[ Database - Intermediate ] - concurrency control (schedule, serializability, recoverability )
바로 트랜잭션에서 동시성을 관리하는 방법에 대해 알아보겠습니다. 우선 이전 상황을 가정할 것인데요, K가 H에게 20만원을 이체할 때 H도 ATM에서 본인 계좌에 30만원을 입금하는 상황입니다. 이러한 상황에서는 여러 형태의 실행이 가능할 수 있습니다.

위와같이 20만원 -> 30만원 트랜잭션 순서로 실행될 수 있습니다.

또한 30만원 -> 20만원 순서로 실행될 수 있습니다.

위와같이 중간에 30만원 트랜잭션이 실행될 수도 있습니다.

그리고 이전에 봤던것 처럼 기존의 30만원입금이 씹히는 즉 Lost update 현상이 나타나는 케이스도 있을 수 있습니다.
우리는 이제부터 위 하나하나의 명령어를 operation이라고 정의해보겠습니다. 그리고 이 operation을 짧게 나타내서 case 4를 아래와같이 표현해 보겠습니다. 예를 들어 r1(K) 는 1번 transaction이 K에 read한다는 거고 w1(K)는 1번 transaction이 K에 write한다는 거겠죠?

이를 순차적으로 나열해서 왼쪽과 같이 문자열로 표시해 볼 수 있을 겁니다. 이제 case1, 2, 3을 동일한 방식으로 나열해 보겠습니다.

이와같이 여러 transaction들이 동시에 실행될 때 각 transaction에 속한 operation들의 실행 순서를 Schedule이라고 합니다! 그리고 각 transaction 내의 operations들의 순서는 절대로 바뀌지 않음에 주의해야 합니다.
여기서 sched2, 1과 같이 transaction들이 겹치지 않고 한 번에 하나씩 실행되는 schedule을 Serial schedule이라고 합니다. 반면에 sched 4, 3으로 transaction들이 겹쳐서 진행되는걸 Nonserial schedule이라고 합니다.
Serial schedule과 NonSerial schedule의 성능

위와같이 serial은 순차적으로 r2(H)만해도 디스크에서의 IO 작업을 기다리면서 CPU utilization에 낭비가 발생합니다. 하지만 nonserial 만 해도 r2(H)가 IO 작업을 하는 동안 r1(K)를 통해 K의 돈을 확인하고 w2(H)를 통해 30만원을 입금하고 w1(K)를 통해 20만원 이체를 완료하고,,,. 를 비동기-논블로킹으로 진행해서 transaction들이 겹쳐서 실행되기 때문에 동시성이 높아져서 같은 시간 동안 더 많은 transaction들을 처리할 수가 있게 됩니다.
하지만 Nonserial schedule의 단점이 당연히 존재하죠. sched4처럼 transaction들이 어떠한 형태로 겹쳐서 실행되는지에 따라 잘못된 결과가 나타날 수 있게 된다는 점이죠.

그래서 serial schedule과 동일한 nonserial schedule을 실행하면 되겠다는 아이디어가 나오게 됩니다! 이제 이 schedule이 동일하다라는 의미가 무엇을 의미하고 conflict가 무엇인지에 대한 정의를 내려보도록 하겠습니다.

먼저 위 3가지 조건을 만족하면 conflict라고 합니다. sched3에서의 r2(H)과 w1(H)의 관계인 것이죠. 이렇게 두 transaction이 서로 다른 transaction소속이고, 같은 데이터에 접근하고 있고 최소 하나는 write operation이라면 이를 read-write conflict라고 합니다. 이 외에도 w2(H), r1(H)도 read-write conflict이겠죠? 그리고 w2(H), w1(H)도 conflict인데 이는 write-write conflict라고 합니다.
이 conflict operation이 중요한 이유는 conflict operation은 순서가 바뀌면 결과도 바뀌기 때문에 매우 중요합니다.

위와같이 w2(H)와 r1(H)의 순서가 바뀌면 결과가 바뀌게 되겠죠..? 그럼 이제 우리는 Conflict equivalent라는 개념을 정의할 수 있습니다.

위에서 나열한 3개의 conflict operation이 순서가 양쪽 schedule 모두 같고 두 schedule이 같은 transaction들을 가지면 이를 우리는 Conflict equivalent라고 말합니다. 그래서 sched3, 2는 Conflict equivalent라고 하는 겁니다.
그런데 sched2는 serial schedule입니다. 그리고 sched3은 nonserial schedul인데, 이떄 sched3은 serial schedule과 equivalent하다고 하는 겁니다. 즉 serial schedule과 conflict equivalent일 때, 우리는 Conflict serializable하다고 말할 수 있는겁니다!!!! 즉 nonseral sched3은 conflict serializable하다고 말할 수 있습니다.

하지만 sched4는 sched2과 conflict operation이 서로 역전되어 있기 때문에 conflict serializable하지 않않습니다.
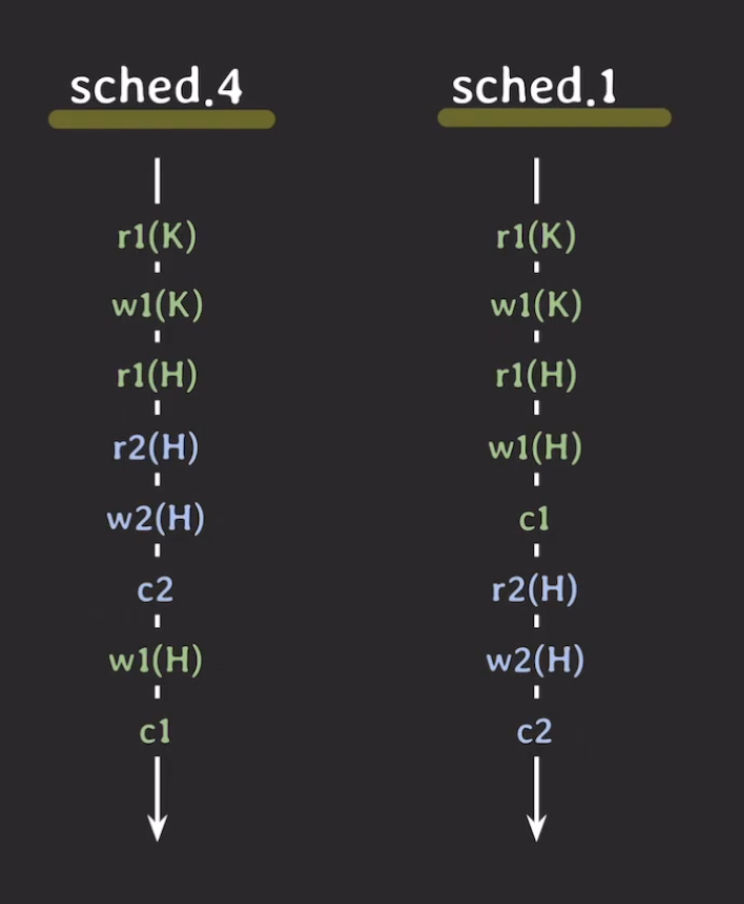
그 외에도 sched1과도 conflict serializable하지 않기 때문에 sched4는 그 어떤 serial schedule과도 conflict equivalent하지 않기 때문에 이 sched4는 conflict serializable하지 않기 때문에 이상한 결과가 나왔던 것입니다.
그래요 이제 equivalent하다까지 정의했는데,, 이를 RDBMS상에서 어떻게 구현해야하냐 라는 구현상의 이슈가 생기게 됩니다. 만약 여러 transaction이 실행될 때마다 해당 schedule이 conflict serializable인지 확인하는 것은 현실적으로 불가능하고 비효율적입니다. 그 대신에 여러 transaction을 동시에 실행해도 schedule이 conflict serializable 하도록 보장하는 프로토콜을 적용합니다.
즉, concurrency control이 어떠한 schedule도 serializable하게끔 만들어 줄 수 있다는 것이죠. 그리고 이와 밀접한 관련이 있는게 Isolation(격리 수준)입니다. 하지만 그만큼 격리수준 level 즉 serializable의 강제성을 높이면 그만큼 성능이 안좋아지게 되는 것이죠. 그래서 relaxed isolation을 제공하겠다! 라고 해서 등장한 것이 isolation level이 되는 것입니다~
Recoverability

만약 위와같은 scheule 5번 상황을 보겠습니다. 이는 20만원을 K가 먼저 이체하고 H에게 쓰는 그 타이밍에 H가 30만원을 찾아오는 그 트랜잭션이 진행됩니다. 그리고 총 250만원이 1번 트랜잭션이 commit되면서 적용되는데, 2번 트랜잭션이 중간에 뭔가 문제가 발생해 commit이 아니라 abort를 발생시키게 됩니다. rollback(H_balance = 200만원)으로 말이죠.
이 상황에서 tx2는 더 이상 유효하지 않으므로 tx2가 write했던 H_balance를 읽은 tx1도 rollback 해야 합니다. 하지만 tx1은 이미 commit된 상태이므로 durability 속성 때문에 rollback 할 수 없습니다. 이러한 tx1같은 경우를 unrecoverable schedule이라고 합니다. 이 스케줄은 rollback을 해도 이전 상태로 회복 불가능할 수 있기 때문에 이런 schedule은 DBMS가 허용해서는 안됩니다.
그 이유는 위 상황이 발생하면 K는 80만원이 되고 H는 200만원이 되는 기이한 상황이 발생하기 때문에 데이터 불일치가 발생하게 되기 때문이죠. 즉 우리는 reocverable schedule을 DBMS가 허용해야 하는 것이고 어떤 스케줄이 이에 해당하는지 알아보겠습니다. 여기서는 commit의 순서가 중요합니다!!

해결 방안은, 의존성이 걸려있는 트랜잭션은 의존성이 걸린 트랜잭션이 끝날때까지 commit을 해서는 안되게 바꿔주면 됩니다. 즉 tx2가 끝날때까지 tx1은 commit을 해서는 안되는 것이죠. 즉 schedule 내에서 그 어떤 transaction도 자신이 읽은 데이터를 write한 transaction이 먼저 commit / rollback 전까지는 commit하지 않는 경우 recoverable schedule이라고 합니다.
이와같이 tx2가 rollback될 때 tx1이 전이되서 rollback되는 것을 cascading rollback이라고 합니다. 이는 여러 트랜잭션의 rollback을 연쇄적으로 일어나면 처리하는 비용이 은근 많이 들게 됩니다. 즉 이를 해결하기 위해 데이터를 write한 transaction이 commit / rollback 한 뒤에는 데이터를 읽는 schedule만 허용하자는 규칙이 등장합니다.

즉 트랜잭션 2번이 commit된 후에만 트랜잭션 1번이 읽고 쓰는 작업을 할수 있게 강제하는 것입니다. 그래서 만약 트랜잭션 2번이 rollback된다 하더라도 이에 의존하는 어떠한 oepration도 없기 때문에 그냥 tx2를 rollback하기만 하면 되는 겁니다. 이러한 schedule 내에서 어떤 transaction도 commit되지 않은 transaction들이 write한 데이터는 읽지 않는 경우를 cascadeless schedule이라고 합니다.
하지만 얘도 어느정도 문제가 발생합니다. 이를 위해 예시를 조금만 바꿔서, K라는 직원이 피자 가격을 1만원으로 H라는 사장님이 피자 가격을 2만원으로 3만원에서 내리는 상황이라고 해 봅시다.

그런데, 위와같은 cascadeless schedule에서 H사장님이 피자 가격을 2만원으로 내려서 commit했는데, K직원의 트랜잭션이 롤백되면서 사장님의 커밋이 씹혀버리는 현상이 일어날 수도 있습니다. 이러한 경우를 방지하려면 조건을 추가해주어야 하는데, schedule 내에서 어떤 transaction도 commit 되지 않은 transaction들이 write한 데이터는 쓰지도 읽지도 않는 경우로 바꾸어 주어야 합니다. 이를 sctrict schedule로 동작하게 한다고 말합니다.

즉 아래와 같이 schedule해야 strict schedule이 되는 것이죠. 즉 정리하면 concurrency control은 serializability와 recoverability를 동시에 제공하는 것이라고 정의내릴 수 있겠군요! 그리고 이와 관련된 속성이 Isolation인 것이구요