[ 딥러닝 논문 리뷰 - PRMI Lab ] - Mask R-CNN (ICC, 2017)
Mask R-CNN은 기존 object detection task에서 사용되던 Faster R-CNN에 Mask branch를 추가해서 classification, bbox regression, predicting object mask를 동시에 처리하는 모델입니다.
FPN ( Feature Pyramid Network)
FPN은 Mask R-CNN에서 어떻게 쓰이는지에 관련해서 간단히 살펴보겠습니다. faster rcnn과는 다르게 여러개의 feature map이 생성되고, 각각의 feature map에 맞는 RoI가 생성되는 것을 아래 그림에서 확인할 수 있습니다.

이는 기본적으로 Bottom-up pathway, Top-down Pathway, Lateral connections를 통해 다양한 크기의 피처를 합쳐서 일반화 성능을 높이는 방법입니다. 즉, 이는 multi-scale feature map을 출력하기 떄문에 단일 feature map보다 더 높은 detection 성능을 보여줍니다.
Detection task 시 고해상도 feature map은 low-level feature를 가지지만 객체의 위치에 대한 정보를 상대적으로 정확하게 보존하고 있습니다. 이는 저해상도 feature map에 비해 downsampling된 수가 적기 떄문이라고 말 할 수 있죠. 이러한 고해상도 feature map의 특징을 element-wise addition을 통해 저해상도 featuremap에 전달하기 때문에 Pyramidal feature hierarachy보다 더 높은 detection 성능을 내게 됩니다.
Instance Segmentation, Mask R-CNN

Mask R-CNN도 일종의 Instance Segmentation기법중에 하나이데요, 이는 BBox Classification과 Segmentation Classification을 합치면 Segmentation in BBox Classification이 가능하겠네! 라는 의식에 흐름에서 시작됩니다.
즉 Faster R-CNN(Cannot Segment) + FCN(Can Segment, Cannot Classification) = FCN on BBOX 인 셈이죠
저자인 Kaiming He도 Mask R-CNN이 별게 아니라 그냥 Faster R-CNN에서 RoIs에 FCN을 돌린것이라고 소개하고 있습니다. 그리고 여태까지 말한게 다입니다.
Introduction
기존 Faster R-CNN에 각각의 RoI에 대해 segmentation mask를 예측하는 mask branch를 추가한 구조라고 할 수 있습니다.
classification, bounding box regression, segmentation mask 총 이렇게 3가지의 branch로 이루어져 있으며, 3가지 task를 동시에 수행합니다. Mask branch는 작은 크기의 FCN으로 pixel-to-pixel 방식으로 픽셀별로 K개의 클래스 각각에 대해 물체가 있는지 없는지를 판단하는 segmentation mask를 예측합니다.
세그멘테이션 마스크(segmentation mask)는 이미지에서 객체가 차지하는 영역을 표현하는 데 사용되는 방법입니다. 이는 이미지의 크기와 동일한 행렬로, 각 픽셀이 어떤 클래스에 속하는지를 표현합니다.
인스턴스 세그멘테이션(Instance segmentation)에서는 각 인스턴스마다 고유한 라벨을 마스크에 부여하여 경계를 그립니다.
또한 기존 fast rcnn의 RoI pooling을 RoI Align layer로 대체해 물체의 Spatial location 즉, 위치 정보를 보존했습니다. (RoI pooling은 위치 정보를 어느정도 보존하지만, 그 보존력이 절대적이지는 않습니다, 그리고 무엇보다도 pooling 창 내에서의 픽셀 위치는 보존되지 않습니다.)
이전 모델들과는 다르게 class 예측과 segmentation mask가 독립적으로 일어나 더 좋은 결과를 가져왔다 합니다. 논문에서는 이를 "decouple"이라고 표현합니다.
결과적으로 학습이 쉽고, faster rcnn에 branch를 하나 더 추가하긴 했지만, 연산량이 크게 많아지지는 않았다고 합니다. 속도 역시 5fps로 빨라졌으며, COCO instance segmentation, bbox object detection, person keypoint detection 등의 COCO suite of challenges에서 모두 top result를 보여주었습니다.
그래서 Mask R-CNN의 Faster R-CNN과의 차이점은 아래 3가지로 분류할 수 있습니다.
- FPN 사용: RoI를 생성하는 RPN에 FPN추가
- RoI pooling을 RoI align으로 대체
- Mask branch 추가
Mask branch
Mask R-CNN은 Fast R-CNN처럼 2단계로 이루어져 있습니다.
1) RPN을 통해 RoI를 얻습니다.
2) RoI, Feature map을 통해 classification, bbox regression, segmentation mask를 동시에 합니다.
그렇기 때문에 loss 함수로 $L_{cls} + L_{box} + L_{mask}$라는 multi loss를 가지게 됩니다.
Mask branch에서는 각각의 RoI에 대해 각각의 클래스 k에 대해 binary mask를 계산합니다. Binary mask란 아래와 같이 특정 클래스 k에 대해서 instance가 있다고 생각되면 1, 없다고 생각되면 0으로 나타내는걸 의미합니다.

기존 모델들의 경우 mask와 class prediction을 동시에 수행했습니다. 하나의 픽셀에 대해 softmax를 취해 각각의 클래스들의 확률을 계산하고 multinomial cross entropy loss를 이용해 학습합니다. $pixel_{1, 1}$에 대해 클래스 4개라면 [0.1, 0.2, 0.4, 0.4]와 같이 확률을 계산해 그 중 가장 큰 값을 class로 사용하게 되는겁니다.
mask branch에서는 이전 모델들과는 다르게 mask와 class prediction을 분리했습니다(decoupling). mask에서는 하나의 픽셀에 대해 각각 클래스 별로 해당 클래스의 instance가 존재하는지 안하는지를 sigmoid를 통해 binary로 계산합니다. $L_{mask}$는 binary cross entropy loss의 평균으로 정의됩니다. 만약 RoI의 ground truth가 k라면 k번째 마스크에 대해서만 $L_{mask}$가 정의됩니다.
그리고 논문에서는 두 branch를 결합하는 방식을 사용할 경우 성능이 매우 하락했다고 합니다. (decoupling 적용 X)

즉 segmentation task는 픽셀 단위로 class를 분류해야 하기 때문에 detection 보다 더 정교한 spatial layout을 필요로 합니다. 이를 위해 mask branch는 여러 개의 conv layer로 구성된 작은 FCN의 구조를 띄고 있습니다. class label이나 bbox offset이 fc layer에 의해 output vector로 붕괴되는 것과 달리 mask는 이미지 내 객체에 대한 공간 정보를 효과적으로 encode하는 것이 가능합니다.
즉 mask branch는 최종적으로 $m^{2}K$크기의 feature map을 출력합니다. 여기서 $m$은 feature map의 크기이며, $K$는 class의 수를 의미합니다. PASCAL VOC의 경우는 20. 이후 post-processing의 과정이 있지만 나중에 살펴보도록 하겠습니다.
Rol-Align
Rol pooling을 사용하면 입력 이미지 크기와 상관없이 고정된 크기의 feature map을 얻을 수 있다는 이점이 있습니다. 하지만 논문에서는 Rol pooling으로 인해 얻은 feature의 Rol 사이에 어긋나는 misalignment가 발생한다고 주장하고 있습니다. 이러한 어긋남은 pixel mask를 예측하는데 매우 안 좋은 영향을 끼친다고 합니다.
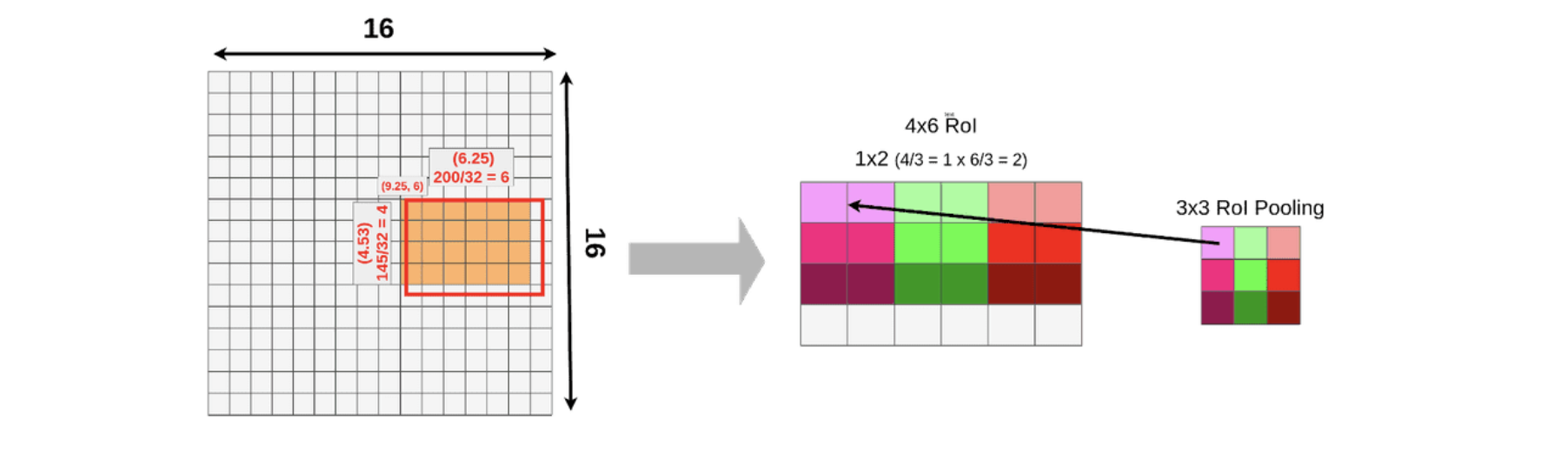
먼저 RoI pooling에 앞서 RPN을 통해 얻은 RoI를 backbone network에서 추출한 feature map의 크기에 맞게 투영(projection) 하는 과정이 있습니다. 위의 그림의 경우 RoI 크기는 145x200이며 feature map은 16x16입니다. 이를 sub sampling ratio(=32)에 맞게 나누어주면 projection을 수행한 feature map은 4.53(145/32)x6.25(200/32)크기를 가지게 됩니다. 하지만 픽셀 미만의 크기로 분할하는 것은 불가능하기때문에 크기에서 정수값을 사용하여 4(145//32)x6(200//32) 크기의 feature map을 얻습니다.
이후에 위의 그림에서는 3x3 크기의 고정된 feature map을 얻기 위해 4x6 크기의 RoI에 대하여 RoI pooling을 수행하게 됩니다. 이 과정에서 고정된 크기에 맞추기 위해 stride는 1x2로 설정됩니다. 최종적으로 3x3 크기의 feature map을 얻을 수 있습니다.
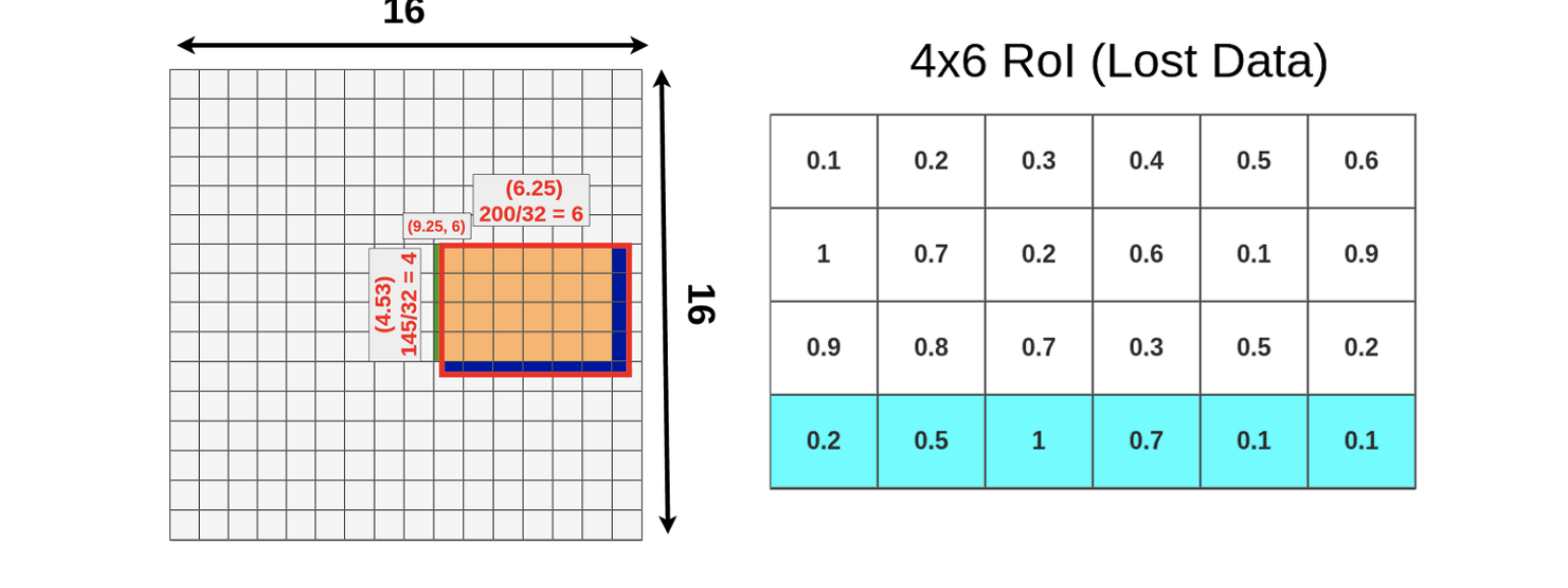
논문에서는 RoI pooling 방식이 quantization 과정을 수반하며 misalignment를 유도한다고 보았습니다. quantization은 실수(floating) 입력값을 정수와 같은 이산 수치(discrete value)으로 제한하는 방법입니다. 이로 인해 RoI projection을 수행하는 과정에서 소수점 부분이 반올림 되면서 아래 초록색과 파란색 영역에 대한 정보가 손실됨을 알 수 있습니다.
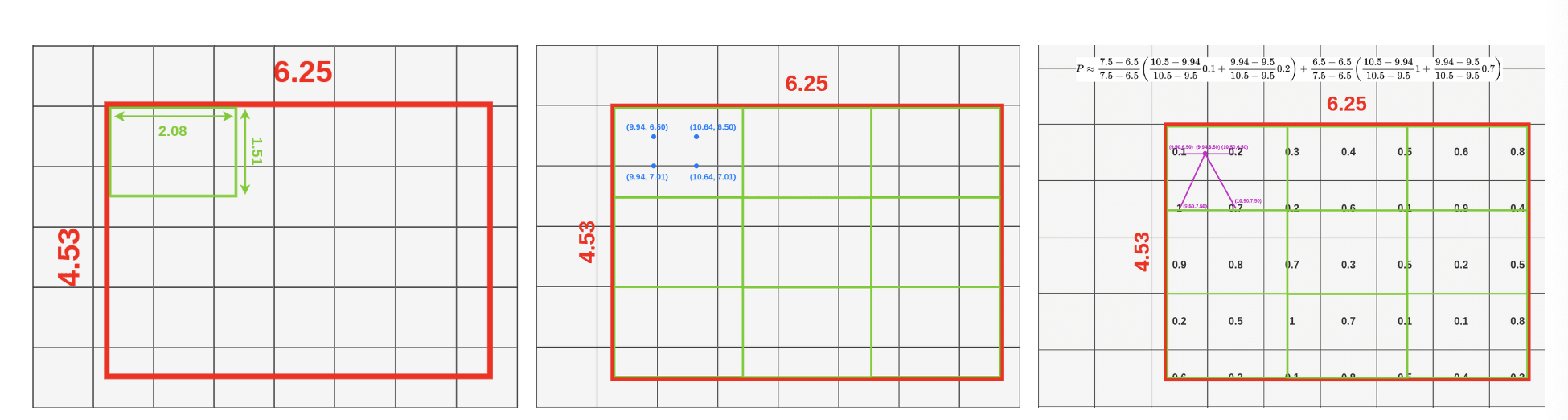
그럼 본격적으로 RoI pooling 방식에 대해 보겠습니다. 먼저 bin=2로 잡아 RoI를 2x2로 나눠줍니다.
각각의 Bin에 대해 sample point 4개씩을 잡습니다. 여기서는 bin=2로 잡았으니 sample point는 16개가 됩니다. 그리고 sample 하나를 기준으로 가까운 그리드 셀 4개에 대해서 bilinear interpolation 식을 따라 계산하게 됩니다.
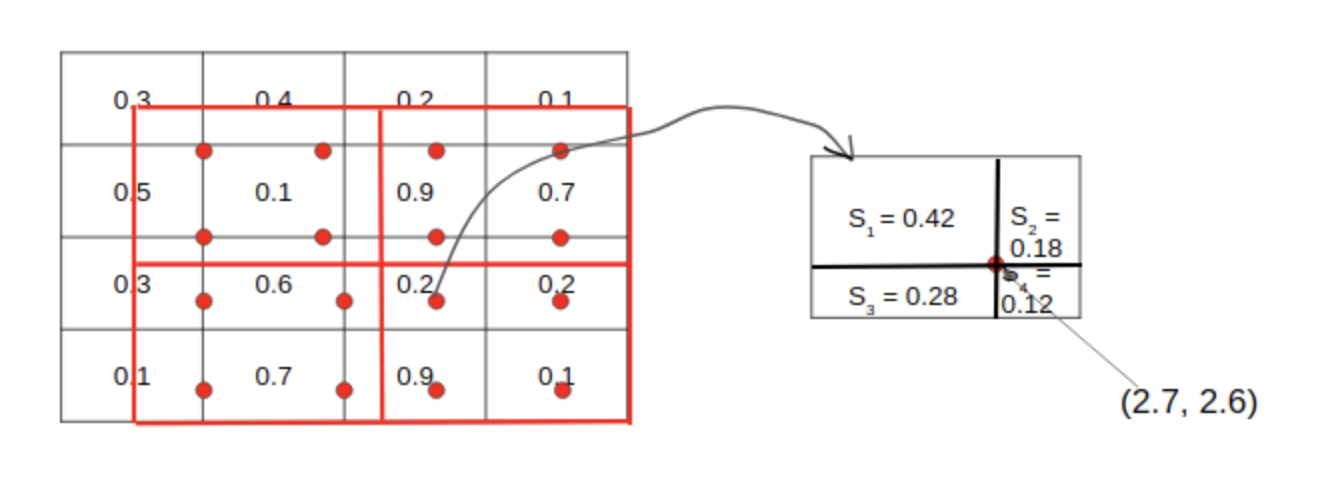
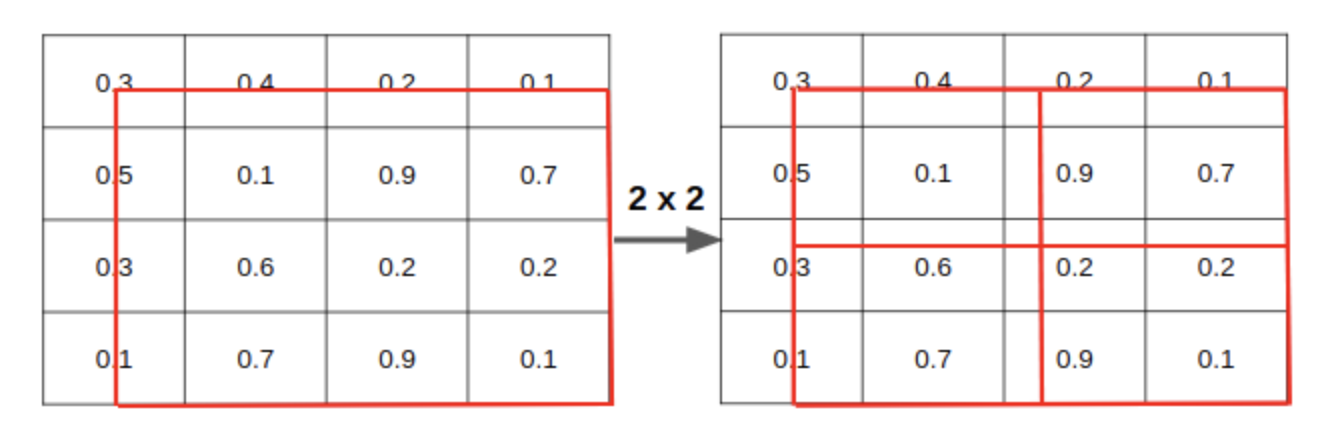
위 과정을 모든 sample point에 대해 진행해줍니다. 그럼 아래와 같이 하나의 영역 안에 4개의 값이 생기게 됩니다. 여기서 max혹은 average pooling을 사용해 2x2 output을 최종적으로 얻어낼 수 있게 됩니다.

Network Architecture
논문에서는 generality를 보여주기 위해 여러가지 backbone 모델들과 여러가지 network head를 사용했습니다. ResNet과 FPN을 같이 사용했을 때, 성능이 가장 좋았으므로 Resnet-FPN을 위주로 얘기하게 됩니다.
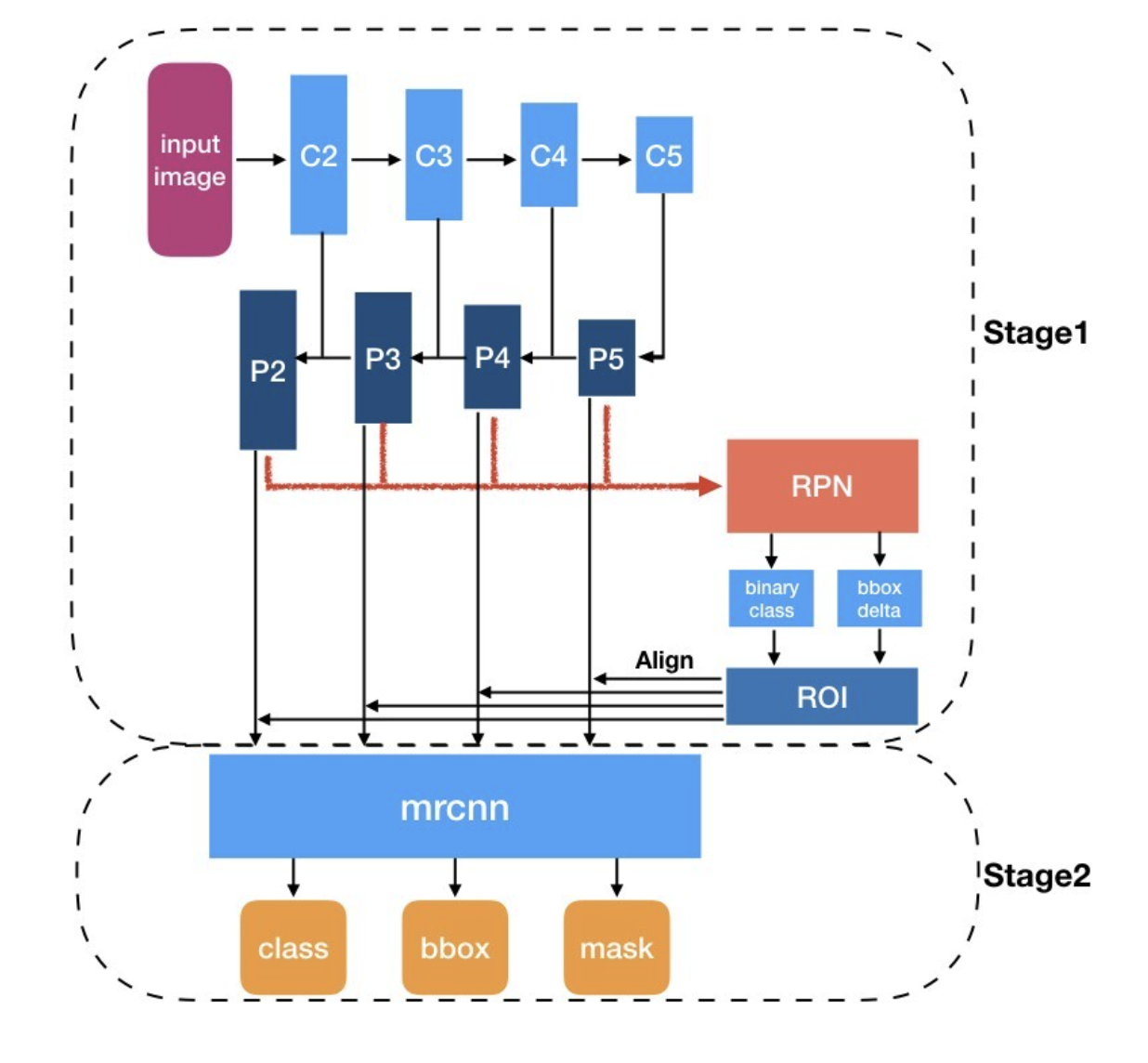
2) Feature pyramid by backbone network
전처리된 이미지를 ResNet-FPN backbone network에 입력하여 feature pyramid {P2, P3, P4, P5, P6}을 얻습니다.
3) Region Proposal by RPN
2) 과정에서 얻은 feature pyramid별로 RPN(Region Proposal Network)에 입력하여 objectness score와 bbox regressor를 가진 Region proposal을 출력합니다. (여기서 Anchor generation layer는 생략되어 있습니다.)
- Input: feature pyramid {P2, P3, P4, P5, P6}
- Process: Region proposal
- Output: Region proposals with objectness score and bbox regressor per feature pyramid {P2, P3, P4, P5, P6}
4) Select best RoI by Proposal layer
그 다음 RPN을 통해 얻은 Region proposal 중 최적의 RoI를 선정합니다. 이 과정은 Faster R-CNN의 Proposal layer, Anchor target layer, Proposal target layer에서 수행하는 과정과 같습니다.
1) objectness score가 높은 top-K개 anchor를 선택합니다. 학습 시 K=12000로 설정
2) bbox regressor에 따라 anchor box의 크기를 조절해줍니다.
3) 이미지의 경계를 벗어나는 anchor box를 제거해줍니다.
4) threshold=0.7로 설정하여 NMS를 수행
5) 지금까지의 과정은 feature pyramid level별 {P2, P3, P4, P5, P6}로 수행되었습니다. 이전까지 얻은 모든 feature pyramid level의 anchor box에 대한 정보를 결합(concatenate) 해줍니다.
6) 마지막으로 결합된 모든 anchor box에 대하여 objectness score에 따라 top-N 개의 anchor box를 선정합니다. 학습시 N=2000로 설정합니다.
최종적으로 수많은 anchor box중 최적의 N개의 box 만이 학습에 사용됩니다.
참고로 RPN의 학습시에는 ground truth와의 IoU가 0.5이상이여야 positive, 이외는 negative로 설정하였습니다.
또한, anchors는 FPN에서와 동일하게 5가지의 scale과 3가지의 aspect ratio를 가집니다.
마지막으로 NMS를 통해 가장 점수가 높은 N개의 RoI만을 output으로 넘겨준다고 보면 됩니다.
- Input: Region proposals
- Process: selecting top-N Rols
- Output: top-N Rols
5) feature map by RoI Align layer
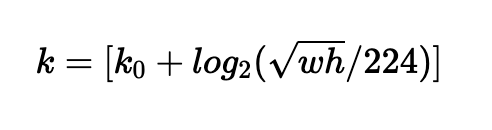
backbone network를 통해 여러 scale을 가진 feature pyramid {P2, P3, P4, P5, P6}가 생성됩니다. 그리고 PRN과 Proposal layer를 거쳐 N개의 RoI가 선정되었습니다. feature pyramid는 multi-scale feature map이기 때문에 RoI를 어떤 scale의 feature map과 매칭시킬지를 결정하는 과정이 필요합니다. 위의 공식에 따라 RoI와 feature pyramid를 매칭시켜줍니다. w, h는 RoI의 크기를 말하며, k는 feature pyramid의 level index를 말합니다.
그 다음 RoI 와 feature map을 사용하여 RoIAlign과정을 통해 7x7 크기의 feature map을 출력합니다.
- Input: feature pyramid and RoIs
- Process: RolAligns
- Output: 7x7 sized feature map
6) Classification and Bounding box regression by Fast R-CNN
이제 RolAlign과정을 통해 얻은 7x7 크기의 feature map을 fc layer를 거쳐 classification branch, bbox regression branch에 전달합니다. 이를 통해 최종적인 class score와 bbox regreessor를 얻을 수 있습니다.
- Input: 7x7 sized feature map
- Process: classification by classification branch, bbox regressor by bbox regression branch
- Output: class scores and bbox regressors
7) Mask segment by Mask branch
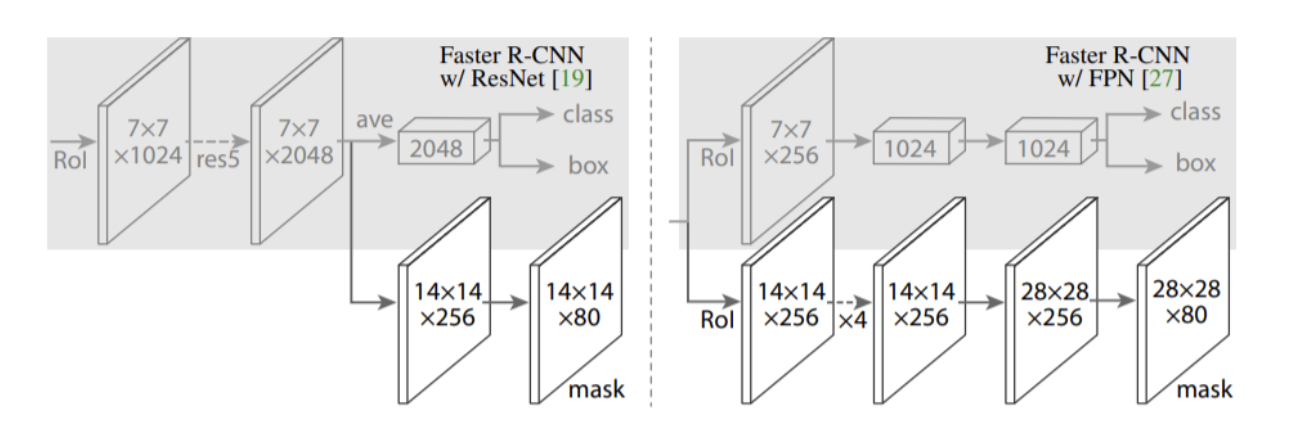
RolAlign과정을 통해 얻은 7x7 feature map을 mask branch에 전달하게 됩니다. mask branch는 3x3 conv - ReLU - deconv(by 2) - 1x1(xK) conv layer로 구성되어 있습니다. 여기서 K는 class의 수를 의미합니다(PASCAL VOC -> 80). 이를 통해 14x14(xK)크기의 feature map을 얻을 수 있습니다. 해당 feature map은 class별로 생성된 binary mask입니다.
14x14(xK) 크기의 feature map 중 앞서 classification branch에서 얻은 가장 높은 score의 class에 해당하는 feature map을 선정하여 최종 prediction에 사용합니다. 즉 단 하나의 14x14 크기의 feature map이 선정되는 셈입니다. 이후 feature map의 각 cell별로 sigmoid 함수를 적용하여 0~1 사이의 값을 가지도록 조정합니다.
- Input: 7x7 sized feature map
- Process: mask segment by mask branch
- Output: 14x14 sized feature map
8) Post-processing of masks
최종적으로 선정된 14x14 크기의 feature map을 원본 이미지의 mask와 비교하기 위해 rescale해주는 작업을 수행해줍니다. 이후 mask threshold(=0.5)에 따라 mask segment의 각 픽셀값이 0.5 이상인 경우 class에 해당하는 객체가 있어 1을 할당하고, threshold 미만의 경우 0을 할당합니다. 이를 통해 실제 mask와 비교할 수 있는 mask segment가 생성되었습니다.
- Input: 14x14 sized feature map
- Process: rescale and apply mask threshold
- Output: mask
9) Train Mask R-CNN by multi-task loss
Mask R-CNN 네트워크를 위에서 언급한 multi-task loss function을 사용하여 학습시킵니다.