[ Database - Intermediate ] - DB 정규화 (1NF, 2NF, 3NF, BFNF, 역 정규화)
DB 정규화(normalization)
db정규화란 이전에도 봤다싶이 데이터 중복과 insertion, update, deletion anomaly를 최소화하기 위해 일련의 normal forms(NF)에 따라 relational DB를 구성하는 과정이라고 할 수 있습니다.

DB 정규화 과정은 위와같습니다. 이는 처음부터 순차적으로 진행되며 앞쪽 NF를 만족하지 못하면 만족하도록 테이블 구조를 조정해야 합니다.
그리고 1NF ~ BCNF까지는 FD와 key만으로 정의되는 normal forms입니다. 그래서 3NF까지 도달하면 정규화 됐다고 말하기도 합니다. 그래서 실무에서는 보통 3NF 혹은 BCNF까지만 진행합니다. 4NF~6NF는 학술적인 측면이 강합니다.

우리는 위 Employee_account를 통해서 1NF 부터 시작해서 BCNF까지의 정규화 과정을 순차적으로 진행해 보겠습니다.
EMPLOYEE_ACOUNT 스키마 설명
위 테이블을 간단히 설명하자면 bank_name은 임직원의 월급 계좌를 관리하는 테이블로써 국민은행이나 우리은행 중 하나만 할당될 것입니다. 그리고 한 임직원이 하나 이상의 월급 계좌를 등록하고 월급 비율(ratio)를 조정할 수 있습니다. 그리고 각 계좌마다 등급(class)가 있습니다. 국민은행은 STAR -> PRESTIGE -> LOYAL, 우리은행은 BRONZE -> SILVER -> GOLD이렇게 나뉩니다. 그리고 한 계좌는 하나 이상의 현금 카드와 연동될 수 있다고 하겠습니다.
key의 종류
그리고 이전에 DB 앞단에서 설명했던 key의 종류를 다시한번 짚고 가겠습니다. super key는 table에서 tuple들을 unique하게 식별할 수 있는 attribues set입니다. (candidate) key는 어느 한 attribute라도 제거하면 unique하게 tuples를 식별할 수 없는 super key입니다. 이에 대한 예시로는 {account_id}, {bank_name, account_num}가 될 수 있겠네요. 그리고 primary key는 table에서 tuple들을 unique하게 식별하려고 선택된 candidate key가 됩니다. 우리는 {account_id}를 PK로 사용하겠습니다. 그리고 prime attribute는 임의의 key에 속하는 attribute입니다. 위의 예씨에서는 account_id, band_name, account_num이 되겠네요. non-prime attribute는 prime attrubute가 아닌 attribute들을 말합니다.
FD
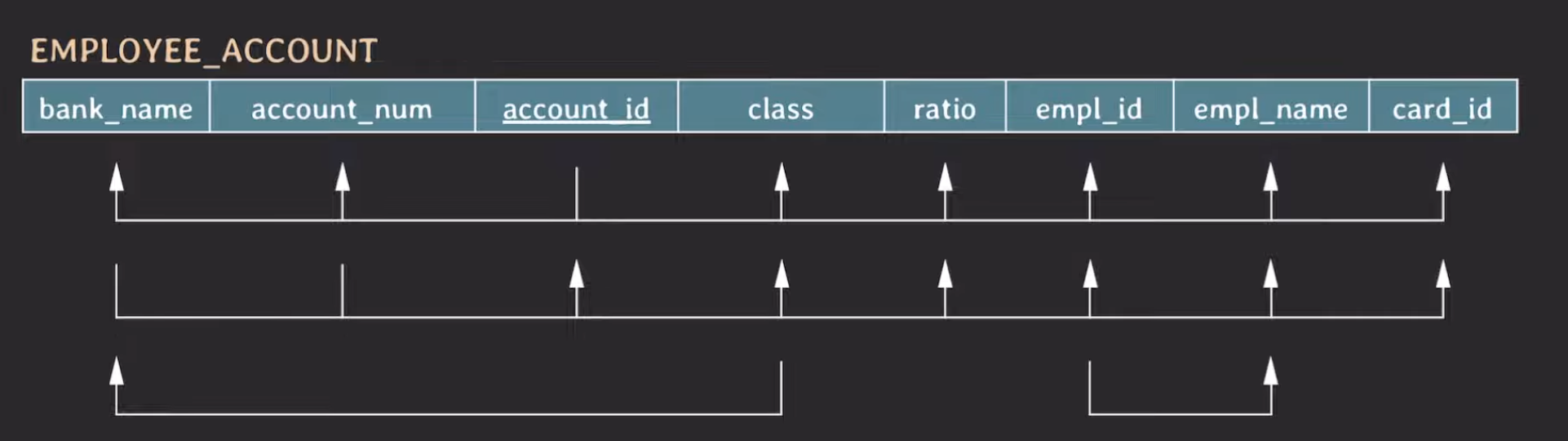
우선 FD를 가시화 했습니다. 첫번째는 {account_id} -> {나머지} 가 될 것이고, {bank_name, account_num} -> {나머지}가 될 것입니다. 또 {empl_id} -> {empl_name} 이 될 것입니다. 또한, 우리는 은행마다 이에 대한 class가 다르다고 했습니다. 즉 {class} -> {bank_name} 이 성립할 것입니다.
1NF 시작
우선 우리는 예제로 사용할 만한 데이터를 넣었다고 하겠습니다.

Sony를 보면, 3개의 계좌를 통해 월급을 0.1, 0.2, 0.7의 비율로 나눠 받는다고 가정하겠습니다. 그리고 card_id도 각각 있고요. Messi는 한개의 계좌와 카드 2개가 있는 것을 볼 수 있습니다.
이제 정규화를 시작해보겠습니다. 1NF란 attribute의 value는 반드시 나눠질 수 없는 단일한 값이여야 한다는 rule입니다. 여기서 이를 위반하고 있는것은 Messi의 card_id가 "c201 c202" 이렇게 단일한 값이 아니여서 위반하고 있는데, 이를 쪼개주는 작업을 1NF에서 해주어야 할 것 같습니다. 이를 처리해주어야 2NF로 넘어갈 수 있습니다.
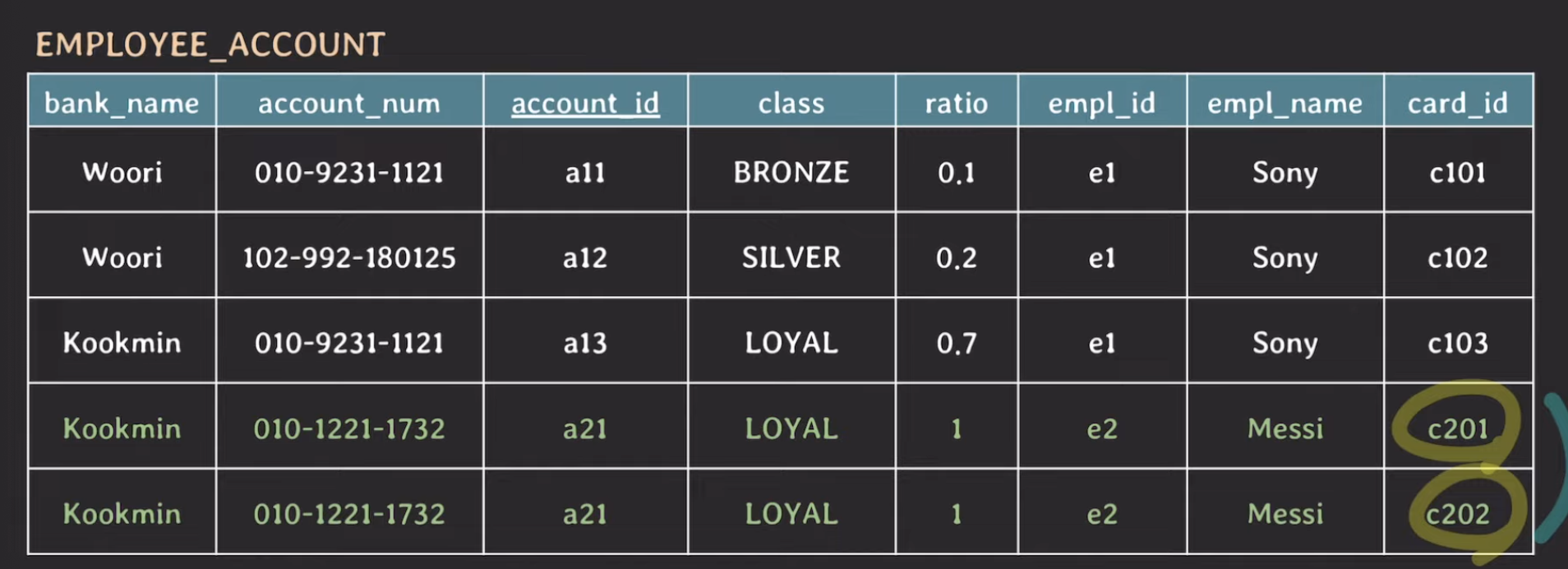
우선 1NF을 만족시키기 위해 위와같이 쪼개주었습니다. 하지만 이렇게 함으로써 중복 데이터가 생기게 되었고, PK(account_id가 unique하지 않게 되었음)도 변경을 해야할거 같고 ratio에도 문제가 생겼습니다(ratio의 합이 1이 아님). 그래서 일단은 {account_id, card_id}를 PK로 지정해 주었습니다.
2NF 시작
우리는 1NF을 하고 나니 (candidate) key에 변화가 생겼습니다. {account_id, card_id}, {bank_name, account_num, card_id}로 말이죠. 그리고 여기서 non-prime attribute는 {class, ratio, empl_id, empl_name} 입니다.

그리고 우리는 또 유심히 봐야할 점이 있습니다. 이 non-prime attribute는 account_id만으로 결정될 수 있습니다. 이를 우리가 이전시간에 FD에서 봤던 이름으로 바꾸면 non-prime attribute 들이 {account_id, card_id}에 대해 partially dependent하다라고 할 수 있습니다. 이렇게 때문에 실제로 중복이 발생하고 있는 것이라고 느끼고 있을 겁니다.
이 뿐만 아니라 모든 non-prime attribute들이 {bank_name, account_num, card_id}에 partially dependent합니다. 즉 card_id이놈이 문제인 것이죠. 얘때문에 중복하지 않아도 될 값들이 생기게 된 것이라고 할 수 있습니다.
이를 위해 2NF를 하는데, 2NF는 모든 non-prime attribute는 모든 key에 fully FD해야 한다는 rule을 만족해야 합니다. 이를 해결하기 위해서는 card_id만을 바꿔주면 될거 같습니다. 얘만 key에서 빼주면 fully FD가 되기 때문입니다.
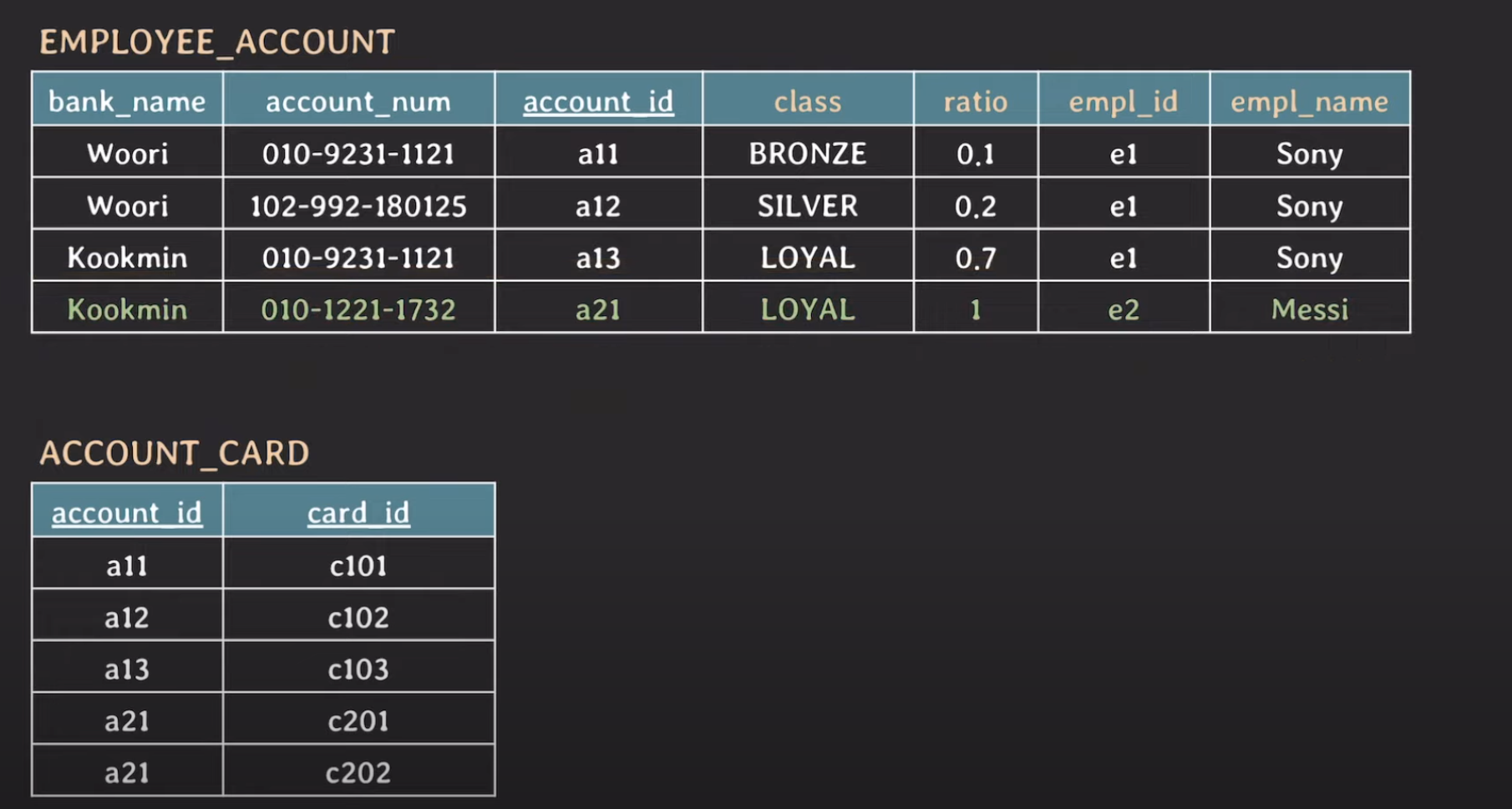
우리는 Account_card를 만들어주어서 account_id를 FK로써 만들어주어서 2NF를 만족하게 했습니다. 이렇게 하면 모든 non-prime attribute에 대해 fully FD하게 되었습니다!!
3NF 시작
하지만 2NF를 적용시켜준 이후에도 empl_name과 empl_id등등에 중복 데이터가 여전히 보임을 확인할 수 있을 겁니다.
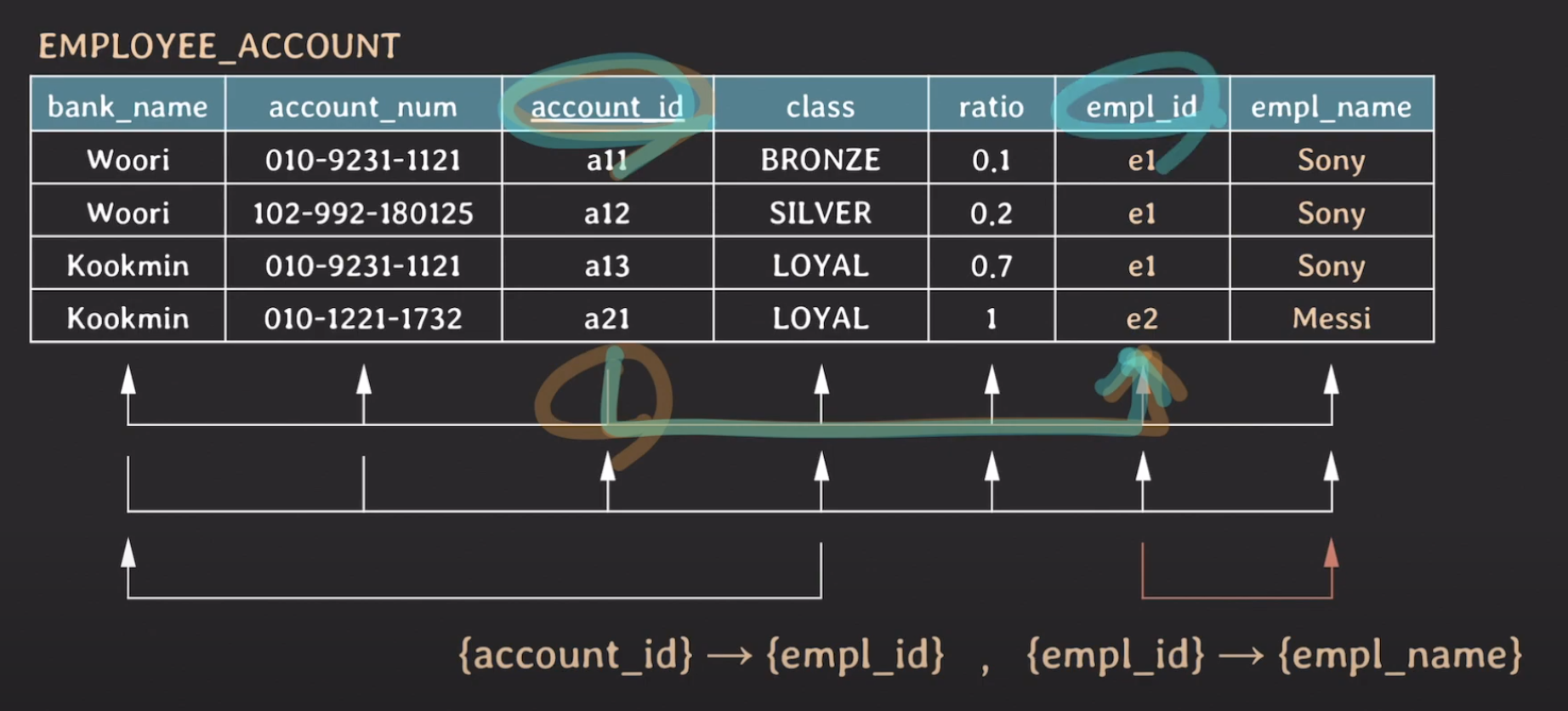
그리고 FD를 분석해보면 {empl_id} -> {empl_name} 입니다. 그리고 {account_id} -> {empl_id} 가 됩니다. 여기서 {empl_id}가 연결되어서 {empl_id} -> {empl_name}이 성립함을 쉽게 알 수 있습니다. 뿐만 아니라 다른 (candidate) key에 대해서도 {bank_name, account_num} -> {empl_name}이 성립함을 알 수 있습니다.
이를 이산수학시간에 많이 배웠었는데 이를 transitive FD라고 합니다! 여기서 중요한 점이 x->y, y->z 일 때 y, z는 어떠한 key의 subset이면 안된다는 제약사항이 있습니다.
여기서 3NF의 규칙을 보면, 이는 모든 non-prime attribute는 어떤 key에도 transitively dependent 하면 안된다는 것입니다. 즉 이를 더 쉬운말로 풀어쓰면 non-prime attribute와 non-prime attribute 사이에는 FD가 있으면 안된다는 것입니다. 이 또한 테이블을 분리해서 FD를 분히ㅐ주면 되겠죠?? 이를 위해 Employee테이블을 만들어주어서 FD를 없애보겠습니다. 그럼 아래와같은 그림이 됩니다.
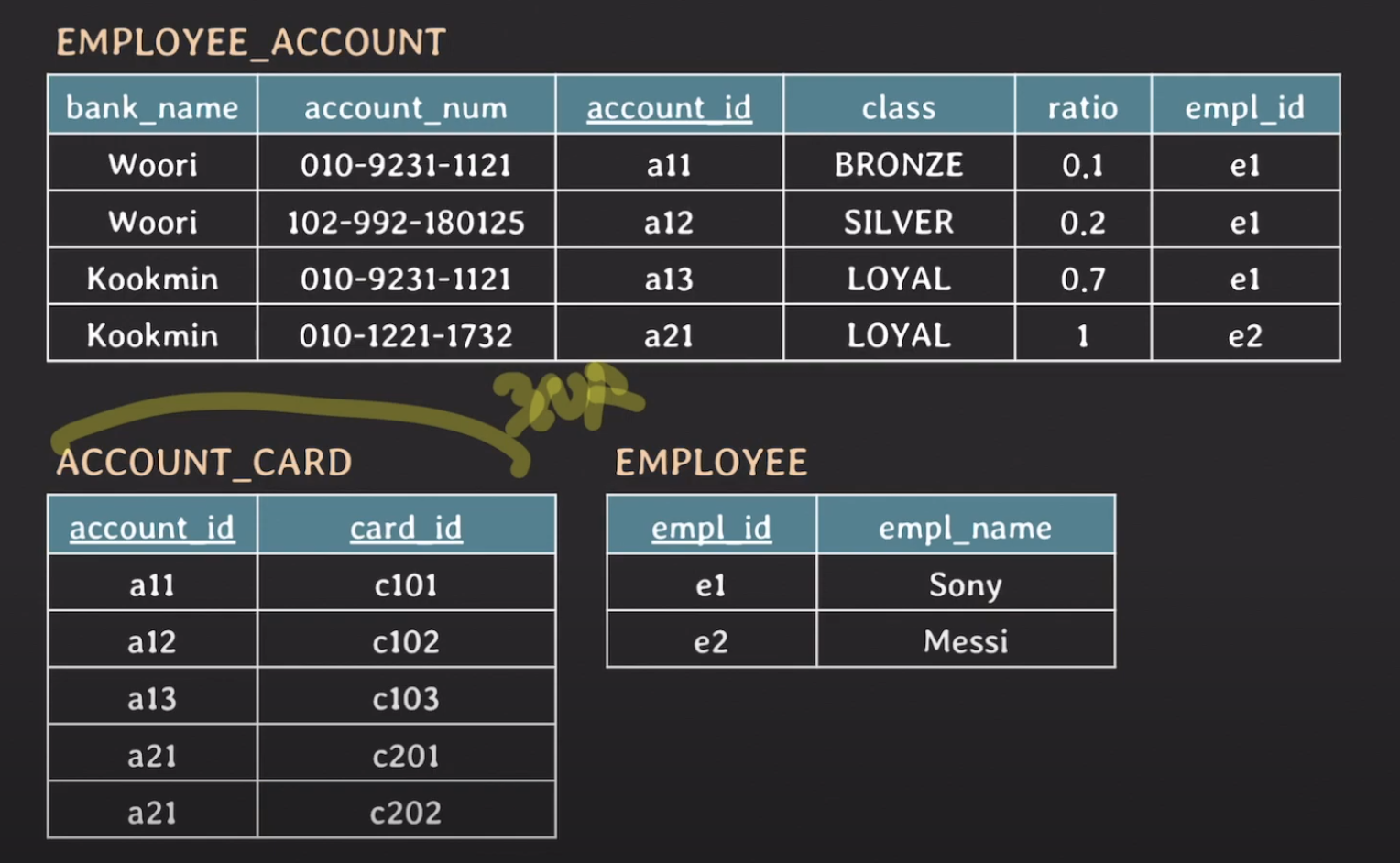
이렇게 하면 3NF까지 되어서 우리가 흔히 말하는 "정규화(normalized) 됐다." 라고 말할 수 있습니다.
BCNF 시작
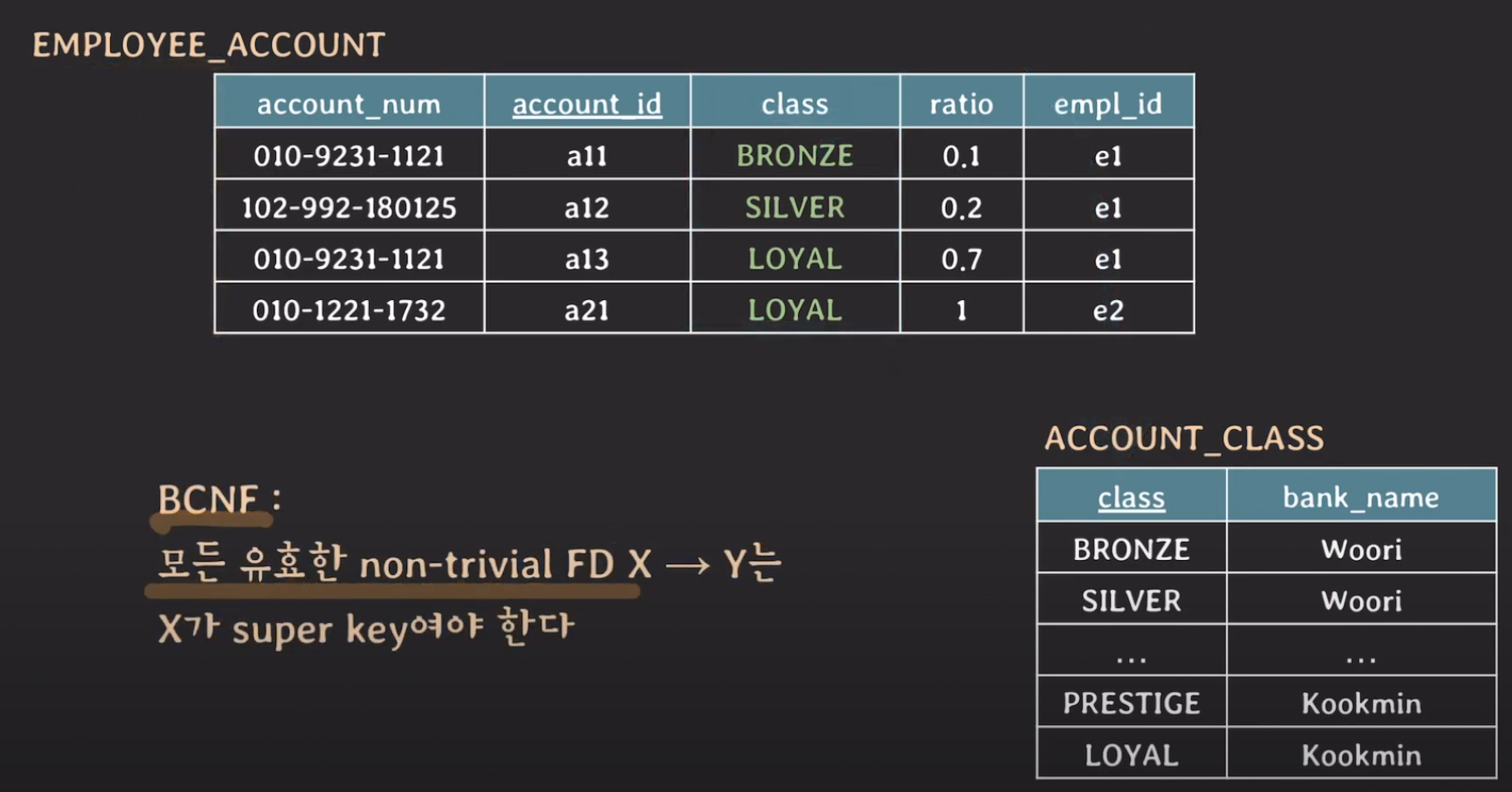
우리는 이전에 {class} -> {bank_name} 이라고 했었습니다. 그래서 우리는 생각해보아야 합니다, 굳이 bank_name과 같이 중복이 발생하는 attribute를 한 테이블에 유지할 필요가 있을까?? 라고 말이죠.
이제 BCNF의 rule에 대해 보겠습니다. 이는 모든 유효한 non-trivial FD X -> Y는 X가 super key여야 한다는 것입니다. 여기서 non-trivial FD란 X가 Y의 부분집합이 아니라는 소리입니다. 하지만 class는 super key가 아니므로 BCNF rule에 위반되게 됩니다. 이제 이 또한 테이블을 나누어서 BCNF를 만족하도록 해보겠습니다.
위와같이 적용하고 bank_name을 지워서 BCNF를 만족시킬 수 있습니다.
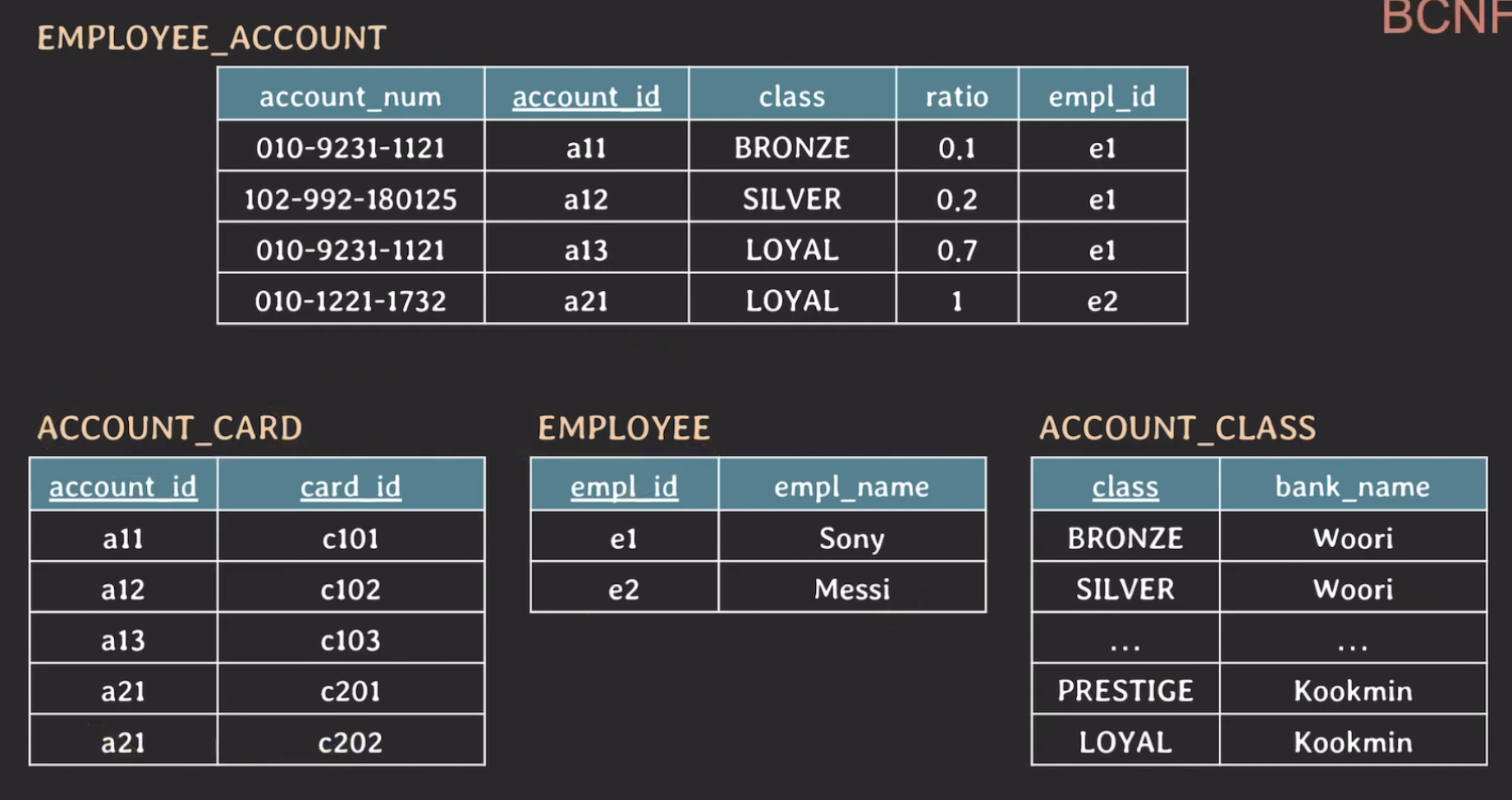
그리고 나머지 Account_card, Employee 모두가 BCNF를 만족하기 때문에 위 테이블 구조는 BCNF를 만족한다고 할 수 있습니다.
2NF 참고사항

2NF에서 참고사항은 key가 composite key가 아니라면 2NF는 자동적으로 만족한다? 가 맞을까요?? 그 이유는 2NF는 모든 non-prime attribute는 모든 key에 fully dependent 해야하는 것이라고 했었습니다. 하지만 key가 composite key가 아니라면 자동적으로 모든 non-prime attribute는 모든 key에 fully dependent 하니까 당연한 소리 같습니다. 아지만 아래 예시를 보겠습니다.

{} 는 {empl_id}의 부분집합이 되게 되는데, 이러면 company는 partially depdent하게 됩니다. 그래서 2NF가 위반되게 되는 것이죠.
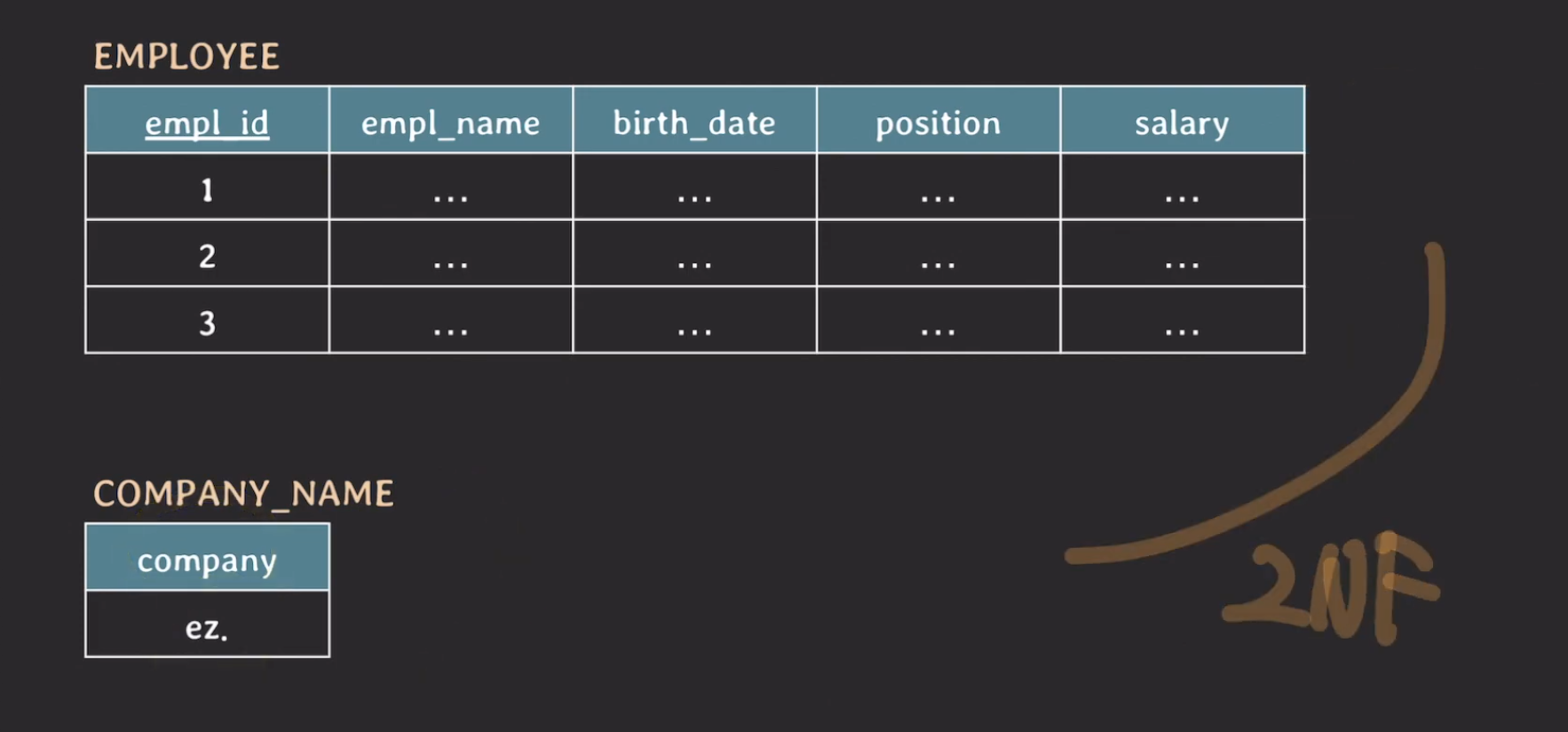
위와같은 Corner-Case를 만족해야 2NF를 만족시킬 수 있게 됩니다. 하지만 일반적인 상황을 가정할 때는 위의 말이 맞다는 것입니다. 하지만 굳이 이렇게 테이블을 쪼개지 않고 ez를 붙히는게 편해서 다시 붙이는걸 고려해볼 수도 있는데, 이를 역정규화(denormalization)이라고 합니다.

위에서 우리가 쭉 BCNF까지 쪼갰던 예시도 굳이 BCNF까지는 안하고 3NF까지 해서 테이블을 붙혀서 join할 때의 오버헤드를 줄이겠어! 라고 할 때 역정규화를 전략적으로 사용하게 됩니다. 즉 DB를 설계할 때 과도한 조인과 중복 데이터 최소화 사이에서 적정 수준을 잘 선택할 필요가 있습니다