[ Database - Advance ] - MVCC

먼저 MVCC가 무엇인지 알아보기 위해 위는 간단한 예시입니다. write(x=50)은 write_lock을 잡고 write하는 일련의 과정을 나타낸 것입니다. 앞으로 생략하겠습니다. 또한, commit하고 그 뒤에 unlock(x) 즉 write-lock을 해제해주는 과정을 진행해 주어야 하는데, 그 이유는 recoverability를 위해 commit 시점 뒤에 해준다고 이전에 설명했었습니다.
위 그림 시점 이후에 또 tx1 에서 tx2 unlock이후에 x를 읽는다면 어떻게 될까요?? 10일까요 아니면 50일까요?? 이는 당연히 DBMS의 isolation level에 따라 다르겠지요.
만약 read committed는 read하는 시간을 기준으로 그 전에 commit된 데이터를 읽기 때문에, tx2 commit 이후에 적용된 값인 50을 읽게 될 것입니다. repeatable read는 tx 시작 시간 기준으로 그전에 commit된 데이터를 읽습니다. 이 시작 시간이라는게 첫번째 read가 되는 시점인지 아니면 진짜 트랜잭션이 시작되는 시점인지는 RDBMS마다 다르지만, read할 때, x가 10이 될것이라는 것은 자명한 사실입니다.
MVCC란 데이터를 읽을 때 특정 시점 기준으로 가장 최근에 commit된 데이터를 읽습니다. (여기서 특정 시점이라는 것은 isolation level마다 다릅니다) 그리고 MVCC는 데이터 변화(write) 이력을 관리해서 추가적인 저장공간을 더 잡아먹게 됩니다. 하지만 장점은 write하는 동안에도 read할 수 있고 read하는 동안에도 write할 수 있게 됩니다. 즉 blcok되지 않고 동시에 처리할 수 있는 트랜잭션 부분이 늘어남에 따라 더 효율적으로 동작할 수 있게 됩니다.
그리고 MySQL에서는 특정 시점 기준으로 읽는 다는 것을 Consistent read라고 합니다.
그 외에도 serializable인 경우, MySQL은 MVCC로 동작하기보다는 lock으로 동작합니다.PosgreSQL은 SSL(serializable Snapshot isolation) 기법이 적용된 MVCC로 동작하게 됩니다. read uncommitted인 경우는, MVCC는 committed된 데이터를 읽기 때문에 이 level에서는 보통 MVCC가 적용되지 않습니다. MySQL의 경우에서느 read uncommitted가 적용되는 경우를 repeatable read와 동일하게 봅니다. PostgreSQL도 비슷합니다.
바로 적절한 예시를 보겠습니다.

위의 두개의 트랜잭션에 대한 결과를 예상해보면 x=40, y=50이 되어야 할거 같습니다. 우선 tx1, tx2 각각이 read committed로 동작한다고 해보겠습니다.

그런데, 위와같이 먼저 tx1이 write(write-lock)을 10을 해버리고 tx2가 tx1의 commit 이전에 x의 값을 읽고 x에 대한 write-lock을 가져오고 80이라는 값을 쓰게 됩니다. 이 상황에서 tx2는 tx1이 x에 대한 write-lock을 가지고 있기 때문에 block됩니다. 그 후, tx1이 y를 읽은 다음에 y에 대한 write-lock을 얻고 y에 50을 쓰고 commit 합니다. 이렇게 하게되면 tx1에서 x를 10으로 바꾼 것이 씹히게 되는데 이를 우리는 이전에도 말했지만 Lost Update라고 했습니다.
이를 해결하기 위해 tx2를 repeatable read isolation level로 변경해보겠습니다. 그럼 이는 write(x=80)될 때에 같은 데이터에 먼저 update 한 tx가 commit되었기 때문에 나중 tx(=tx2)는 rollback됩니다. 그래서 (x=10, y=50)이 되고 tx2가 다시 실행되어서 (x=40, y=50)이 될 수 있는 것이죠. 이러한 방식을 first-updater-win이라고 합니다. 이처럼 트랜잭션 마다 다른 isolation level을 줄 수 있습니다.
하지만 이 경우에도 문제가 생기는데, tx1을 여전히 read committed로 유지해도 괜찮냐는 것입니다.

위와같은 상황에서 x=10으로 업데이트 한 것이 씹히게 됩니다. 그래서 (x=10, y=50)이라는 기이한 결과가 나옵니다. 그래서 tx1도 repeatable read로 변경해야함을 단번에 눈치챌 수 있습니다.
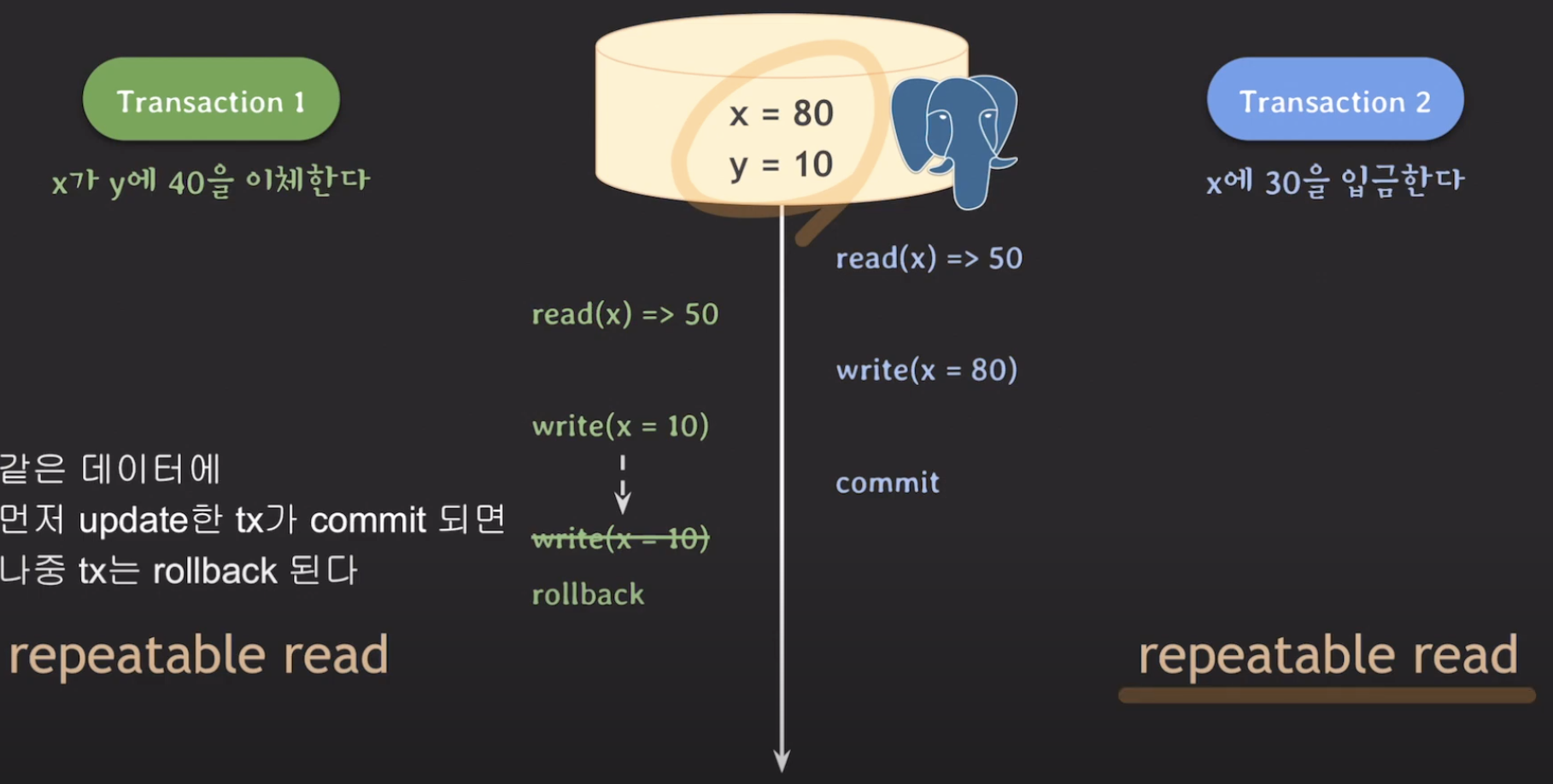
이 또한 write(x=10)인 상황에서 tx1이 rollback되게 됩니다. 이와같이 Lost update 문제를 해결하기 위해서는 한 트랜잭션의 isolation level만을 챙겨주면 되는 것이 아니라 연관있는 다른 트랜잭션의 isolation level까지 챙겨주어야 함을 알아야 합니다. 이 모든것은 PostgreSQL 기준입니다. 사실 MySQL기준에서는 repeatable read인 경우에도 그냥 rollback하지 않고 쭉 진행합니다. 여전히 Lost update가 발생하게 되는데, 과연 MySQL에서는 어떻게 이를 해결할지 살펴보겠습니다.
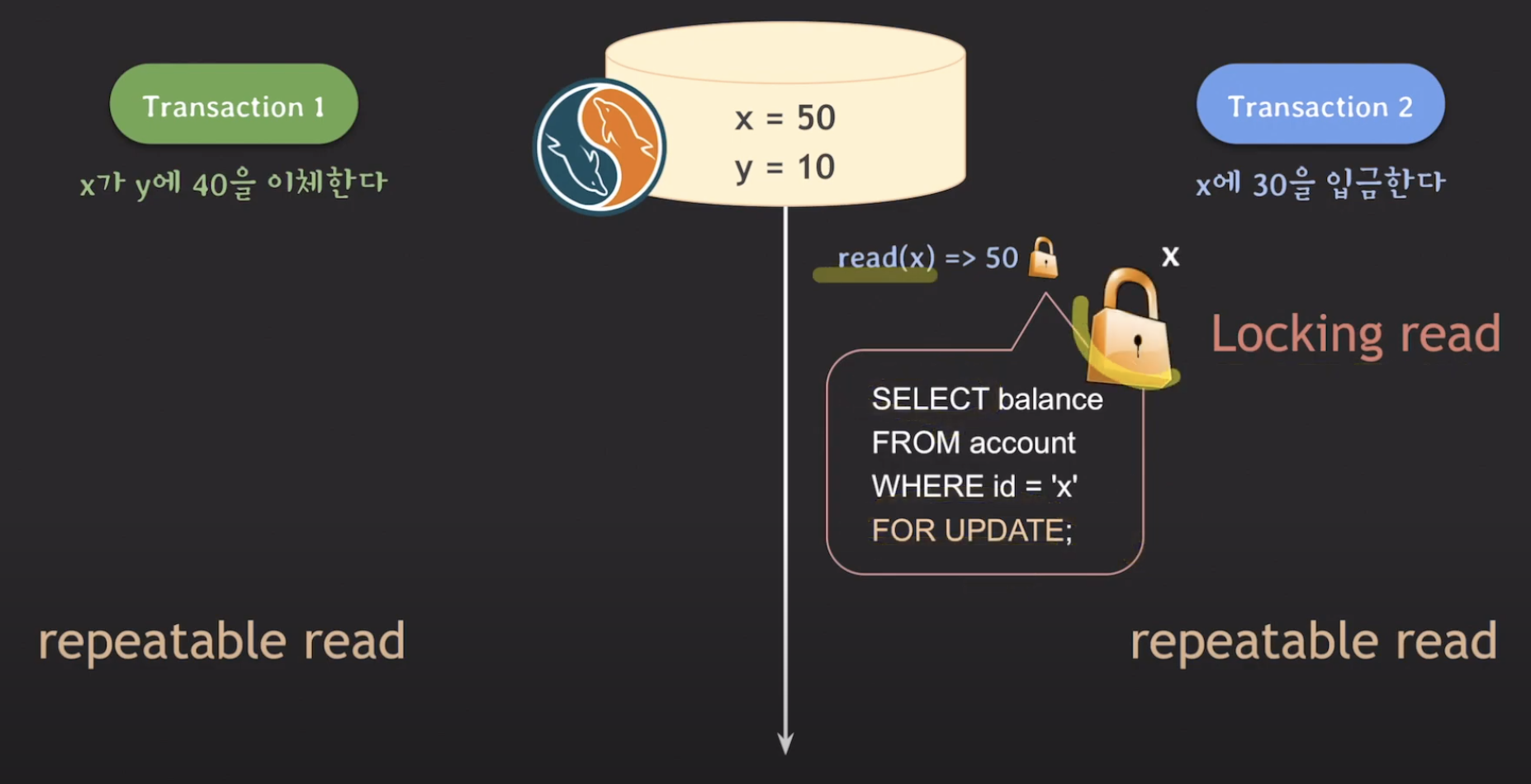
먼저 이를 해결하려면 Locking read라는 개념을 알아야 합니다. 이는 MySQL에서 개발자가 챙겨줘야 하는 부분인데요, SQL구분 맨 끝에 FOR UPDATE를 붙혀주어 read상황에서도 write-lock을 획득할 수 있게 해야합니다. 그 후에도 tx1에 대한 read(x)도 Locking read로 읽어주어야 하겠죠? 그럼 tx1은 blocking 될 것입니다.

하지만 read(x)를 tx2에서 commit 이후에 할텐데 어떤 값을 읽어올까요? repeatable read이니까 50?? 아닙니다. Locking read상황에서는 isolation level과 상관없이 가장 최근에 commit된 값을 가져오기 때문에 80을 가져오고 쭉쭉 또 y에 대한 write-lock을 read할떄 가져오고 하면 (x=40, y=50) 이렇게 정상적으로 MySQL에서 동작할 수 있게 됩니다.
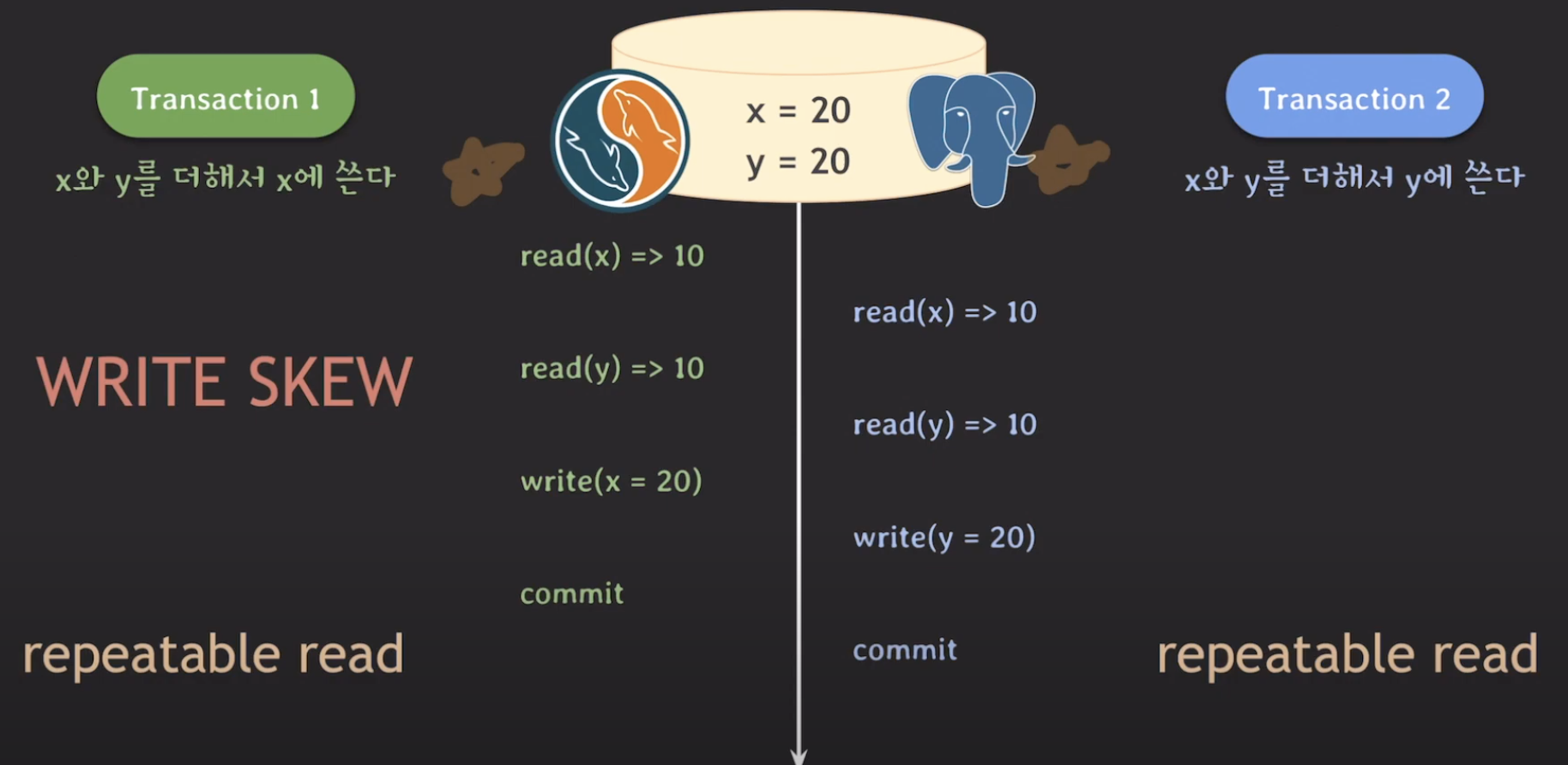
그 다음은 두 상황에서 발생할 수 있는 WRITE SKEW를 보겠습니다. 위 흐름을 쭉 타고 들어가보면 (x=20, y=20)이라는 결과가 나오는데, 원래라면 (x=20, y=30)이나 (x=30, y=20)이라는 결과가 나오는게 맞습니다. 이러한 문제를 어떻게 해결하는게 좋을까요??
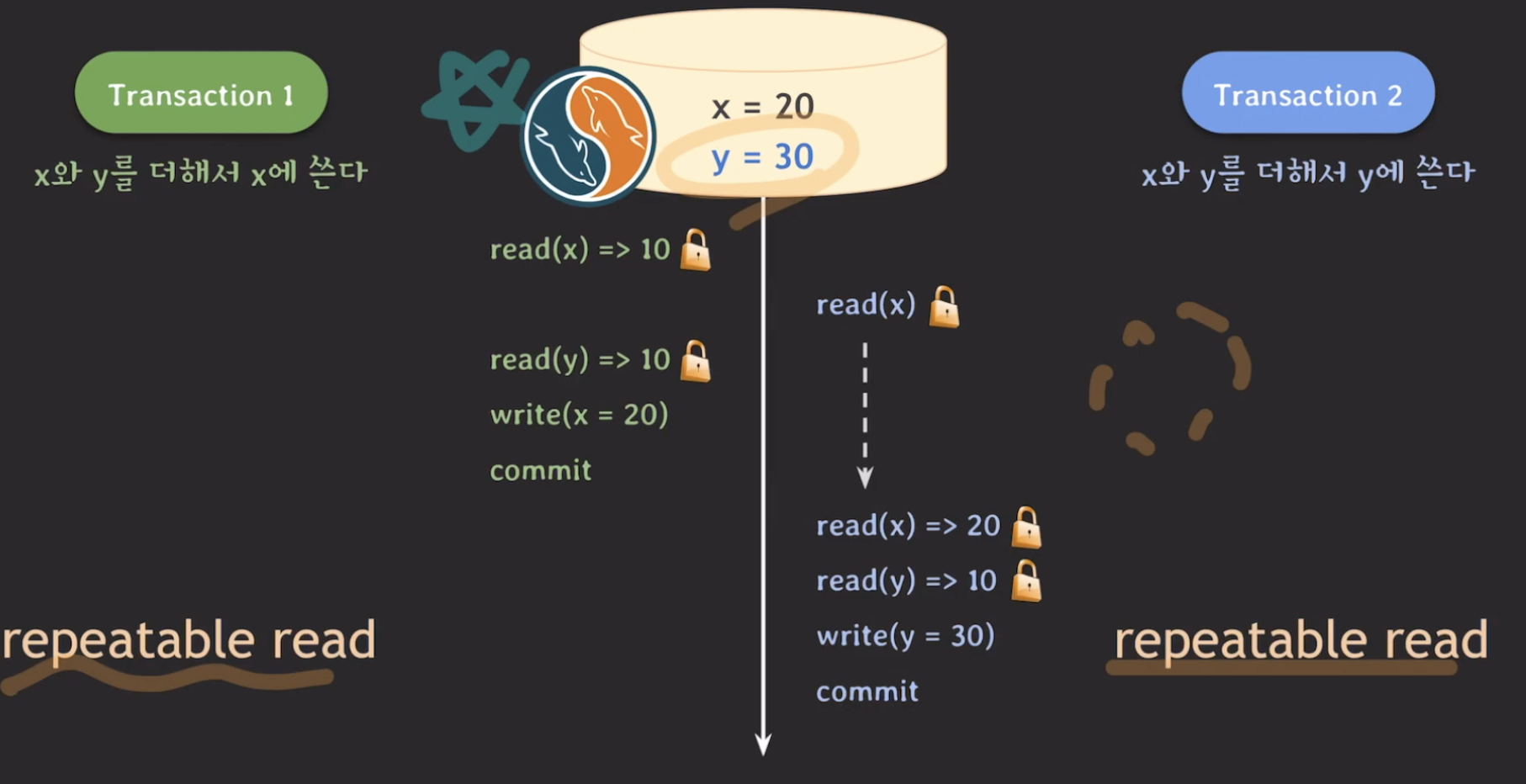
MySQL에서 해결하는 방법은 Locking read를 그대로 챙겨주게 되면, read(x)하게 될 때 write-lock을 챙기게 됩니다. 그 후에 tx2에서는 lock이 해제가 될 때까지 blocking 될 것입니다. 그 후에 read(y)를 할 때도 write-lock을 챙깁니다. 그리고 쭉쭉 진행하죠. 그리고 여기서의 핵심도 Locking read에서는 isolation level과 상관없이 가장 최근에 commit된 내역만 읽는다고 했기 때문에, tx1이 commit된 후에 x값인 20을 읽게 되고 쭉쭉 진행해서 y=30을 최종적으로 commit할 수 있게 됩니다.
이러한 FOR UPDATE(=shared lock, exclusive lock)을 사용해주게 되면 해당 행 또는 테이블에 대한 다른 동시 작업을 차단하므로 동시성(concurrency)이 감소하고 결국 일련의 연산이 직렬화(serialization)되는거 아닌가? 그럼 MVCC 의 장점이 없어지는거 아닌가라고 혼자 생각해볼 수 있었습니다. 하지만 이는 데이터의 일관성을 보장하는데 유용할 수 있습니다. 즉 MVCC는 동시성을 높이기 위한 일반적인 방법이지만, 모든 상황에서는 최선의 방법이 아닐 수 있습니다. 동시성이 높은 시스템에서는 트랜잭션 격리 수준, 잠금 유형, 인덱싱 전략 등을 고려하여 데이터 무결성과 성능 사이의 균형을 찾아야 합니다.
딴 얘기 그만하고 바로 PostgreSQL에서 writeskew를 어떻게 해결하는지 보겠습니다.
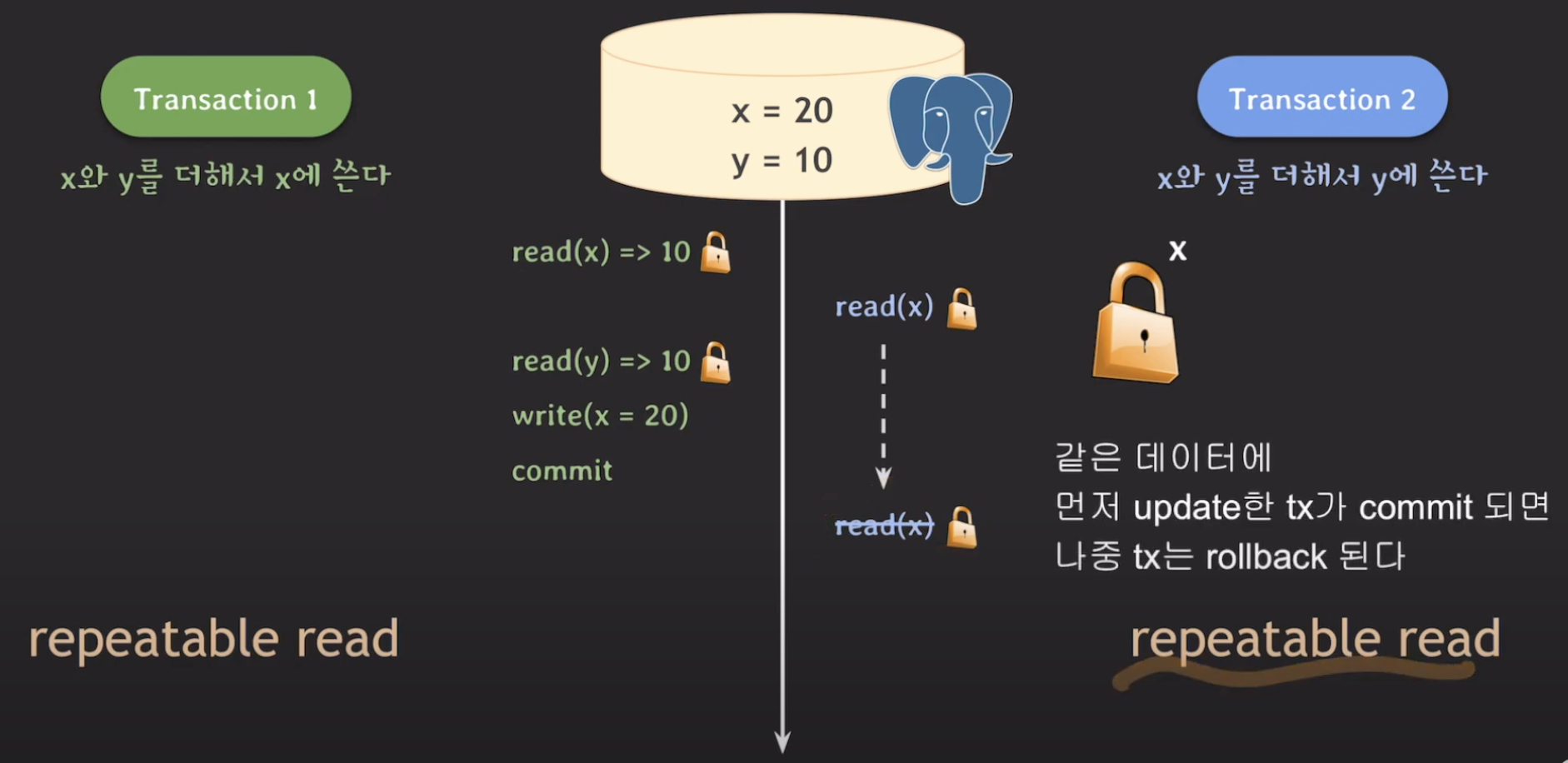
이는 이전과 동일합니다. 같은 데이터에 먼저 update한 tx1이 commit되면 tx2는 자연스레 rollback 되게 되는 것이죠. 이는 FOR UPDATE상황에서 동작한 예시를 보여준 것입니다.

또한 이는 FOR SHARE에서도 똑같이 적용될 수 있습니다(read-lock을 적용) 그리고 그 다음으로 serializable isolation level을 통해서 다 해결할 수 있습니다.

먼저 MySQL을 사용하게 되면 이는 repeatable read와 동일하게 동작합니다. 그리고 트랜잭션의 모든 평범함 select(=read)는 암묵적으로 select ... for share 처럼 동작하게 됩니다. 즉 lock으로 동작하는 것이죠. 그래서 MySQL에서 serializable을 사용한다고 하면 MVCC보다는 lock으로 동작한다고 많이들 얘기한다고 합니다.
그리고 for update가 아닌 for share인 이유는, 성능상의 이슈 때문인거 같습니다. for update를 하게되면 shared lock을 잡기 때문에 동시성에 문제가 있을 수 있습니다. 하지만 for share를 사용하면 이러한 문제점은 줄지만 deadlock이 발생할 가능성이 높아지게 됩니다.
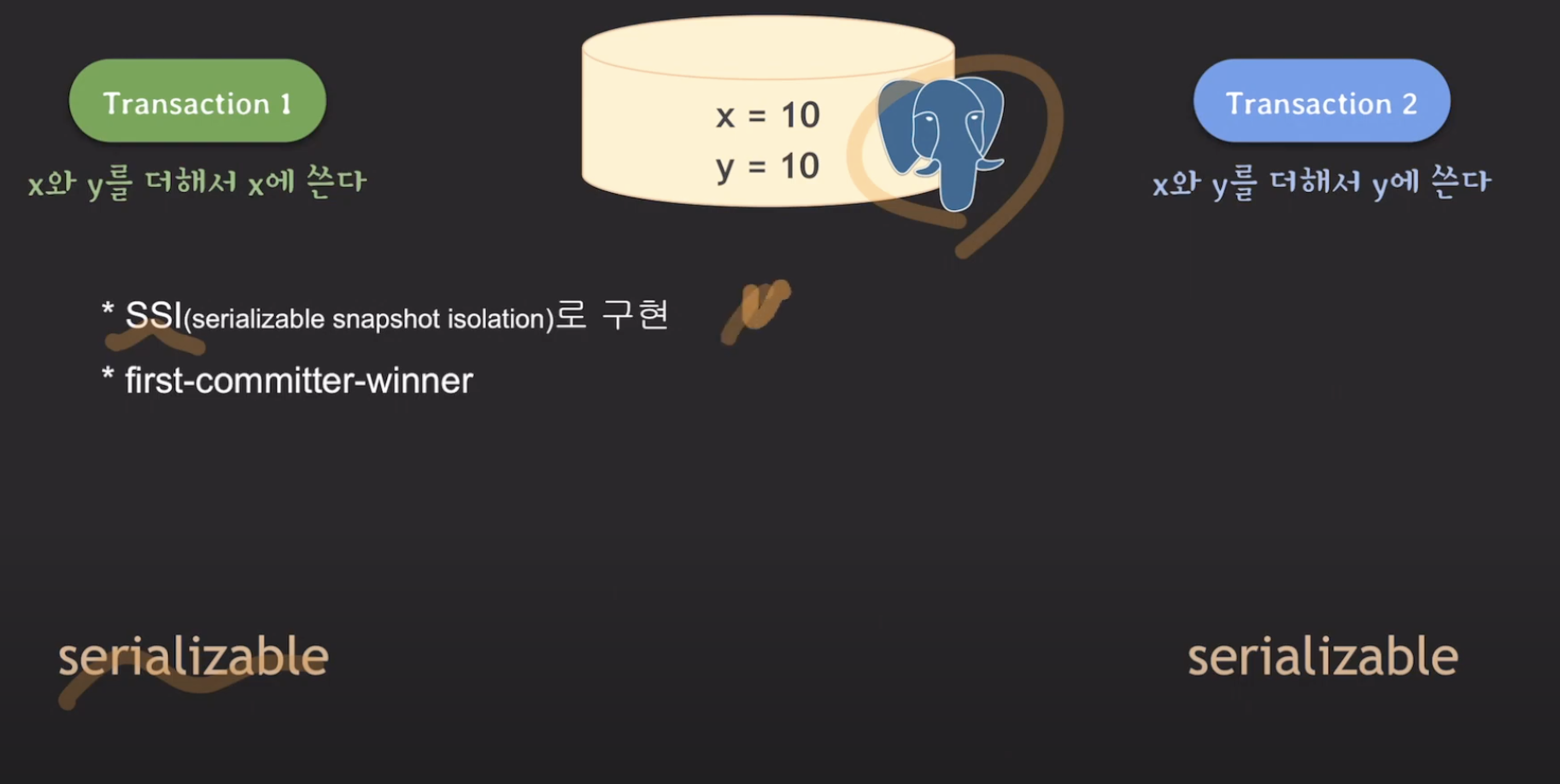
마지막으로 PostgreSQL같은 경우에는 기본적인 MVCC로 동작하면서도 SSI를 통해 이를 간단히 구현합니다. SSI는 기본적으로 first-committer-winner로 동작한다고 합니다.