[ 딥러닝 논문 리뷰 - PRMI Lab ] - seq2seq, Attention, teacher forcing
English and Korean has different word order
"I love you" 라는 언어를 한국어로 번역하는 가장 간단한 방법은 "Nan saranghey nul" 이렇게 바꾸는 것입니다. 이는 Input과 Prediction을 그냥 순서대로 1:1 매칭시켜주면 되는 것이겠죠. 하지만 "난(Nan) 사랑해(saranghey) 널(nul)"은 뭔가 좀 이상합니다. SVO순서를 SOV를 아래와같이 바꿔줘야 할거 같습니다.

output always have same word count with input, while it should not

또한 위와같이, "How are you"를 번역하면 "Jal jiney?"로 바뀌어질 수 있는데, 단어의 카운트가 다릅니다. 즉 단어별로의 번역은 그닥 좋은 방법은 아니라고 할 수 있겠습니다.
Let's use RNN (= seq2seq)

그럼 이제 RNN을 활용해보겠습니다. 위와같이 늘 하던대로 input으로 "I love you"를 넣어주고 이를 통해 Context vector를 만들어 주겠습니다. 그 후 <start> 시그널에서 부터 시작하여 <end>가 나올때 까지 번역해 내면, 위의 이슈들을 해결할 수 있습니다. 이러한 모델을 encoder, decoder 모델이라고도 하고 seq2seq 모델이라고도 합니다.
encoder가 주로 하는 일은, 문자열을 순차적으로 받아들여서 Context vector(문맥 벡터)를 만들어 내는 데에 있습니다. decoder가 하는 일은 이 문맥 벡터로부터 기계번역을 <start> ~ <end>부터 시작하는 것입니다.
하지만 이 방법에도 문제가 없지만은 않았습니다. 아래 그림을 보시죠.

문맥 벡터는 고정된 벡터입니다. 하지만 문장이 많은 수의 단어로 이루어지면, 이 문맥 벡터에 모든 의미를 함축할 수 없다는 문제점이 생겨서 의미를 다 함축할 수 없게됩니다. 그래서 충분하지 않은 번역이 이루어질 수 있다고 seq2seq를 소개한 Research Paper에서 소개하고 있습니다. 이러한 문제점을 해결하기 위한 방법이 Attention 입니다!
Attention

Attention 모델에서는 기존에는 마지막에 생성된 output만을 decoder에 input으로 넣어주었다면, Attention모델은 중간에 생성된 모든 prediction을 decoder에 넣어줍니다. 즉 RNN의 모든 cell의 값들을 decoder에 투입해서 dynamic context vector를 만들자는 아이디어에 핵심이 있습니다. 핵심은 아래와 같습니다.
- single context vector -> dynamic context vector로 변환함에 따라 핵심적인 의미들을 다 함축할 수 있게 됩니다.
- RNN cell에서의 핵심 내용만을 선택해서 중요한 정보를 골라서 이들을 중심으로 학습할 수 있다는 것입니다.
seq2seq + Attention Model

먼저 Attention 메커니즘은 각 RNN cell의 출력값에 대한 'score'를 먼저 계산합니다. 이 score는 현재 시점의 Query(질의)와 RNN cell의 Key(키) 사이의 관계를 나타내며, 이를 계산하는 방식은 다양합니다. 이를 내적(dot product)할 수도 있고, fully-connected layer에 넣은 후 합산하는 방식, 복잡한 신경망을 사용하는 방식등이 있습니다.
계산된 score에 softmax 함수를 적용합니다. 이렇게 만들어진 score를 'Attention weight'라고 합니다. Softmax를 적용함으로써, 우리는 특정 RNN cell의 출력값에 더 많은 '주목'을 기울일 수 있게 됩니다.
마지막으로, 다음 그림에 나오겠지만 각 RNN cell의 출력값을 해당 Attention weight로 가중 평균하여 'context vector'를 생성합니다. 이 context vector는 Attention 매커니즘을 거친 후의 출력값으로, 이후의 처리 단계인 decoder로 들어가게 됩니다.
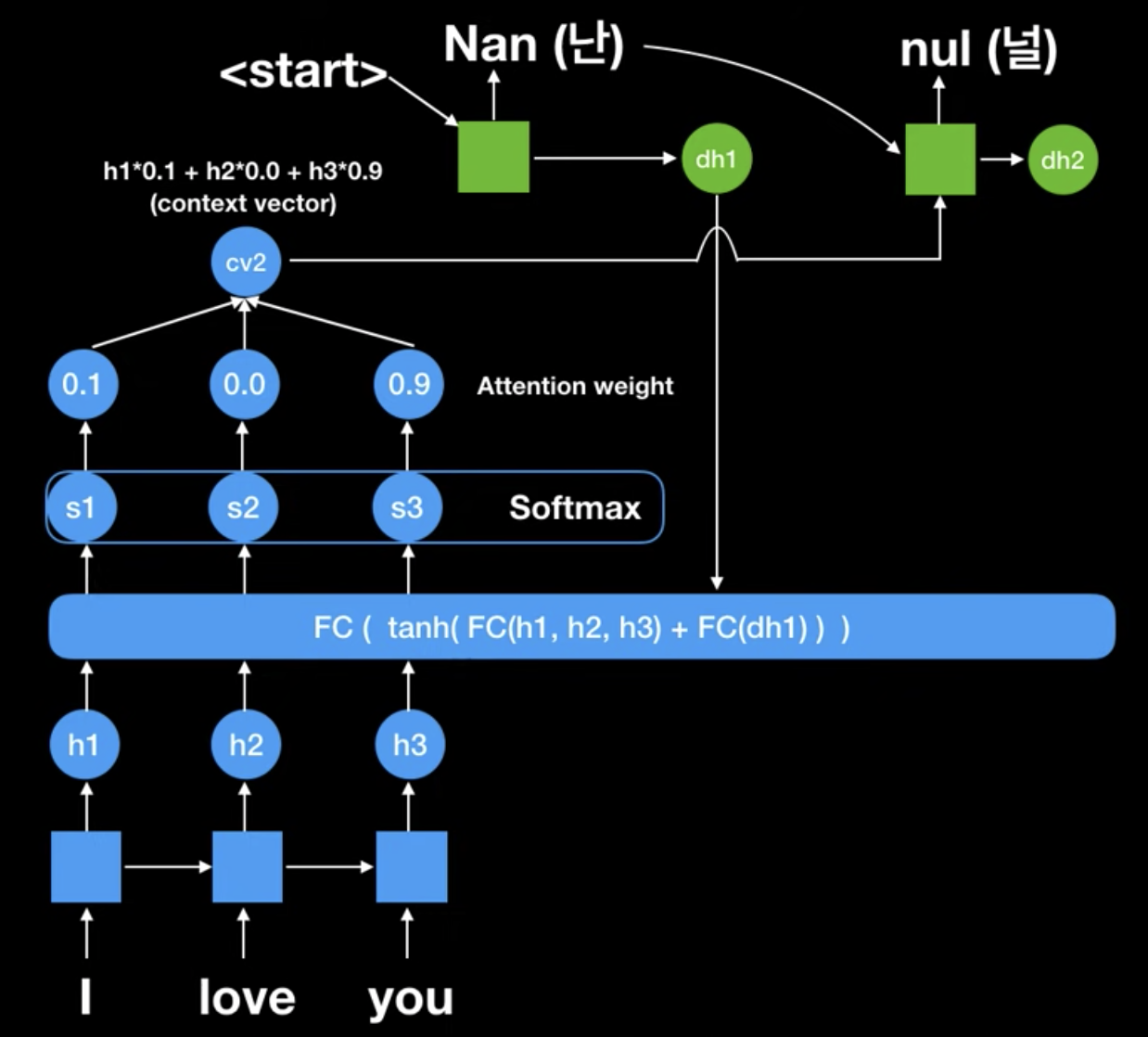
그리고 Attention 메커니즘이 적용된 context vector에 <start>를 붙혀서 decoder에 넣습니다. 그리고 첫번째 output인 "Nan"을 만들어 냅니다. 그리고 이게 다시 이전 encoder의 FC에 적용됩니다. 그 이유는 이전에서도 말했지만, 어떤 문장에 집중(Attention) 해야할지를 알려주어서 결국 Attention weight를 갱신해주기 위함입니다. 이전과 다르게 "you"에 0.9 focus가 적용된 것을 볼 수 있습니다.
이처럼 과거에 1개의 context vervtor를 사용한 seq2seq 모델보다, dynamic하게 context vector 사용한 seq2seq + attention 메커니즘이 좀 더 방대한 양의 information을 함축하는데 있어서 유리하다라고 Reserach paper에서 말하고 있습니다.
그 후, 생성된 context vector가 2번째 RNN cell에 들어갑니다(decoder). 그리고 이전에 생성된 "Nan"이라는 값과 함께 input으로 들어와서 결과적으로 "nul"이라는 값이 나온 것을 볼 수 있습니다.
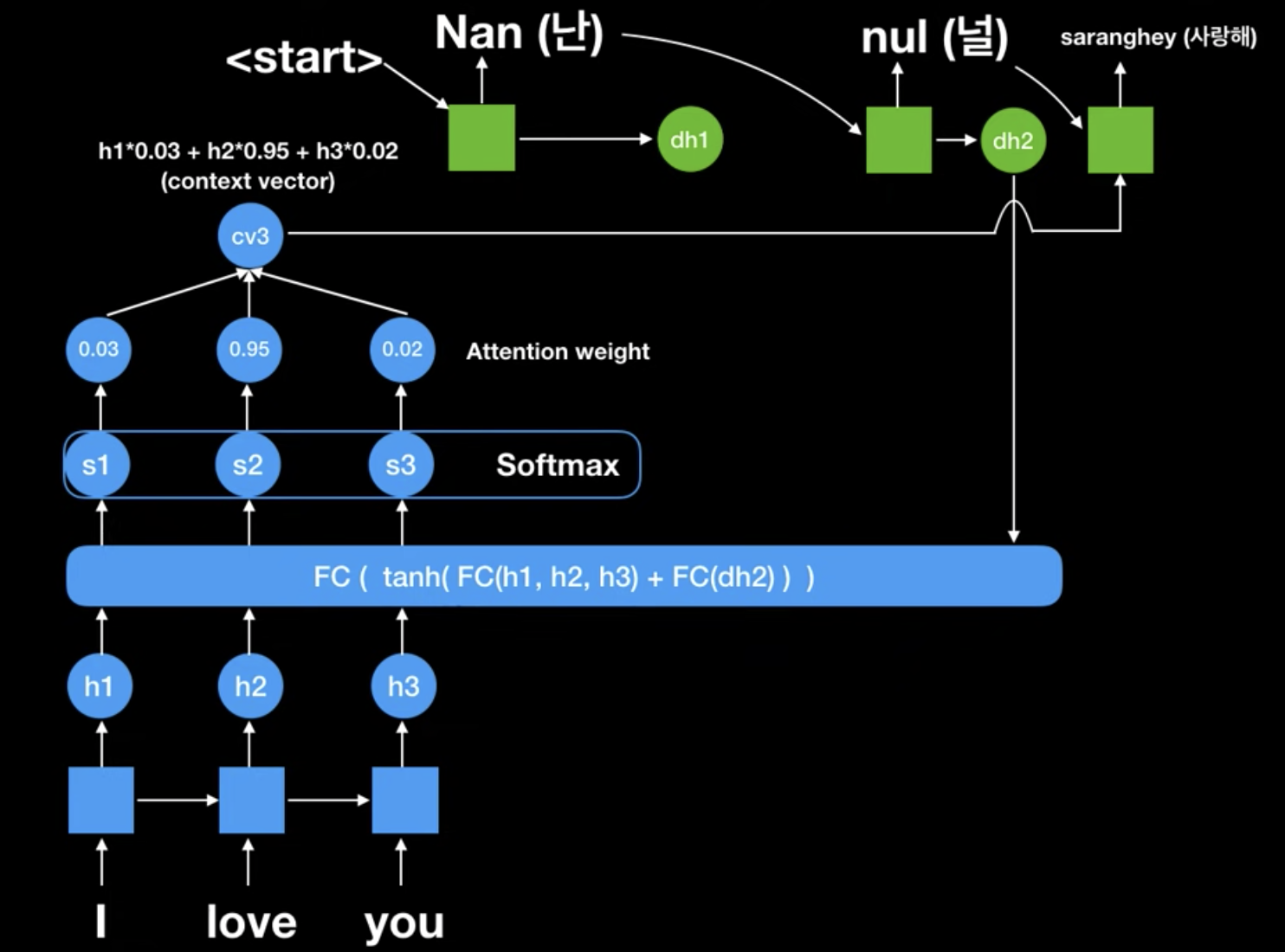
그리고 최종적으로 위와같이 "saranghey"가 3번째 decoder RNN cell에 투입되어서 나온것을 볼 수 있습니다. FC의 input으로 "I love you"는 계속 투입되는데, 이 중에 어떠한 값이 Attention해야하는지를 encoder가 판단해야하기 때문입니다.
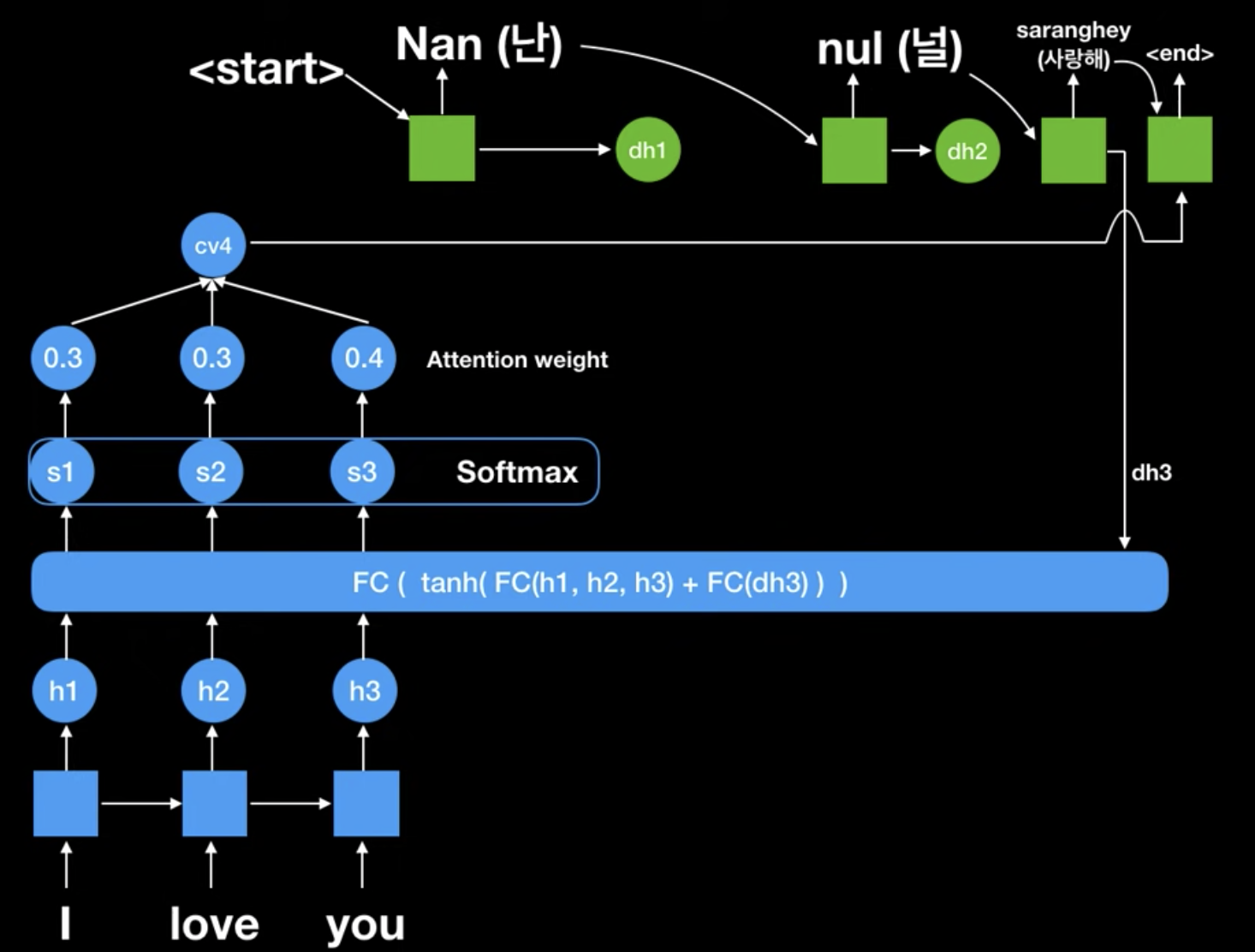
최종적으로 <end> 시그널이 나와 "Nan nul saranghey"로 번역된 것을 볼 수 있습니다.
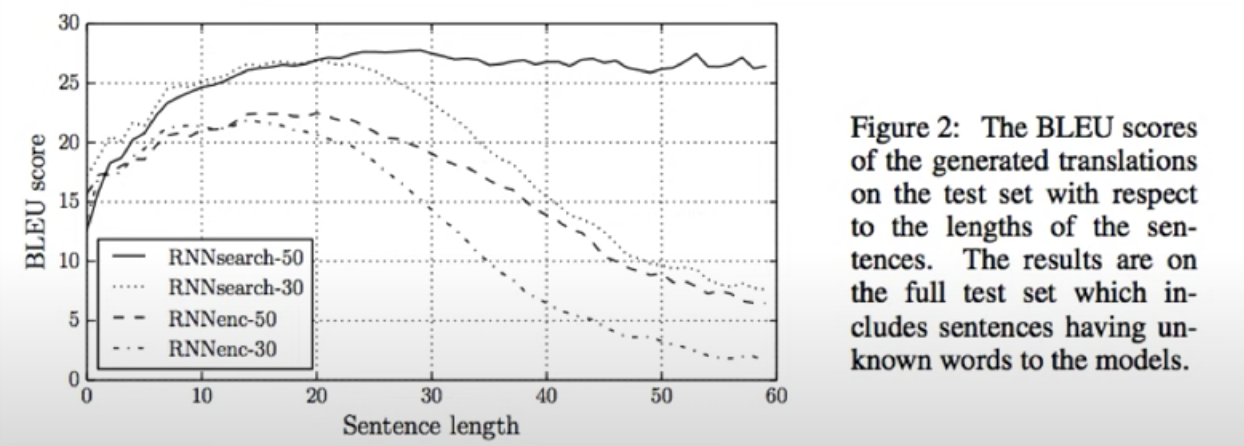
실제 실험 결과도 RNNsearch-50, RNNenc-50만을 비교했을 때, attention 메커니즘을 seq2seq에 적용한 전자 모델이 Sentence length에 상관없이 기존의 모델보다 훨씬 뛰어난 성능을 유지할 수 있음을 볼 수 있습니다.
Teacher Forcing
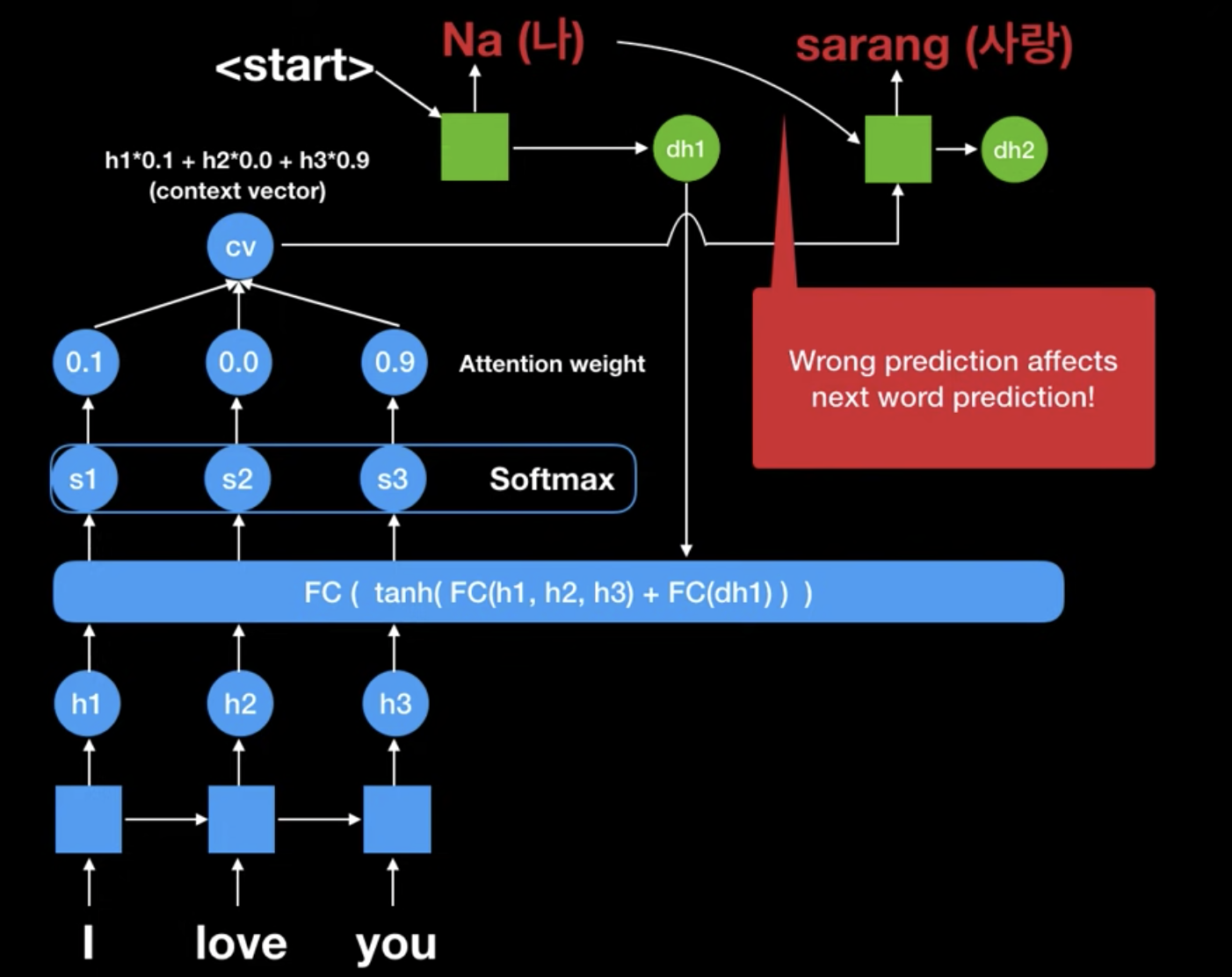
그리고 추가적으로, teacher forcing에 대해 보겠습니다. 만약 처음부터 "Nan"을 "Na"로 잘못 예측했다고 해봅시다. 그리고 이 잘못 예측된 "Na"라는 벡터가 encoder의 FC에 투입되서 잘못된 Attention weight를 만들어 냅니다. 그럼 그 뒤로 번역된 값을 다 잘못되겠죠.
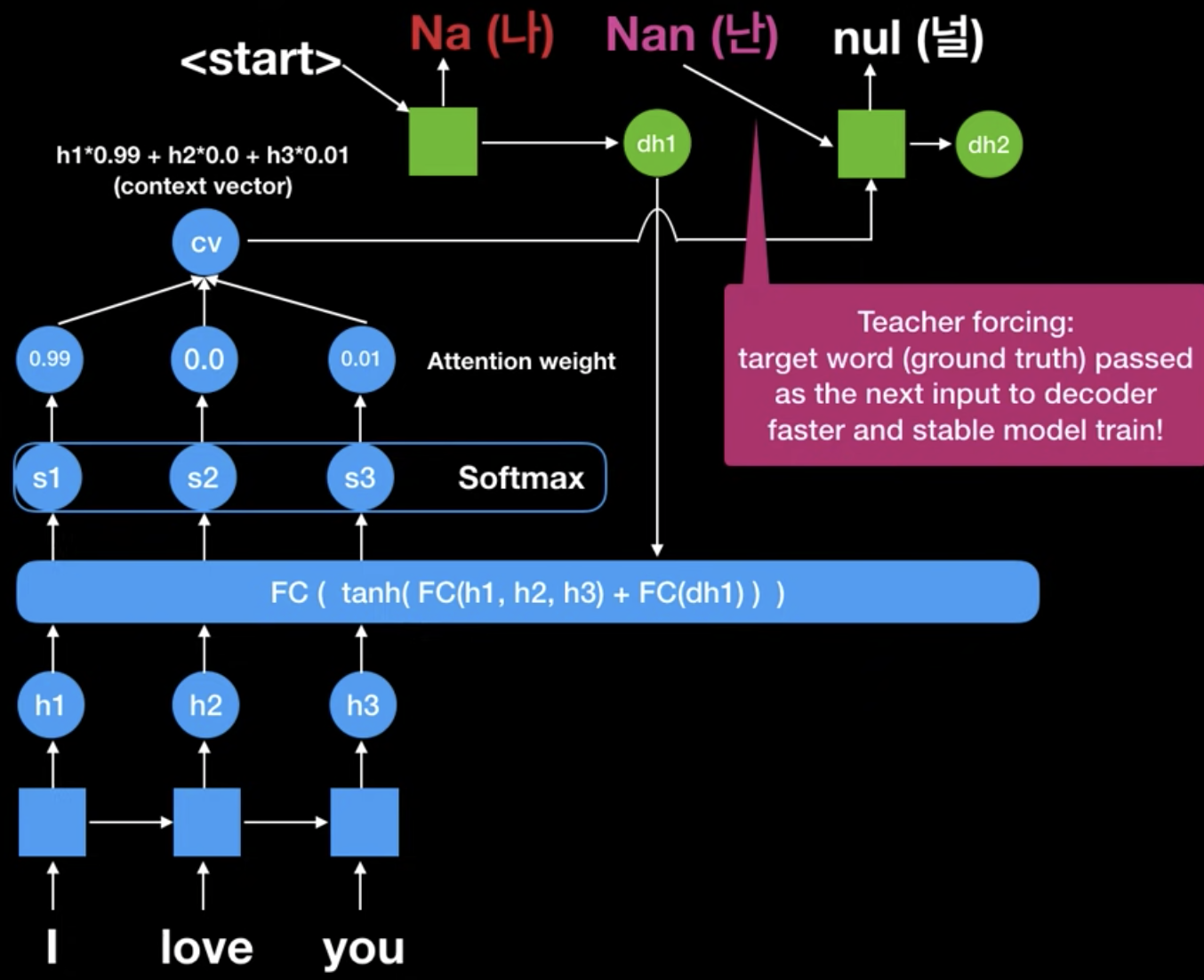
그럼 학습하는 의미가 없어지므로, 이럴 때에는 아래와 같이, 정답인 "Nan"을 넣어주어서 학습을 더 안정적이고 효율적으로 학습하게 합니다.
https://www.youtube.com/watch?v=WsQLdu2JMgI
해당 유튜브를 참조했습니다.