[ Database - Basic ] - DB 테이블 설계를 잘못하면 발생할 수 있는 문제점
중복 데이터 문제

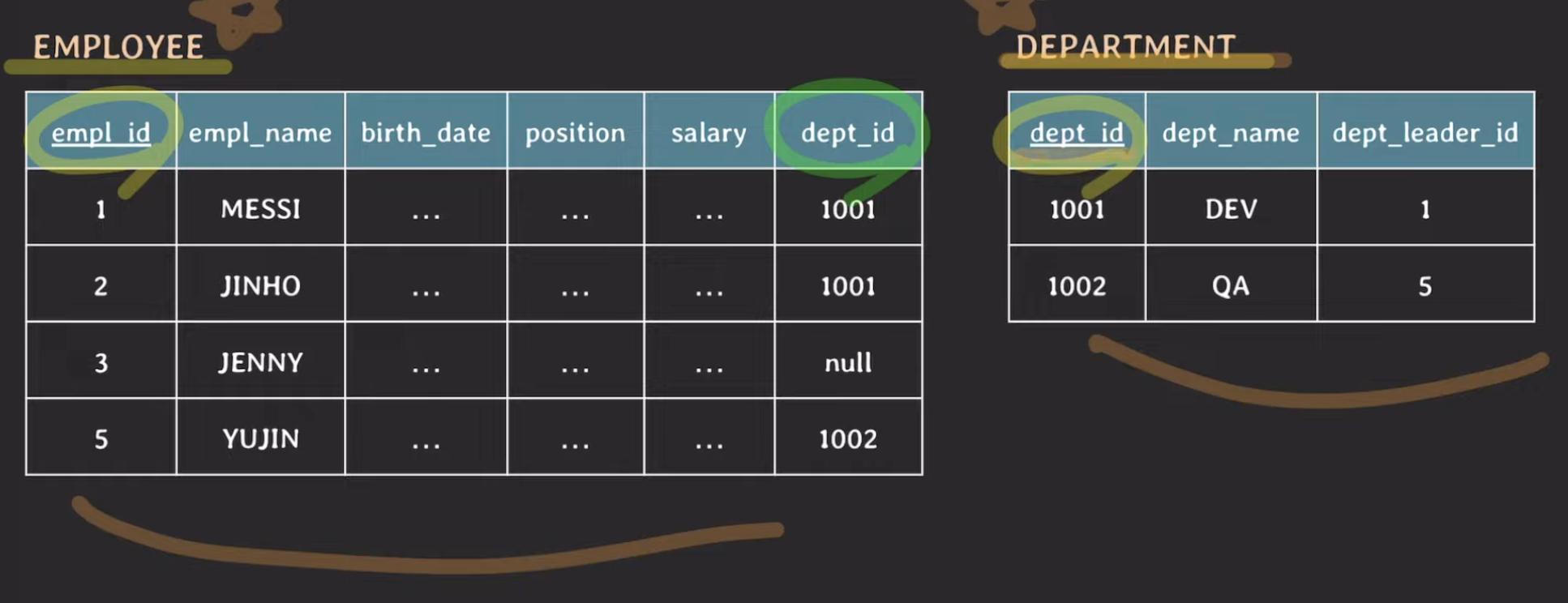
만약 위와같이 예전에 봤던 employee 데이터베이스 스키마와 department 데이터베이스 스키마를 한번에 합친 모습입니다. 이때는 Insertion anomalies가 발생하게 되는데, 위와같이 중복된 데이터가 삽입되게 됩니다.
이렇게 하게되면 저장공간 낭비일 뿐더러, 실수로 인한 데이터 불일치 가능성이 존재하게 됩니다. 실수로 dept_name을 DEV가 아닌 DEB이렇게 삽입하면 발생할 수 있는 문제점입니다. 그리고 만약 어떤 employee가 부서배치를 받기 전이라면 dept_id부터 dept_leader_id까지의 정보가 싹다 null이 될 것입니다. 뒤에서 볼거지만 이렇게 로우에 null을 난발하는 것은 좋지 못한 것입니다.

또다른 문제점이 있습니다. 만약 임직원의 정보를 저장하고 싶은게 아니라 어떤 부서의 정보만을 저장하고 싶다고 하면 위와같이 될겁니다. 그리고 위와같이 저장되는게 아니라 employee_department 테이블의 PK는 empl_id이기 때문에 4로 할당될 것입니다. 우리는 그냥 QA부서 저장 용 row를 만들어 주었는데, empl_id를 할당해주어야 하는 기이한 상황을 마주치게 되었습니다. 이는 매끄럽지도 않고 null값도 많이 쓰게 됩니다.

그리고 QA부서에 YUJIN이 들어왔다고 하면, 위에서 할당했던 4번 로우는 삭제해주어야 하는 번거로움이 생기게 됩니다. 이러한 문제는 두개의 관심사가 하나의 테이블 스키마에 있기 때문에 발생한 문제라고 할 수 있겠습니다. 그래서 관심사를 분리하게 되면 아래와 같이 바꿀 수 있게 되는 것이죠.
그리고 위상황에서 Deletion anomalies라는 것도 있는데, 만약 5번 YUJIN을 삭제하는 상황에서는 이제 department에서 QA팀에 한명도 속하지 않습니다. 이 상황에서는 on delete 속성이 어떻게 지정되어 있느냐에 따라 다르겠지만 dept_id가 1002번인 dept_leader_id를 null로만 바꿔주면 될거 같습니다. 기존이라면 위처럼 QA만 덩그러니 있고 싹다 null로 채워줘야 했었죠.
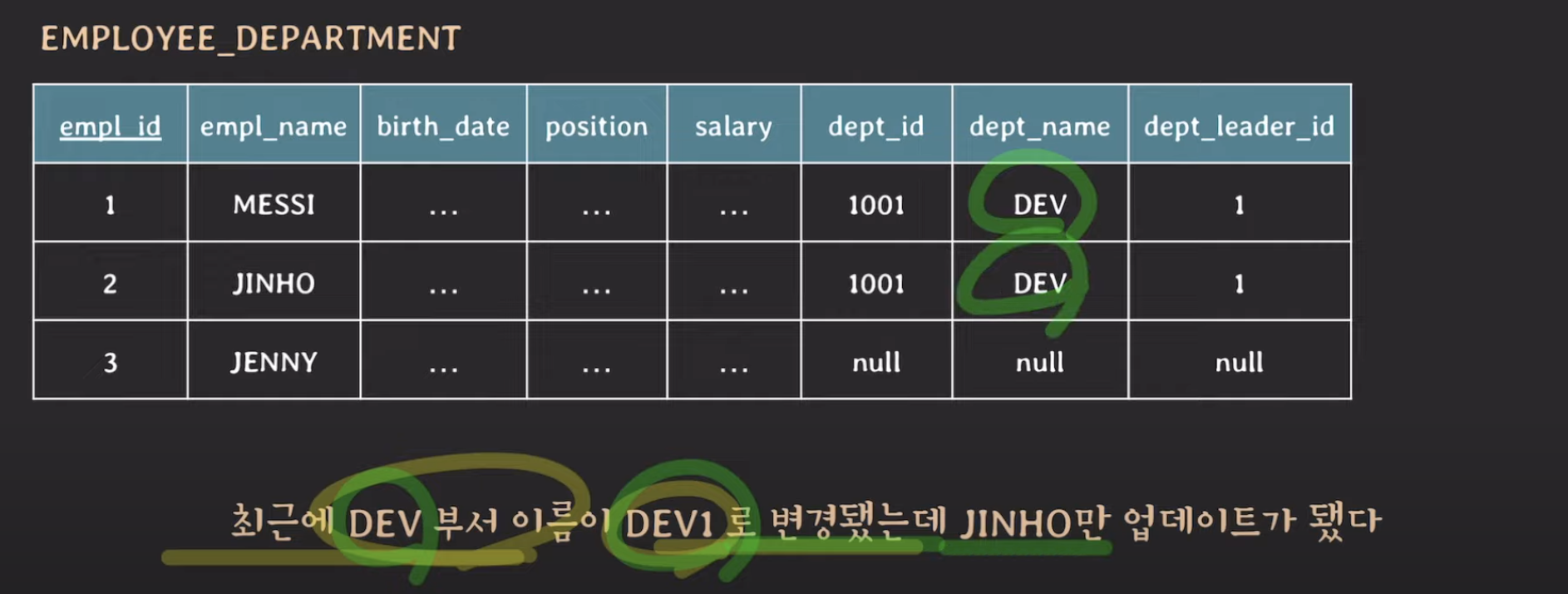
그리고 만약에 DEV의 이름을 바꾸고 싶은데, 위 상황에서는 싹다 바꿔주어야 합니다. 그리고 하나만 바꿔주면 데이터의 불일치가 발생할 수도 있는 것이죠. 이를 Update anomalies라고 합니다. 하지만 관심사를 분리하면 department하나만 수정해주면 되겠죠??
Supurious Tuples
우선 이를 알아보기 전에 사진 촬영 회사의 데이터베이스를 설계했다고 해보겠습니다.
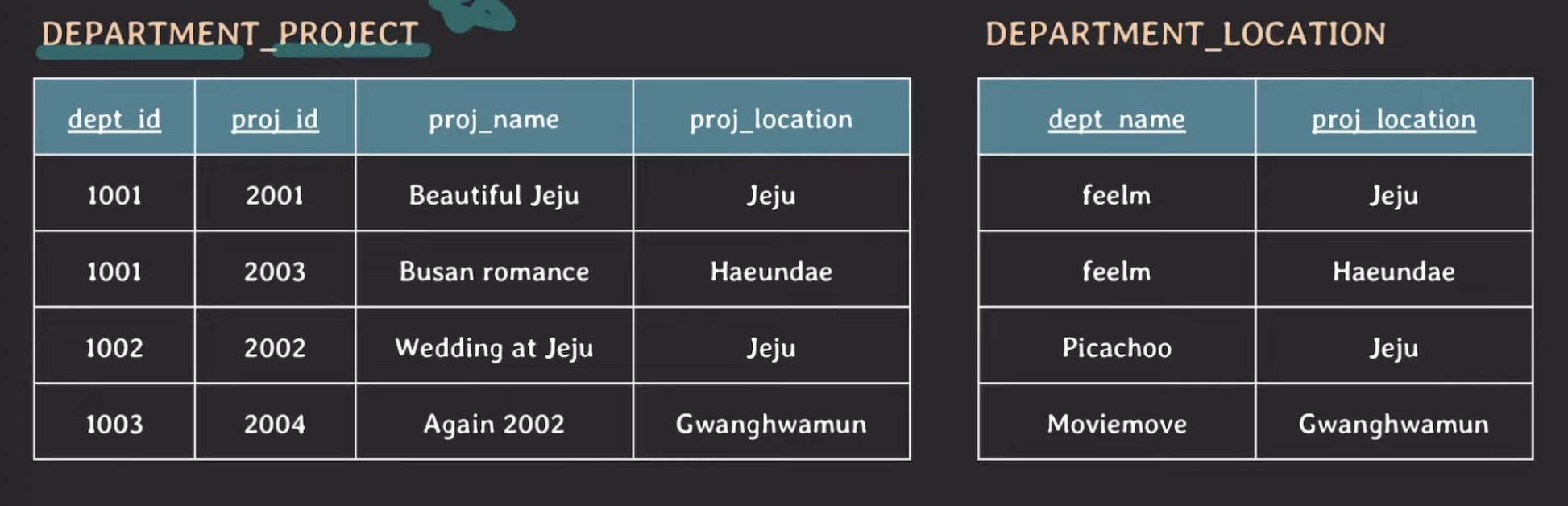
위 상황에서 department_project에 대해 natural join을 해보겠습니다.
SELECT * from DEPARTMENT_PROJECT natural join DEPARTMENT_LOCATION;이렇게 하면 다들 예상하셨겠지만, 1001번에 대해서 proj_location이 jeju인데, Jeju는 dept_name이 feelm, Picachoo 2개여서 총 join table의 로우수가 4개가 아니라 6개로 늘어나게 됩니다.
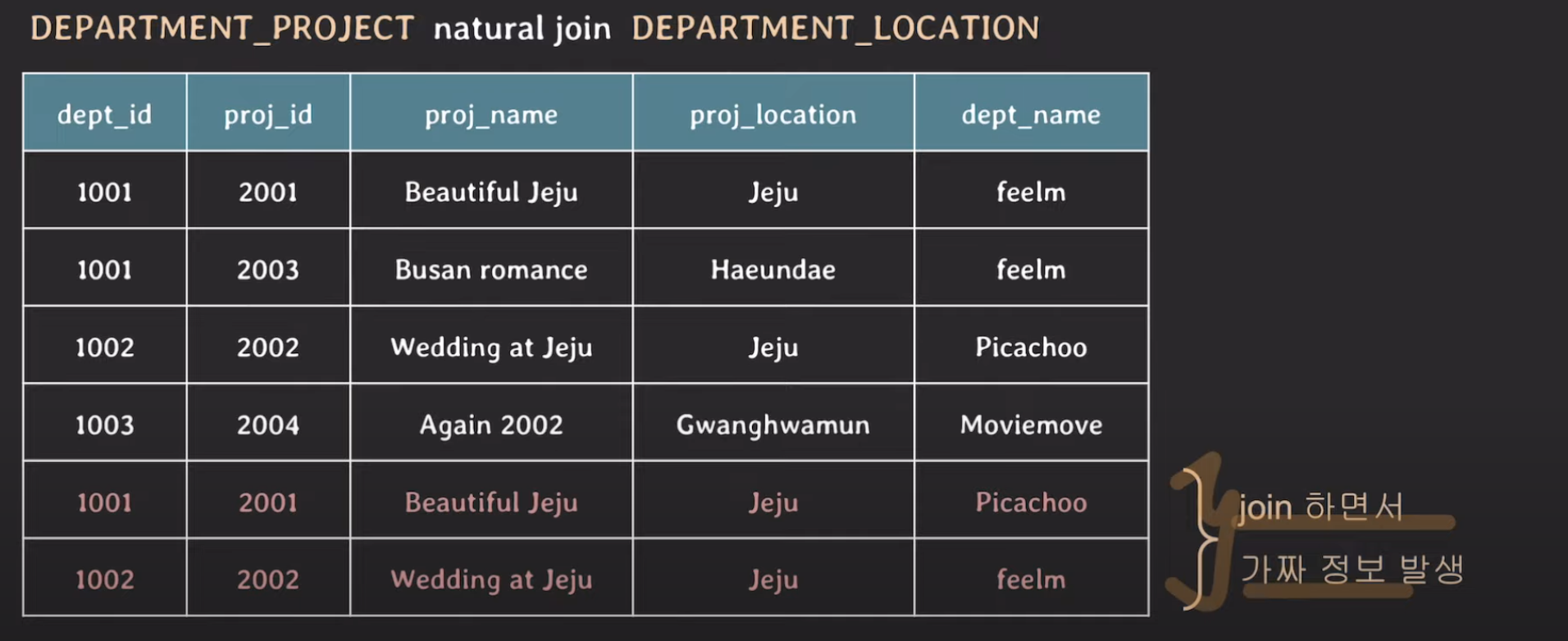
위와같이 join을 하면서 가짜 정보가 발생하는데, 이를 supurious tuple이라고 하는 것이죠. 이를 해결하기 위해서는 아래와 같이 테이블을 분리하여 관심사의 분리를 해야합니다.

null 값이 많아지므로 인한 문제점들
이전에 테이블 설계를 이상하게 했더니 null값이 많아졌었습니다. null값이 있는 column으로 join을 하는 경우 상황에 따라 예상과 다른 결과가 발생할 수 있습니다. 그리고 null 값이 있는 column에 aggregate function을 사용했을 때 주의해야 합니다. 기본적으로 count는 null값을 세지 않는 것을 기억해내야 합니다.
바른 DB schema 설계
정리하자면 바른 DB schmea를 설계하기 위해서는, 의미적으로 관련있는 속성들끼리 테이블을 구성해야 하며, 중복 데이터를 최대한 허용하지 않도록 설계 해야하고, join 수행 시 가짜 데이터가 생기지 않도록 설계하고 되도록이면 null을 줄일 수 있는 방향으로 설계해야 합니다.
하지만 성능 향상을 위해 일부러 테이블을 나누지 않는 경우도 있습니다!