[ Database - Intermediate ] - 파티셔닝, 샤딩, 래플리케이션
Partitioning

파티셔닝은 말 그대로 테이블을 자르는 작업이라고 보면 됩니다. 이에 대한 종류로는 위와같이 vertical, horizontal partitioning이 있습니다. 우선 vertical partitioning 먼저 보겠습니다.
vertical partitioning
이는 그리 어렵지 않습니다. 우리가 쭉 해오던 BCNF와 같은 normalization이 결국에는 column을 기준으로 table을 나눈 것이 되므로 vertical partitioning이 됩니다. 하지만 이는 정규화만 있는 것이 아닙니다.

우리는 위와같이 Article에 대한 예시를 들 수 있겠습니다. 해당 테이블로부터 위 쿼리문을 통해 게시물들을 조회해올 겁니다. 하지만 실제로는 content 값이 필요 없어서 필요한 attribute만 명시하는 과정을 거칠 겁니다.
하지만 실제 HDD나 SDD에서 쿼리문을 통해 값을 가져오는 방식을 간략히 살펴보면, 우선 HDD, SDD로부터 content를 포함한 row 전체 정보를 램으로 가져옵니다. 즉, 어차피 content를 들고 오는 상황에서 I/O에 대한 지연이 어떻게든 생기게 될 것이라는 소리입니다. 이는 실제로 index가 걸려있으면 체감하지 못할 수도 있지만 fullscan등을 할때에는 체감을 할 수 있습니다.

그래서 실제로 위와같이 vertical partitioning을 통해 I/O에 대한 부담을 줄여 빠르게 Article 정보를 바르게 select해올 수 있게 됩니다. 정리하면 이미 정규화가 되어있는 테이블이라도 performance등을 위해 vertical partitioning을 진행할 수 있습니다. 그 외에도 민감한 정보에도 제한을 두거나, 자주쓰는 attribute와 자주쓰지 않는 attribute를 묶기 위해 이를 사용하기도 합니다.
horizontal partitioning
이는 vertical partitioning과 다르게 테이블의 스키마는 유지가 되게 됩니다.

만약 위와같은 구독 정보가 담겨있는 테이블이 있다고 해 보겠습니다. user_id, channel_id가 PK인데, 각각 N, M개면 row는 $N x M$개가 될 것입니다. 1M x 1K가 되어도 1G개가 됩니다.. 그리고 테이블의 크기가 커질수록 인덱스의 또한 커집니다.
이 말은 테이블에 읽기/쓰기가 있을 때마다 인덱스에서 처리되는 시간도 조금씩 늘어난다는 소리입니다. 이는 규모가 커질 수록 체감이 될 것입니다. 이때 사용되는 것이 hash-based horizontal partitioning입니다.
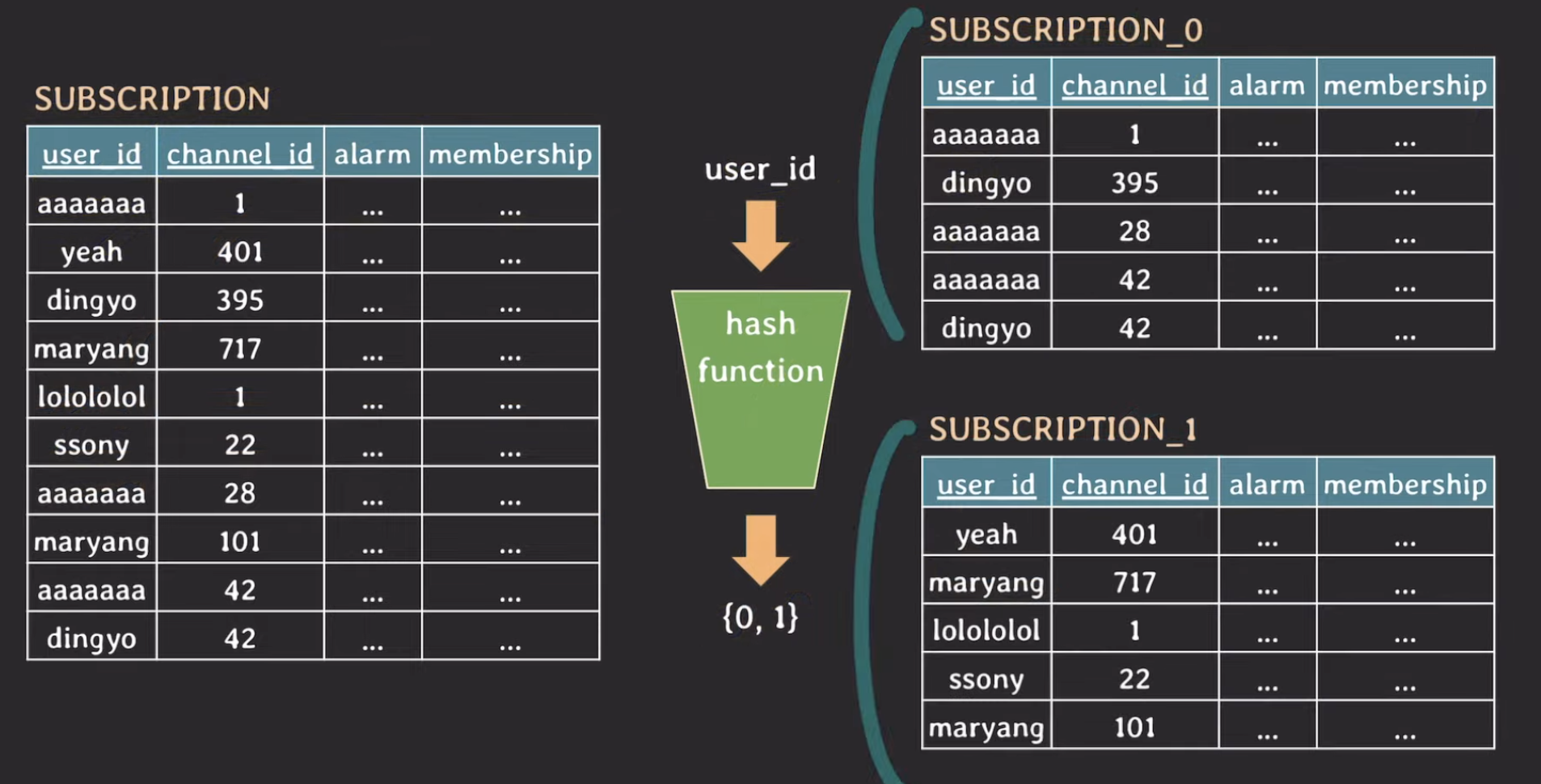
위와같이 hash값에 따라 위에서는 (user_id)를 hash function을 통해 나온 값을 통해 검색할 테이블을 결정하게 됩니다. 여기서는 2개의 테이블로 쪼갰지만, 실제로는 더 많은 테이블로 쪼갤 수 있습니다. 이떄 user_id를 partition key라고 합니다.
만약 dingyo가 구독한 채널들 정보를 모두 조회하고 싶다면 위 상황에서 어떻게 해야할까요? 그럼 쉽게 Subscription_0 테이블에 가서 조회하면 됩니다.
하지만 id가 1인 channel을 구독한 사용자의 id를 모두 조회하고 싶다면 어떻게 해야할까요? 여기서 channel_id는 partition key가 아니기 때문에 모든 table을 다 찾아봐야 하는 것입니다. 그래서 partition key를 가장 많이 사용될 패턴에 따라 정하는 것이 매우 중요합니다.
그리고 Universial hashing을 하도록 유지하는 것 또한 매우 중요합니다. 한쪽 테이블에 데이터가 다 몰리면 안되겠죠?? 그리고 여기서 주의해야할 점은 한번 partition이 나눠져서 사용되면 이후에 partition을 추가하기가 까다롭기 때문에 신중히 테이블을 나누어야 합니다.
Sharding
이는 horiziontal partitioning 처럼 동작합니다. 하지만 sharding을 하게되면 각 partition이 독립된 DB 서버에 저장되게 됩니다.

위와같이 partition 된 테이블이 한 DB서버에 있다면 이는 horiziontal partitioning이라고 할 수 있습니다. 어느 테이블에 대한 요청이든 한 DB 서버에 대한 CPU와 MEM을 사용해 처리하게 되는 것이죠. 즉 HW가 한정되어 있다는 것입니다.
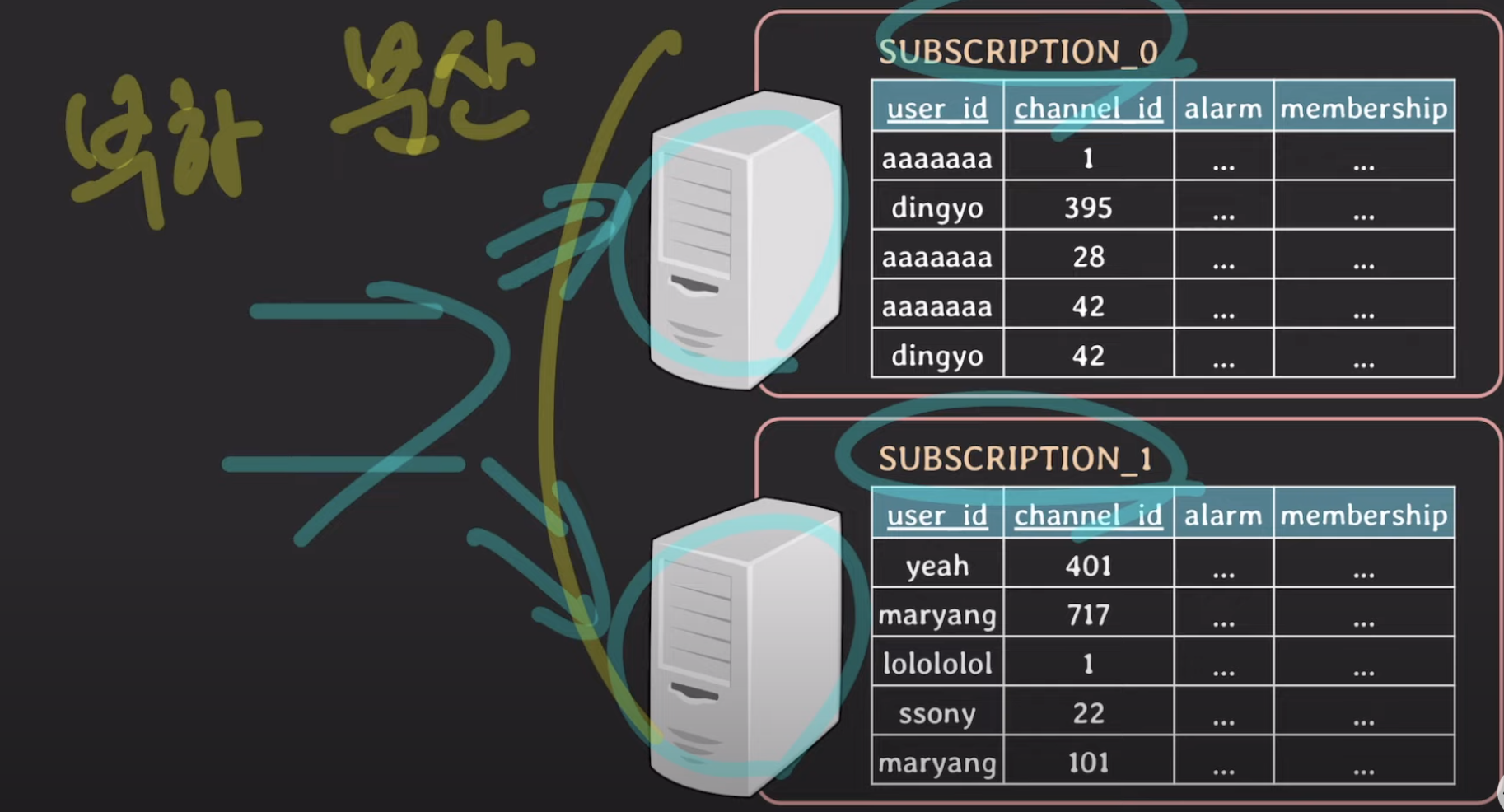
Sharding은 위와같이 partition table을 독립된 DB서버에 두어서 부하를 분산시키는 것을 말합니다. 이를 load balancing이라고도 하죠. 이를 하게되면 partition key를 shard key라고 부릅니다. 그리고 각 partition을 shard라고 부릅니다.
Replication
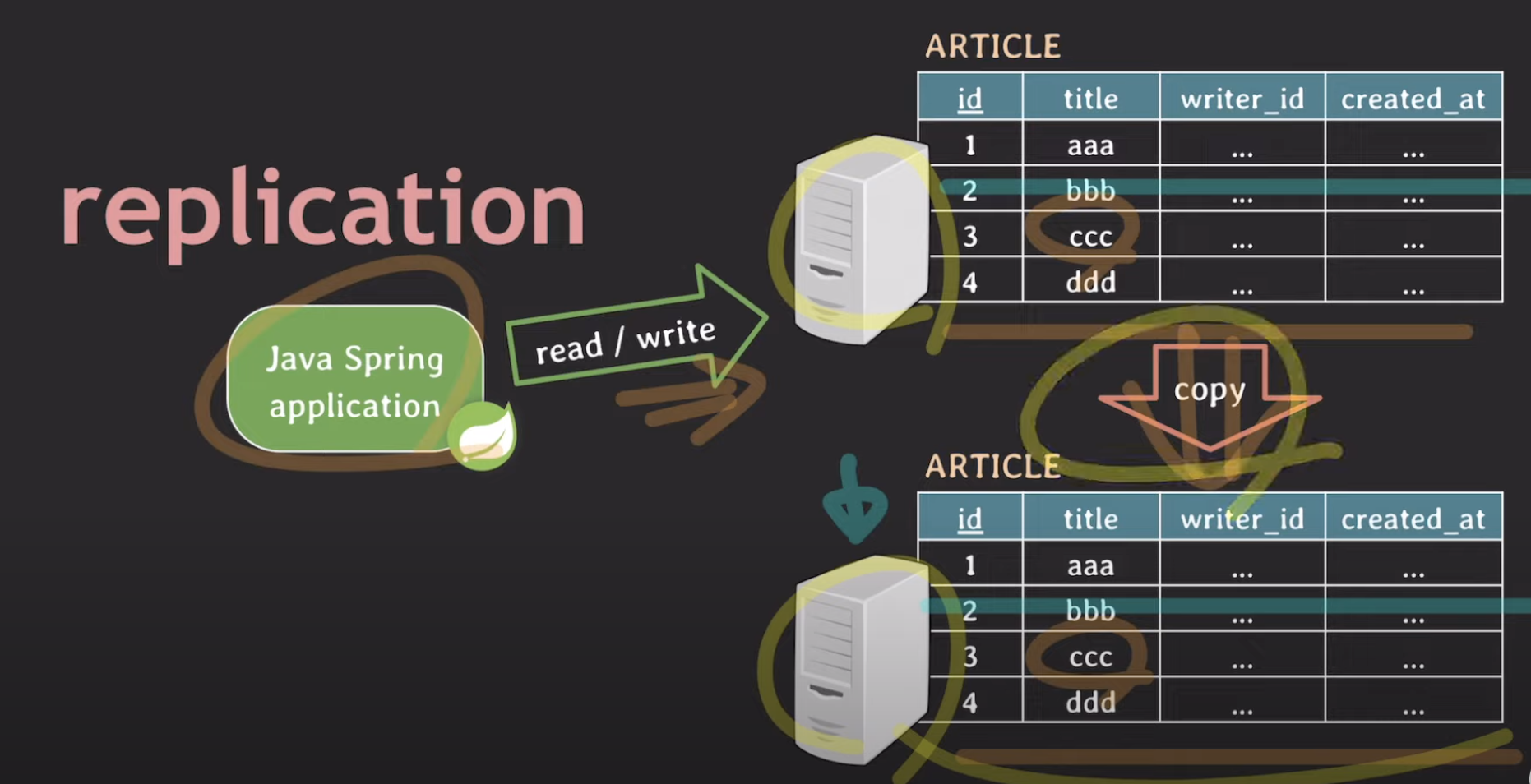
실제로 replication이란 위와같이 Java Spring 기반의 애플리케이션에 DB 서버로 read / write 요청을 할 것인데, 이 DB로부터 복사본을 따로 만들어서 해당 read / wirte요청을 그대로 해주는 것을 말합니다. 즉 주 DB서버가 있고 이에 대한 보조 DB서버가 있는 것을 Replication이라고 합니다.
여기서 주 DB서버를 우리는 master / primary / leader라고 부릅니다. 그리고 보조 DB서버는 slave / secondary / replica 라고 부르는 것이 보통입니다.
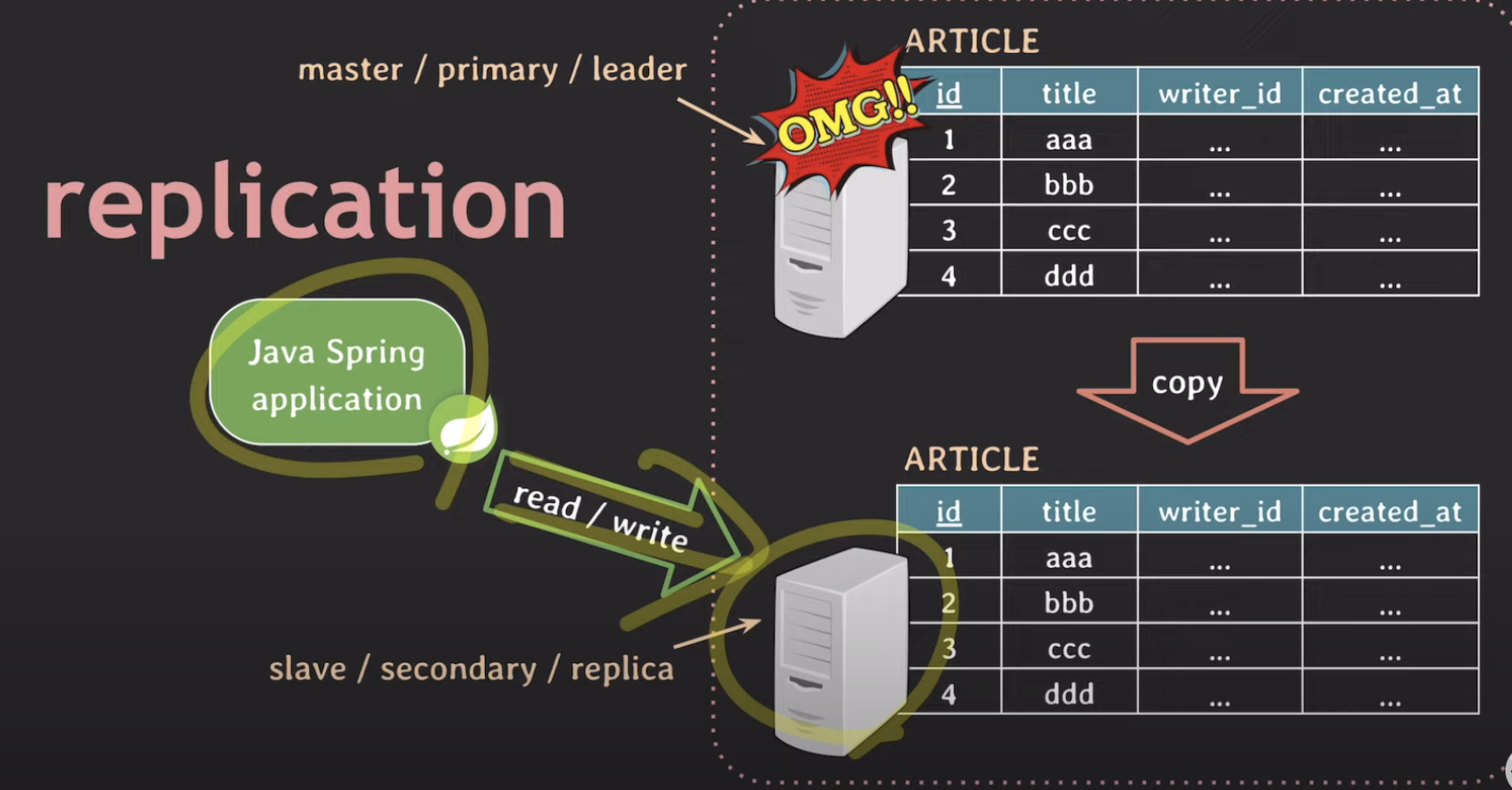
만약 master에 문제가 생기면 바로 fail-over를 통해 slave에 연결해 줍니다. 이를 통해 최대한 서비스에 영향이 없도록 하는 것이 High-availability(고가용성, HA)을 만족한다 라고 합니다.
그리고 위와같이 replication을 하게되면, read 쿼리를 slave로 부하 분산을 할 수 있습니다. 그럼 그만큼 master에 대한 부하가 줄어들게 됩니다.