[ 논문리뷰 - PRMI Lab ] - RNN, LSTM
오늘은 경북대학교 PRMI Lab 2023 - summer project를 수행하기 위해, DeTR이라는 논문을 읽고 직접 구현해보기 위해, 사전적으로 읽어야 하는 개념들에 대해 간단히 정리해보겠습니다. 이들은 엄청 오래전에 소개된 논문에서 나온 개념이고 대부분의 SOTA모델들은 DeTR이나 BERT, GPT등의 encoder, decoder 기반이라고 합니다. 하지만 RNN, LSTM, Attention등의 개념이 발전되어서 해당 모델들이 등장하게 된 것이므로, 알아두어야 겠다고 생각해서 한번 정리해보겠습니다.
Sequence is important for POS tagging
우리에게 "I work at google", "I google at work" 이라는 단어가 있다고 해 봅시다. 여기에서의 의미는 전자는 "나는 구글에서 일한다", "나는 구글링을 일할때 한다"로 여기서의 work, google의 품사 (POS)가 각기 다릅니다. 그래서 RNN에서는 이러한 Sequence의 POS tagging이 중요합니다.

이와 같이, 각각의 품사를 라벨링하고 RNN에 학습시킵니다. 그리고 각각의 히든레이어에 대한 출력이 하나는 품사에 대한 예측이고, 하나는 다른 히든 레이어로의 입력이 되겠죠?? 이제 가장 기본적인 Vanila RNN의 구조에 대해 보겠습니다.
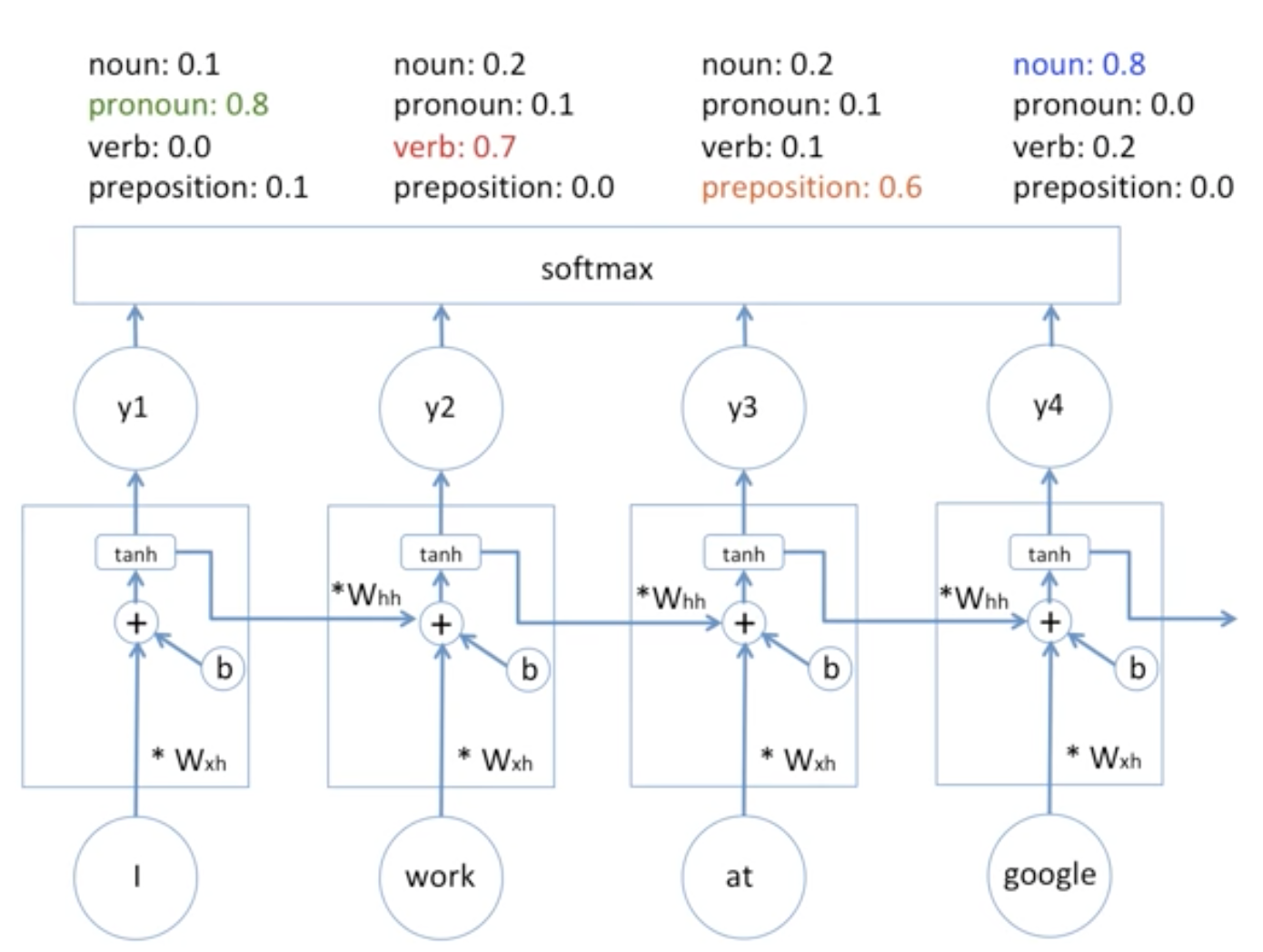
위와같이 softmax의 출력값을 토대로 품사를 판단하게 되고, 다음 히든레이어에 투입합니다. 참고로 여기서의 Weight, bias 값은 다 같습니다. 또한 여느 인공신경망 처럼 실제 Target 즉 GT(Groud truth)값을 토대로 GD(Gradient Descent)를 토대로 모델을 학습해 나갑니다.
Sentiment Analysis

위와같이 최종 출력값을 통해 Sentiment를 분석해 볼 수도 있습니다. 그리고 이를 바탕으로 softmax -> pred -> target을 통해 학습을 할 수 있겠죠?

그리고 여기서의 back propagation through time (btpp)란 가중치를 다 공유하고 시간에 따라 이를 갱신해 나간다고 해서 bptt라고 하는데, 이를 통해서 모델을 갱신해 나갑니다.

위와같이 RNN의 모델을 간소화 할 수도 있습니다.
가중치를 공유하는 이유
RNN에서 가중치와 편향 값을 공유하는 것은 RNN의 핵심 특징 중 하나입니다. 이렇게 가중치와 편향 값 공유의 이유는 주로 아래와 같습니다.
- 파라미터의 효율적인 사용: 가중치와 편향 값을 시간 스텝마다 공유함으로써, 모델의 파라미터 수를 크게 줄일 수 있습니다. 이는 모델이 더 효율적으로 학습되며, 과적합을 방지하는데 도움이 됩니다.
- 시퀀스의 길이에 독립적인 학습: RNN은 가변 길이의 입력 시퀀스를 처리할 수 있습니다. 가중치와 편향 값을 공유함으로써, 모델은 시퀀스의 길이와 관계없이 동일한 업데이트를 적용할 수 있습니다. 이는 다양한 길이의 시퀀스를 처리하는 데에 매우 유용합니다.
- 일반화 능력 향상: 가중치와 편향을 공유함으로써, RNN은 시간 스텝마다 동일한 작업을 수행합니다. 이는 다양한 위치에서 등장하는 패턴을 공통적으로 인식하도록 학습될 수 있으므로, 모델의 일반화 능력을 향상시킵니다.
- 예를 들어 "나는 학교에 간다", "그녀는 집에 간다"에서 "간다"가 사용되는 문맥은 서로 다르지만, 그 의미와 역할은 유사합니다. RNN에서는 이 가중치를 공유함으로써 "간다"가 어떤 주체에 의해 실행되는 패턴을 학습하고, 다양한 문맥에서 일반화 할 수 있습니다.
LSTM
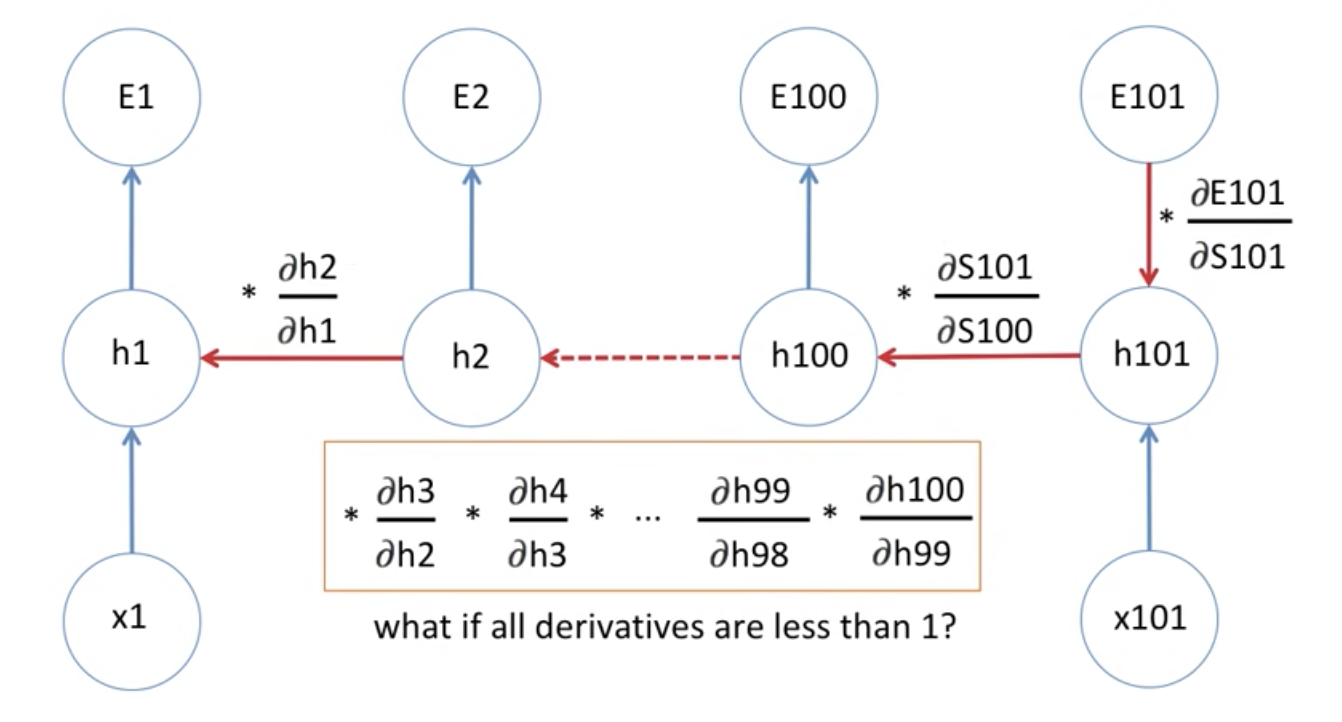
기존에 RNN에서 bptt를 할 때, Chain rule을 적용하다보면 당연히 Gradient Vanishing 문제가 발생합니다. 그 외에도 미분값이 1보다 크다면 Gradient Exploding 문제가 발생할 수 있습니다.
이처럼 RNN은 장기간에 걸친 의존성을 학습할 수 있는 구조를 가지고 있지만, 이와같은 문제점이 있어 학습하는 데 어려움이 있습니다. 그래서 LSTM(Long Short-Term Memory)는 이런 문제를 해결하기 위해 제안된 구조입니다. LSTM은 '입력 게이트', '망각 게이트', '출력 게이트'등으로, 네트워크가 기억할 정보와 잊을 정보를 학습적으로 선택할 수 있게 해줍니다. 이를 통해 LSTM은 장기 의존성을 더 잘 학습하고, 그래디언트 소실 문제를 크게 완화시킬 수 있게 됩니다.
LSTM: Introducing (memory cell) in RNN
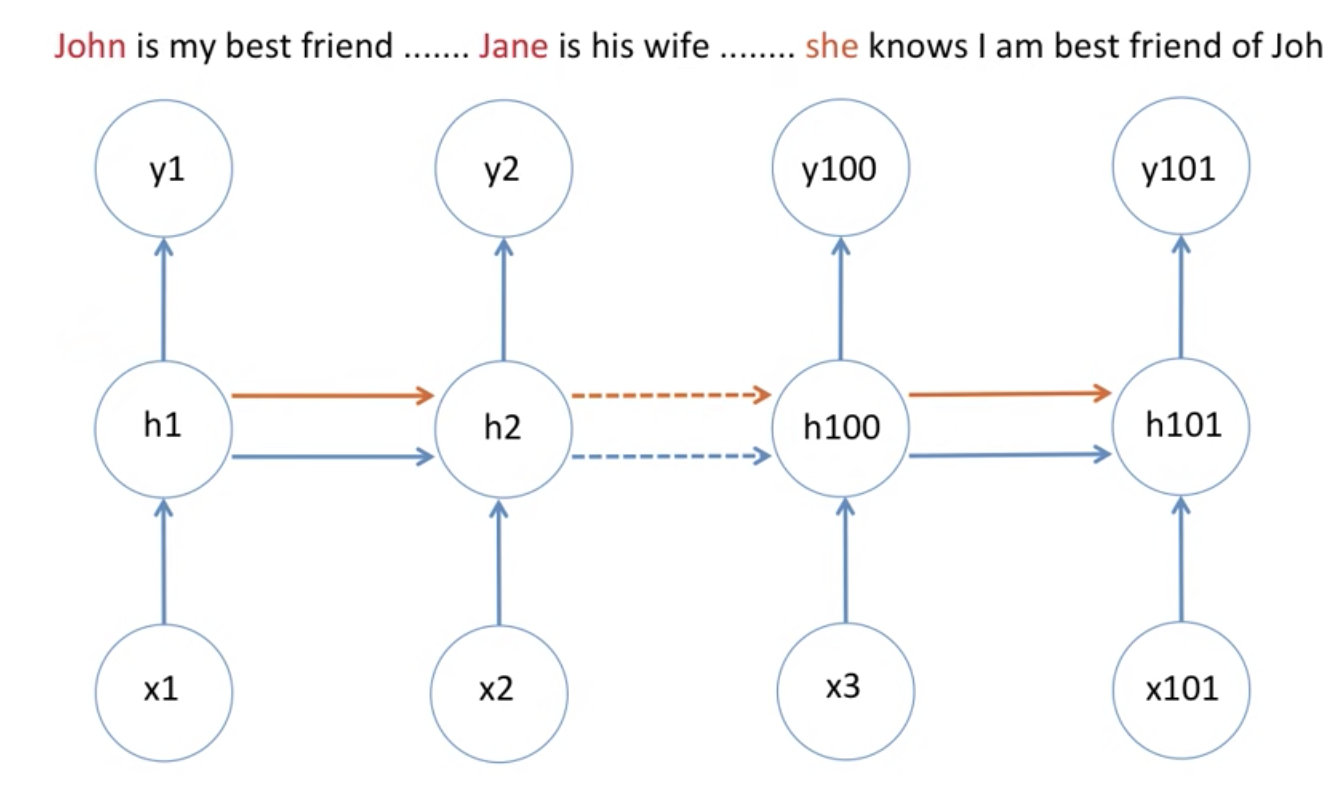
위와같은 상황에서는 John보다는 Jane에 더 집중을 해야합니다. 이를 위해서 LSTM memory cell이라는 걸 사용합니다.
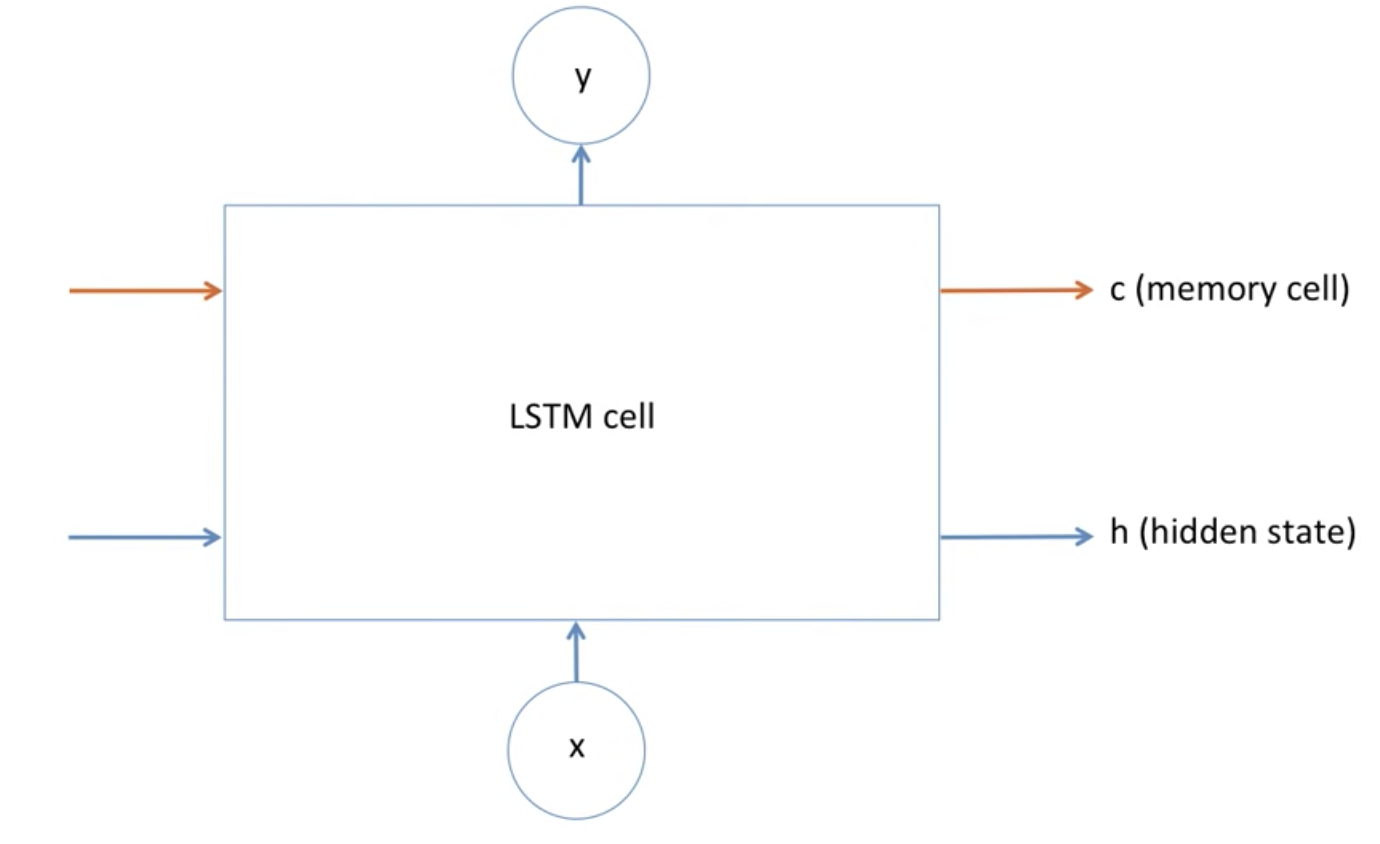
LSTM은 위와같은 딥러닝 모델이고, 딥러닝 모델은 수학적 모델이므로, 어떠한 정보를 잊고, 기억하는게 어떻게 보면 다 수학적 공식이라고 할 수 있습니다.
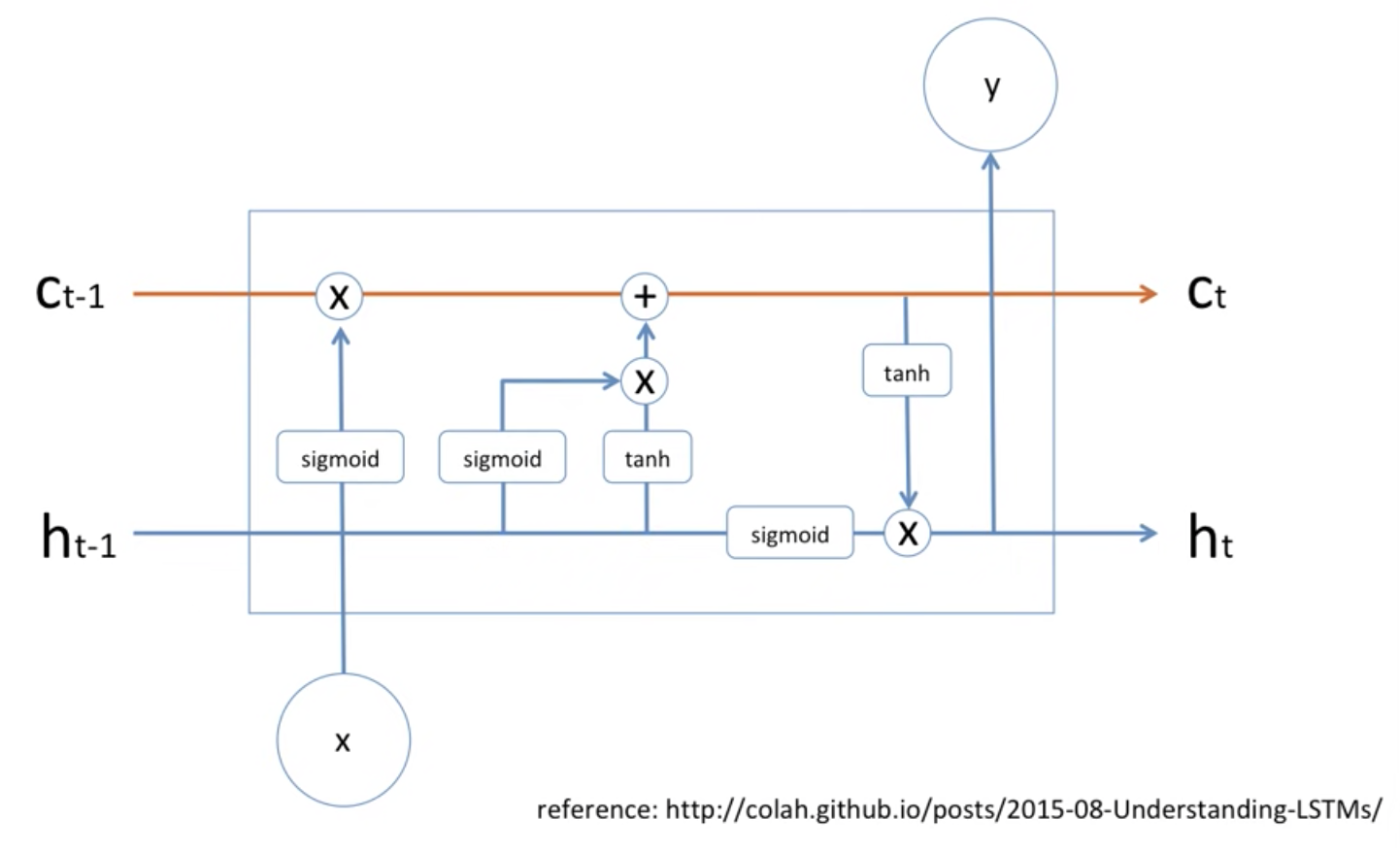
$C_{t-1}$은 위의 예시에서 "John is ..."이라고 할 수 있습니다. John에 대한 이야기입니다. 그리고 x에 "Jane"이라는 정보가 들어왔을 때, $h_{t-1}$ 이전의 정보가 sigmoid와 곱해져서 곱해집니다. sigmoid는 어떠한 확률값으로 나타내질 수 있으므로, 이를 수학적으로 생각해보면 얼마나 기억해야할지?로 생각해 볼 수 있습니다.
그리고 쭉쭉 $h_{t-1}$을 sigmoid, tanh를 적용한 값을 곱하고 $C_{t-1}$과 더하고, 마지막도 $h_{t-1}$을 sigmoid를 적용한 값에 $C_{t-1}$을 적용한 값을 곱해서 $C_{t}$, $h_{t}$이라는 값으로 내보냅니다. 이가 가장 기본적인 LSTM cell입니다. 참고로 sigmoid, tanh 각각은 다 당연히 Weight, bias값이 다 있겠죠?? 이를 bptt마다 목적함수를 갱신해 나가는 겁니다.