[ Database - Intermediate ] - Lock을 활용한 concurrency control - 2PL(two-phase locking)

먼저 간단히 read-write lock에 대한 예시입니다. 우리는 이를 OS에서 많이 보았습니다. 먼저 read-lock은 read시에 획득하는 lock으로써 read_lock끼리는 동시에 이 lock에 접근할 수 있습니다. 그 이유는 read 끼리는 공유 자원을 변경하지 않기 때문이죠. 하지만 write-lock은 말 그대로 Mutex(Mutual Exclusion)을 만족시키게 하는 lock입니다. 그냥 일반적인 lock이라고 보시면 됩니다. 즉 아래와 같은 호환성 표를 이해할 수 있을 겁니다.

lock을 써도 생기는 이상한 문제

위 두개의 트랜잭션이 있습니다. 한눈에 봐도 두개의 트랜잭션을 serial하게 실행하면 결괏값이 달라질 수 있다는건 알 수 있을 겁니다.

만약 위처럼 그럼 동시에 실행해보겠습니다. read-write lock을 사용한 예시입니다. 자세한 설명은 빼고 결과를 보면 x=300, y=300으로 Serial하게 실행했을 때와는 다른 결과를 볼 수 있습니다. 즉 이는 Nonserializable하다는 것입니다. 즉 lock 하나만으로 이러한 concurrency를 control할 수 없다는 것입니다.
그 이유는 tx1이 update되기 전에 y를 읽었기 때문에 발생했습니다. tx2또한 마찬가지로 업데이트 되기전의 x값을 읽었기 떄문에 이상한 현상이 발생한 것입니다. 이를 해결하려면 어떻게 해야할까요?? 생각보다 간단할 것입니다.
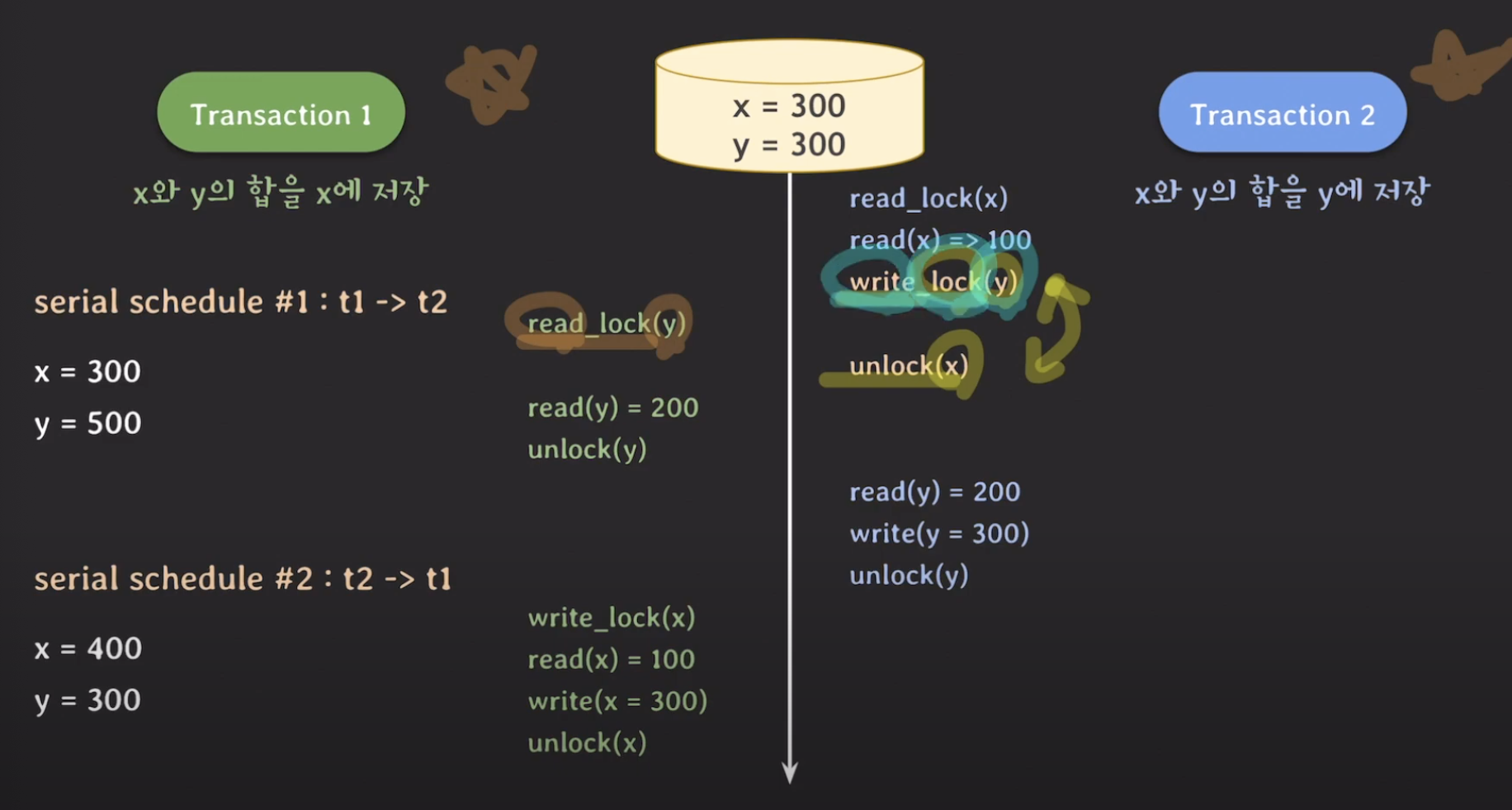
바로 그냥 write_lock(y)와 unlock(X)의 순서를 바꿔주기만 하면 됩니다. 그러면 write_lock(y)을 한 후에 read_lock(y)가 호출되어도 tx1은 lock이 걸려서(block) 그 아래로 실행되지 않죠.
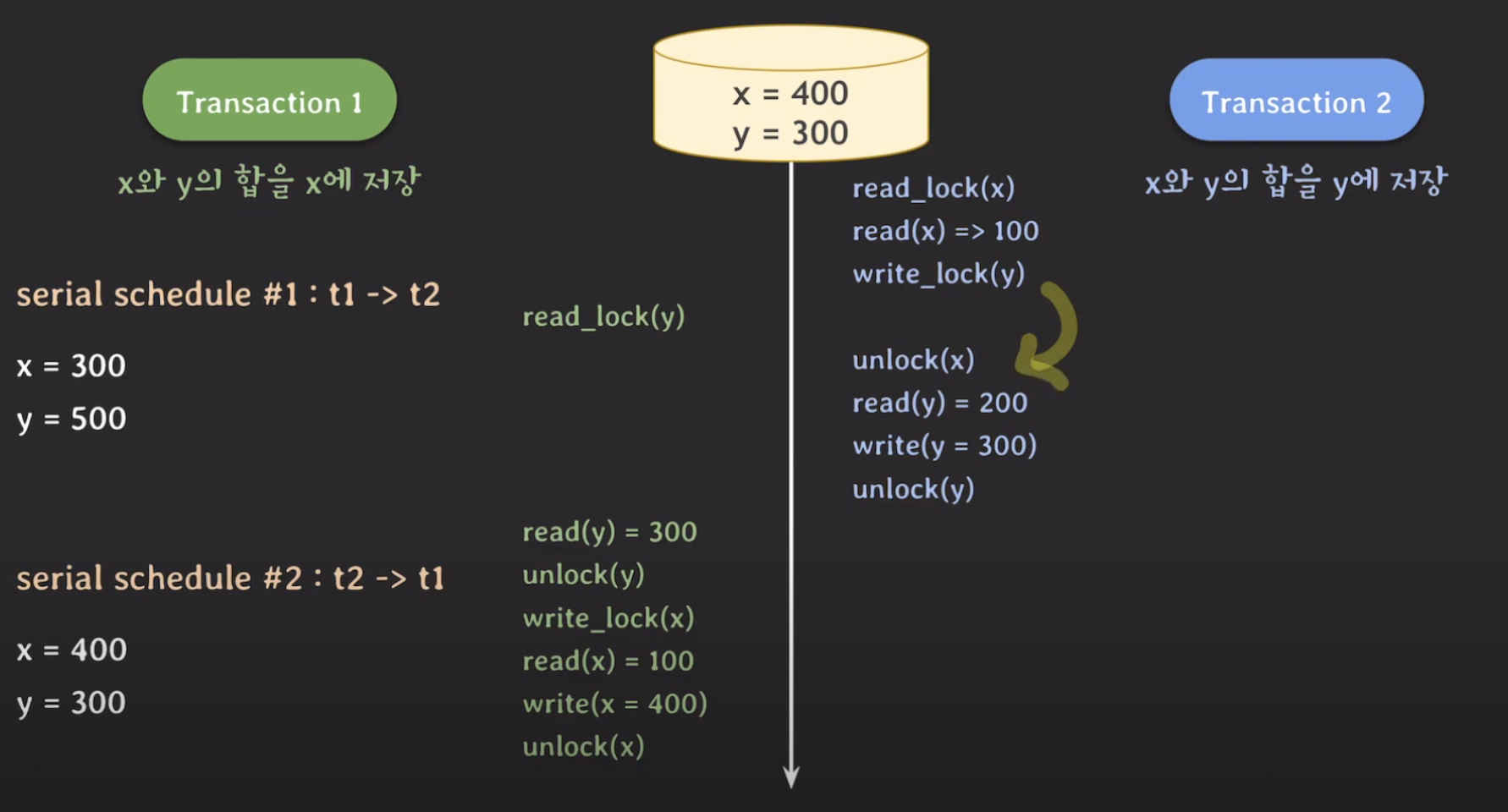
그럼 위와같이 전체적인 operation의 순서가 바뀌게 되는데, tx1의 read(y)를 tx2의 update(=write) 작업이 끝나고 unlock(y)를 한 후에 read가 가능해지기 때문에 Serial schedule처럼 동작할 수 있게 됩니다. 그런데 이건 또 tx1이 먼저 실행되었을 때 고려하지 않은 동작방식입니다. 이를 위해서는 read(y) 을 하고 바로 write_lock(x)를 해주어야 정상 작동 하겠죠.
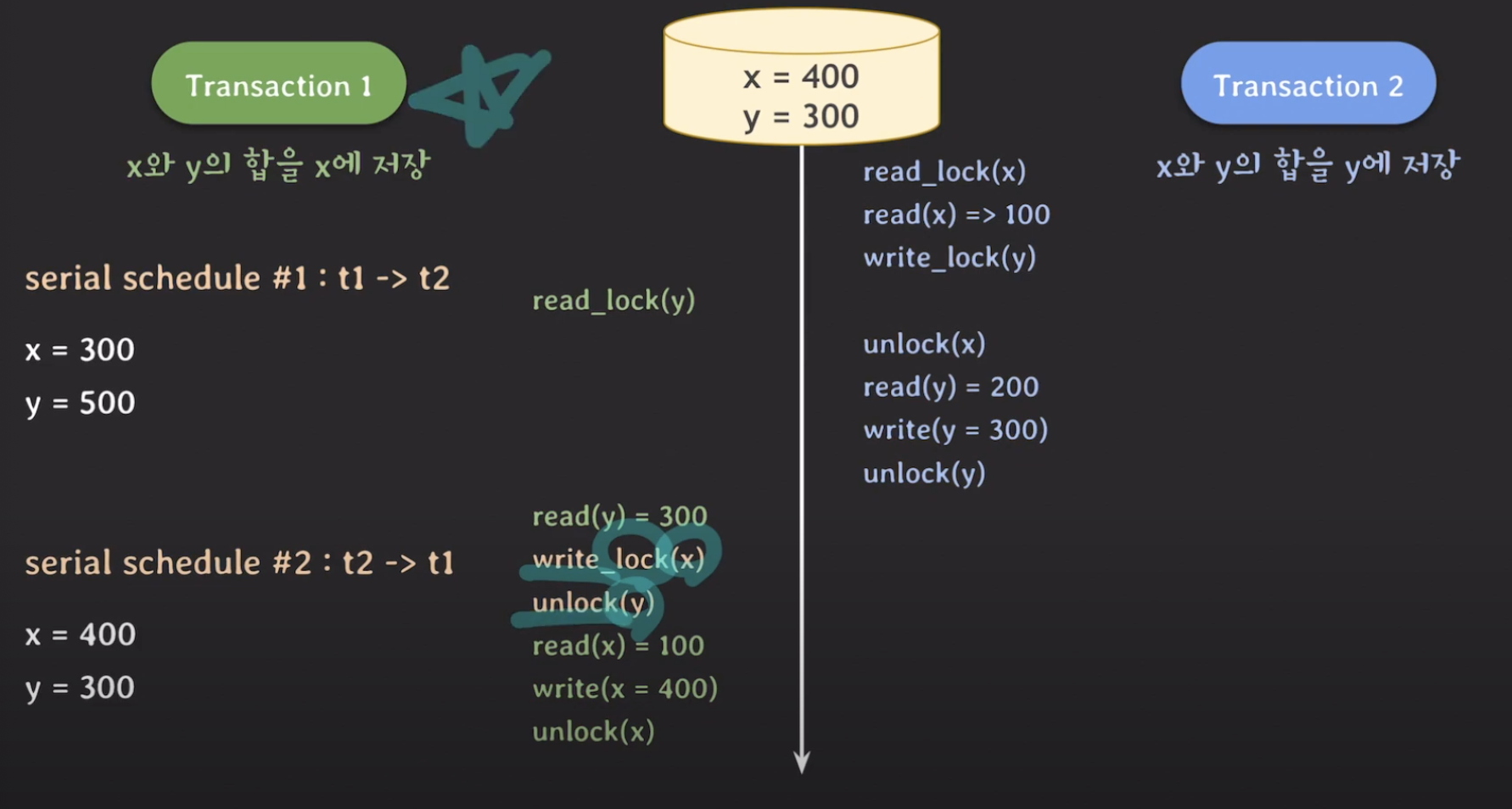
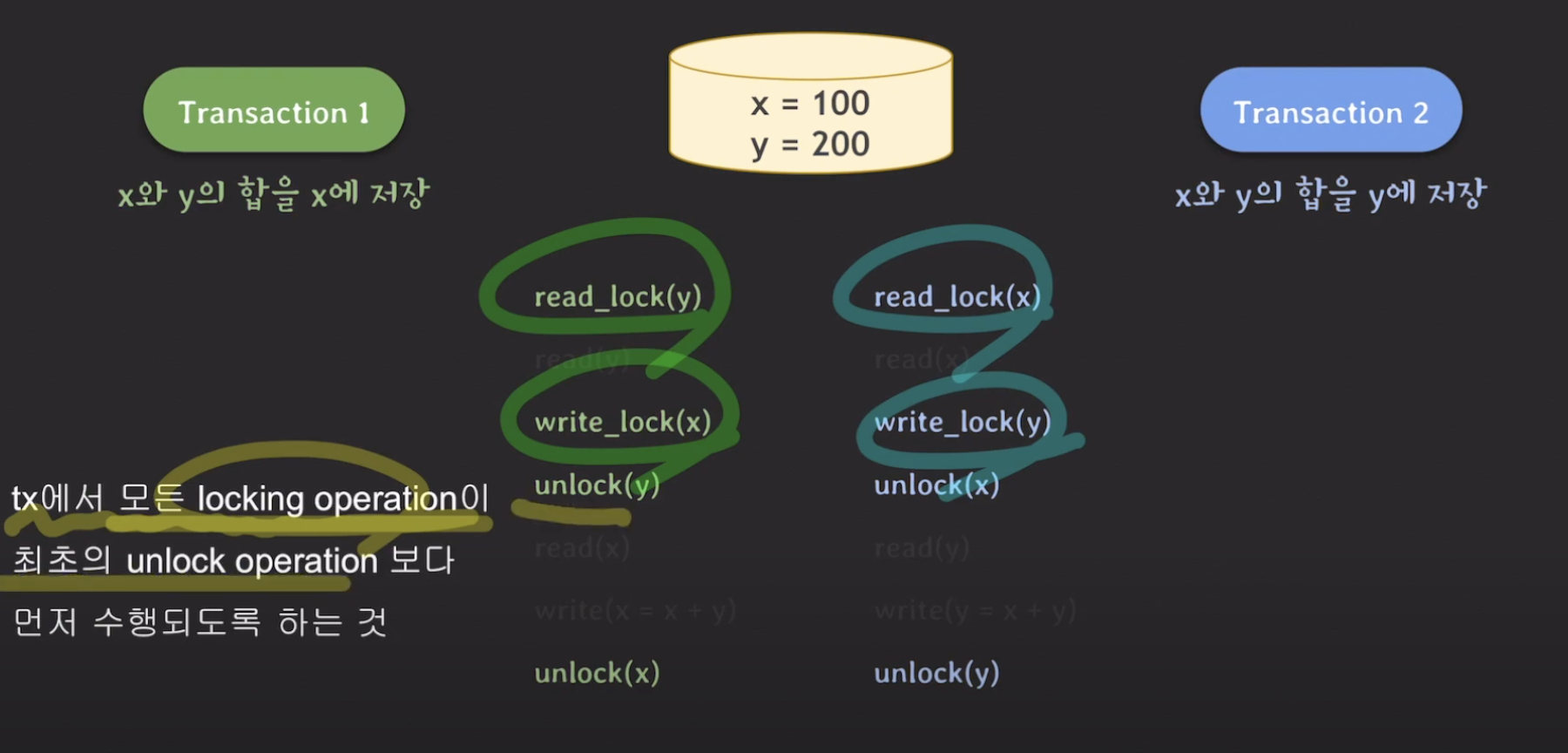
즉 정리해보자면, 트랜잭션에서 모든 locking operation이 최초의 unlock operation보다 먼저 수행되도록 하는 것을 2PL protocol이라고 합니다. 이는 two-phase locking의 약자인데, 그 이유는 트랜잭션에서 read_lock(y) -> write_lock(x)을 하는 부분이 lock을 취득하기만 하고 반환하지는 않는 phase이기 때문입니다. 이를 Expanding phase (growing phase)라고 하고, 이 lock을 반환하는 phase를 Shrinking phase (constracting phase)라고 합니다. 이 2PL protocol은 Serialability를 제공합니다. 하지만 위 경우에서도 OS에서도 배웠지만 Deadlock이 발생할 수 있습니다.
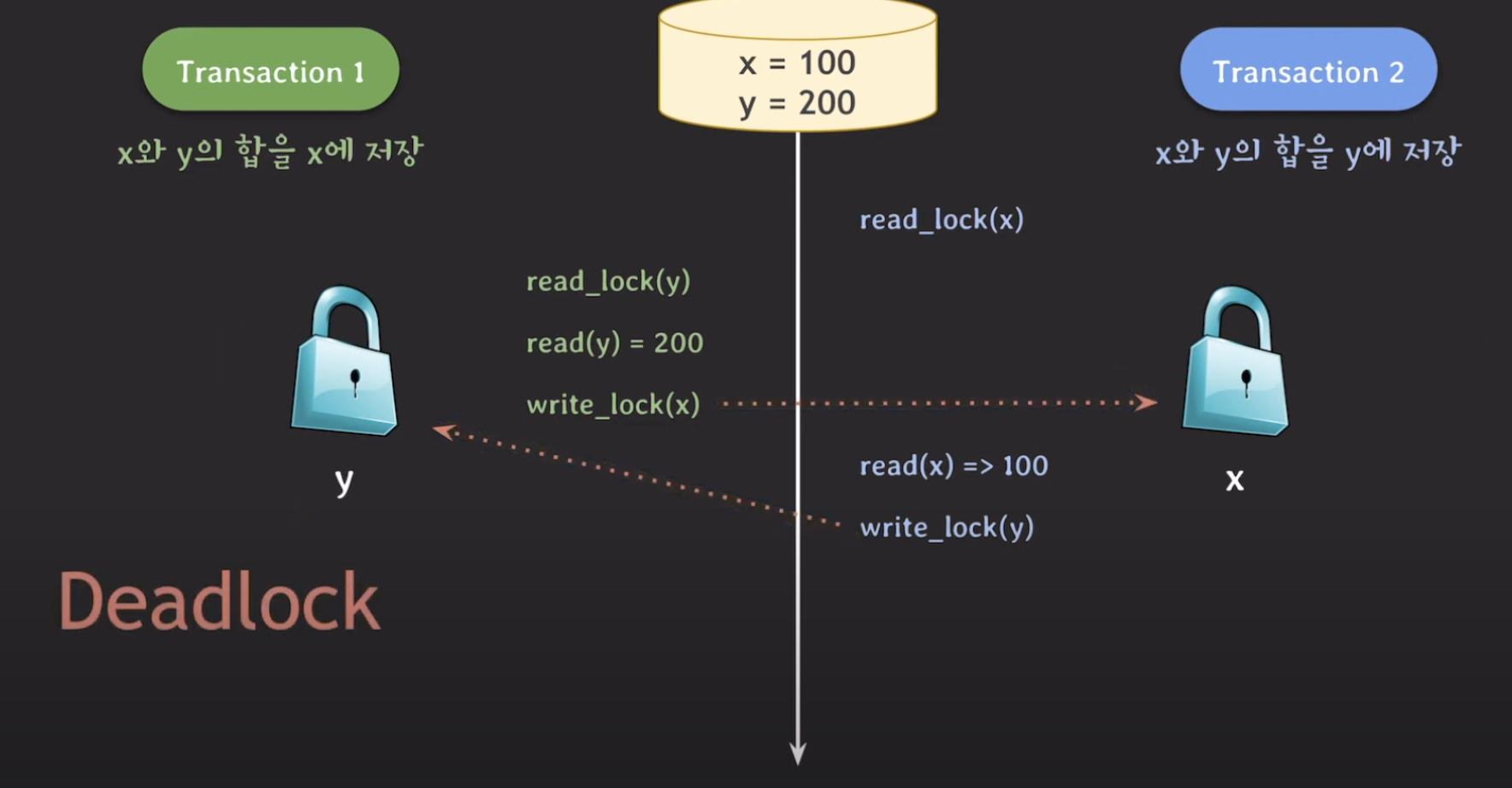
바로 위와같은 순서로 실행된다면, Deadlock이 발생할 수 있습니다. 그래서 2PL을 사용하면 Deadlock이 발생할 수도 있다는 것을 알아야 합니다. 아에 대한 해결방안은 OS에서 소개하는 방안과 같기 때문에 생략하겠습니다.
conservative 2PL

먼저 위와같은 트랜잭션이 있다고 해보겠습니다. 위는 기본적인 2PL protocol인데, 이를 conservativef 2PL로 바꿔보도록 하겠습니다.

이는 이렇게 모든 lock을 다 잡고 가는 것을 말합니다. 하지만 이렇게 하게되면 transaction 자체를 실행하기가 어려워지는 상황이 될 수 있기 때문에 조금 실용적이진 않습니다. 다만 deadlock에서 자유로울 수 있어집니다.
strict 2PL

이는 recoverability할 때도 봤는데, strict란 어떤 트랜잭션이 write하는 트랜잭션이 있다면, 이 트랜잭션이 commit / rollback 되기 전까지는 다른 트랜잭션이 그 데이터에 대해서 read / write 하지 않아야 하는 schedule을 말합니다.
즉 이 strict 2PL은 strict schedule을 보장하는 2PL로써 recoverability를 아래와 같이 제공합니다.

즉 위와같이 commit을 하고 y와 z를 unlock 즉 write-lock을 unlock해주는 것을 strict 2PL이라고 합니다.
strong strict 2PL (SS2PL or rigorous 2PL)
이는 위와 동시에 read-lock 모두 commit / rollback 될 때 반환합니다.

이의 장점은 S2PL보다 구현이 쉽다는 장점이 있고 recoverability를 보장할 수 있게됩니다. 하지만 이렇게 하면 그만큼 readlock을 해당 트랜잭션이 더 쥐고 있게 되는 것이 되므로 동시성에 있어서 더 비효율적이게 될 수 있게 되는것이겠죠
이러한 방식이 초기 RDBMS에서 가장 많이 사용되는 방식이였습니다.
lock 호환성 방식의 약점
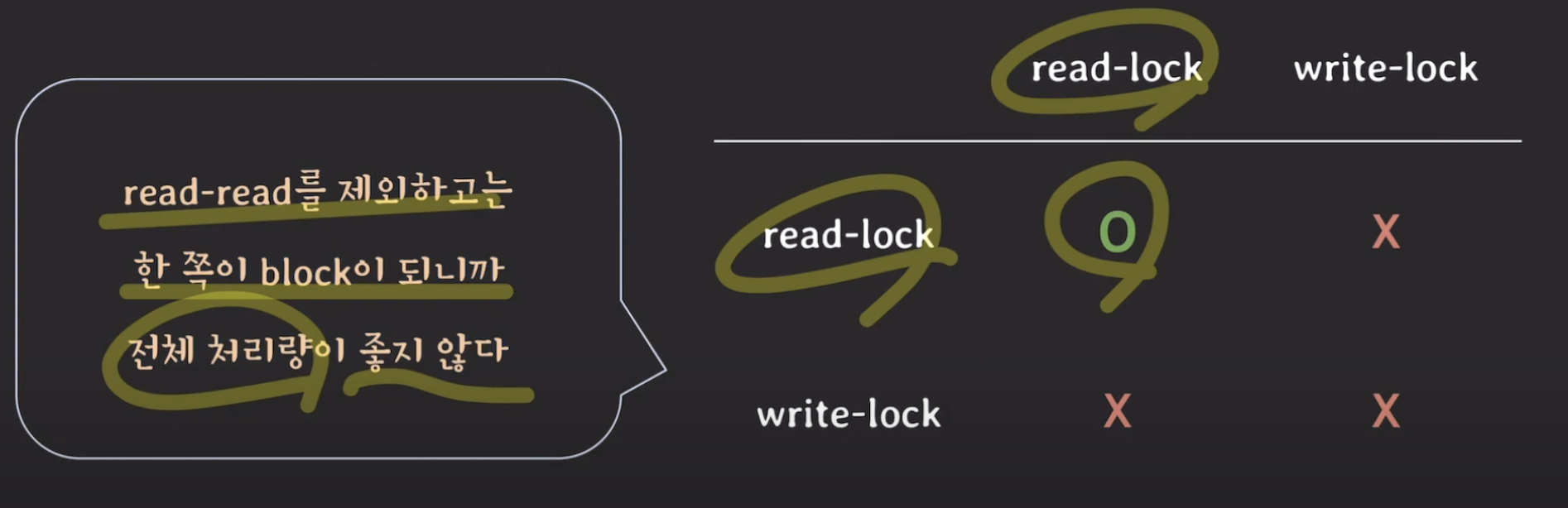
이는 그래도 한쪽에서 lock을 잡으면 다른 트랜잭션에서 block되어서 매우 느리다는 단점이 있습니다. 그래도 read와 write가 서로를 block 하는 것이라도 해결해 보자라는 노력이 있어왔습니다. ( write-write는 절대 될 수 없는 것이고 ) 이에 대한 해결방안이 MVCC(multiversion concurrency control)입니다.
오늘날의 많은 RDBMS가 lock과 MVCC를 혼용해서 사용하곤 합니다.