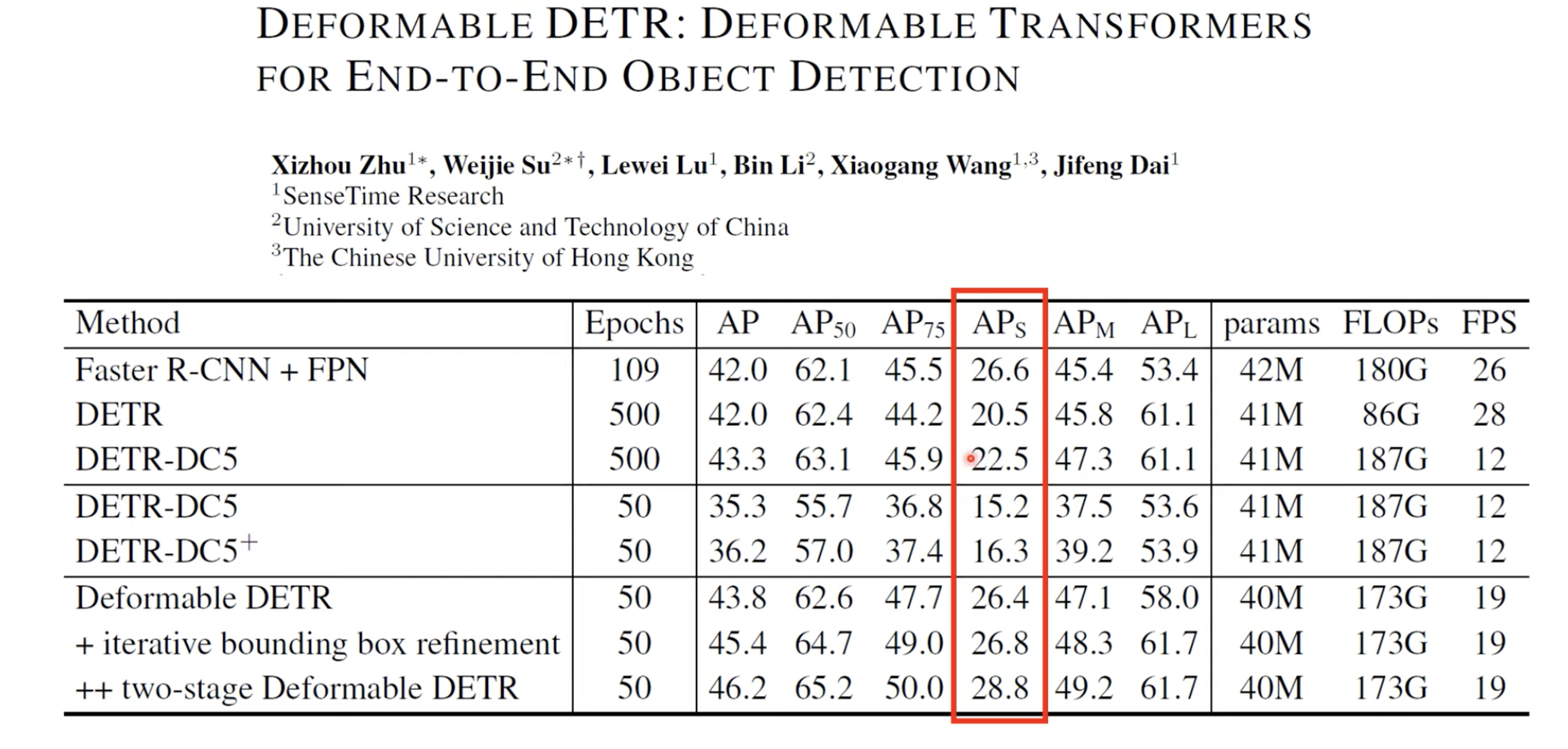
그리고 실제로 추후에 "Deformable DETR: Deformable transformers for end-to-end object detection"이라는 논문에서 SenseTime Research team이 $AP_{S}$에 대한 성능을 실제로 많이 높였습니다.
Number of Encodier Layers
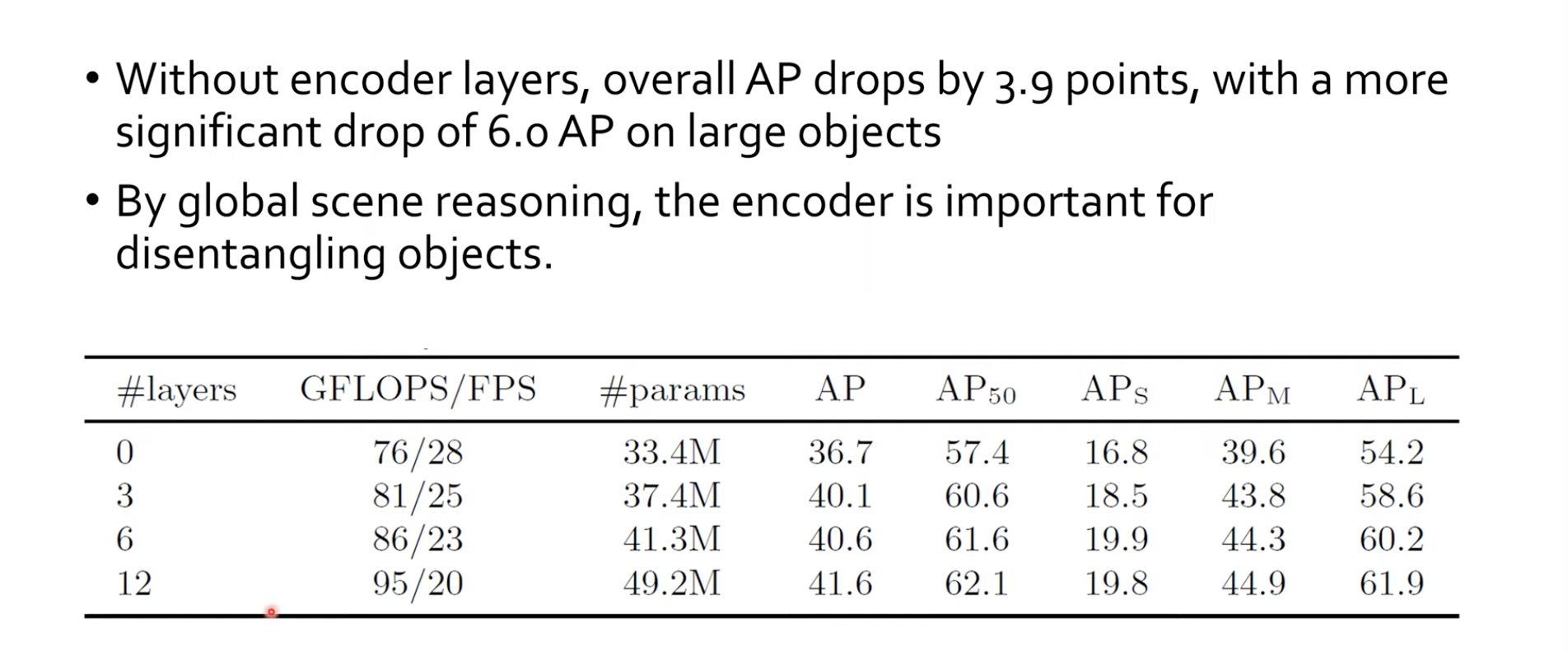
이제는 Ablation study 부분입니다. 이는 Encoder를 아얘 쓰지 않았을 때부터, 개수를 늘리면서 성능을 살펴본 실험 결과입니다. 당연히 Layer를 많이 쌓을 수록 계산량은 많아지고 FPS는 떨어지고 학습 파라미터수가 많아졌지만, 성능은 높아진 것을 볼 수 있습니다.
이렇게 만들어놓고 보니, Encoder part는 물체들을 disentangling하는 역할을 한다고 합니다. 즉 물체들을 구분하는 역할을 할 수 있었다고 하는데요, 이는 Self-Attention map을 통해 확인할 수 있습니다.

인코더에서는 실제 이미지에서 좀 줄어든 이미지에서 모든 픽셀 상에서의 Attention 작업을 진행하게 될 텐데, 그 때 계산된 point에 대해서 attention map의 값을 본것입니다. 여기에서 자기가 속한 Object에 대해서 Self-Attention map을 확인해 보니 잘 구분해 낸다! 즉 disentangling한다 라고 본겁니다.
이는 매우 놀라운 결과인데, 실제 인스턴스가 겹치는 부분도 겹치는 부분은 연하게 표시하고 실제 속한 인스턴스는 진하게 구분해주기 때문입니다. 정말 Transformer는 놀라운 매커니즘인거 같습니다!
Number of Decoder Layers
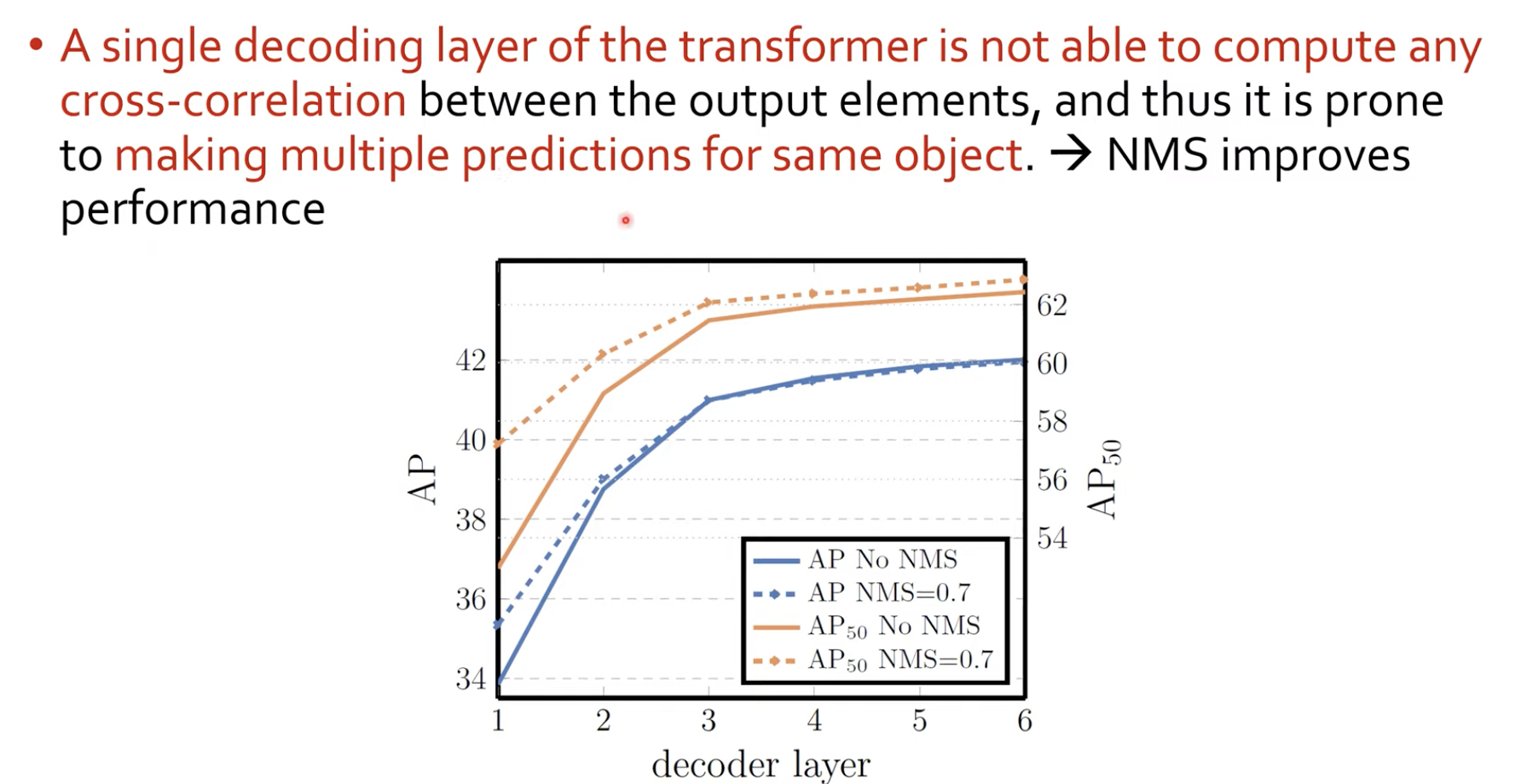
Decoder layer도 ablation study를 통해 아얘 없을때부터 추가해가면서 AP를 측정해보았습니다. 그리고 NMS도 실제로 수행해보았다고 합니다.
실제로 a single decoding layer of transformers즉 1개의 decoding layer를 사용하면 한개의 물체에 대해 여러개의 bounding box를 예측한다고 합니다. 이를 어떻게 알 수 있었냐면 NMS를 통해 성능이 올라갔기 때문에 간접적으로 예측할 수 있었다고 합니다. 그리고 decoder layer를 더 쌓으면 NMS를 했을 때의 성능이 더딘 것을 보아, decoder의 역할을 추측해 볼 수 있습니다.
Decoder Attention

그리고 Decoder에서 Object Queries마다 Attention이 어떻게 걸리는지 봤는데, 물체의 가장자리에 Attention값이 높게 찍혔다고 합니다. 이러한 특성은 Bounding box를 어디에 쳐야하는지를 정확하게 알 수 있는지를 Decoder에서 Object Queries로 학습을 한다고 유추를 할 수 있습니다.
Importance of Positional Encoding
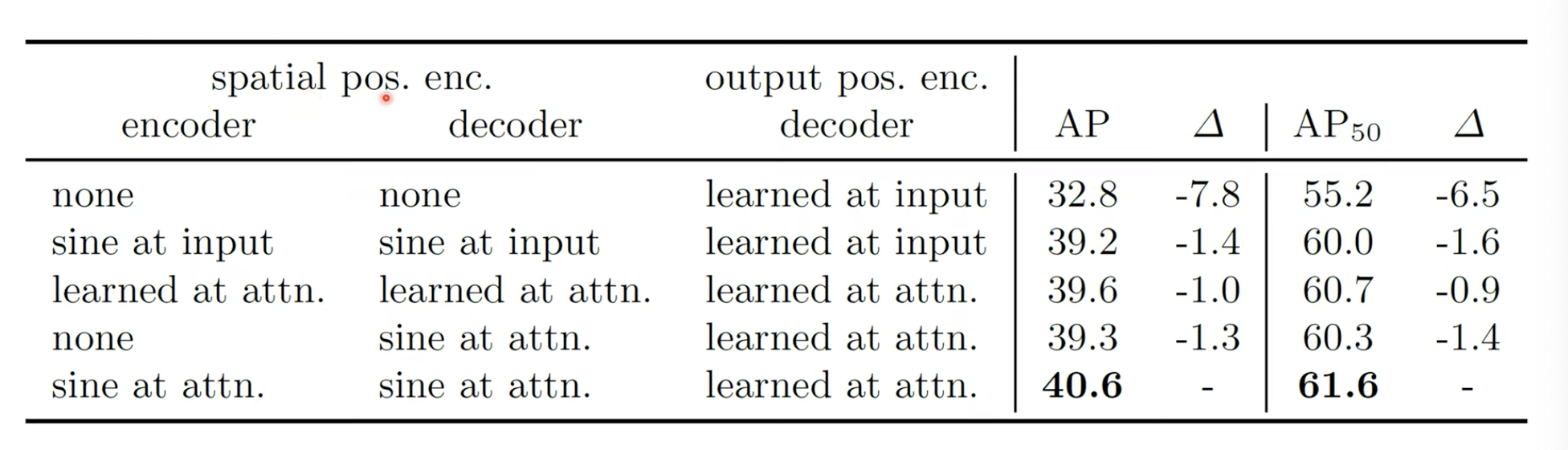
위의 DETR Architecture를 보면 Spatial Positional encoding의 정보를 그냥 encoder, decoder layer에 넣어주었는데, 이를 한쪽에서만 적용하고, 아얘 없애거나 sine 함수만을 사용했을 때의 값을 찍어본 것입니다.
여기에서는 attention block이 반복될 때마다 계속 positional encoding 정보를 넣어주는게 성능이 가장 좋았다고 합니다.
Loss Ablations

이는 필수로 있어야 하는 Classification외에 l1, GIoU를 없애고 다 사용하는 것에 대해 ablation study를 진행한 것입니다. 이 또한 실제 논문에서 보았던 l1, GIoU를 다 사용하는게 AP 성능이 가장 좋았다고 합니다.
Analysis
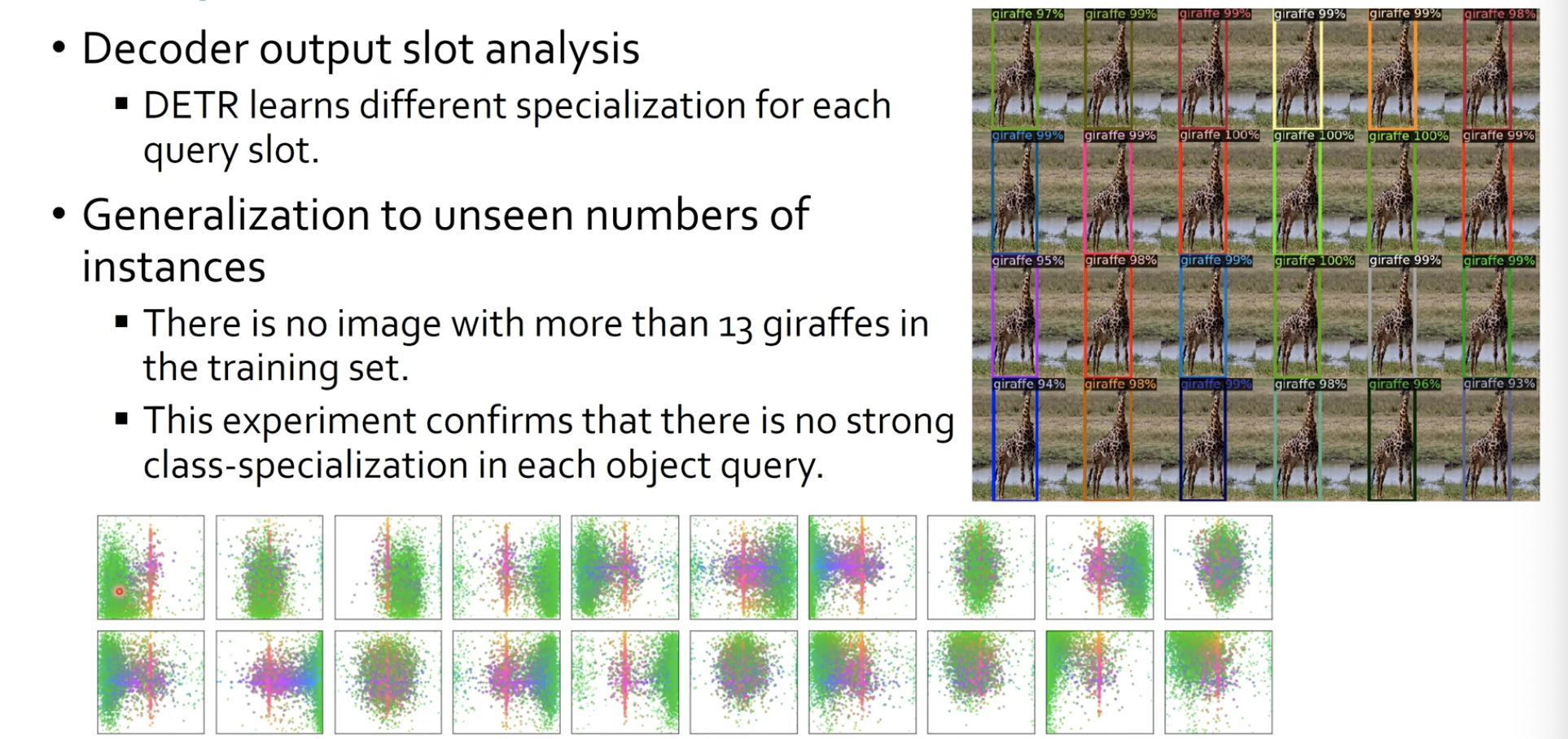
Decoder의 object queries의 output을 봤을 떄 그 물체에 대한 중심이 어디에 찍히는지를 봤는데, 다양하게 나오더라 라는 결과입니다.
그리고 오른쪽 그림은, 기린 사진을 여러개를 붙혔는데도 이를 잘 찾더라 라는 것입니다. 즉 DETR은 out of distribution에 대한 것도 잘 찾더라 라는 것을 알 수 있습니다.
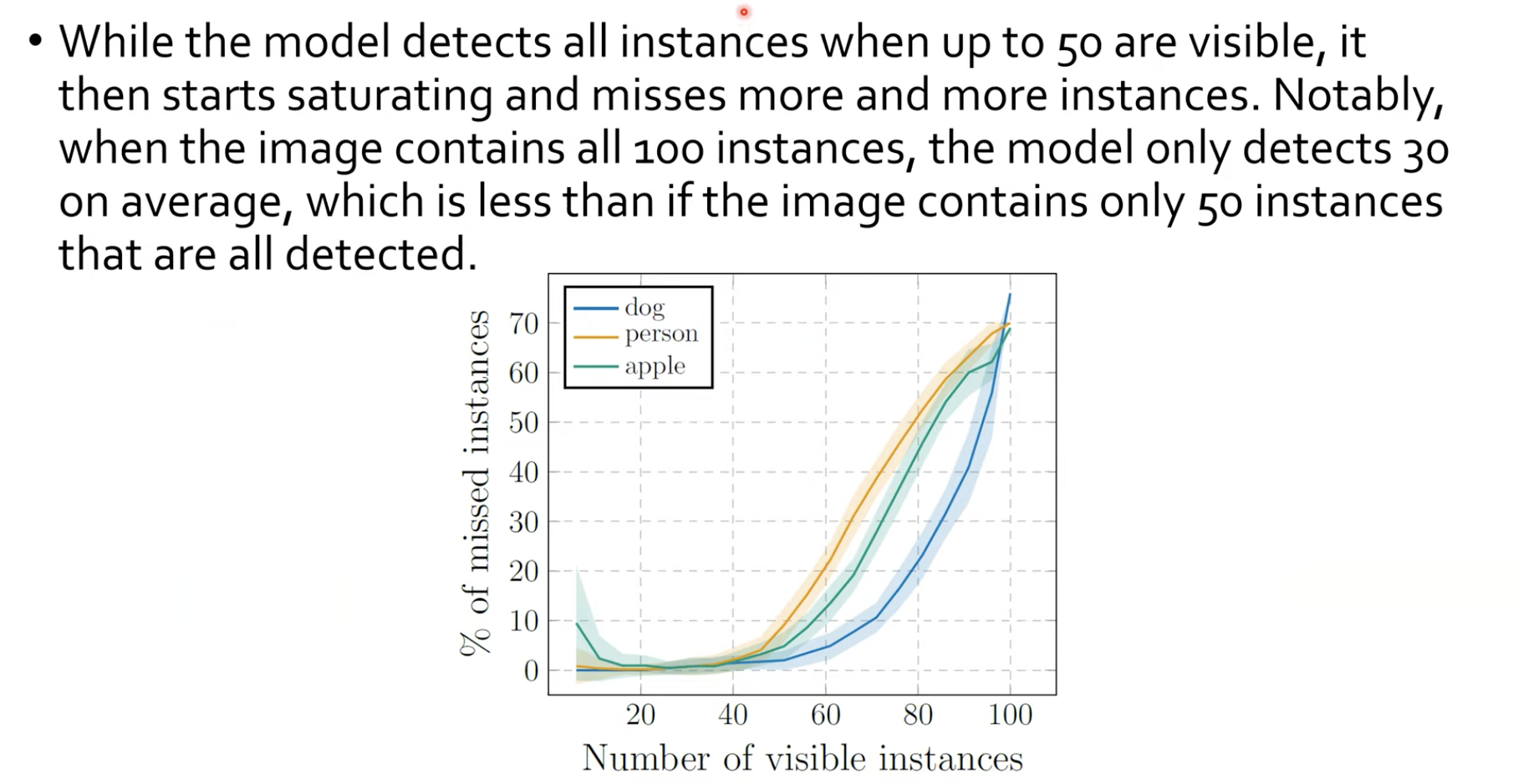
100개까지 인스턴스를 높여보았을 때의 실험 결과입니다. 여기에서 100개로 늘렸더니 70개 정도가 missing되었음을 보이고 있습니다. 즉 30개정도까지만 찾을 수 있다는 것입니다. 근데 50개까지 갔을 때에는 2개정도를 missing한다는데, 이는 dataset에 어느정도의 overfitting이 있다는 것을 알 수 있습니다.
DETR for Panoptic Segmentation

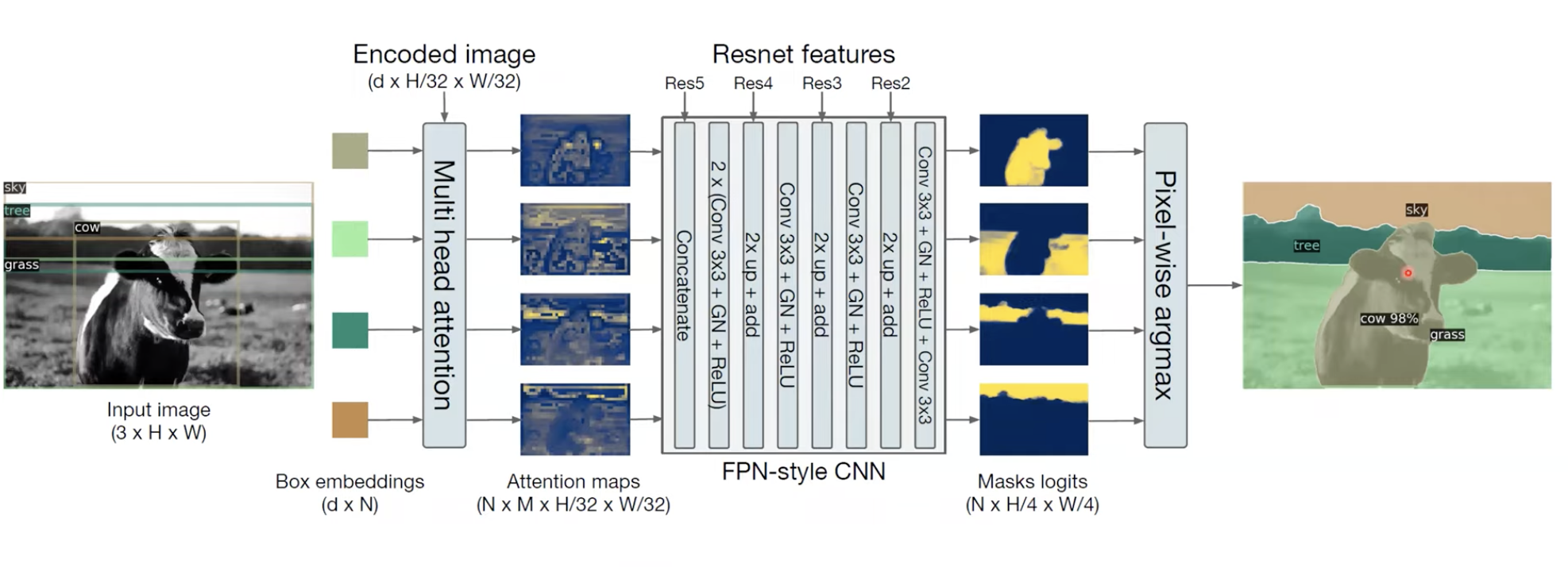
기존의 Faster R-CNN에 Mask를 추가해서 Instance Segmentation 문제를 해결한 것처럼. DETR에 FPN 구조의 CNN를 활용해서 Panoptic Segmentation문제를 해결해보았다고 합니다.
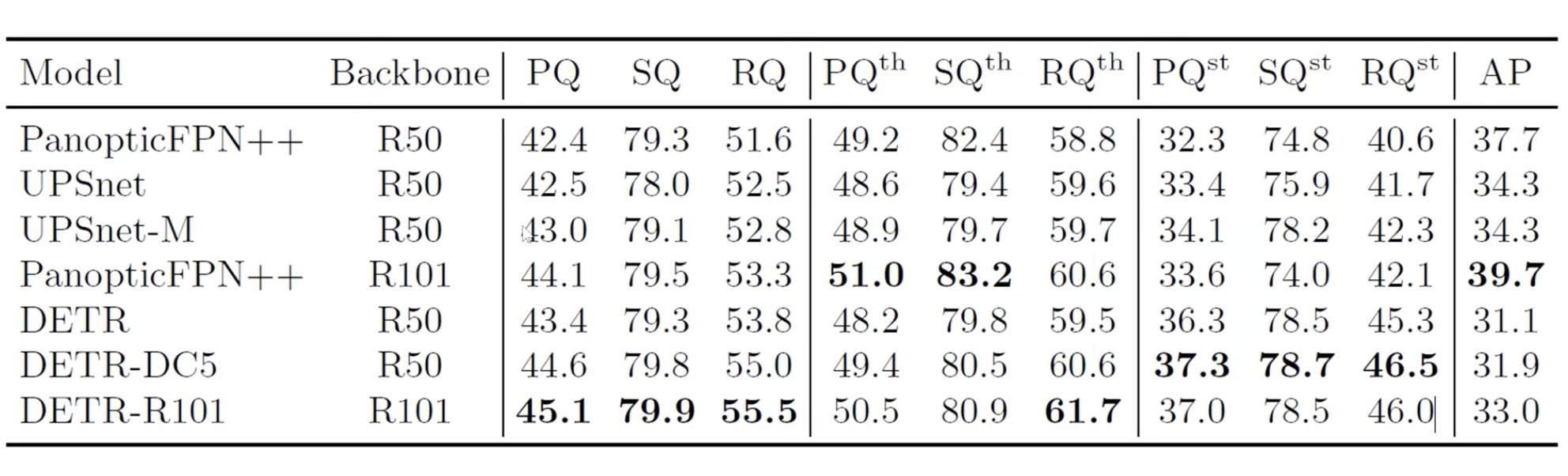
실제로 Segmentation 결과도 매우 잘 나오는 것을 볼 수 있습니다.
Reference
https://www.youtube.com/watch?v=lXpBcW_I54U